CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention(CVPR 2023)

标题:Slide-Transformer:具有局部自注意力的分层视觉变换器
作者:Xuran Pan, Tianzhu Ye, Zhuofan Xia, Shiji Song, Gao Huang
文章链接:https://arxiv.org/abs/2302.02814
项目代码:https://github.com/LeapLabTHU/Slide-Transformer
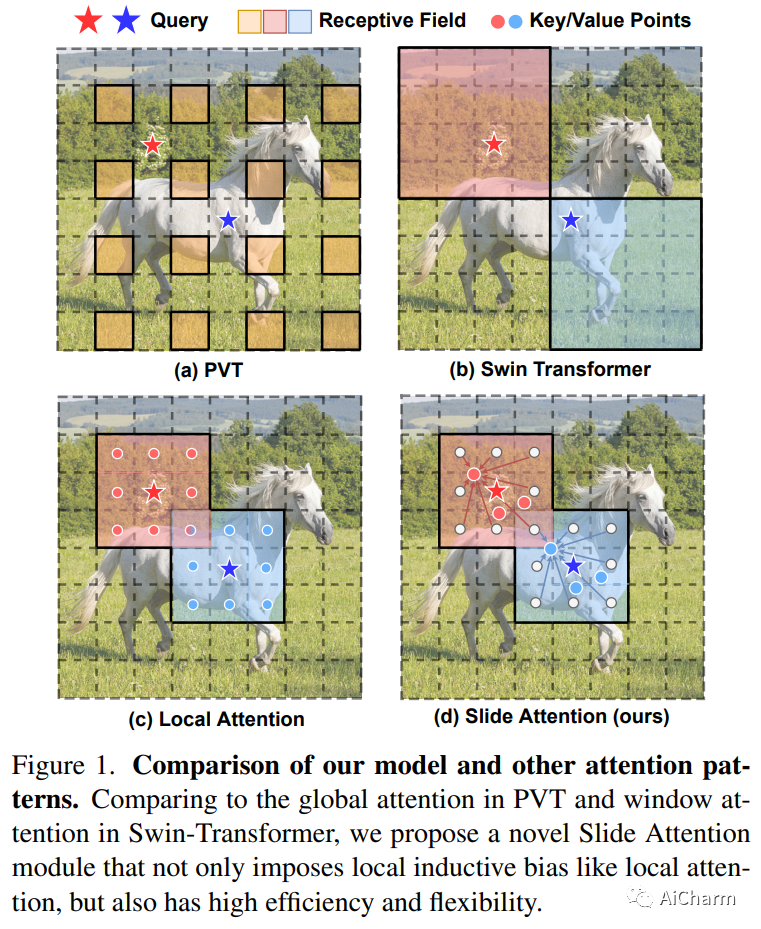
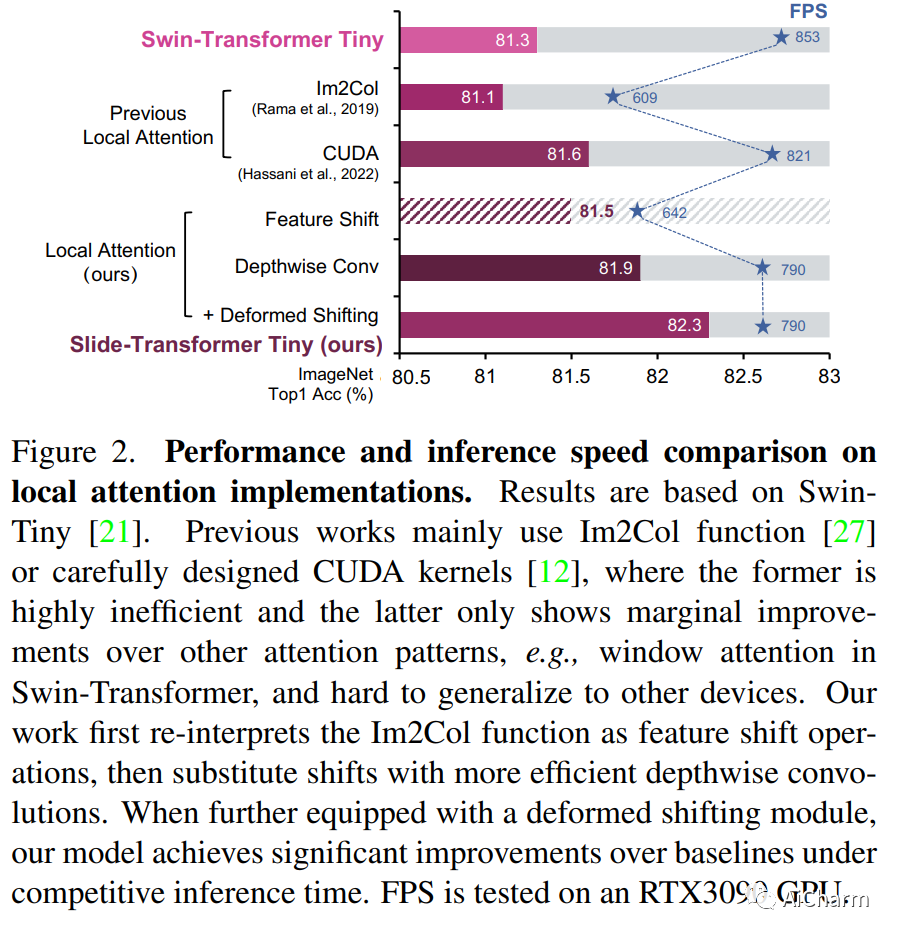
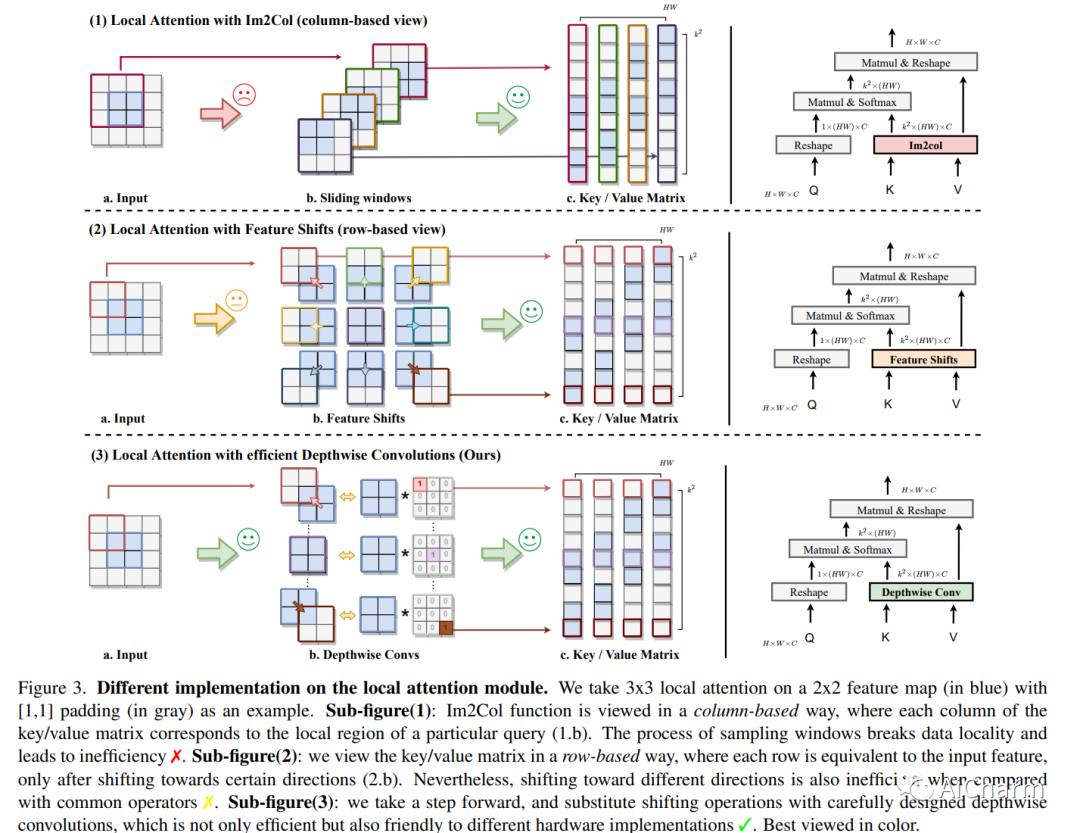
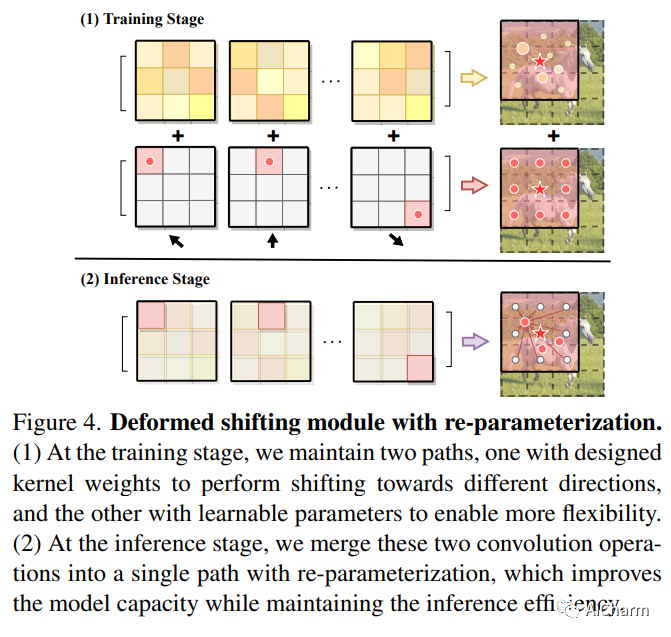
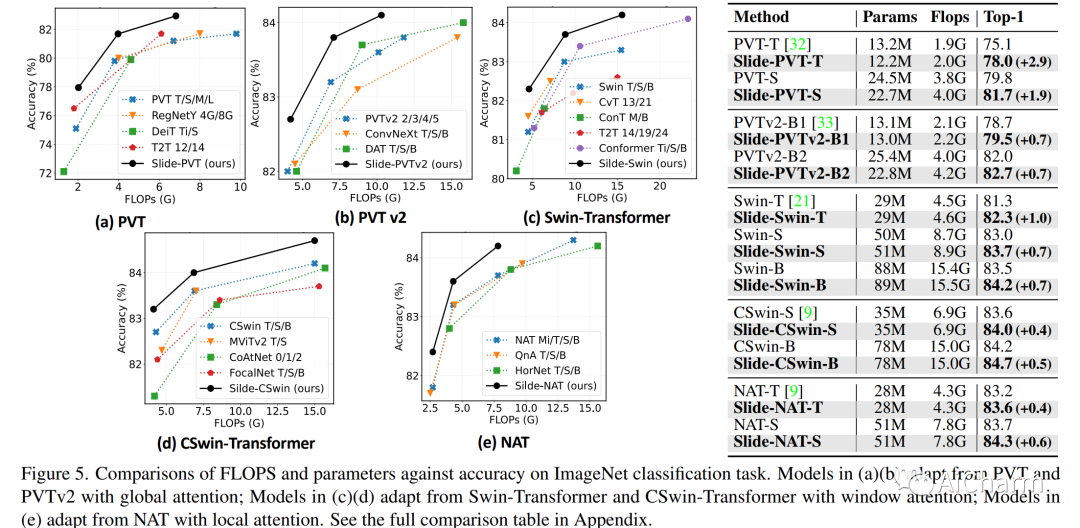
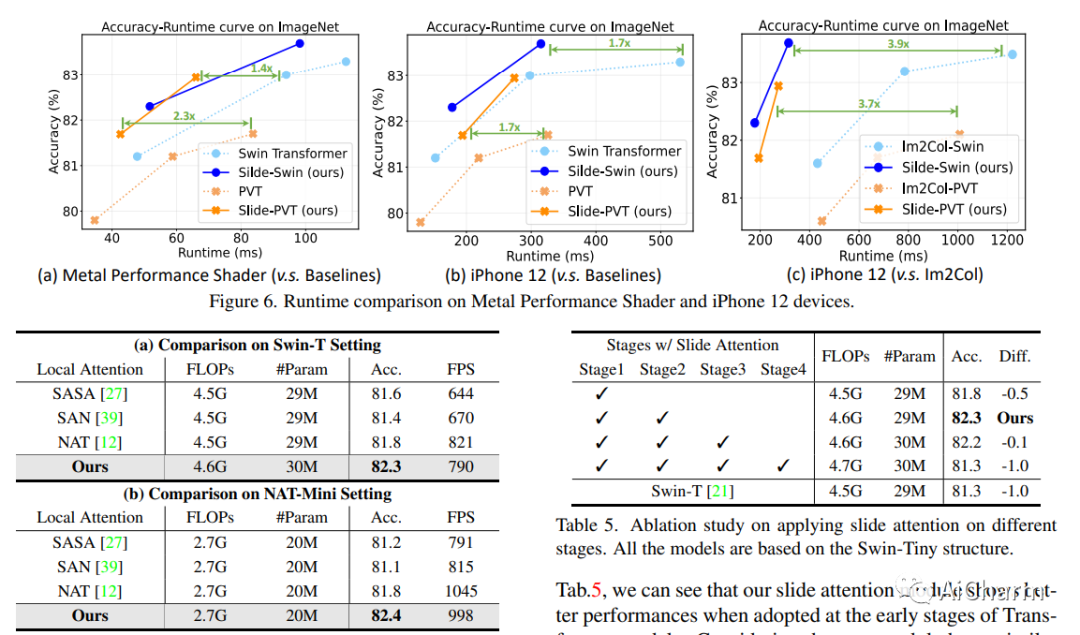
摘要:
自注意力机制一直是 Vision Transformer (ViT) 近期进展的关键因素,它可以从全局上下文中提取自适应特征。然而,现有的自注意力方法要么采用稀疏全局注意力或窗口注意力来降低计算复杂度,这可能会损害局部特征学习或受制于一些手工设计。相比之下,局部注意将每个查询的感受域限制在其自身的相邻像素内,享有卷积和自我注意的双重好处,即局部归纳偏差和动态特征选择。然而,当前的局部注意力模块要么使用低效的 Im2Col 函数,要么依赖于特定的 CUDA 内核,这些内核很难推广到没有 CUDA 支持的设备。在本文中,我们提出了一种新颖的局部注意模块 Slide Attention,它利用常见的卷积运算来实现高效、灵活和通用性。具体来说,我们首先从新的基于行的角度重新解释基于列的 Im2Col 函数,并使用 Depthwise Convolution 作为有效的替代。在此基础上,我们提出了一种基于重新参数化技术的变形移位模块,进一步将固定键/值位置放宽到局部区域的变形特征。通过这种方式,我们的模块以高效灵活的方式实现了局部注意力范式。大量实验表明,我们的幻灯片注意力模块适用于各种高级 Vision Transformer 模型并兼容各种硬件设备,并在综合基准测试中实现了持续改进的性能。此 https URL 上提供了代码。
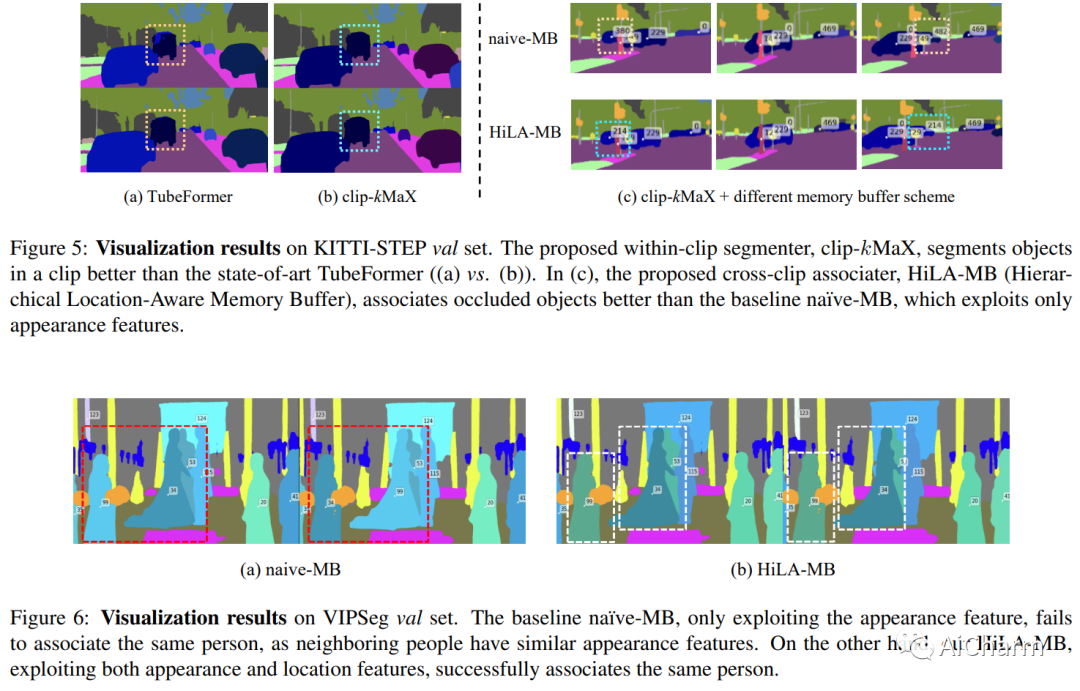
2.Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation

标题:Video-kMaX:一种用于在线和近在线视频全景分割的简单统一方法
作者:Inkyu Shin, Dahun Kim, Qihang Yu, Jun Xie, Hong-Seok Kim, Bradley Green, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
文章链接:https://arxiv.org/abs/2304.04694


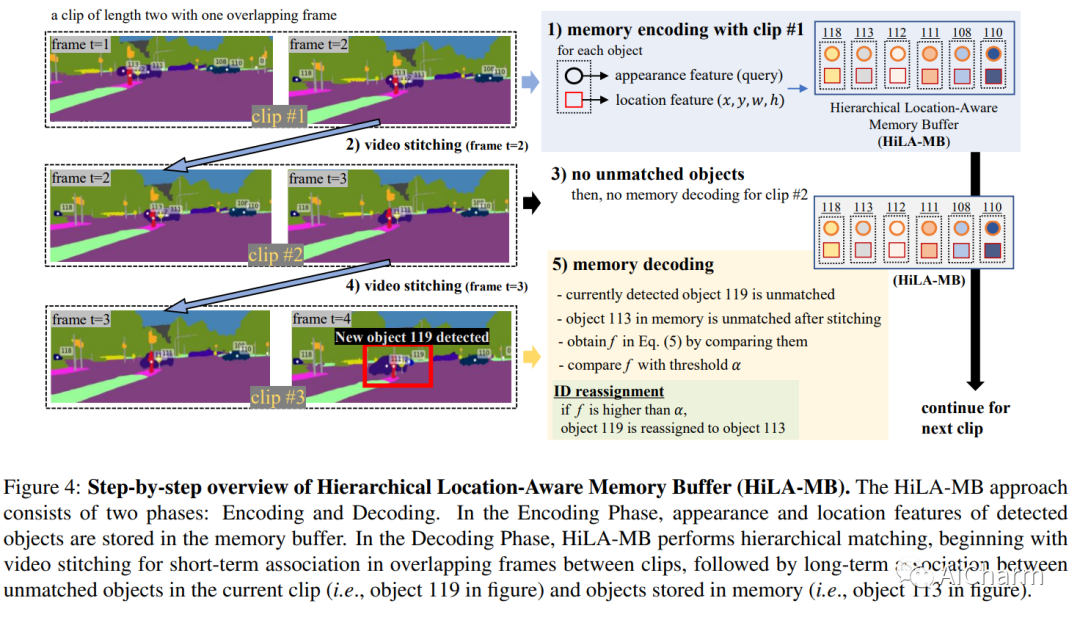
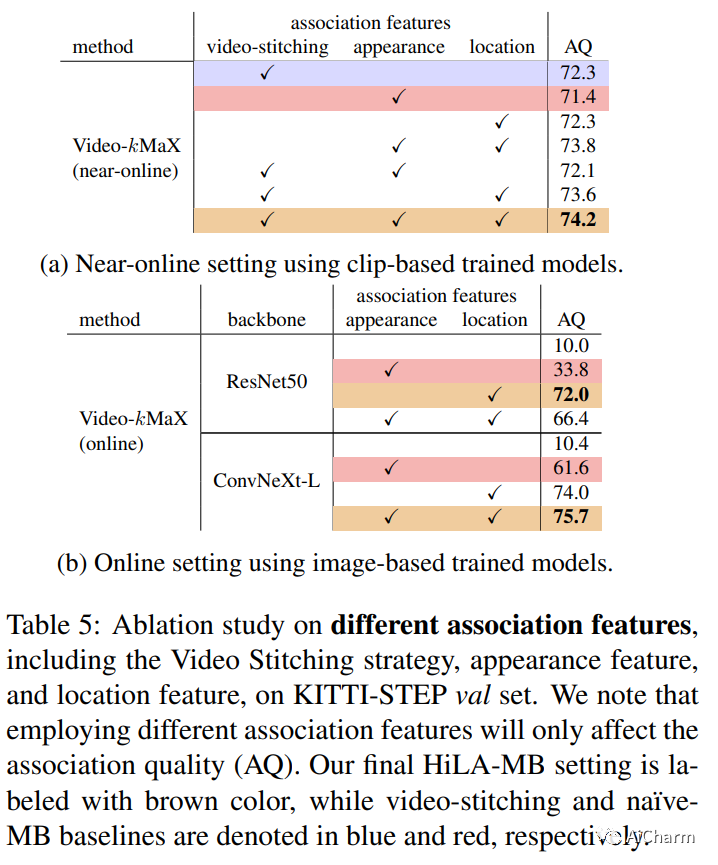

摘要:
视频全景分割 (VPS) 旨在通过分割视频中的所有像素和关联对象来实现全面的像素级场景理解。当前的解决方案可以分为在线和近在线方法。随着时间的推移,每个类别都有自己的专门设计,这使得在不同类别之间调整模型变得非常重要。为了减轻这种差异,在这项工作中,我们提出了一种统一的在线和近在线 VPS 方法。所提出的 Video-kMaX 的元架构由两个组件组成:剪辑内分割器(用于剪辑级分割)和跨剪辑关联器(用于剪辑以外的关联)。我们提出 clip-kMaX(clip k-means mask transformer)和 HiLA-MB(分层位置感知内存缓冲区)分别实例化分段器和关联器。我们的一般公式包括在线场景作为一种特殊情况,采用的剪辑长度为 1。 Video-kMaX 在 KITTI-STEP 和用于视频全景分割的 VIPSeg 以及用于视频语义分割的 VSPW 上设置了新的最先进技术。代码将公开。
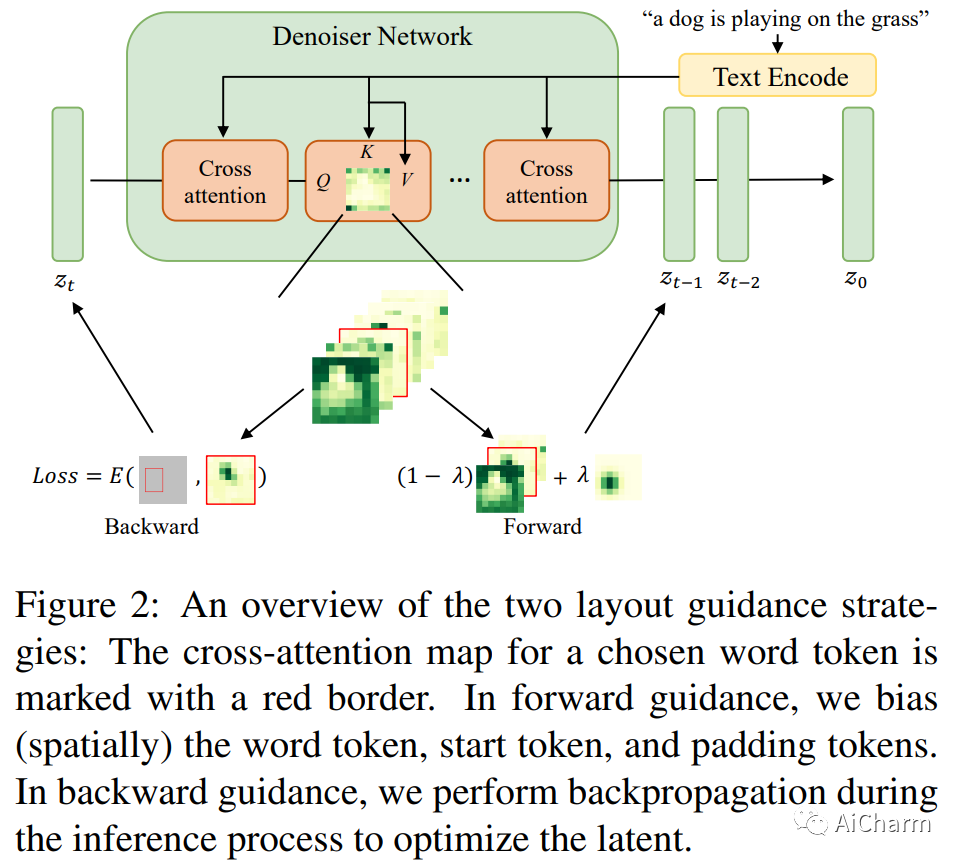
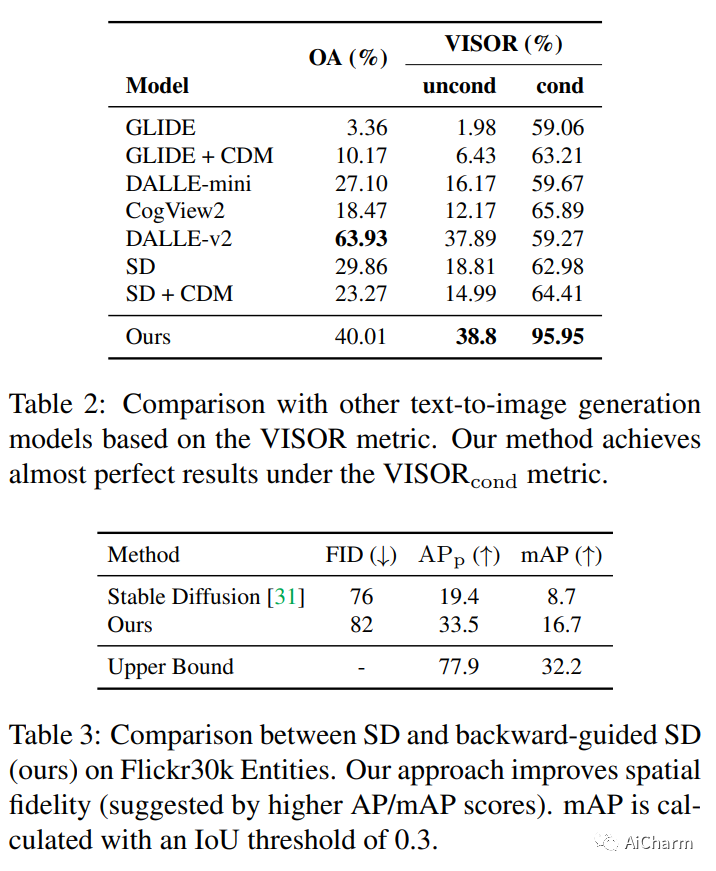
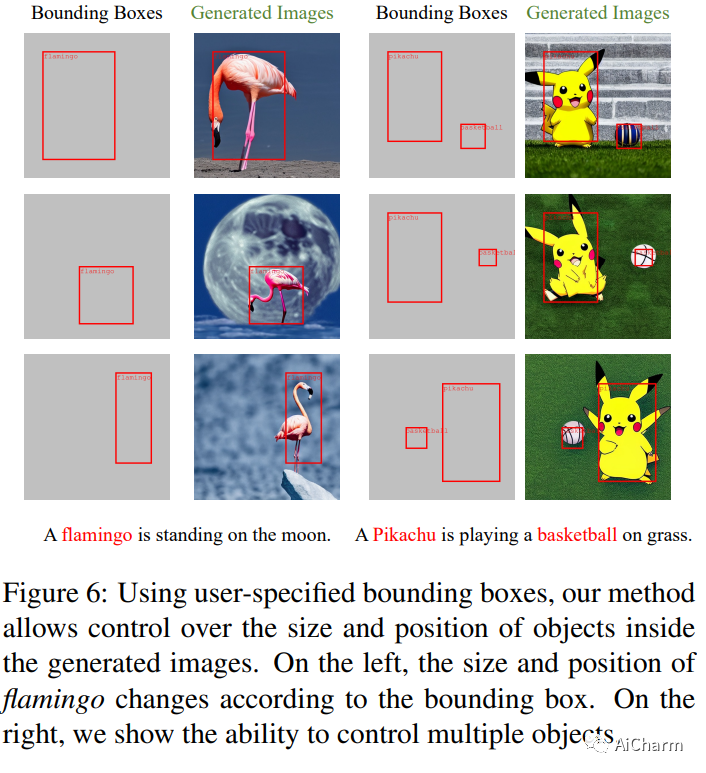
3.Training-Free Layout Control with Cross-Attention Guidance

标题:具有交叉注意力引导的免训练布局控制
作者:Minghao Chen, Iro Laina, Andrea Vedaldi
文章链接:https://arxiv.org/abs/2304.03373
项目代码:https://silent-chen.github.io/layout-guidance/

摘要:
最近基于扩散的生成器可以仅根据文本提示生成高质量的图像。但是,它们不能正确解释指定构图空间布局的指令。我们提出了一种简单的方法,无需训练或微调图像生成器即可实现稳健的布局控制。我们的技术,我们称之为布局指导,操纵模型用来连接文本和视觉信息的交叉注意层,并在给定的所需方向上引导重建,例如,用户指定的布局。为了确定如何最好地引导注意力,我们研究了不同注意力图在生成图像时的作用,并试验了两种可供选择的策略,前向引导和后向引导。我们通过几个实验对我们的方法进行了定量和定性评估,验证了其有效性。我们通过将布局指导扩展到编辑给定真实图像的布局和上下文的任务,进一步证明了它的多功能性。
更多Ai资讯:公主号AiCharm