CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.HypLiLoc: Towards Effective LiDAR Pose Regression with Hyperbolic Fusion(CVPR 2023)

标题:HypLiLoc:通过双曲线融合实现有效的 LiDAR 姿态回归
作者:Sijie Wang, Qiyu Kang, Rui She, Wei Wang, Kai Zhao, Yang Song, Wee Peng Tay
文章链接:https://arxiv.org/abs/2304.00932
项目代码:https://github.com/sijieaaa/HypLiLoc
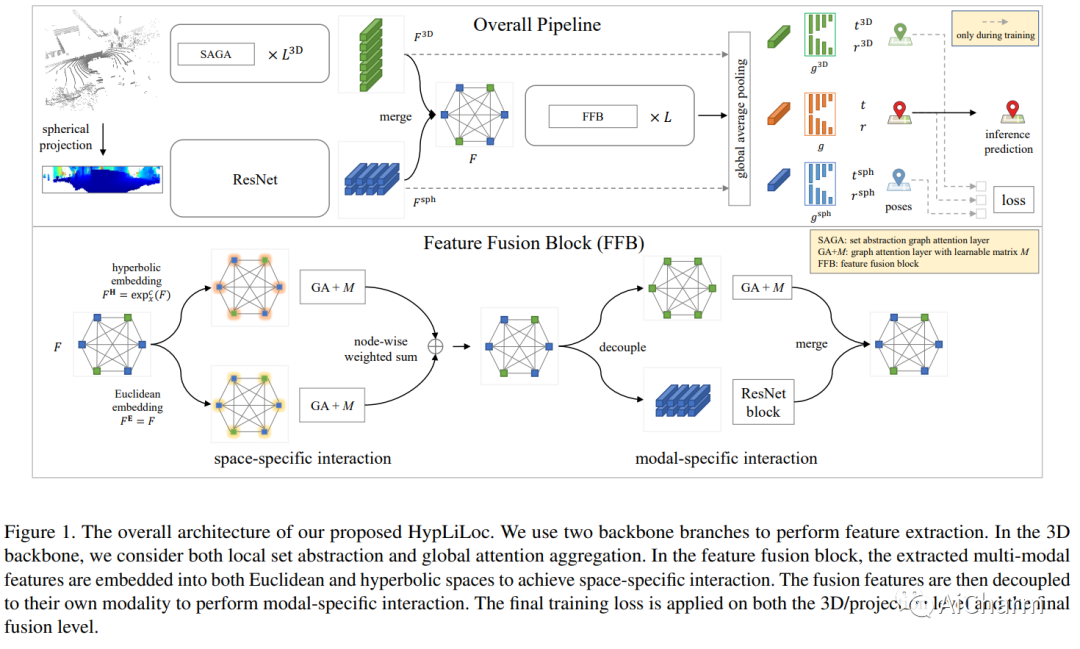
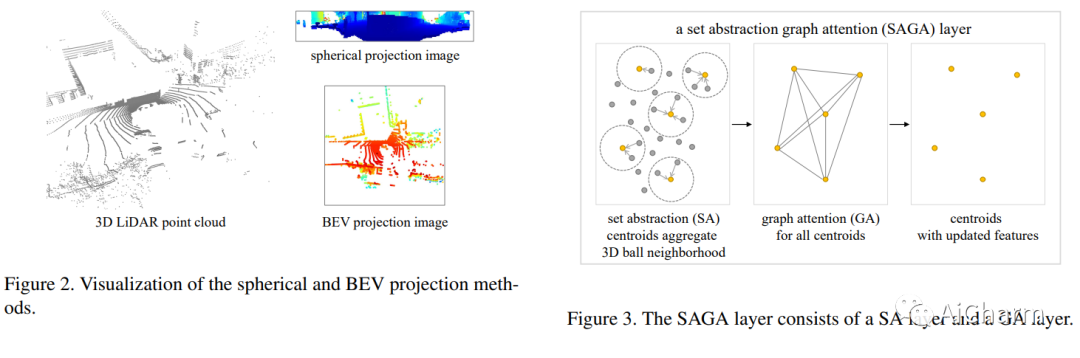
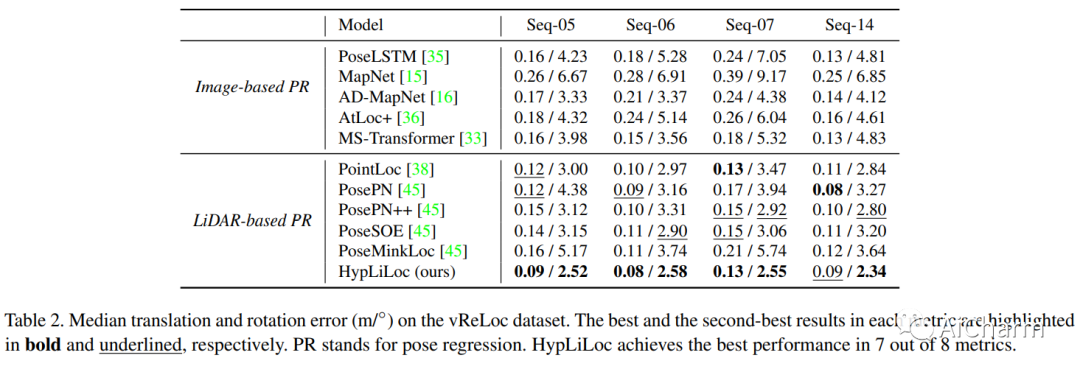
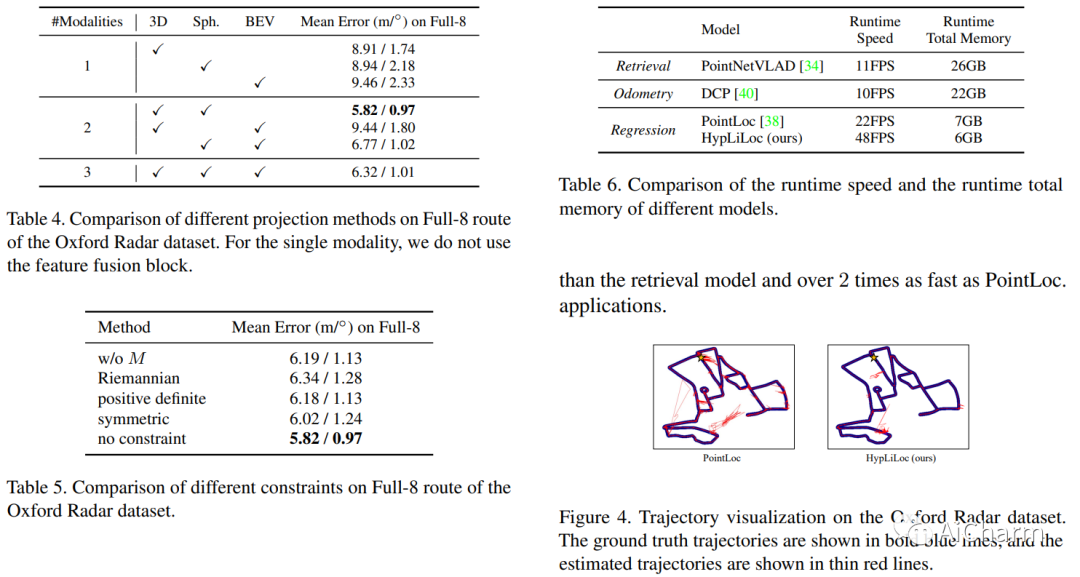
摘要:
LiDAR 重定位在许多领域发挥着至关重要的作用,包括机器人技术、自动驾驶和计算机视觉。基于 LiDAR 的数据库检索通常会产生高计算存储成本,并且如果数据库过于稀疏,则可能导致全局不准确的姿态估计。另一方面,姿态回归方法以图像或点云作为输入,并以端到端的方式直接回归全局姿态。它们不执行数据库匹配,并且比检索技术计算效率更高。我们提出了 HypLiLoc,一种用于 LiDAR 位姿回归的新模型。我们使用两个分支主干分别提取 3D 特征和 2D 投影特征。我们考虑在欧几里德空间和双曲空间中进行多模态特征融合,以获得更有效的特征表示。实验结果表明,HypLiLoc 在室外和室内数据集中都实现了最先进的性能。我们还对框架设计进行了广泛的消融研究,证明了多模态特征提取和多空间嵌入的有效性。我们的代码发布于:这个 https URL
2.DiffMimic: Efficient Motion Mimicking with Differentiable Physics(ICLR 2023)

标题:DiffMimic:利用可微物理进行高效运动模拟
作者:Jiawei Ren, Cunjun Yu, Siwei Chen, Xiao Ma, Liang Pan, Ziwei Liu
文章链接:https://openreview.net/forum?id=06mk-epSwZ
项目代码:https://diffmimic.github.io/

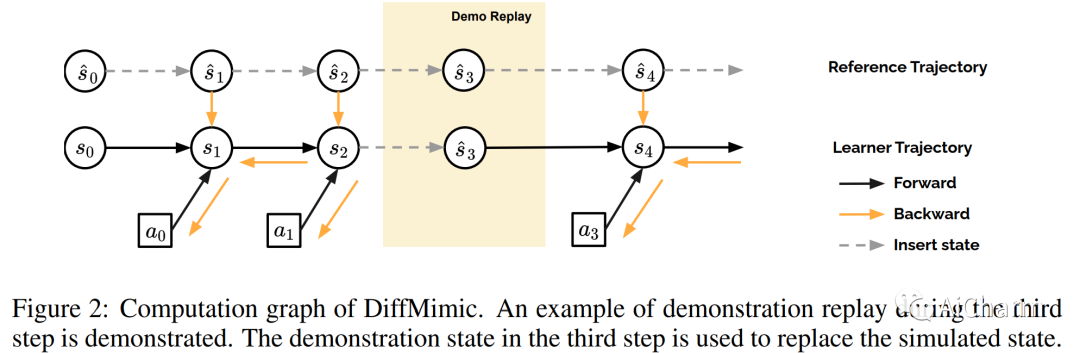

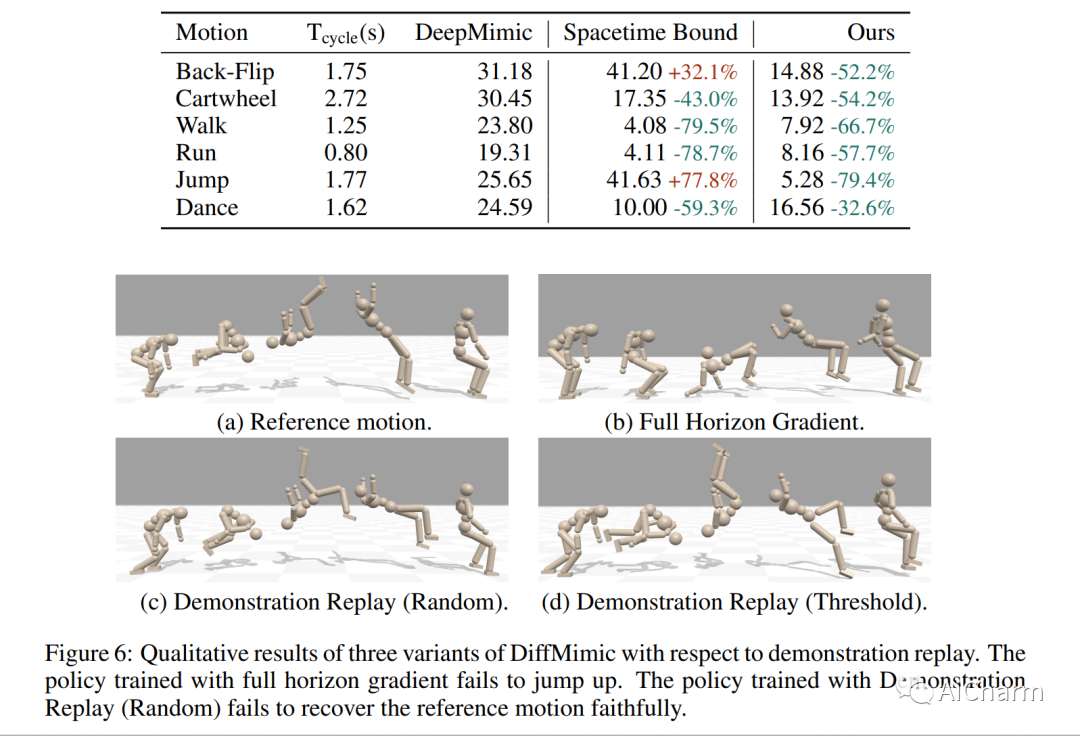
摘要:
运动模仿是基于物理的角色动画中的一项基础任务。然而,大多数现有的运动模仿方法都是建立在强化学习 (RL) 的基础上的,并且存在大量奖励工程、高方差和缓慢收敛以及艰苦探索的问题。具体来说,他们通常需要数十小时甚至数天的训练来模仿一个简单的运动序列,导致可扩展性差。在这项工作中,我们利用可微分物理模拟器 (DPS) 并提出了一种称为 DiffMimic 的高效运动模仿方法。我们的关键见解是 DPS 将复杂的策略学习任务转换为更简单的状态匹配问题。特别是,DPS 通过具有真实物理先验的分析梯度来学习稳定的策略,从而导致比基于 RL 的方法更快更稳定的收敛。此外,为了避免局部最优,我们利用 Demonstration Replay 机制在长范围内实现稳定的梯度反向传播。对标准基准的大量实验表明,DiffMimic 比现有方法(例如 DeepMimic)具有更好的样本效率和时间效率。值得注意的是,DiffMimic 允许物理模拟角色在训练 10 分钟后学习 Backflip,并能够在训练 3 小时后循环它,而现有方法可能需要大约一天的训练才能循环 Backflip。更重要的是,我们希望 DiffMimic 在未来的研究中可以通过可微分服装模拟等技术使更多可微分动画系统受益。
3.Detecting and Grounding Multi-Modal Media Manipulation(CVPR 2023)

标题:检测和接地多模态媒体操纵
作者:Rui Shao, Tianxing Wu, Ziwei Liu
文章链接:https://arxiv.org/abs/2304.02556
项目代码:https://rshaojimmy.github.io/Projects/MultiModal-DeepFake

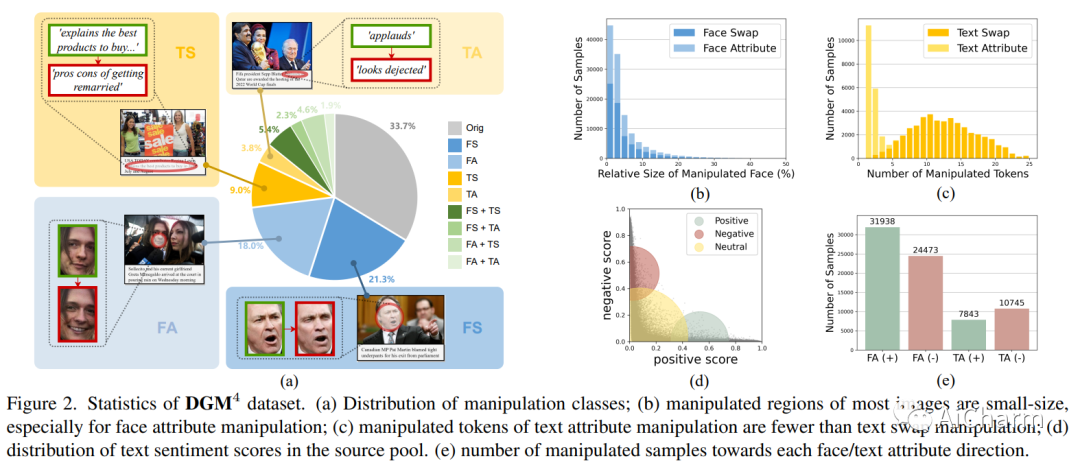

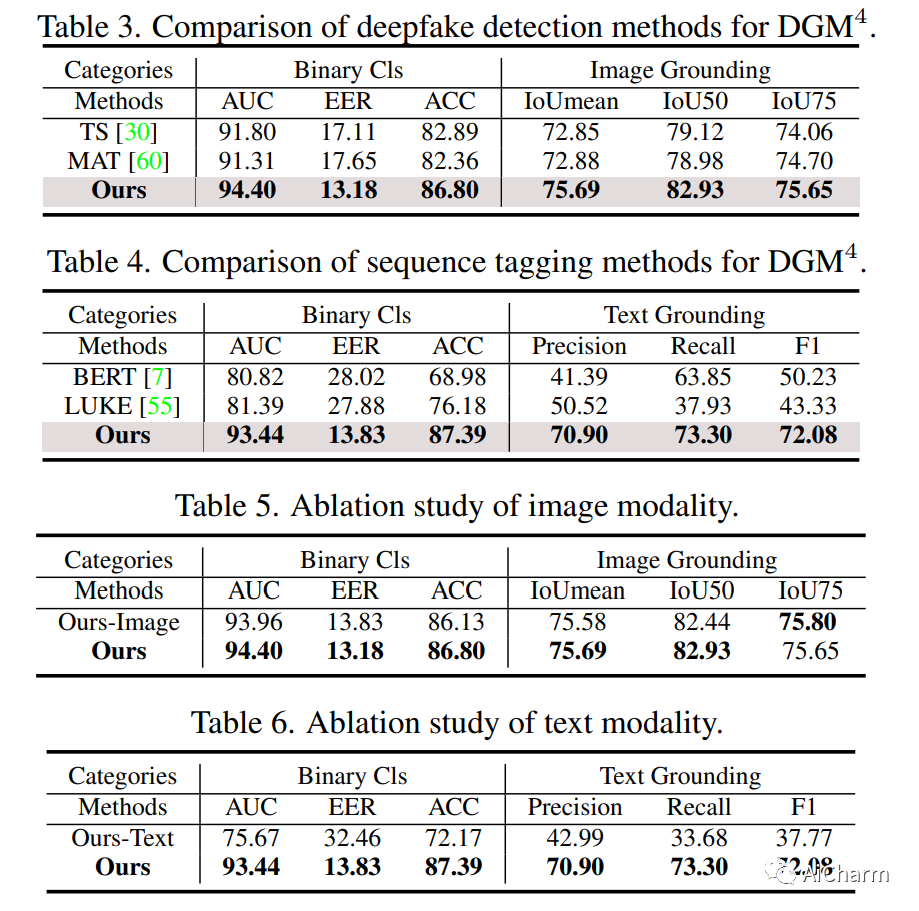
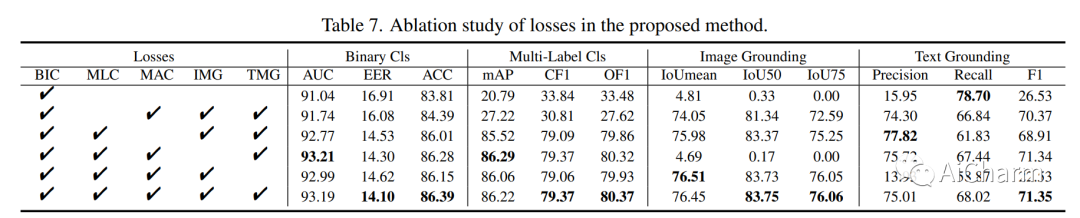
摘要:
错误信息已成为一个紧迫的问题。网络上广泛存在视觉和文本形式的虚假媒体。虽然已经提出了各种 deepfake 检测和文本假新闻检测方法,但它们仅设计用于基于二进制分类的单模态伪造,更不用说分析和推理跨不同模态的细微伪造痕迹。在本文中,我们强调了多模态虚假媒体的一个新研究问题,即检测和接地多模态媒体操纵 (DGM^4)。DGM^4 的目标不仅是检测多模态媒体的真实性,而且还将被操纵的内容(即图像边界框和文本标记)作为基础,这需要对多模态媒体操纵进行更深入的推理。为了支持大规模调查,我们构建了第一个 DGM^4 数据集,其中图像-文本对通过各种方法进行操作,并对各种操作进行了丰富的注释。此外,我们提出了一种新颖的分层多模态操作推理变换器 (HAMMER),以充分捕捉不同模态之间的细粒度交互。HAMMER 执行 1) 两个单模态编码器之间的操作感知对比学习作为浅层操作推理,以及 2) 多模态聚合器的模态感知交叉注意力作为深度操作推理。基于交互的多模态信息,从浅到深集成专用的操纵检测和接地头。最后,我们为这个新的研究问题建立了一个广泛的基准并建立了严格的评估指标。综合实验证明了我们模型的优越性;还揭示了一些有价值的观察结果,以促进未来对多模态媒体操纵的研究。
更多Ai资讯:公主号AiCharm