导读
随着AIGC时代的到来,机器学习技术也在不断涌现,例如chatgpt和diffusion等模型的诞生,给人工智能带来了新的机遇和挑战。对于企业和个人而言,跟不上这波潮流,可能就会被淘汰。因此,如何研究和应用新的机器学习技术,成为了各行各业的关注焦点。而Apache DolphinScheduler作为一款优秀的开源调度系统,结合Ray AI Runtime,可以构建可复用的机器学习工作流,提升机器学习工作效率和可复用性,帮助企业更好地应对AIGC时代的挑战。
在这篇文章中,我们将介绍Apache DolphinScheduler和Ray AI Runtime的优势,以及如何结合它们构建可复用的机器学习工作流。旨在为广大机器学习从业者提供一些思路和指导,帮助他们更好地应对AIGC时代的挑战。
概述
Apache DolphinScheduler
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。Apache DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
Apache DolphinScheduler 与其他工具相比有以下优势:
高可扩展性,支持多云、多环境,集群支持弹性扩缩
支持三十多种系统任务类型,并且支持自定义扩展
支持可视化、Python、API配置,易用性好
强大的调度能力,支持时间日历触发、依赖触发,支持跨项目依赖和多租户功能
分布式设计,保证系统稳定
简单的权限设计,支持LDAP
性能好,能支持百万量级
社区非常活跃,每个月至少发一个版本
Ray AIR
Ray AI Runtime(AIR)是一个可扩展并且统一的机器学习应用工具集。AIR 使用 Python 编程语言提供了简单扩展单个工作负载、端到端工作流和流行的生态系统框架的能力。

AIR 建立在 Ray 最佳库的基础上,包括预处理、训练、调整、评分、服务和强化学习等方面库,以此打造了一个生态系统以满足集成需求。Preprocessing, Training, Tuning, Scoring, Serving, and Reinforcement Learning
Preprocessing:数据预处理是将原始数据转换为机器学习模型特征的常用技术。Ray AIR提供多个预处理器和接口,可应用于离线训练数据和在线推理数据。
Training:Ray Train可以扩展Torch, XGBoost、TensorFlow等常用机器学习框架的模型训练,并与Ray Tune和Predictors等Ray库无缝集成。
Tuning:Tune是一个Python库,用于在任何规模下执行实验和超参数调整。通过使用Population Based Training (PBT)和HyperBand/ASHA等先进算法,您可以调整您喜欢的ML框架(如 PyTorch、XGBoost、Scikit-Learn、TensorFlow和Keras)。
Scoring:完成模型训练后,可使用Ray AIR Predictor进行推理和预测。
Serving:Ray Serve是一个可扩展的模型服务库,用于构建在线推理API。它支持多种框架,重点是模型组合能力强,构建复杂推理服务,并基于Ray构建,可轻松扩展大量机器。
Reinforcement Learning:RLlib是一个强化学习的开源库,支持各种生产级和高度分布式的RL工作负载,并为广泛的行业应用提供统一且简单的API。无论您想在多智能体环境中训练代理,纯粹使用离线数据集,还是使用外部连接的模拟器,RLlib都提供了简单易用的解决方案。
构建可复用机器学习工作流
在这个例子中,我们使用Apache DolphinScheduler和Ray AIR构建了可复用的机器学习工作流。
例子案例来源于Tabular data training and serving with Keras and Ray AIR。
所有的代码都可以从这里获取 dolphinscheduler-ray-example
启动 Apache Dolphinscheduler
执行以下命令可以启动DolphinScheduler Standalone
docker run --name dolphinscheduler-standalone-server -p 12345:12345 -p 25333:25333 -p 8265:8265 -d jalonzjg/dolphinscheduler-standalone-server:3.1.4-ray改命令启动了以下端口
12345: 用于访问DolphinScheduler UI
25333: 用于使用 pydolphinscheduler SDK 提交工作流
8265: ray dashboard
然后我们就可以登录 http://<ip>:12345/dolphinscheduler/ui来访问Apache Dolphinscheduler
用户名:admin
密码:dolphinscheduler123
创建工作流
DolphinScheduler可以使用python提交工作流,执行以下命令,你需要在dolphinscheduler-ray-example 目录下
python3 -m pip install -i https://pypi.org/simple/ apache-dolphinscheduler==4.0.0
export PYDS_HOME=./
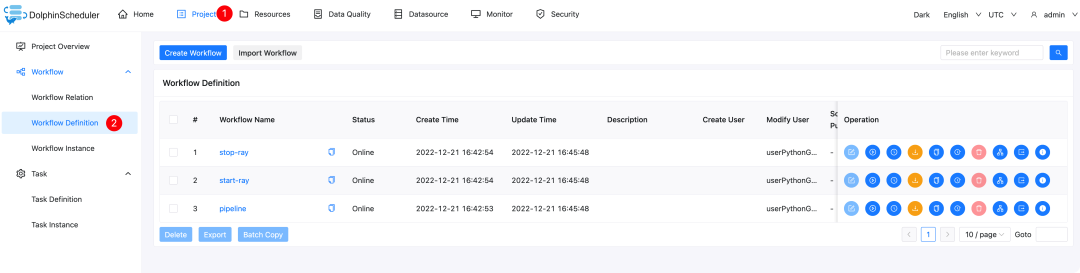
python3 pyds-workflow.py我们登录DolphinScheduler后,就可以看到以下项目

点击项目进去后,我们可以看到3个工作流
start-ray: 在docker里面启动一个 ray cluster
stop-ray: 停止ray cluster
pipeline: 在local ray cluster 中训练模型和部署模型
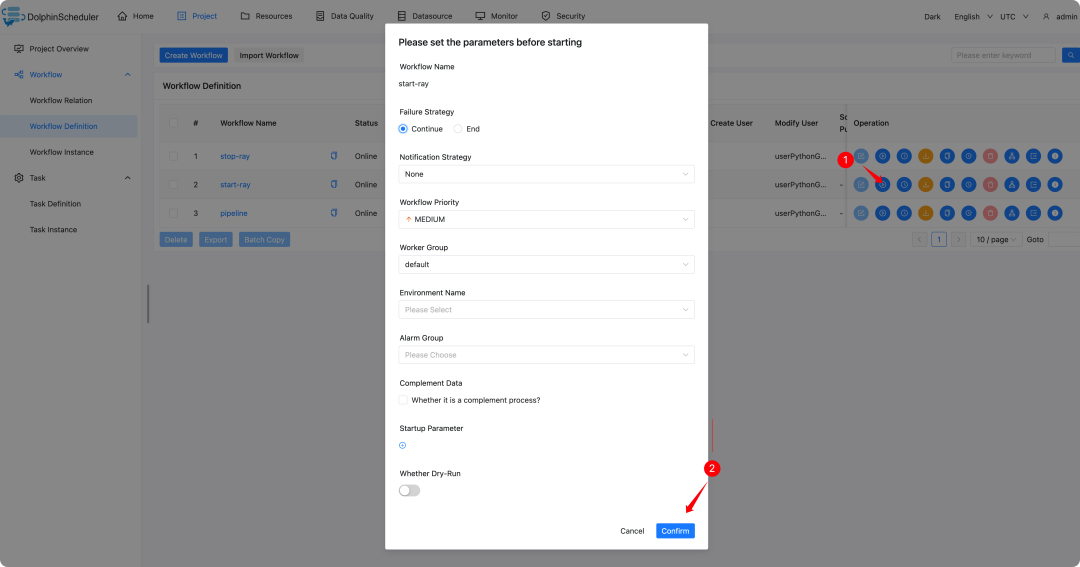
启动ray cluster
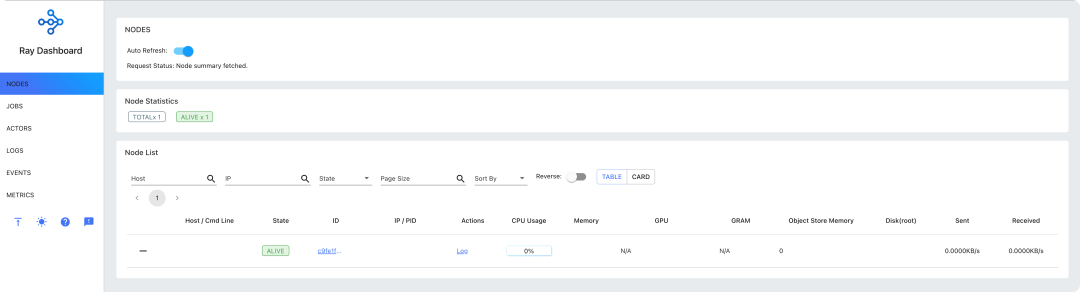
然后我们通过访问 <ip>:8265 就可以登录ray的dashboard
运行Pipeline
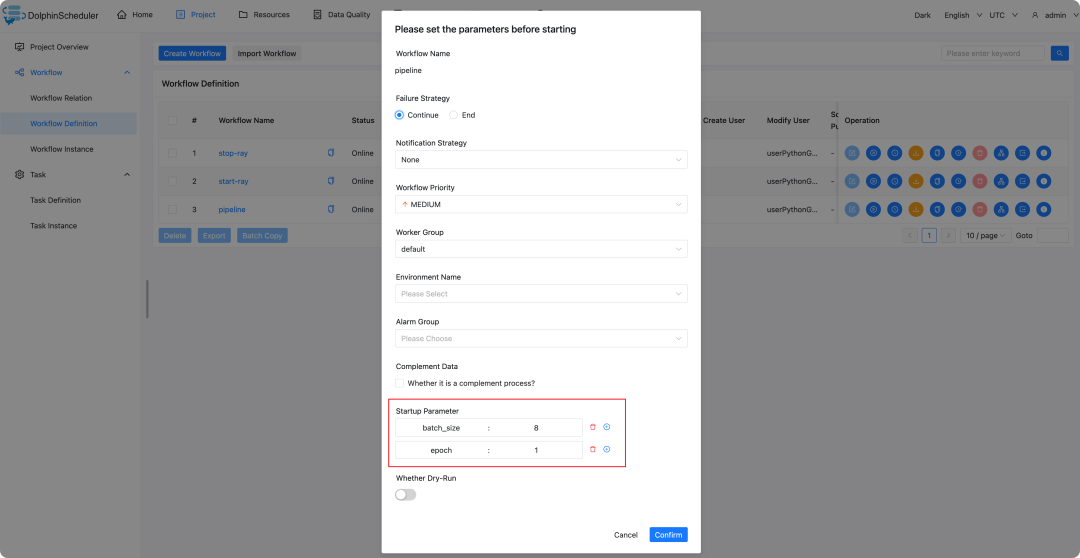
启动参数
batch_size
epoch
对于DolphinScheduler定义的工作流,可以通过参数的方式来构建可复用的机器学习工作流,只需要在任务中抽离参数即可。
任务查看
然后我们就可以在工作流实例中查看对应的任务
train_model: 训练模型,包含了获取数据,和训练模型,详见
train_model.py文件serving: 部署模型,使用 Ray AIR Predictor快速部署模型,详见
serving.py文件test_serving: 测试部署的模型,详见
test_serving.py文件
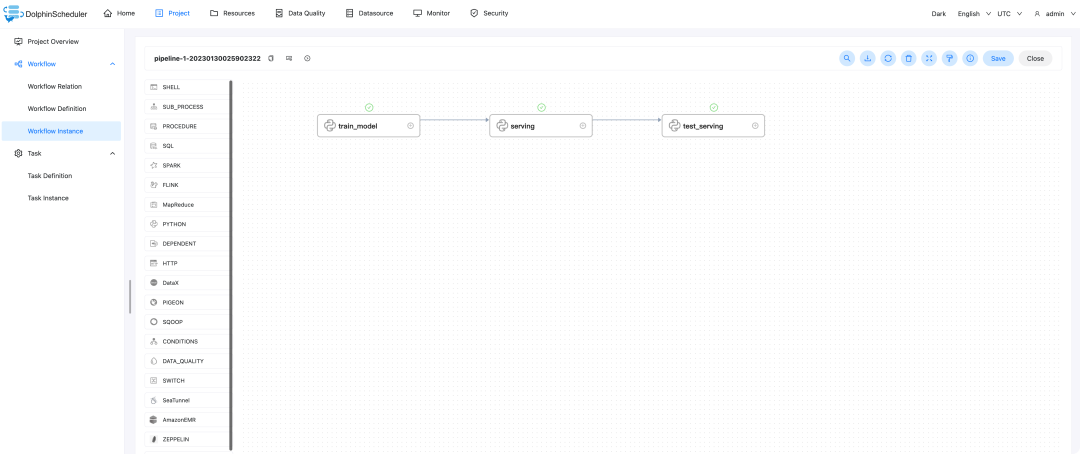
然后我们可以双击对应的任务,查看任务日志,如下图所示
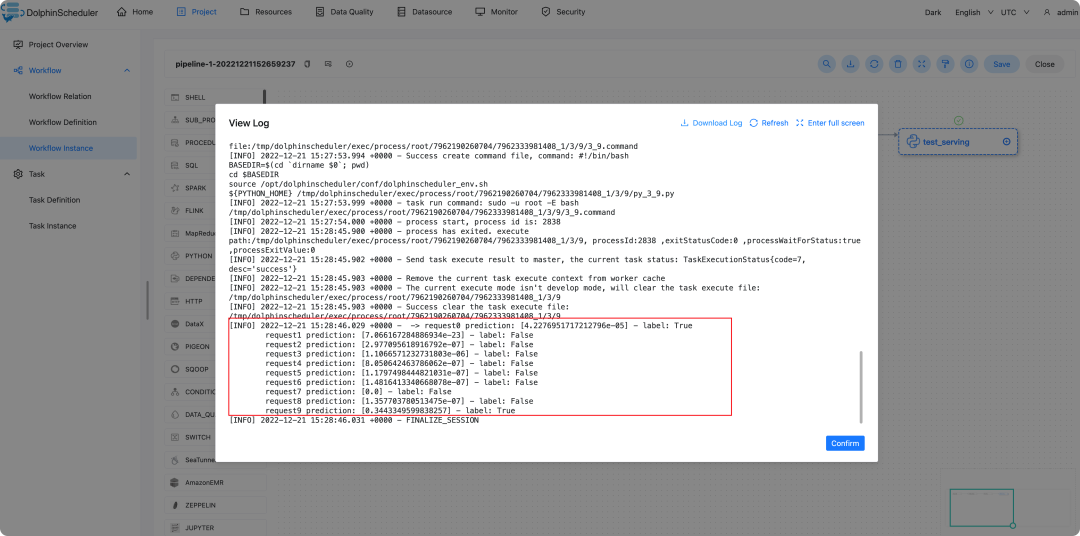
作为结合DolphinScheduler和Ray AI Runtime的实践,我们通过Tabular数据来进行训练和部署实现了一个可重用的机器学习工作流程。
同时,Ray AI Runtime作为一款高性能、分布式的机器学习运行时,具有卓越的性能和可扩展性,在加速机器学习训练和推理方面表现突出。与DolphinScheduler的结合,使得DolphinScheduler具备了更好的调度和管理分布式机器学习任务的能力,两者相结合可以更好地服务于机器学习工作流程的实际应用需求。同时,DolphinScheduler和Ray AI Runtime的优势互补,可以更好地发挥各自的优点和特长,持续推动机器学习水平和实际应用的发展。
随着AIGC(AI-generated content)时代的到来,企业需要处理各种复杂的机器学习任务,例如训练chatgpt、diffusion等模型。这些任务需要在分布式环境中执行,需要高效的调度和管理。DolphinScheduler与Ray AI Runtime的结合,可以为企业提供高效、可扩展的机器学习工作流程,帮助企业更好地训练和管理复杂的机器学习任务,从而在AIGC时代取得更大的成功。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
点击阅读原文,点亮Star支持我们哟