目录
(3)Limited Discrepancy Search (LDS)
1.背包问题
背包问题(Knapsack problem)是一种组合优化的NP完全问题。问题可以描述为:给定一组物品,每种物品都有自己的重量和价格,在限定的总重量内,我们如何选择,才能使得物品的总价格最高。

2.贪婪算法
(1)贪婪算法(Greedy Algorithms):一次选择一个物品,直到不能再选择,选择方法如
- 数量越多越好,每次选择最小重量的物品
- 价值越高越好,每次选择价值最高的物品
- 价值比越高越好,每次选择单位价值最高的物品
(2)贪婪算法总结
- 对于一个问题,有许多可能的贪婪解:有些解比其它好;取决于输入
- 优势:很快设计和实现;求解速度快
- 问题:无法保证解质量;不同问题的解质量差别大;前提假设容易找到可行解
- 优于贪婪解的方法:约束规划;局部搜索;混合整数规划
3.建模
(1)如何建模
- 选择决策变量:我们感兴趣的结果
- 描述这些变量的问题约束:指定问题的解应该是什么样的
- 描述目标函数:指示了解的质量
(2)结果就是一个优化模型
- 一个描述性的形式:告诉你是什么而不是如何做
- 建模的形式有很多
(3)背包问题模型如下: 如果物品数为,那么解的可能性有
,不能暴力枚举

4.动态规划
(1)动态规划(Dynamic Programming):广泛使用的一种优化方法,基本原则如下
- 分成子问题求解
- 自下而上计算
假设有物品,
表示容量为k,物品[1...j]的背包问题的最优解,我们想要知道
,思路如下,假设我们知道如何求解
,那么对于
只需要再多考虑一个物品
,如果物品
的重量
小于
,有两种情况:选择
或者不选择
。

可以用一个小程序实现,下面是自上而下的方法,这个方法效率如何?

回顾一下fibonacci数的代码,计算fib(n)时需要fib(n-2)和fib(n-3),fib(n-2)又需要fib(n-3)和fib(n-4),但是fib(n-3)已经计算过,因此对同一个子问题我们计算了多次

动态规划的思想便是自下而上的计算递归方程,先从一个物品开始,然后两个物品,直到全部
(2)案例分析:以下面问题(左)为例通过表格说明DP过程

- 列0:无物品。O(k,0)=0
- 列1:物品1(价值5,重量4)。O(4,1)=5
- 列2:物品1➕物品2(价值6,重量5)。O(5,1)=5,O(5,2)=max(O(5,1),O(0,1)+6)=6;O(9,1)=5,O(9,2)=max(O(9,1),O(4,1)+6)=11
- 列3:物品1➕物品2➕物品3(价值3,重量2)。O(2,3)=max(O(2,2),3+O(0,2))=3;O(4,3)=max(O(4,2),3+O(1,2))=5;O(5,3)=max(O(5,2),3+O(3,2))=6;O(6,3)=max(O(6,2),3+O(4,2))=8;O(7,3)=max(O(7,2),3+O(5,2))=9;O(9,3)=max(O(9,2),3+O(7,2))=11
- trace back:O(9,3)=11=O(9,2),没有选择物品3,O(9,2)=5,选择物品2,O(9,1)=0,选择物品1
5.分支定界
(1)对于背包问题,可以暴力搜索找到所有的可能性,这是最简单效率也最低的方法


(2)分支定界(Branch and Bound ):迭代分支和定界两个步骤
- Branching:分支即将问题分成多个子问题
- Bounding:定界是指找到子问题最优解的乐观估计,包括UB(上界)和LB(下界)
(3)Relaxation松弛:找到乐观估计的方法
如下图,每次分支更新价值,剩余容量和乐观估计UB,如x1=0,不选择物品1即最优解UB=128-45=83,第一次找到可行解为80,如果别的分支UB<80即可停止。尽管相比暴力搜索,已经节约了一些步骤,但是还有可以改进的空间吗?即在其它方面松弛

假设我们现在可以将物品分割成多个小部分,即设定,根据物品的单位价值比可得选择物品3和物品1,以及1/4的物品2,最优解UB更新为92而不是128,称为linear relaxation。

为什么这样更新UB是对的?将模型写成下面的形式,要求和最大,
越大
就越小

更新UB后重新计算,发现x1=0后UB=92-45=77,无需再进行后续分支操作,相比前一次节约步骤更多,这就是Relaxation的意义,缩小问题解的搜索空间,提高搜索效率。

6.搜索策略
前文的Branch Bound使用的搜索策略为深度优先,本节介绍三个搜索方法:Depth-first,Best-First,Least-Discrepancy
(1)Depth-first
- 选择左边的node
- 什么时候裁剪新分支:it finds a new node worse than the found solution
- 内存:思考一下探索过程,一直选择left,left,left直到不能再继续,因此在一次搜索过程中需要保存的节点数为这个分支的深度,也就是所有物品的数目
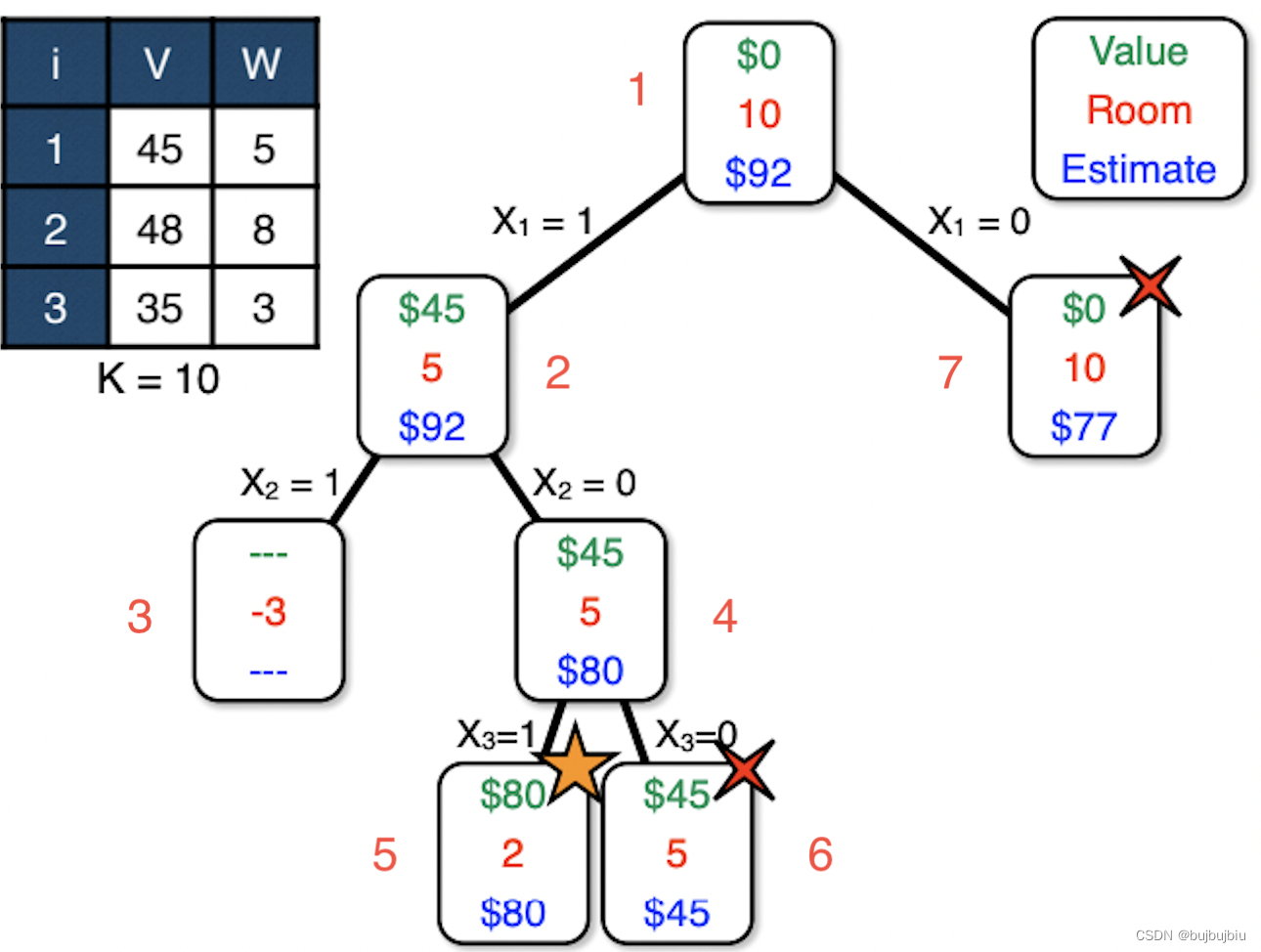
- 过程:顺序红色数字标出,5搜索到解80,7搜索UB=77直接终止
(2)Best-First
- 选择估计值最好的节点
- 什么时候裁剪新分支:all the nodes are worse than a found solution
- 内存:考虑最坏的情况,每次分支最优两边的estimate都一样,这样就需要存储整棵树,非常耗内存
- 过程:顺序红色数字标出,best estimate分别是128,128,83,83,80

(3)Limited Discrepancy Search (LDS)
- 假设有一个启发式规则是branch left,如果branch right代表一次mistake,以mistake次数递增的方式搜索解空间,也就是说越来越不信任这个启发式规则。LDS的wave表示一次搜索过程中可以出现的mistake数,下图为例,wave1表示0个mistake,所有一直left,wave2表示1个mistake,随机选择一次right,其余都是left。可以看到第二个wave都已经探索完了一半的空间。

- 过程:下图中按照wave颜色搜索,在wave2找到了最优解80

- 性能: 时间和空间的选择
7.Getting Started
怎么求解一个优化问题?先用最简单的方法如启发式规则,之后再去改进这个解。比如用约束规划,混合整数规划改进解质量,使用领域搜索提升解的扩展性。有时也会混合使用这些方法。优化问题没有通用的方法,需要尝试各种方法找到最合适的解。

8.Knapsack编程作业
测试规模从4-10000,同时要求时间和质量,最终得分60/60。分别用DP和Gurobi求解,完整代码见本人githubknapsack