目录
1. 介绍
根据 第二节 的步骤,生成了属于自己的 my_yolov3.cfg 配置文件,本章将介绍yolo 配置文件的内容以及如何读取配置文件

部分的yolo配置文件如下:

2. 关于yolo的cfg网络配置文件
因为搭建网络的时候,是根据配置文件cfg逐步实现的,因此理解 cfg网络配置文件也很重要
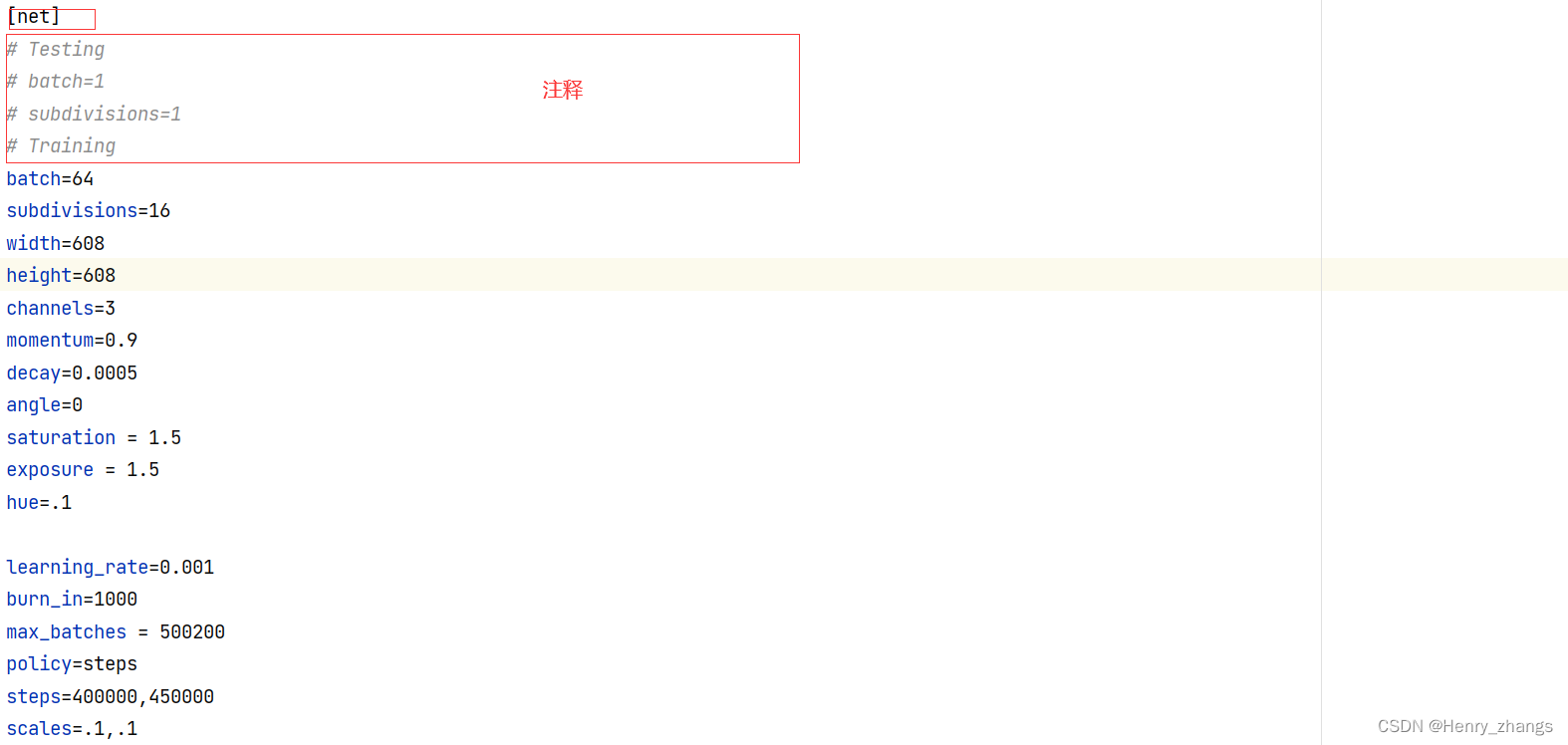
首先,关于net部分是用于训练的相关配置,这里用不到
TIPS : cfg 配置文件里面的内容不要做更改,因为固定的行号是确定的。删除了一个空格的话,索引的行号就对不上了
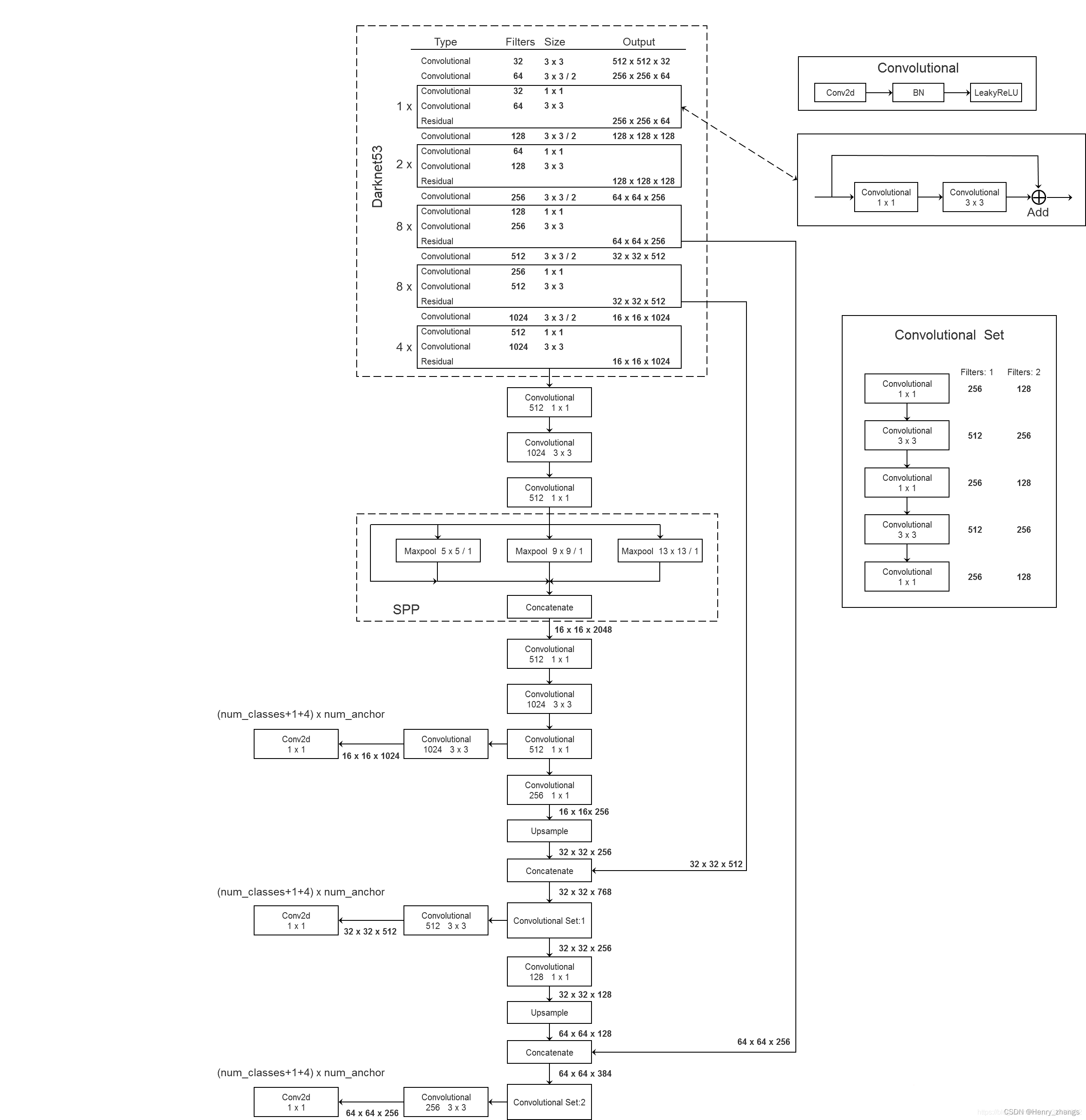
yolo v3 spp 网络如下:
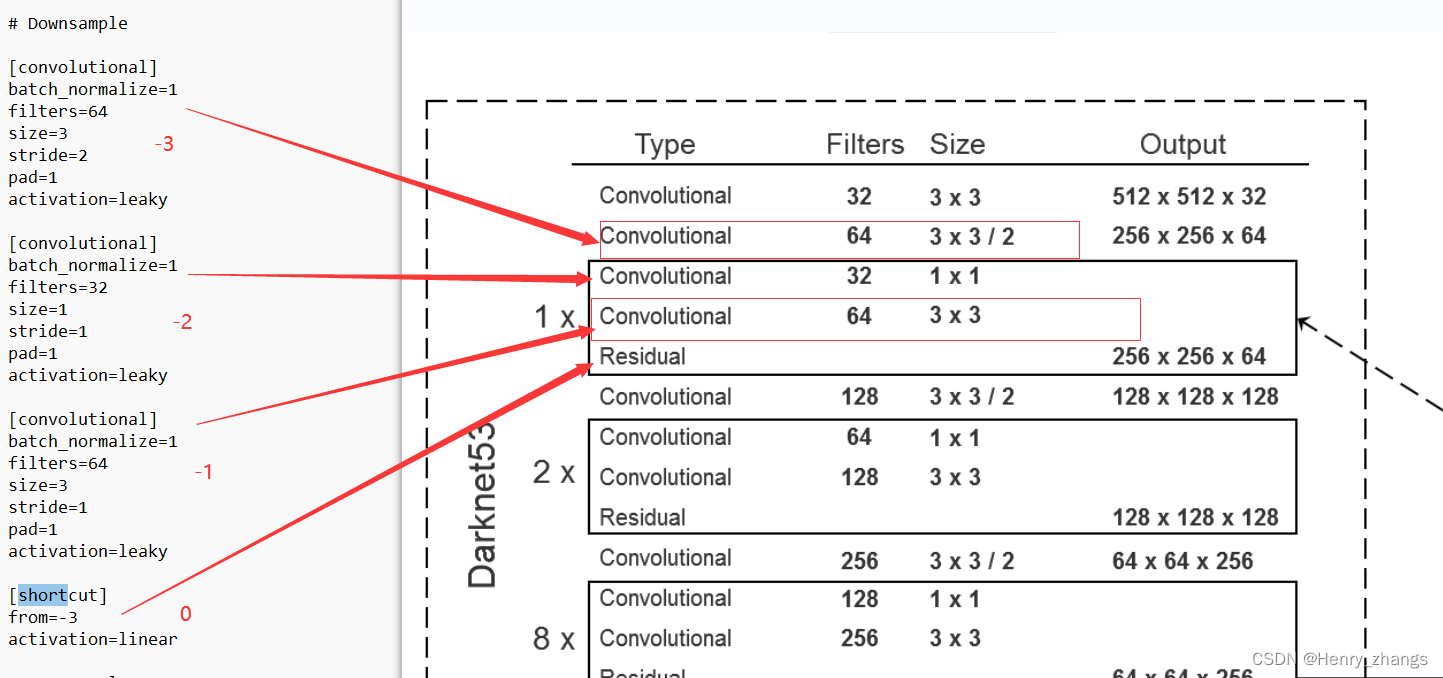
2.1 关于卷积层
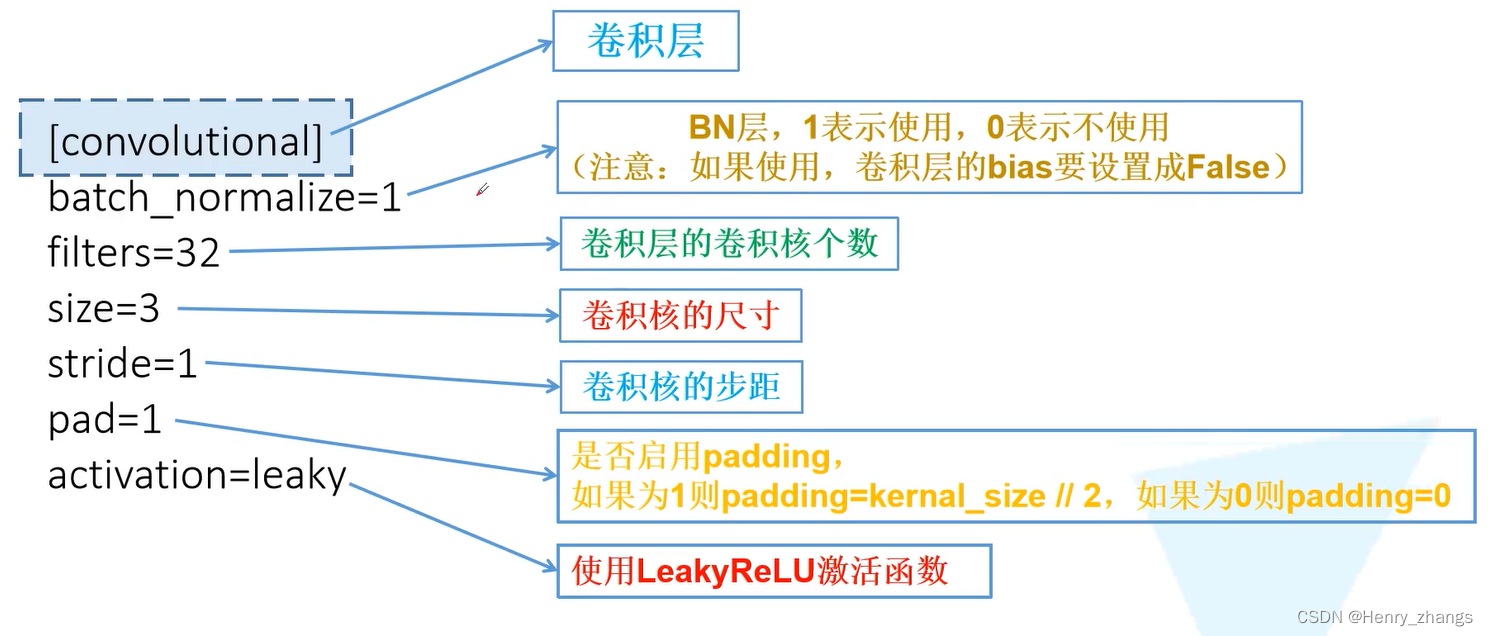
卷积层的开始是:[convolutional]
其中,batch_normalize和pad的1代表是否使用这两个参数,为1代表使用
2.2 关于池化层
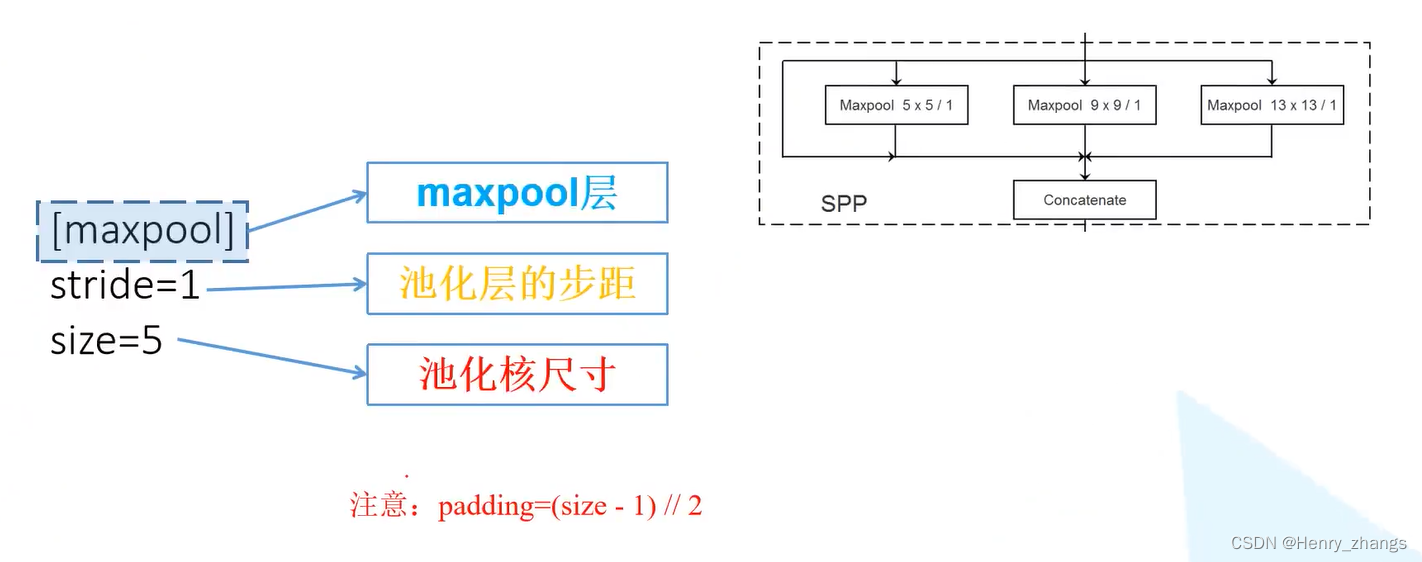
池化层的开始是:[maxpool]
yolo v3 spp中,只有 SPP用maxpool操作,为了实现concatenate 操作,所以要保证shape相同,因此padding 的设定就是为了这个
yolo v3 spp 下采样用卷积 stride = 2实现
2.3 关于捷径分支shortcut
捷径分支shortcut的开始是:[shortcut]
-3 代表,前面-3的输出和自己相加
shortcut 是指两个不同信息的shape相同,再相加的操作
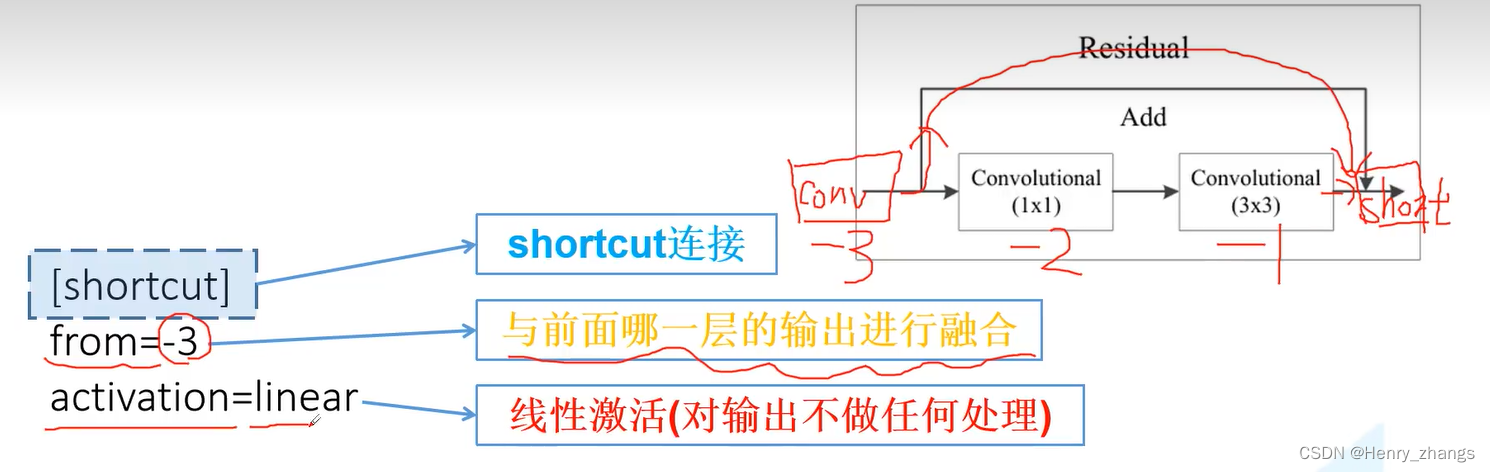
如图所示,第一个residual就是两个矩形框的输出相加
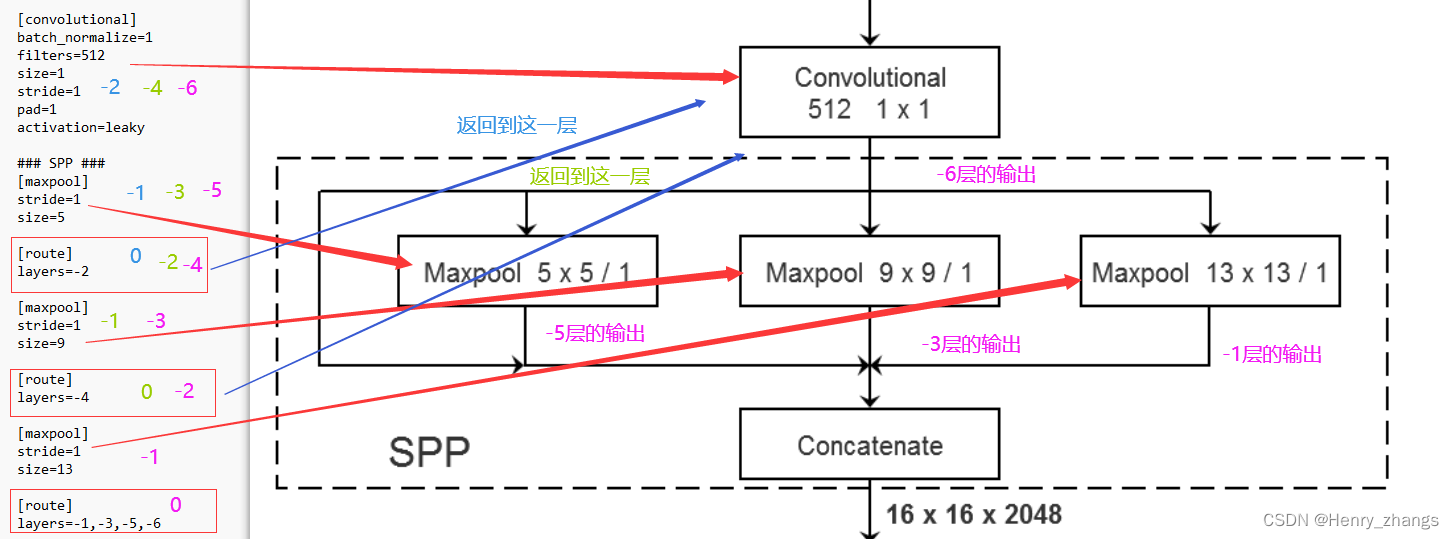
2.4 关于route 层
route层的开始是:[route]
spp 中,需要多个信息的融合,所以route层也很重要
route 的实现类似于指针

具体的如下:
当route 只有一个值的时候,可以理解为一个指针,返回对应的层结构
当route 有多个值的时候,将对应的输出拼接
concatenate 代表在 channel 维度堆起来
2.5 关于上采样层
上采样层的开始是:[upsample]
将图像的w和h扩大两倍

2.6 关于yolo层
yolo层的开始是:[yolo]
yolo 层并不在 spp 的网络图中,是3个尺度的后处理
前三组是小目标的anchor ,以此类推

3. 解析cfg 文件
代码是 parse_config.py
首先,先读取cfg的文件,去掉空格和注释

lines 的部分内容为,这里每样保留了一个方便观看:
[
'[net]', 'batch=64', 'subdivisions=16', 'width=608', 'height=608', 'channels=3', 'momentum=0.9', 'decay=0.0005', 'angle=0', 'saturation = 1.5', 'exposure = 1.5', 'hue=.1', 'learning_rate=0.001', 'burn_in=1000', 'max_batches = 500200', 'policy=steps', 'steps=400000,450000', 'scales=.1,.1',
'[convolutional]', 'batch_normalize=1', 'filters=32', 'size=3', 'stride=1', 'pad=1', 'activation=leaky',
'[shortcut]', 'from=-3', 'activation=linear',
'[maxpool]', 'stride=1', 'size=5',
'[route]', 'layers=-2',
'[route]', 'layers=-1,-3,-5,-6',
'[upsample]', 'stride=2',
'[yolo]', 'mask = 6,7,8', 'anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326', 'classes=20', 'num=9', 'jitter=.3', 'ignore_thresh = .7', 'truth_thresh = 1', 'random=1'
]
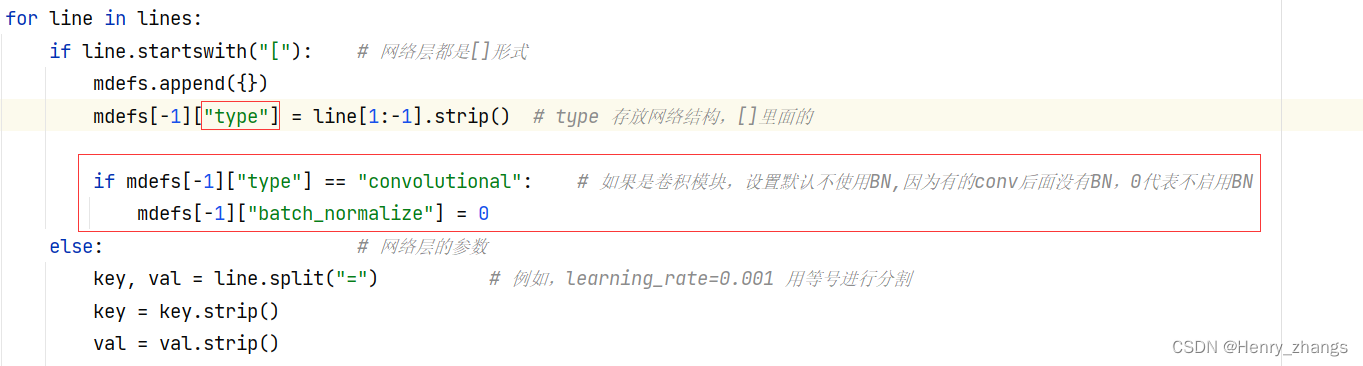
type 存放网络的结构,后面跟着对应的配置,存放在一个字典中
需要注意的是,有的卷积后面不跟BN层,所以矩形框里面的内容不可忽略。因为大部分conv后面有BN,虽然设定为0,后面也会被替换成本来的值
后面是对key的相关操作,key是 = 之前的东西,val是 = 后面的东西,这里主要是将 = 后面的val 数值变成int或者float类型,因为默认读取的val是str类型

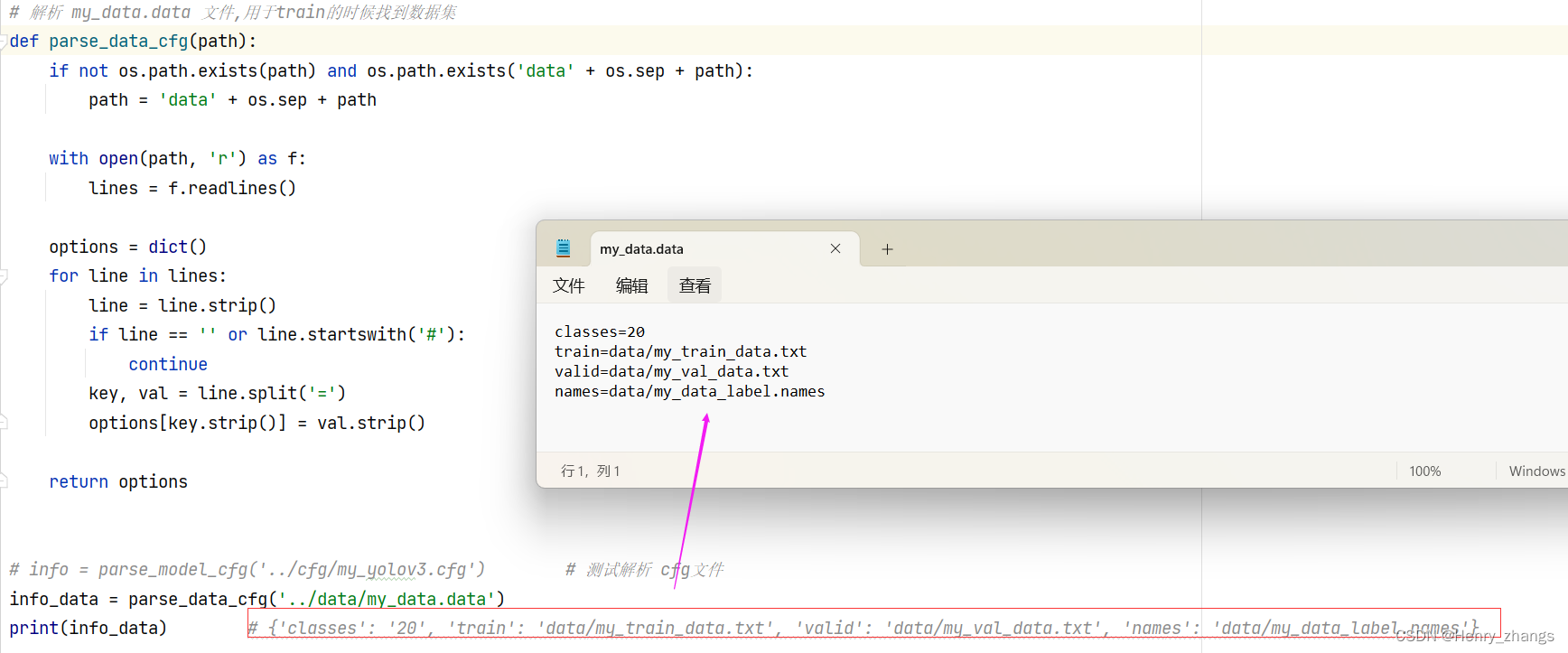
parse_config.py 代码中,还有一个是解析my_data.data 文件的,具体效果如下:
4. 代码
parse_config.py 的代码为:
# 解析网络中的配置文件
import os
import numpy as np
# 解析 my_yolov3.cfg 文件
def parse_model_cfg(path: str):
if not path.endswith(".cfg") or not os.path.exists(path): # 检查文件是否存在
raise FileNotFoundError("the cfg file not exist...")
# 读取文件信息
with open(path, "r") as f:
lines = f.read().split("\n")
lines = [x for x in lines if x and not x.startswith("#")] # 去除空行和注释行
lines = [x.strip() for x in lines] # 去除每行开头和结尾的空格符
mdefs = [] # module definitions
for line in lines:
if line.startswith("["): # 网络层都是[]形式
mdefs.append({})
mdefs[-1]["type"] = line[1:-1].strip() # type 存放网络结构,[]里面的
if mdefs[-1]["type"] == "convolutional": # 如果是卷积模块,设置默认不使用BN,因为有的conv后面没有BN,0代表不启用BN
mdefs[-1]["batch_normalize"] = 0
else: # 网络层的参数
key, val = line.split("=") # 例如,learning_rate=0.001 用等号进行分割
key = key.strip()
val = val.strip()
# yolo 层
if key == "anchors":
val = val.replace(" ", "") # 将空格去除
mdefs[-1][key] = np.array([float(x) for x in val.split(",")]).reshape((-1, 2)) # (9,2) anchor
# 特殊结构
elif key in ["from", "layers", "mask"]:
mdefs[-1][key] = [int(x) for x in val.split(",")]
# 常见的正常网络参数
else:
if val.isnumeric(): # return int or float 如果是数值的情况
mdefs[-1][key] = int(val) if (int(val) - float(val)) == 0 else float(val)
else:
mdefs[-1][key] = val # return string 是字符的情况
# check all fields are supported
supported = ['type', 'batch_normalize', 'filters', 'size', 'stride', 'pad', 'activation', 'layers', 'groups',
'from', 'mask', 'anchors', 'classes', 'num', 'jitter', 'ignore_thresh', 'truth_thresh', 'random',
'stride_x', 'stride_y', 'weights_type', 'weights_normalization', 'scale_x_y', 'beta_nms', 'nms_kind',
'iou_loss', 'iou_normalizer', 'cls_normalizer', 'iou_thresh', 'probability']
# 遍历检查每个模型的配置
for x in mdefs[1:]: # 0对应 net配置
# 遍历每个配置字典中的key值
for k in x:
if k not in supported:
raise ValueError("Unsupported fields:{} in cfg".format(k))
return mdefs
# 解析 my_data.data 文件,用于train的时候找到数据集
def parse_data_cfg(path):
if not os.path.exists(path) and os.path.exists('data' + os.sep + path):
path = 'data' + os.sep + path
with open(path, 'r') as f:
lines = f.readlines()
options = dict()
for line in lines:
line = line.strip()
if line == '' or line.startswith('#'):
continue
key, val = line.split('=')
options[key.strip()] = val.strip()
return options
# info = parse_model_cfg('../cfg/my_yolov3.cfg') # 测试解析 cfg文件
# info_data = parse_data_cfg('../data/my_data.data')
# print(info_data) # {'classes': '20', 'train': 'data/my_train_data.txt', 'valid': 'data/my_val_data.txt', 'names': 'data/my_data_label.names'}