目录
3.1 生成 my_train_data.txt和my_val_data.txt
1. 介绍
根据 第一节 的操作,已经生成了下图中圆圈中的部分,而本章的内容就是通过代码生成矩形框中的部分,为后面的工作做准备
- my_yolov3.cfg 是将官方的yolov3-spp.cfg 网络的配置文件根据自定义的数据集修改得到的自己的网络配置(因为检测的分类个数不同,yolo输出的信息也会不同)
- my_train_data.txt 和 my_val_data.txt 是训练集 / 验证集中,所有图片的完整路径,也就是my_yolo_dataset 中 两个 images 下面的所有图片的路径
- my_data.data 是分类个数、my_train_data.txt 和 my_val_data.txt这两个文件的路径、以及my_data_label.names 的路径(如果,一开始数据集就是yolo格式的,就不会经过第一节的操作,也不会生成这个.names文件,所以要自己建立)

2. 完整代码
实现代码为 calculate_dataset.py
"""
该脚本有3个功能:
1.统计训练集和验证集的数据并生成相应.txt文件
2.创建my_data.data文件,记录目标检测的 classes个数, train以及 val数据集文件(.txt)路径和 label.names文件路径
3.根据 yolov3-spp.cfg创建 my_yolov3.cfg文件修改其中的 predictor filters以及 yolo classes参数(这两个参数是根据类别数改变的)
"""
import os
# 生成训练集、验证集的所有数据路径文件
def calculate_data_txt(txt_path, dataset_dir):
with open(txt_path, "w") as w:
for file_name in os.listdir(dataset_dir): # 遍历数据的标注文件train、val下的labels
if file_name == "classes.txt":
continue
# 根据标注文件找到对应的图片,图片后缀需要是jpg
img_path = os.path.join(dataset_dir.replace("labels", "images"),file_name.split(".")[0]) + ".jpg"
line = img_path + "\n" # 写入一个数据路径就换行
assert os.path.exists(img_path), "file:{} not exist!".format(img_path)
w.write(line)
# 创建data.data文件,记录分类类别个数、训练集、验证集、分类类别的文件路径
def create_data_data(create_data_path, train_path, val_path, classes_info):
with open(create_data_path, "w") as w:
w.write("classes={}".format(len(classes_info)) + "\n") # 记录类别个数
w.write("train={}".format(train_path) + "\n") # 记录训练集对应txt文件路径
w.write("valid={}".format(val_path) + "\n") # 记录验证集对应txt文件路径
w.write("names=data/my_data_label.names" + "\n") # 记录label.names文件路径
# 创建yolo v3 spp的配置信息
def change_and_create_cfg_file(classes_info, save_cfg_path="./cfg/my_yolov3.cfg"):
filters_lines = [636, 722, 809]
classes_lines = [643, 729, 816]
cfg_lines = open(cfg_path, "r").readlines()
for i in filters_lines:
assert "filters" in cfg_lines[i-1], "filters param is not in line:{}".format(i-1)
output_num = (5 + len(classes_info)) * 3 # (x,y,w,h+置信度 + 类别的个数) * 每一个cell生成 3 个预测框
cfg_lines[i-1] = "filters={}\n".format(output_num)
for i in classes_lines:
assert "classes" in cfg_lines[i-1], "classes param is not in line:{}".format(i-1)
cfg_lines[i-1] = "classes={}\n".format(len(classes_info))
with open(save_cfg_path, "w") as w:
w.writelines(cfg_lines)
def main():
# 统计训练集和验证集的数据并生成相应 txt文件
train_txt_path = "data/my_train_data.txt"
val_txt_path = "data/my_val_data.txt"
calculate_data_txt(train_txt_path, train_annotation_dir) # 所有训练集的路径
calculate_data_txt(val_txt_path, val_annotation_dir) # 所有验证集的路径
# 获取检测的所有类别
classes_info = [line.strip() for line in open(classes_label, "r").readlines() if len(line.strip()) > 0]
# 创建data.data文件,记录classes个数, train以及val数据集文件(.txt)路径和 label.names文件路径
create_data_data("./data/my_data.data", train_txt_path, val_txt_path, classes_info)
# 根据yolov3-spp.cfg创建my_yolov3.cfg文件修改其中的predictor filters以及yolo classes参数(这两个参数是根据类别数改变的)
change_and_create_cfg_file(classes_info)
if __name__ == '__main__':
train_annotation_dir = "./my_yolo_dataset/train/labels" # 训练集的标注文件
val_annotation_dir = "./my_yolo_dataset/val/labels" # 验证集的标注文件
classes_label = "./data/my_data_label.names" # 检测的分类label
cfg_path = "./cfg/yolov3-spp.cfg" # 官方的yolov3-spp 的配置文件
assert os.path.exists(train_annotation_dir), "train_annotation_dir not exist!"
assert os.path.exists(val_annotation_dir), "val_annotation_dir not exist!"
assert os.path.exists(classes_label), "classes_label not exist!"
assert os.path.exists(cfg_path), "cfg_path not exist!"
main()
3. 代码讲解
代码有些部分自己又加了些注释,这里会挑着讲解
首先将相关路径设定好

3.1 生成 my_train_data.txt和my_val_data.txt
然后生成数据集图片的路径,这里训练集和测试集一样,只讲解训练集

对于训练集来说,写入my_train_data.txt 文件。

其中,file_name 就是labels 下面文件名,因为这里文件名就是图片的名称。通过路径替换就能、后缀替换就可以找到images所有的图片完整路径,写入my_train_data.txt 文件即可
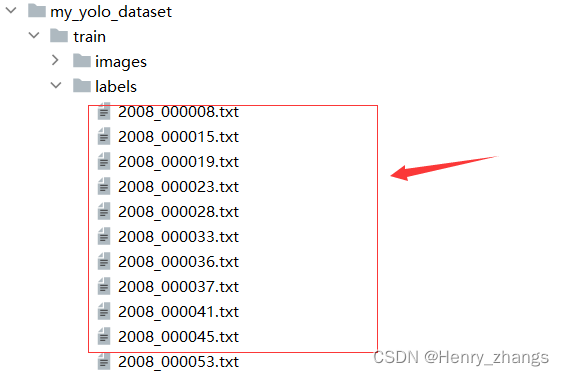
生成的my_train_data.txt 和my_val_data.txt 如下:

3.2 生成 my_data.data 文件
代码如下

其中,classes_info 信息如下:['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] ,其实就是分类的名称
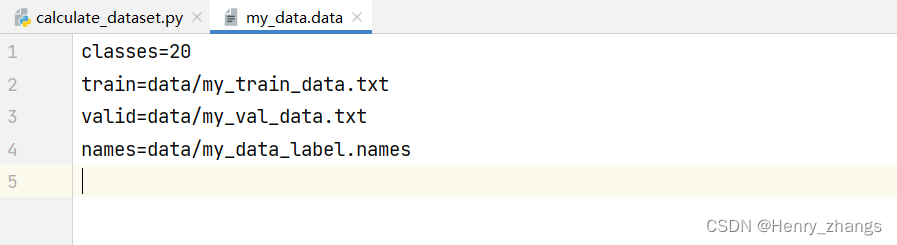
然后,进入create_data_data 函数内部,将对应的文件路径写入即可

my_data.data 文件
3.3 生成 my_yolov3.cfg
因为不同检测任务的分类个数可能不同,因此需要更改yolo的配置信息

实现的方式如下:
因为yolo输出是三个尺度的,而 filters_lines = [636, 722, 809] classes_lines = [643, 729, 816]就是对应三个尺度的信息。除了检测的类别更改自定义数据集的类别个数外。预测框输出的tensor也和类别有关
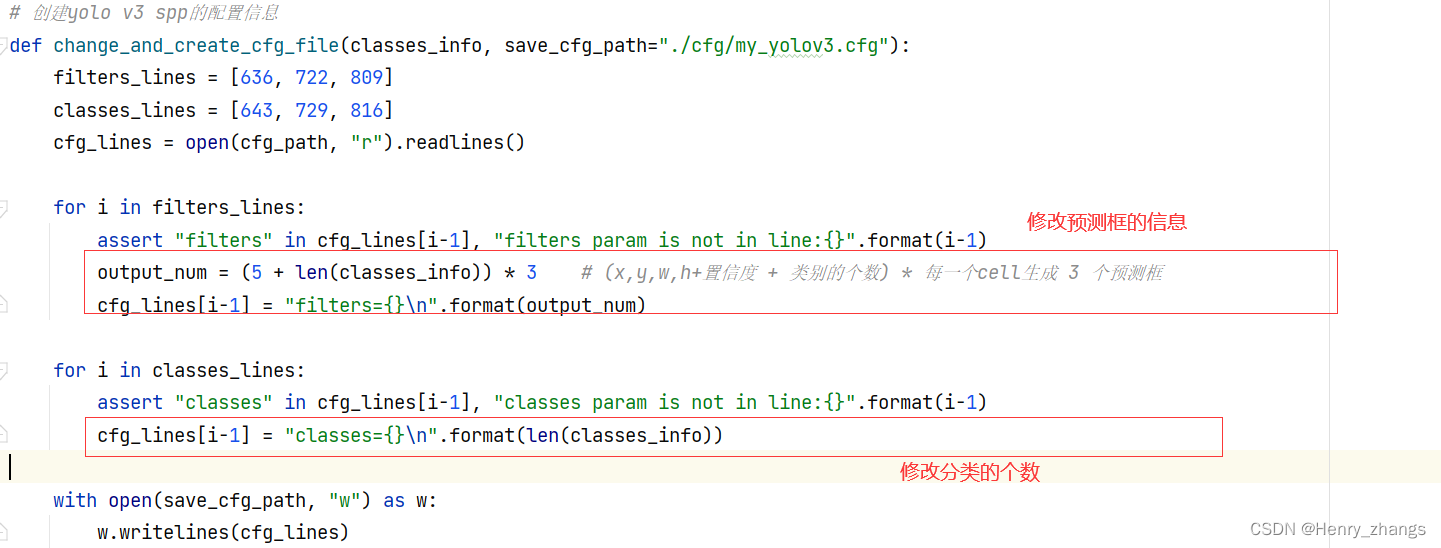
如下,官方的classes 是coco所以是80类别。这里使用的是pascal voc 所以是20类别
75 = (x、y、w、h+置信度 + 类别个数)* 3(每一个cell生成3个预测框) = 25 * 3
官方是 (5 + 80)*3 = 255

3.4 关于my_data_label.names文件
如果本身就是yolo 数据集的话,是不需要进行第一节的操作的
那么这个文件my_data_label.names是不存在的,需要手工建立,如下:
只需要更改文件名就行了
