CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
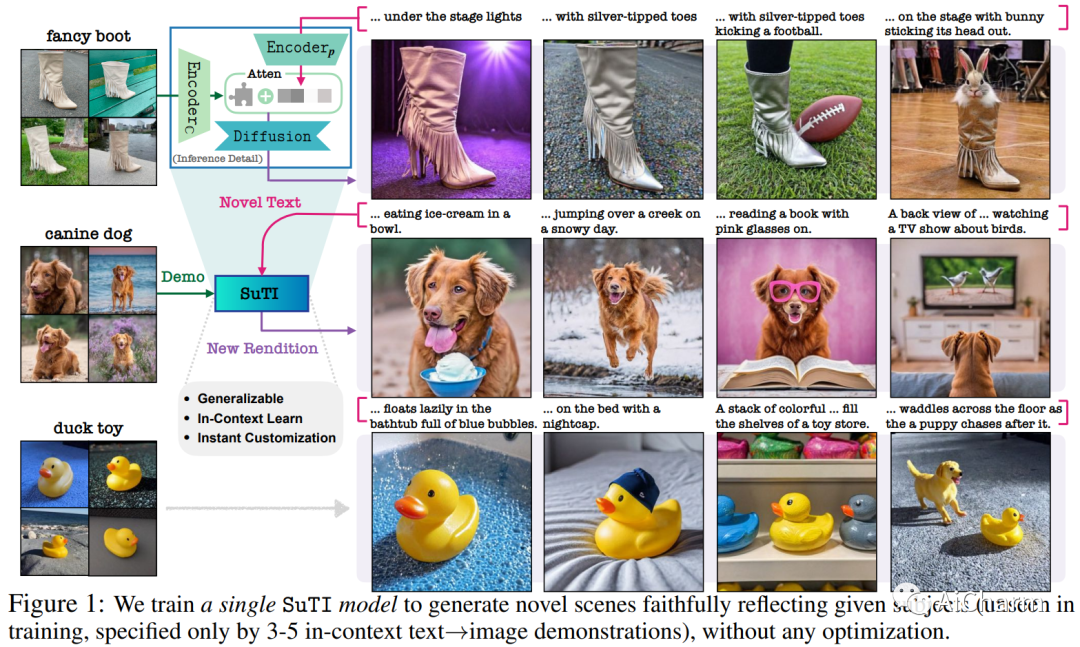
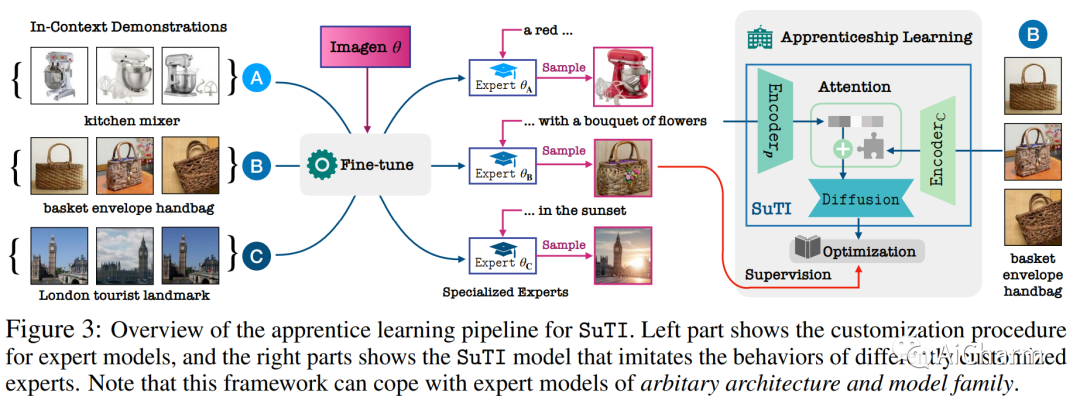
1.Subject-driven Text-to-Image Generation via Apprenticeship Learning

标题:通过学徒学习生成主题驱动的文本到图像
作者:Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Rui, Xuhui Jia, Ming-Wei Chang, William W. Cohen
文章链接:https://arxiv.org/abs/2304.00186


摘要:

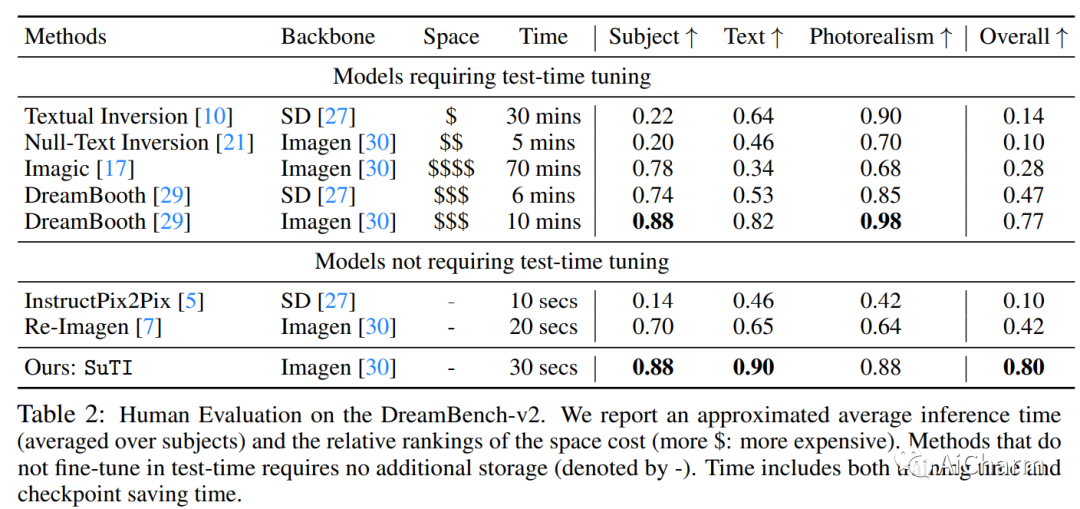
最近的文本到图像生成模型,如 DreamBooth,通过从几个例子中为给定主题微调“专家模型”,在生成目标主题的高度定制图像方面取得了显着进步。然而,这个过程是昂贵的,因为必须为每个主题学习一个新的专家模型。在本文中,我们介绍了 SuTI,一种主题驱动的文本到图像生成器,它用 \emph{in-context} 学习取代了特定主题的微调。给定一个新主题的一些演示,SuTI 可以立即在不同场景中生成该主题的新颖再现,而无需任何特定于主题的优化。SuTI 由 {\em apprenticeship learning} 提供支持,其中单个学徒模型是从大量特定主题专家模型生成的数据中学习的。具体来说,我们从 Internet 中挖掘出数百万个图像集群,每个图像集群都围绕一个特定的视觉主题。我们采用这些集群来训练大量专门针对不同主题的专家模型。学徒模型 SuTI 然后通过所提出的学徒学习算法学习模仿这些专家的行为。SuTI 可以生成高质量和定制的特定主题图像,比基于优化的 SoTA 方法快 20 倍。在具有挑战性的 DreamBench 和 DreamBench-v2 上,我们的人类评估表明 SuTI 可以显着优于 InstructPix2Pix、Textual Inversion、Imagic、Prompt2Prompt、Re-Imagen 等现有方法,同时与 DreamBooth 的表现相当。
2.Vision Transformers with Mixed-Resolution Tokenization
标题:具有混合分辨率标记化的视觉转换器
作者:Tomer Ronen, Omer Levy, Avram Golbert
文章链接:https://arxiv.org/abs/2304.00287
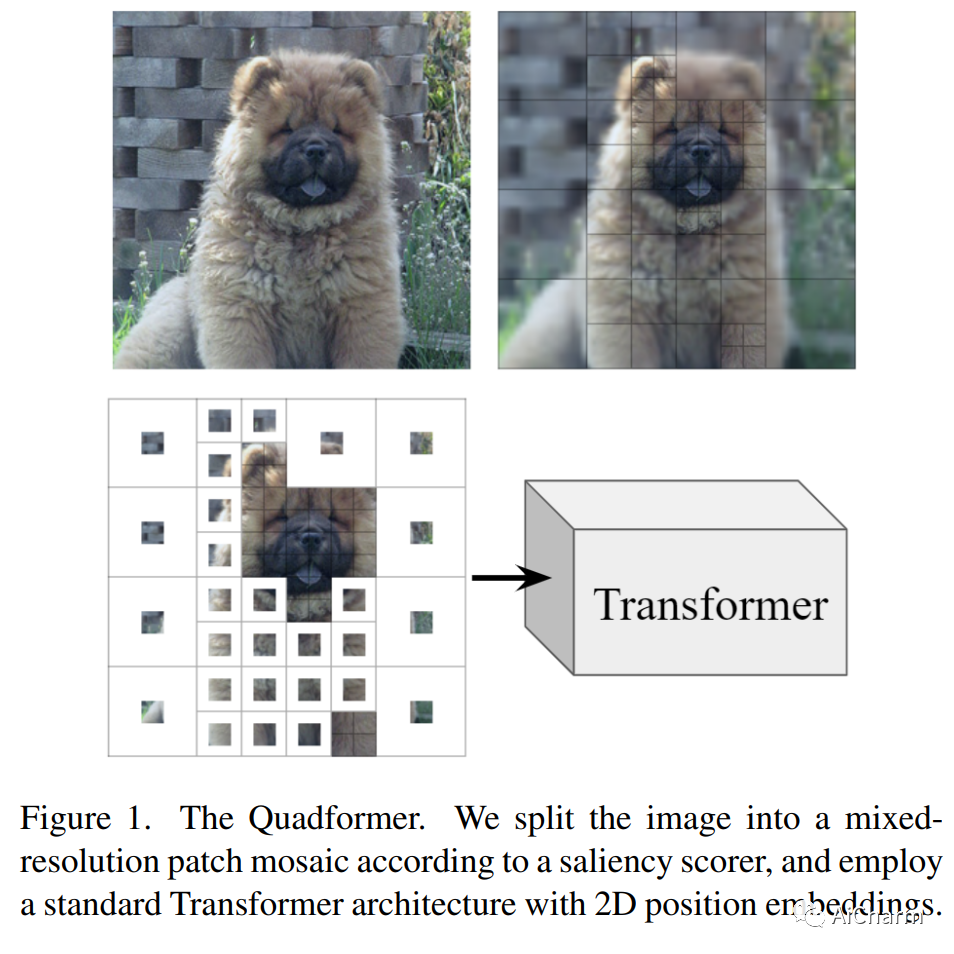


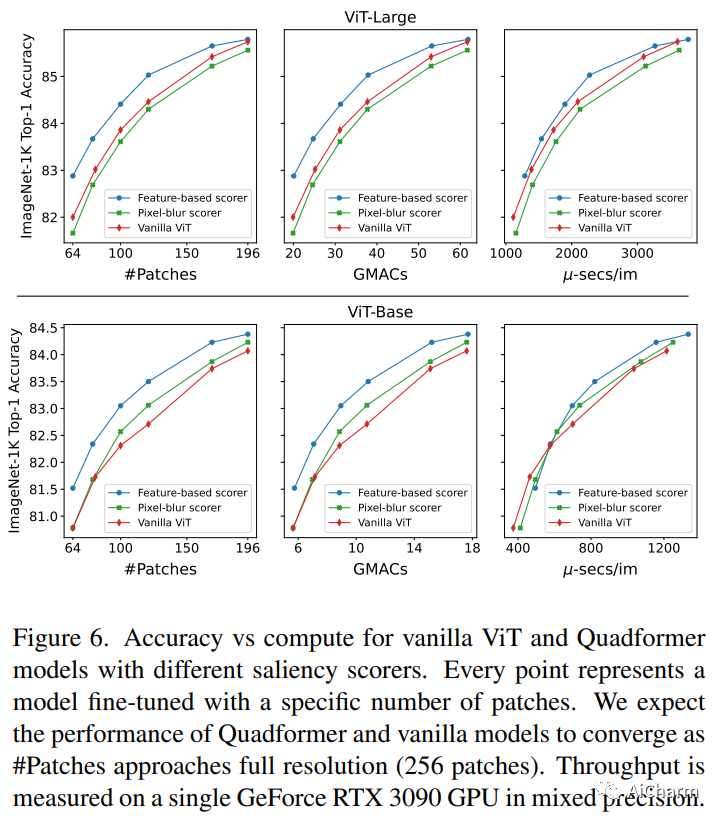

摘要:
Vision Transformer 模型通过将输入图像划分为大小相等的空间规则网格来处理输入图像。相反,Transformers 最初是在自然语言序列上引入的,其中每个标记代表一个子词——一块任意大小的原始数据。在这项工作中,我们通过引入一种新颖的图像标记化方案将这种方法应用于 Vision Transformers,将标准统一网格替换为混合分辨率的标记序列,其中每个标记代表一个任意大小的补丁。使用四叉树算法和一种新颖的显着性评分器,我们构建了一个补丁马赛克,其中以低分辨率处理图像的低显着性区域,将更多模型的容量路由到重要的图像区域。使用与 vanilla ViTs 相同的架构,我们的 Quadformer 模型在控制计算预算时在图像分类方面实现了显着的准确性提升。代码和模型可在此 https URL 上公开获得。
3.SVT: Supertoken Video Transformer for Efficient Video Understanding

标题:SVT:用于高效视频理解的 Supertoken 视频转换器
作者:Chenbin Pan, Rui Hou, Hanchao Yu, Qifan Wang, Senem Velipasalar, Madian Khabsa
文章链接:https://arxiv.org/abs/2304.00325
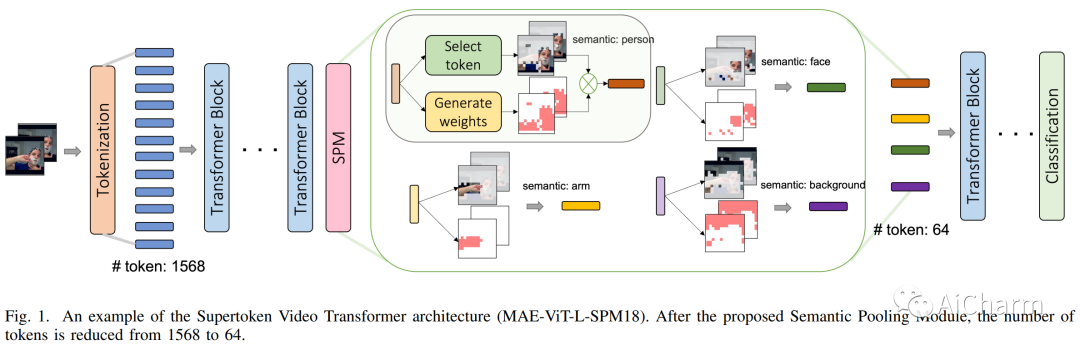
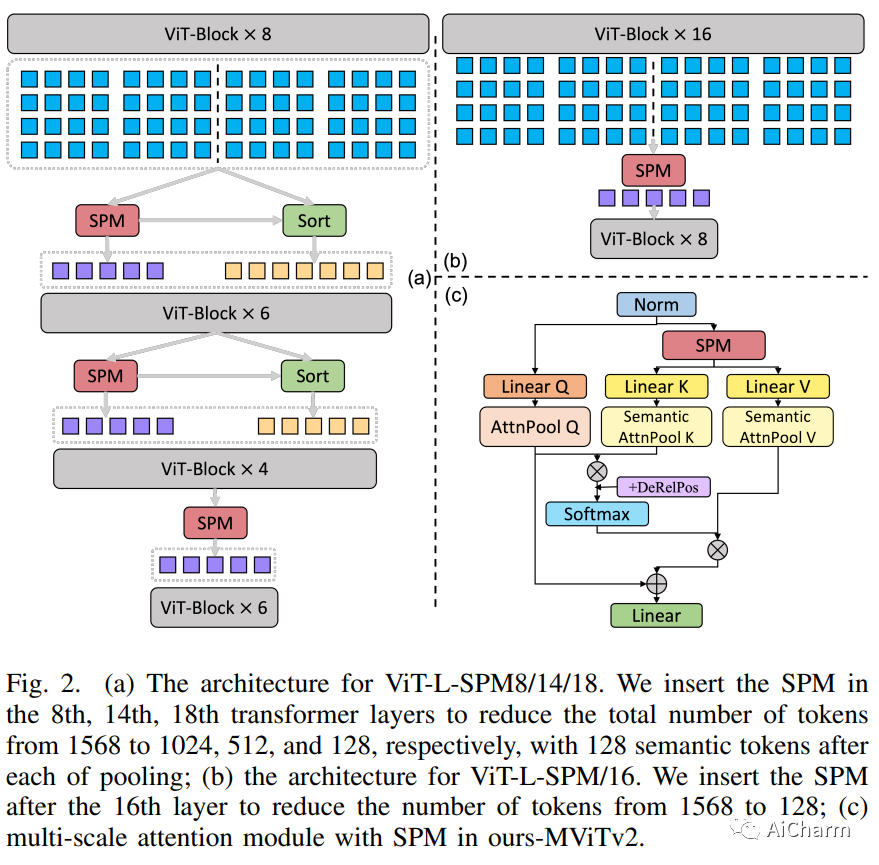

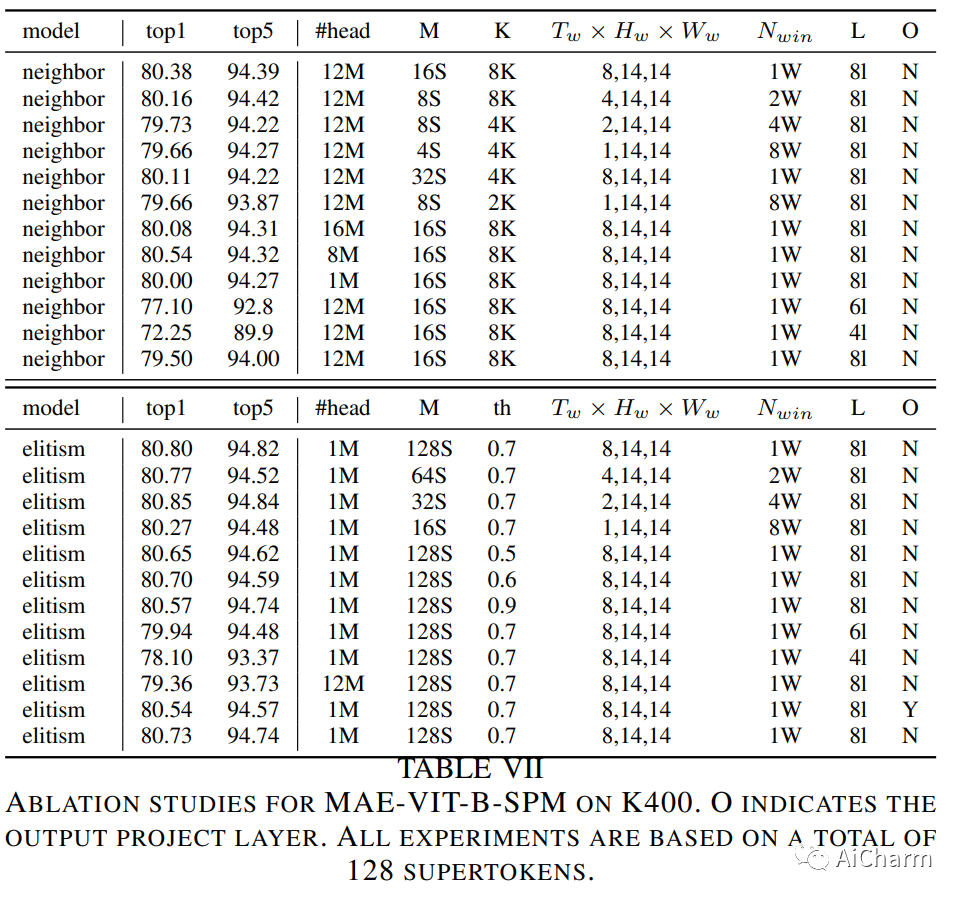
摘要:
无论是通过从头到尾以固定分辨率处理视频,还是结合池化和缩小策略,现有的视频转换器都可以处理整个网络中的整个视频内容,而无需专门处理大部分冗余信息。在本文中,我们提出了一种 Supertoken Video Transformer (SVT),它结合了语义池模块 (SPM),根据视觉转换器的语义沿着视觉转换器的深度聚合潜在表示,从而减少视频输入中固有的冗余。~定性结果表明我们的方法可以通过合并具有相似语义的潜在表示有效地减少冗余,从而增加下游任务的显着信息的比例。~从数量上讲,我们的方法提高了 ViT 和 MViT 的性能,同时需要显着减少 Kinetics 和 Something 的计算-Something-V2 基准。~更具体地说,通过我们的 SPM,我们将 MAE 预训练的 ViT-B 和 ViT-L 的准确性分别提高了 1.5%,GFLOP 减少了 33%,FLOP 减少了 55%,分别提高了 0.2% Kinectics-400 基准测试,并将 MViTv2-B 的精度提高 0.2% 和 0.3%,同时在 Kinectics-400 和 Something-Something-V2 上分别减少 22% 的 GFLOP。
更多Ai资讯:公主号AiCharm