CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.DiffCollage: Parallel Generation of Large Content with Diffusion Models(CVPR 2023)

标题:DiffCollage:使用扩散模型并行生成大内容
作者:Qinsheng Zhang, Jiaming Song, Xun Huang, Yongxin Chen, Ming-Yu Liu
文章链接:https://arxiv.org/abs/2303.17076
项目代码:https://research.nvidia.com/labs/dir/diffcollage/

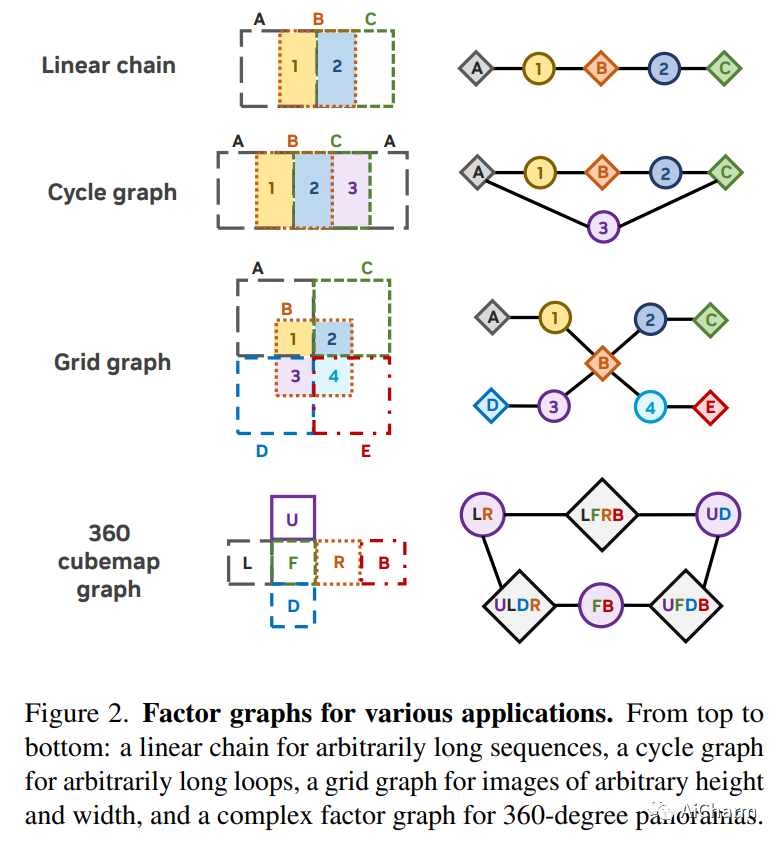
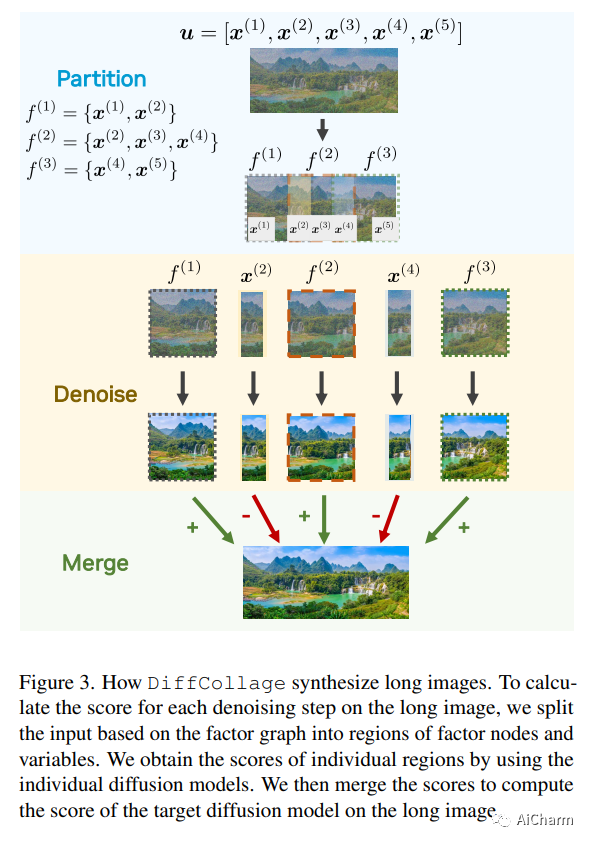
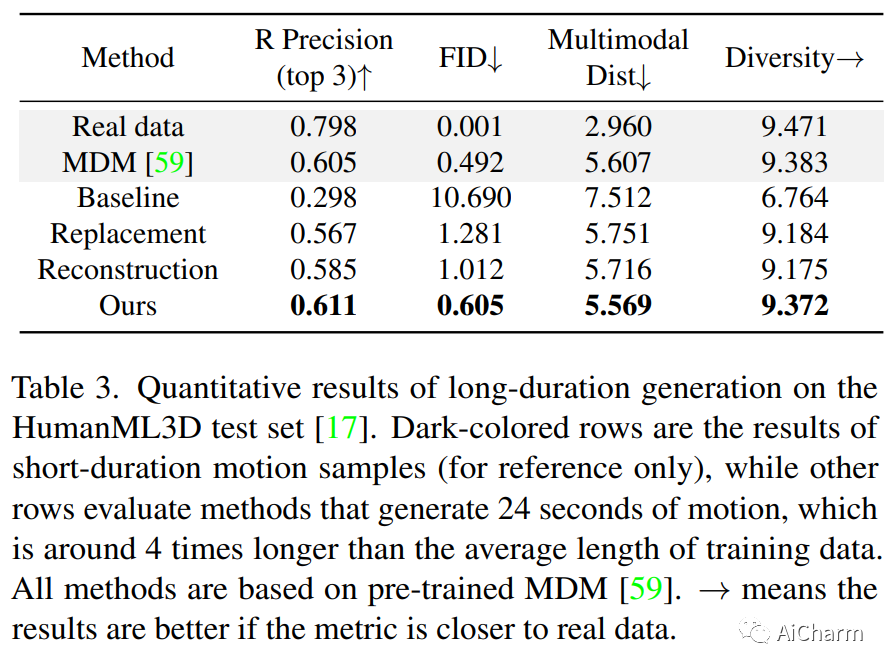
摘要:
我们提出了 DiffCollage,这是一种组合扩散模型,它可以通过利用在生成大内容片段上训练的扩散模型来生成大内容。我们的方法基于因子图表示,其中每个因子节点代表内容的一部分,变量节点代表它们的重叠。这种表示允许我们聚合来自在各个节点上定义的扩散模型的中间输出,以并行生成任意大小和形状的内容,而无需诉诸自回归生成过程。我们将 DiffCollage 应用于各种任务,包括无限图像生成、全景图像生成和长时间文本引导运动生成。与强自回归基线进行比较的大量实验结果验证了我们方法的有效性。
2.NeILF++: Inter-Reflectable Light Fields for Geometry and Material Estimation

标题:NeILF++:用于几何和材料估计的相互反射光场
作者:Jiayu Jiao, Yu-Ming Tang, Kun-Yu Lin, Yipeng Gao, Jinhua Ma, YaoWei Wang, Wei-Shi Zheng
文章链接:https://arxiv.org/abs/2303.17147
项目代码:https://yoyo000.github.io/NeILF_pp/
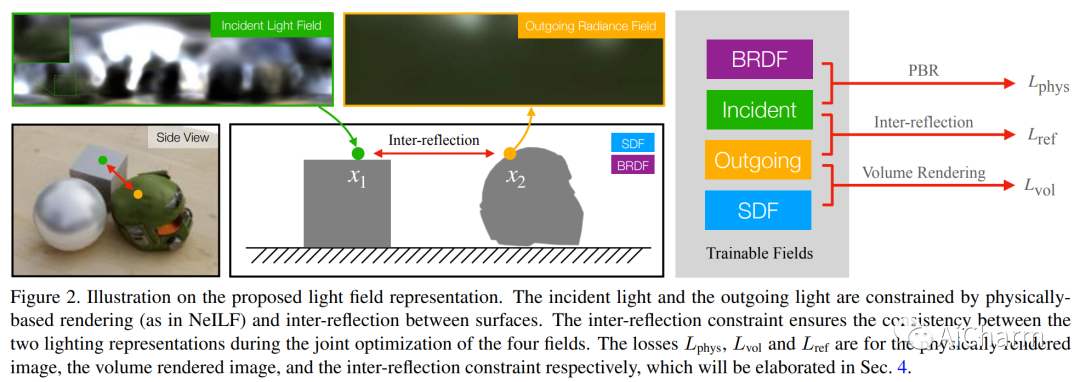
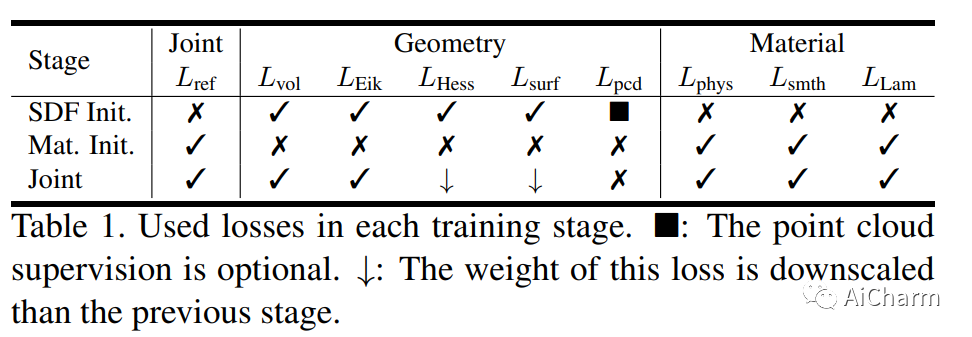
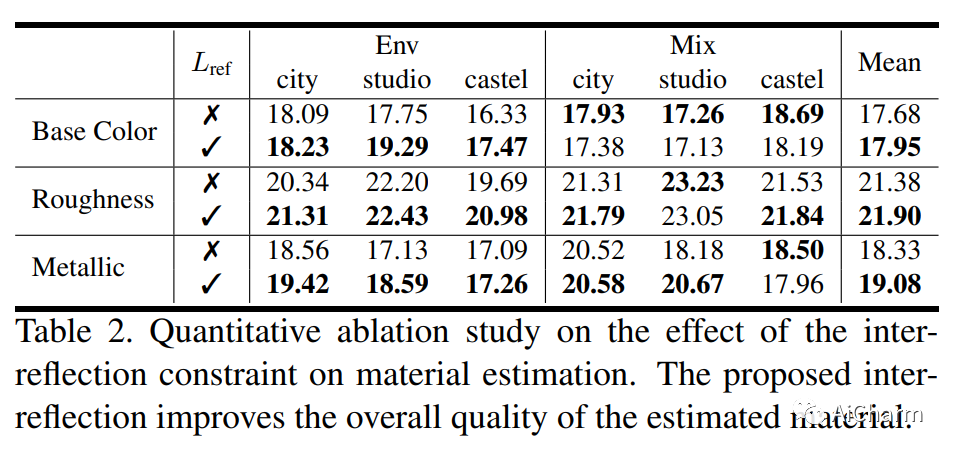
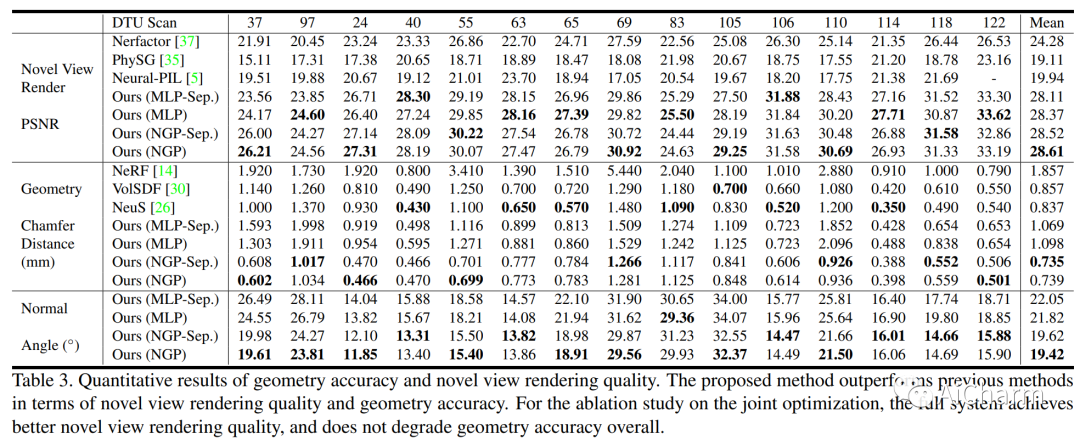
摘要:
我们提出了一种新颖的可微分渲染框架,用于从多视图图像估计联合几何、材料和照明。与假设简化的环境地图或共置手电筒的先前方法相比,在这项工作中,我们将静态场景的照明制定为一个神经入射光场 (NeILF) 和一个出射神经辐射场 (NeRF)。所提出方法的关键见解是通过基于物理的渲染和表面之间的相互反射将入射光场和出射光场结合起来,从而可以从基于物理的图像观察中分离出场景几何、材料和照明。方式。所提出的入射光和相互反射框架可以很容易地应用于其他 NeRF 系统。我们表明,我们的方法不仅可以将出射辐射分解为入射光和表面材料,而且还可以作为表面细化模块,进一步改善神经表面的重建细节。我们在几个数据集上证明,所提出的方法能够在几何重建质量、材料估计精度和新视图渲染的保真度方面取得最先进的结果。
3.Streaming Video Model(CVPR 2023)
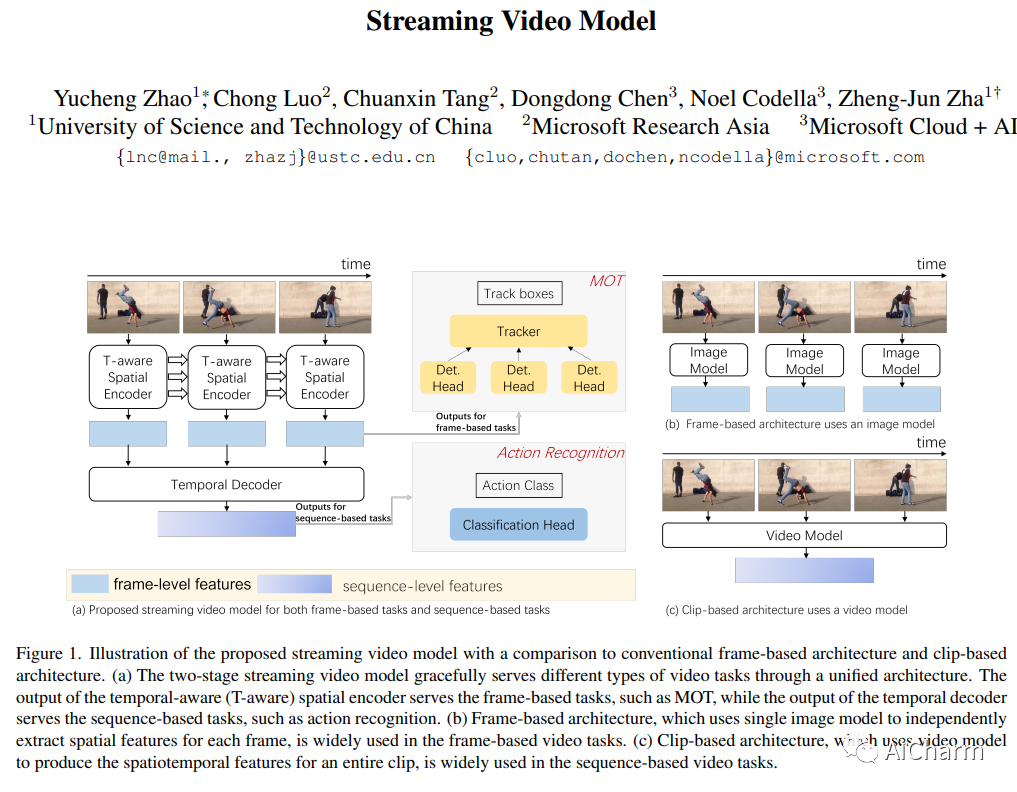
标题:流媒体视频模型
作者:Yucheng Zhao, Chong Luo, Chuanxin Tang, Dongdong Chen, Noel Codella, Zheng-Jun Zha
文章链接:https://arxiv.org/abs/2303.17228
项目代码:https://github.com/yuzhms/Streaming-Video-Model
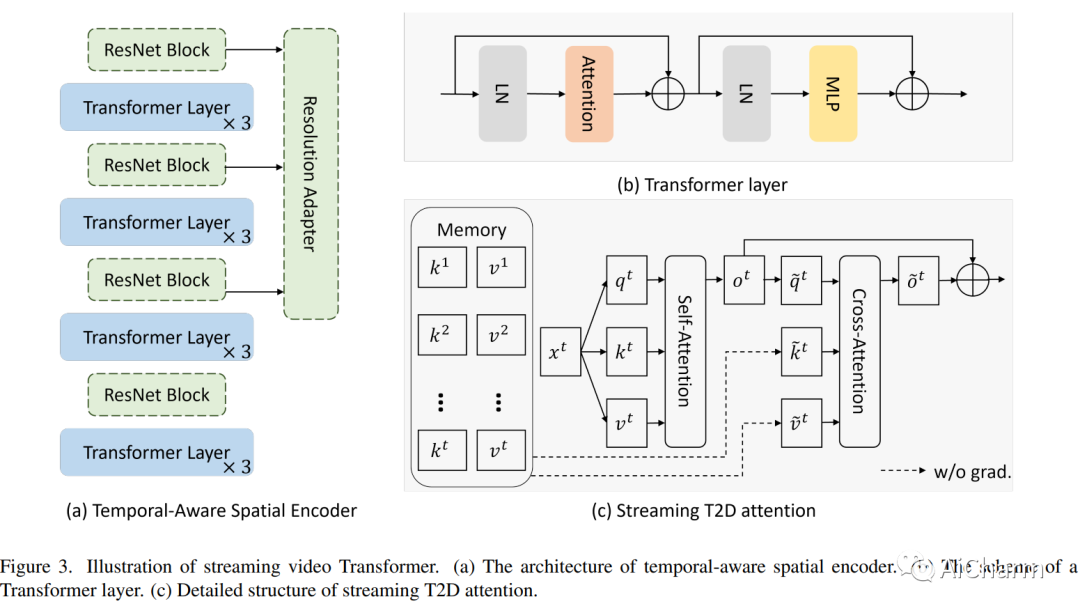
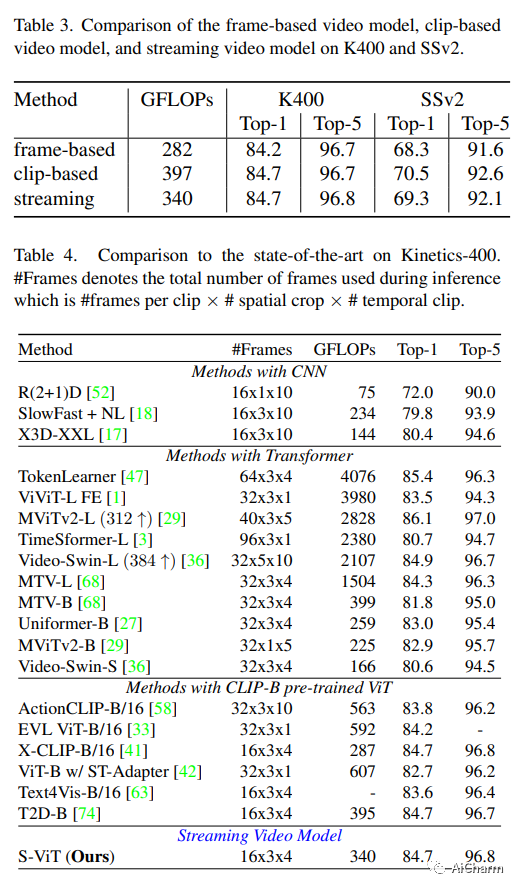
摘要:
传统上,视频理解任务由两个独立的架构建模,专门为两个不同的任务量身定制。基于序列的视频任务,如动作识别,使用视频主干直接提取时空特征,而基于帧的视频任务,如多目标跟踪 (MOT),依赖单个固定图像主干提取空间特征。相比之下,我们建议将视频理解任务统一到一种新颖的流式视频架构中,称为流式视觉转换器 (S-ViT)。 S-ViT 首先使用支持内存的时间感知空间编码器生成帧级特征,以服务于基于帧的视频任务。然后将帧特征输入到任务相关的时间解码器中,以获得基于序列的任务的时空特征。 S-ViT 的效率和功效通过基于序列的动作识别任务中最先进的准确性以及基于框架的 MOT 任务中优于传统架构的竞争优势得到证明。我们相信,流媒体视频模型的概念和 S-ViT 的实施是朝着统一的视频理解深度学习架构迈出的坚实一步。代码将在这个 https URL 上可用。
更多Ai资讯:公主号AiCharm