目录
2. 关于PASCAL VOC数据集xml --> YOLO txt格式
代码参考是b站的大佬:3.2 YOLOv3 SPP源码解析(Pytorch版)
PASCAL VOC数据集的链接:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/


转换之后的yolo格式数据集分为两个,一个太大了,没法上传
训练集:PASCAL VOC 目标检测的yolo格式之训练集
验证集:PASCAL VOC 目标检测的yolo格式之验证集
1. 前言
目标检测的label文件和分类、分割都不相同。一般来说,分类任务中,相同类别的图片放在同一个目录下,文件名的索引就是分类的名称。而分割任务中,不同的训练图像对应的是不同的多阈值图像,即训练是图像,label也是图像
目标检测的label分为两个,一个是待检测目标的类别,例如猫啊、狗啊等等。另一个是目标的位置,用边界框来标注,经常是xmin、xman、ymin、ymax的矩形框。
通常,目标检测的标签是用xml 文件标注的
例如,下方的object里面,就有horse和person两个类别,对应类别的下方有四个参数就是边界框的信息

而yolo算法导致这样的xml 不满足 yolo的格式,所以需要一个xml转yolo格式的操作
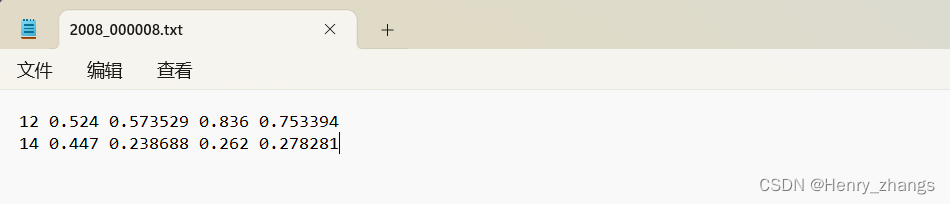
如下,12 指的是检测的类别,后面四个参数是x、y、w、h边界框的信息
yolo 边界框是根据边界框中心坐标、w、h相对于整幅图像而言的
2. 关于PASCAL VOC数据集xml --> YOLO txt格式
本章只完成数据转换的工作
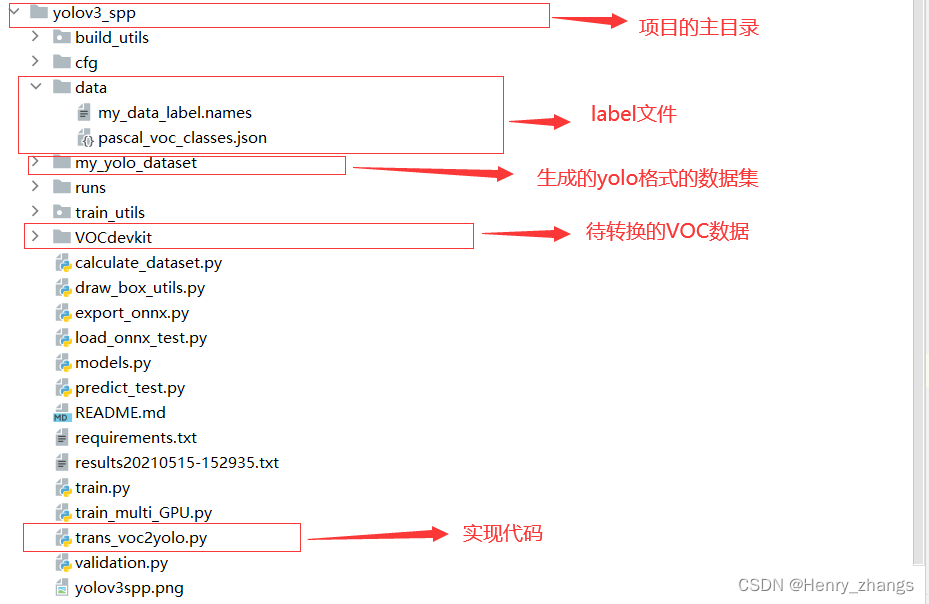
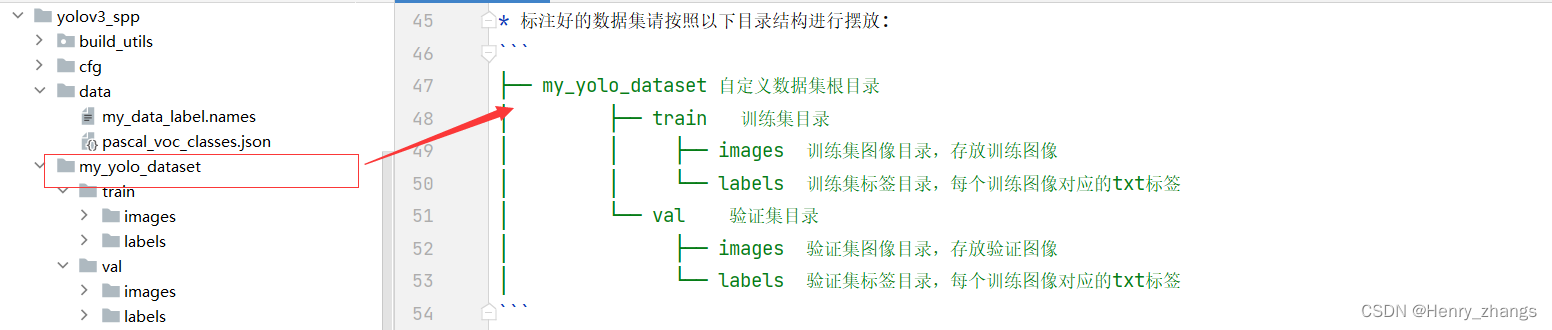
一开始,my_yolo_dataset 和my_data_label.names 是没有的,是由trans_voc2yolo.py 将VOCdevkit的数据转换才生成的两个文件
2.1 路径设定
VOC 数据集是分开的,用于不同的任务,这里只针对目标检测任务
- Annotations 放目标检测的xml 标签文件
- train.txt、val.txt 放训练集和验证集的 文件名(只有文件名,不包含后缀,也不是绝对路径)
- JPEGImages 放所有VOC的图片
2.2 读取xml 文件的函数
如下:
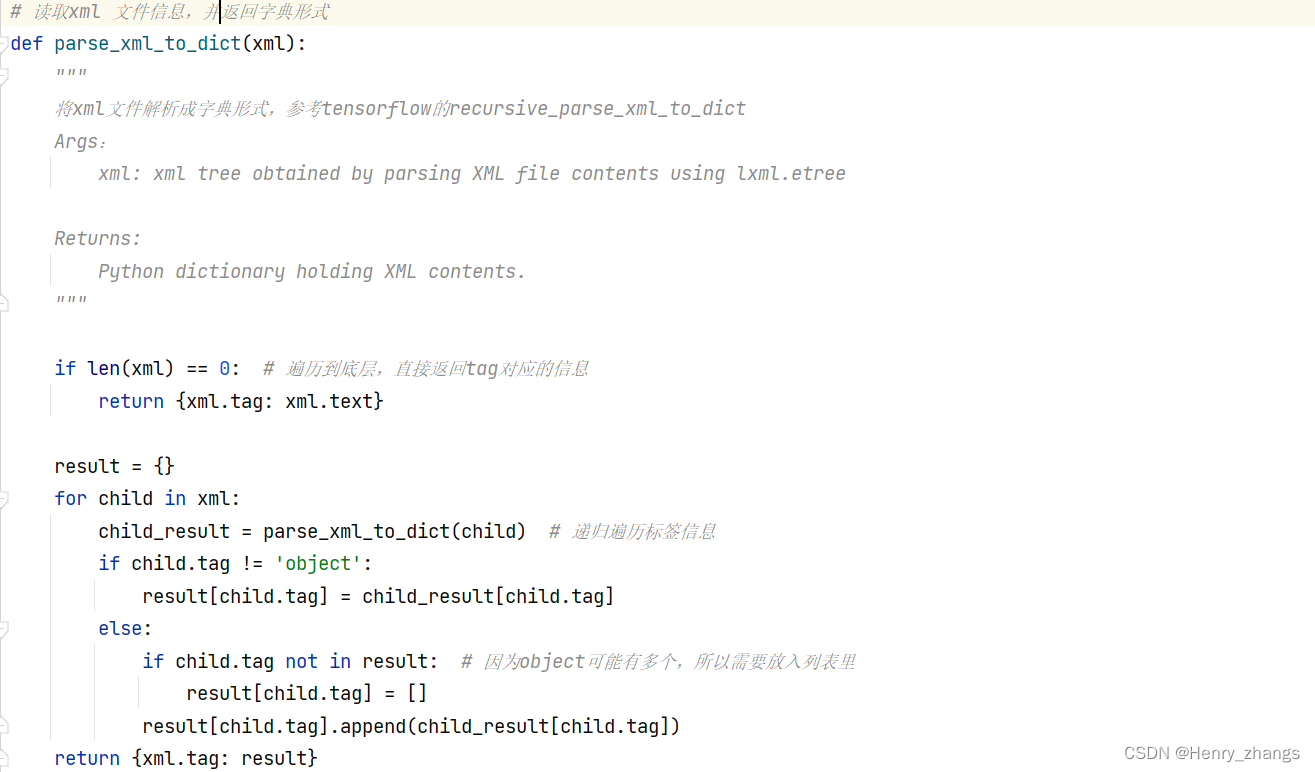
这里的代码用的递归实现,没怎么看懂,知道怎么用就行了
下面是读取一个xml文件,返回的字典信息
{'annotation': {'folder': 'VOC2012', 'filename': '2008_000008.jpg', 'source': {'database': 'The VOC2008 Database', 'annotation': 'PASCAL VOC2008', 'image': 'flickr'}, 'size': {'width': '500', 'height': '442', 'depth': '3'}, 'segmented': '0', 'object': [{'name': 'horse', 'pose': 'Left', 'truncated': '0', 'occluded': '1', 'bndbox': {'xmin': '53', 'ymin': '87', 'xmax': '471', 'ymax': '420'}, 'difficult': '0'}, {'name': 'person', 'pose': 'Unspecified', 'truncated': '1', 'occluded': '0', 'bndbox': {'xmin': '158', 'ymin': '44', 'xmax': '289', 'ymax': '167'}, 'difficult': '0'}]}}
2.3 xml ---> yolo txt
这部分比较重要,一点一点看
注意框中的部分,因为 parse_xml_to_dict 返回的是字典,而最先的key是annotation,所以data先将它取出来


然后遍历key为object下面的边界框
注意这里的index是索引,从0开始。这里是第一个index和obj的值
![]()
最后将边界框转为中心点坐标宽度和高度,然后再改为整幅图像的相对值就行了

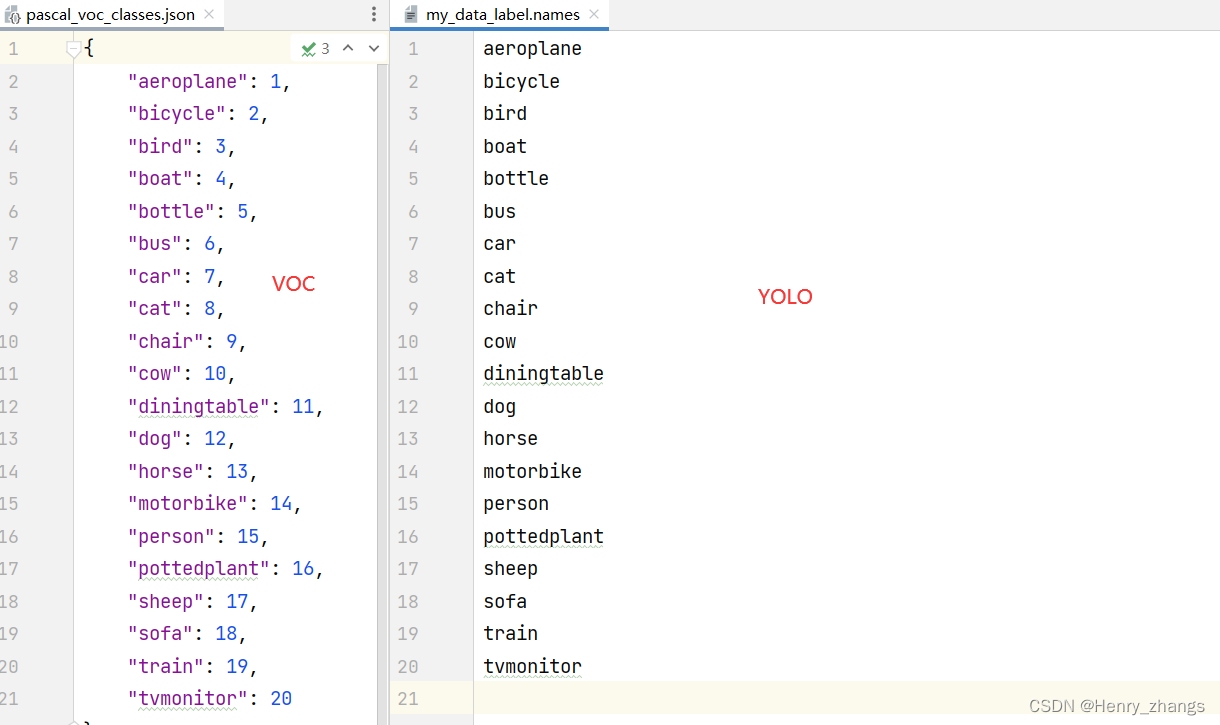
2.4 yolo 的label文件
实现代码如下:

这里也很简单,就是将VOC的key取出,然后存放即可
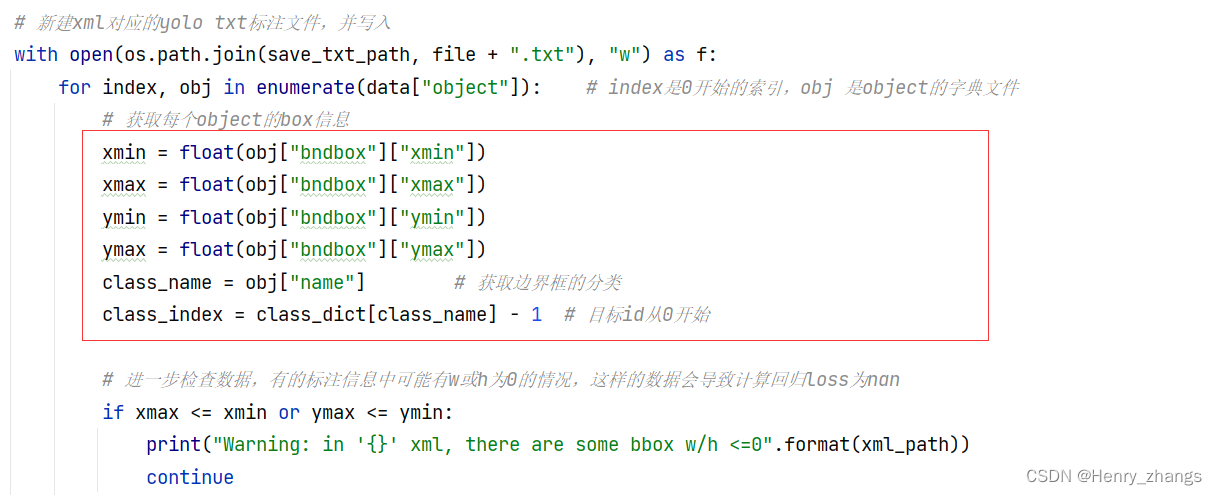
2.6 结果
运行过程如下

生成的yolo 数据集目录如下:
yolo 的label信息:
2.7 代码
转换的代码如下:
"""
本脚本有两个功能:
1.将voc数据集标注信息(.xml)转为yolo标注格式(.txt),并将图像文件复制到相应文件夹
2.根据json标签文件,生成对应names标签(my_data_label.names)
"""
import os
from tqdm import tqdm
from lxml import etree
import json
import shutil
# 读取xml 文件信息,并返回字典形式
def parse_xml_to_dict(xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
# 将xml文件转换为yolo的 txt文件
def translate_info(file_names: list, save_root: str, class_dict: dict, train_val='train'):
"""
:param file_names: 所有训练集/验证集 图片的路径
:param save_root: 带保持的对应的 yolo 文件
:param class_dict: voc 数据的json 标签
:param train_val: 判断传入的是训练集还是验证集
"""
save_txt_path = os.path.join(save_root, train_val, "labels") # 保存yolo的 txt 标注文件
if os.path.exists(save_txt_path) is False:
os.makedirs(save_txt_path)
save_images_path = os.path.join(save_root, train_val, "images") # 保存yolo 的训练图像文件
if os.path.exists(save_images_path) is False:
os.makedirs(save_images_path)
for file in tqdm(file_names, desc="translate {} file...".format(train_val)):
# 检查下图像文件是否存在
img_path = os.path.join(voc_images_path, file + ".jpg")
assert os.path.exists(img_path), "file:{} not exist...".format(img_path)
# 检查xml文件是否存在
xml_path = os.path.join(voc_xml_path, file + ".xml")
assert os.path.exists(xml_path), "file:{} not exist...".format(xml_path)
# read xml
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = parse_xml_to_dict(xml)["annotation"] # 读取xml文件信息
img_height = int(data["size"]["height"]) # 读入图像的 h
img_width = int(data["size"]["width"]) # 读入图像的 w
# 判断该xml 是否有 ground truth
assert "object" in data.keys(), "file: '{}' lack of object key.".format(xml_path)
if len(data["object"]) == 0:
# 如果xml文件中没有目标,返回该图片路径,然后忽略该样本
print("Warning: in '{}' xml, there are no objects.".format(xml_path))
continue
# 新建xml对应的yolo txt标注文件,并写入
with open(os.path.join(save_txt_path, file + ".txt"), "w") as f:
for index, obj in enumerate(data["object"]): # index是0开始的索引,obj 是object的字典文件
# 获取每个object的box信息
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
class_name = obj["name"] # 获取边界框的分类
class_index = class_dict[class_name] - 1 # 目标id从0开始
# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为nan
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
# 将box信息转换到 yolo格式
xcenter = xmin + (xmax - xmin) / 2 # 中心点坐标
ycenter = ymin + (ymax - ymin) / 2
w = xmax - xmin # 边界框的 w 和 h
h = ymax - ymin
# 绝对坐标转相对坐标,保存6位小数
xcenter = round(xcenter / img_width, 6)
ycenter = round(ycenter / img_height, 6)
w = round(w / img_width, 6)
h = round(h / img_height, 6)
info = [str(i) for i in [class_index, xcenter, ycenter, w, h]]
if index == 0:
f.write(" ".join(info))
else: # 自动换行
f.write("\n" + " ".join(info))
# 复制图像到对应的集
path_copy_to = os.path.join(save_images_path, img_path.split(os.sep)[-1])
if os.path.exists(path_copy_to) is False:
shutil.copyfile(img_path, path_copy_to)
# 创建yolo 的 label文件
def create_class_names(class_dict: dict):
keys = class_dict.keys()
with open("./data/my_data_label.names", "w") as w:
for index, k in enumerate(keys):
if index + 1 == len(keys):
w.write(k)
else:
w.write(k + "\n")
def main():
# 读取原先的voc数据的json label文件
json_file = open(label_json_path, 'r')
class_dict = json.load(json_file)
# 读取voc数据集所有训练集路径文件 train.txt中的所有行信息,删除空行
with open(train_txt_path, "r") as r:
train_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]
# voc信息转 yolo,并将图像文件复制到相应文件夹
translate_info(train_file_names, save_file_root, class_dict, "train")
# 读取voc数据集所有验证集路径文件 val.txt中的所有行信息,删除空行
with open(val_txt_path, "r") as r:
val_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]
# voc信息转yolo,并将图像文件复制到相应文件夹
translate_info(val_file_names, save_file_root, class_dict, "val")
# 创建my_data_label.names文件
create_class_names(class_dict)
if __name__ == "__main__":
# voc数据集根目录以及版本
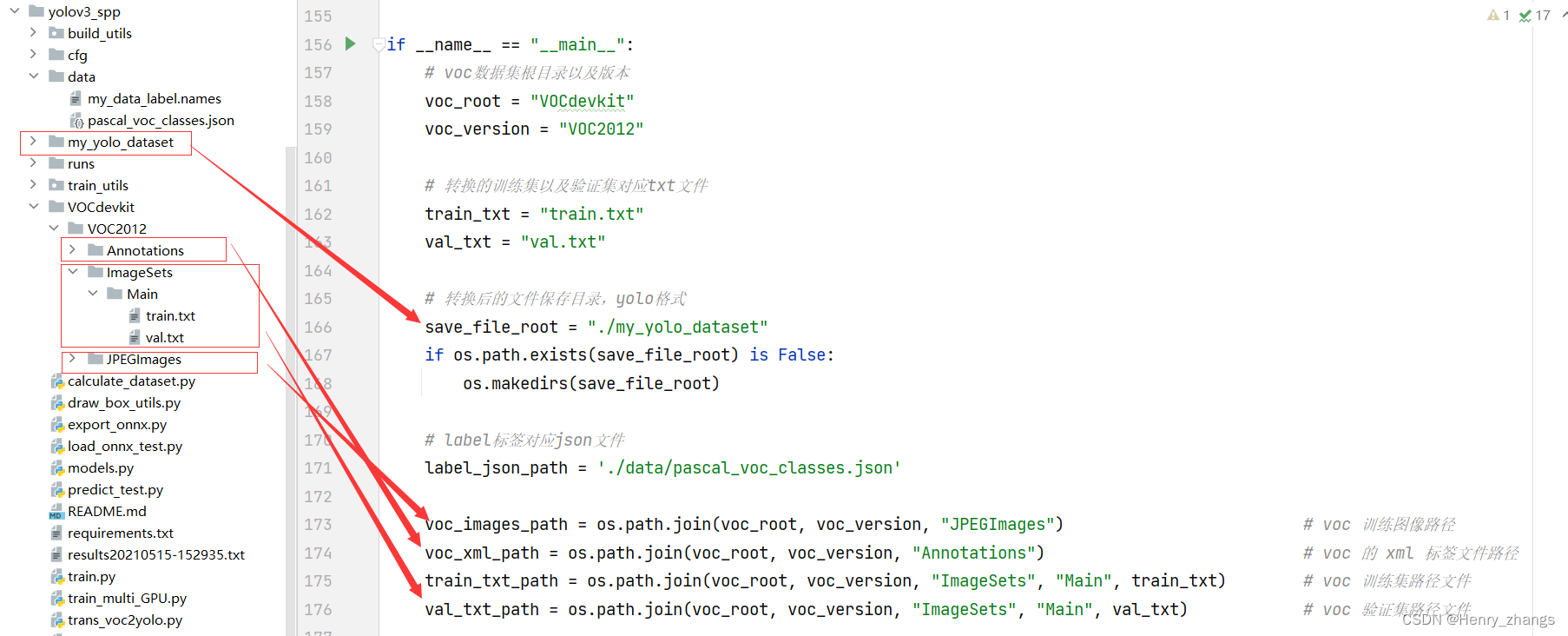
voc_root = "VOCdevkit"
voc_version = "VOC2012"
# 转换的训练集以及验证集对应txt文件
train_txt = "train.txt"
val_txt = "val.txt"
# 转换后的文件保存目录,yolo格式
save_file_root = "./my_yolo_dataset"
if os.path.exists(save_file_root) is False:
os.makedirs(save_file_root)
# label标签对应json文件
label_json_path = './data/pascal_voc_classes.json'
voc_images_path = os.path.join(voc_root, voc_version, "JPEGImages") # voc 训练图像路径
voc_xml_path = os.path.join(voc_root, voc_version, "Annotations") # voc 的 xml 标签文件路径
train_txt_path = os.path.join(voc_root, voc_version, "ImageSets", "Main", train_txt) # voc 训练集路径文件
val_txt_path = os.path.join(voc_root, voc_version, "ImageSets", "Main", val_txt) # voc 验证集路径文件
# 检查文件/文件夹都是否存在
assert os.path.exists(voc_images_path), "VOC images path not exist..."
assert os.path.exists(voc_xml_path), "VOC xml path not exist..."
assert os.path.exists(train_txt_path), "VOC train txt file not exist..."
assert os.path.exists(val_txt_path), "VOC val txt file not exist..."
assert os.path.exists(label_json_path), "label_json_path does not exist..."
# 开始转换
main()
3. 自定义 YOLO 数据集
这里用的是labelimg,安装如下
pip install labelimg终端输入 labelimg 即可进入,界面如下:

3.1 预备工作
新建一个demo 文件夹,下面存放这三个文件
- annotation 是保存的yolo 边界框文件
- img 是图片
- labels.txt 是label文件
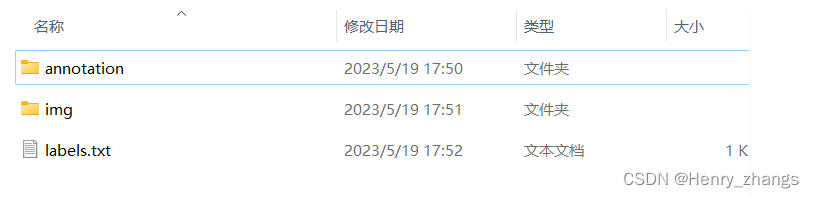
label存放如下:
3.2 打开labelimg
在demo中打开终端,第一个参数是图像的文件夹,第二个是labels的路径

3.3 绘制
打开后会这么显示,首先要将保存的格式改成yolo的。然后将save dir选中annotation文件夹
右边是img有的文件,这里放置两张图像

绘制的时候,选中哪个类别就行了

最后结果就是这样
