YOLO v3文章地址:YOLOv3: An Incremental Improvement
v3相对于v2的主要改进:
- 1. 特征提取器更深(参考ResNet)
- 2. 多尺度预测 (类似FPN)
- 3. Bounding Box和Loss
1. 特征提取器(分类器)
V3的特征提取器在V2的Darknet-19基础上做了优化,命名为Darknet-53。包含52层卷积层和1个全连接层,加入了多个连续的3×3和1×1的卷积,借鉴了ResNet网络结构,增加直接连接(shortcut connections),并且网络层数达到53层,简易框架:
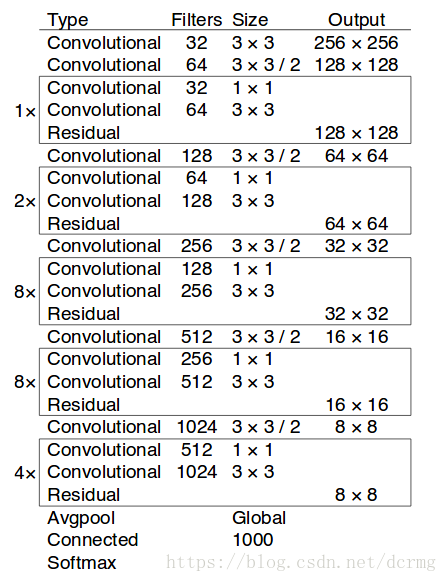
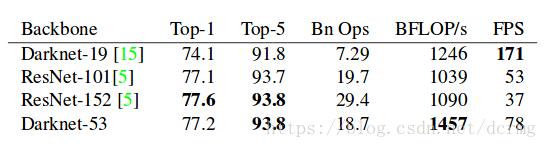
Darknet53和Darknet19、ResNet在ImageNet上的效果对比:
2. 多尺度预测
在结果的预测上,v2只用了一个尺度,v3使用了3个尺度。分别是一个下采样的,feature map为13*13,还有2个上采样的eltwise sum,feature map为26*26,52*52,也就是说v3的416版本已经用到了52的feature map,而v2把多尺度考虑到训练的data采样上,最后也只是用到了13的feature map,这应该是对小目标影响最大的地方。
每个位置预测3个bbox(4个位置输出+1个objectness+C个类别的分数),在v2中会预测5个bbox。所以每个位置输出(1+4+C)*3个值,这也就是训练时yolov3.cfg里的filter的数量。这也就是每个尺度张量的深度。
3. Bounding Box的预测和Loss
边界框的预测跟V2中一样,仍使用维度聚类方法,先在样本上使用K-means聚类得到Anchor Boxes(v2中使用了5个,v3中使用了9个)。使用逻辑回归而不是Softmax对每个框进行分类,这是考虑到自然场景图像中物体之间重叠很常见,使用Softmax在每一个框上只能给出最大的类别,导致重叠的漏检,使用多个单独的逻辑回归(主要用到了sigmoid函数)预测替代了之前的Softmax分类。