CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CL
1.A Survey of Large Language Models
标题:大型语言模型综述
作者:Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang,etc
文章链接:https://arxiv.org/abs/2303.18223
摘要:
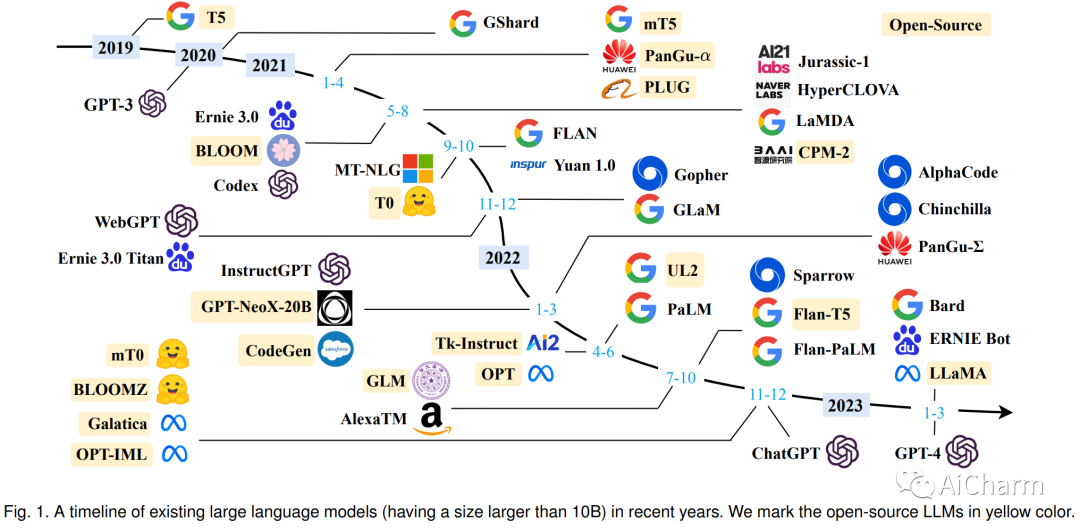
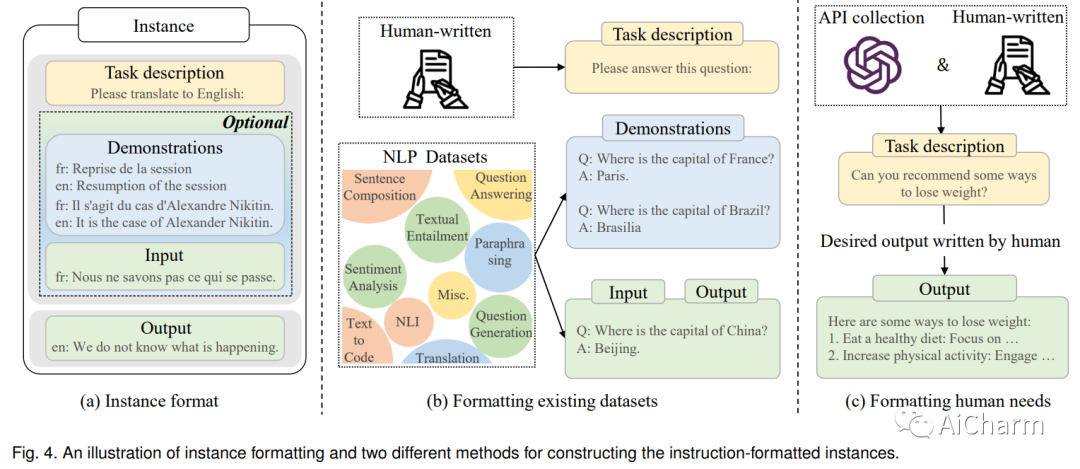
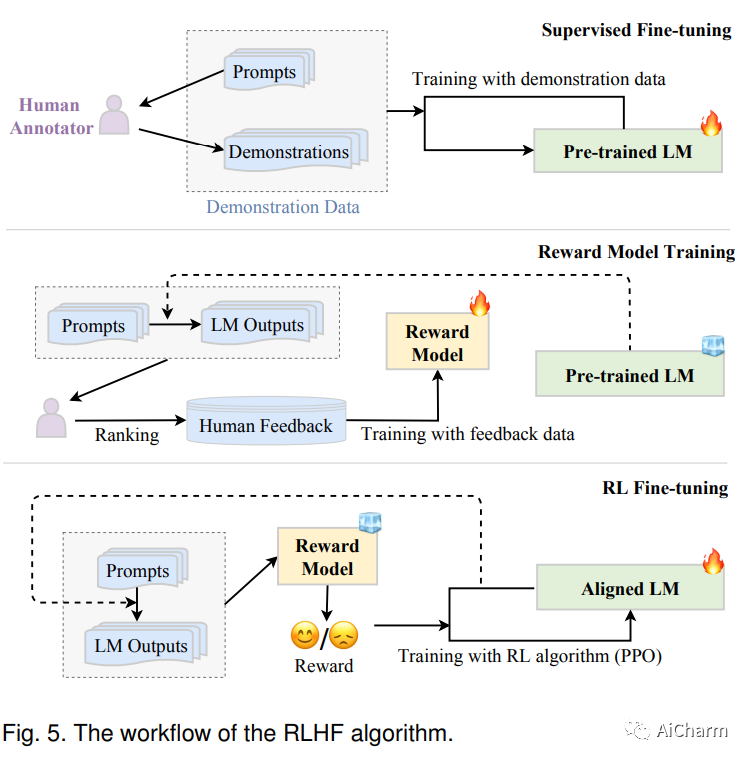
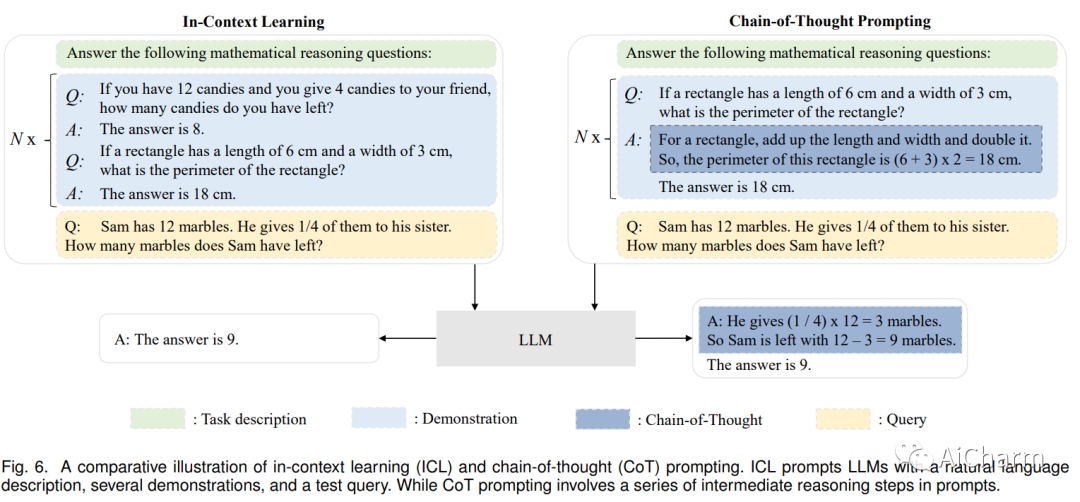
语言本质上是一个复杂、错综复杂的人类表达系统,受语法规则支配。开发用于理解和掌握语言的有能力的 AI 算法是一项重大挑战。作为一种主要方法,语言建模在过去二十年中被广泛研究用于语言理解和生成,从统计语言模型发展到神经语言模型。最近,通过在大规模语料库上预训练 Transformer 模型提出了预训练语言模型 (PLM),在解决各种 NLP 任务方面表现出强大的能力。由于研究人员发现模型缩放可以带来性能提升,因此他们通过将模型尺寸增加到更大的尺寸来进一步研究缩放效果。有趣的是,当参数规模超过一定水平时,这些扩大的语言模型不仅实现了显着的性能提升,而且还表现出一些小规模语言模型所不具备的特殊能力。为了区分参数规模的差异,研究界为具有显着规模的 PLM 创造了术语大型语言模型 (LLM)。近年来,LLMs的研究得到了学术界和产业界的大力推进,其中一个引人注目的进展是ChatGPT的推出,引起了社会的广泛关注。LLM 的技术发展对整个 AI 社区产生了重要影响,这将彻底改变我们开发和使用 AI 算法的方式。在本次调查中,我们通过介绍背景、主要发现和主流技术来回顾 LLM 的最新进展。特别是,我们关注 LLM 的四个主要方面,即预训练、自适应调优、利用和能力评估。 此外,我们还总结了开发 LLM 的可用资源,并讨论了未来方向的剩余问题。
Subjects: cs.CV
2.3D-aware Image Generation using 2D Diffusion Models

标题:使用 2D 扩散模型生成 3D 感知图像
作者:Jianfeng Xiang, Jiaolong Yang, Binbin Huang, Xin Tong
文章链接:https://arxiv.org/abs/2303.17905
项目代码:https://jeffreyxiang.github.io/ivid/

摘要:
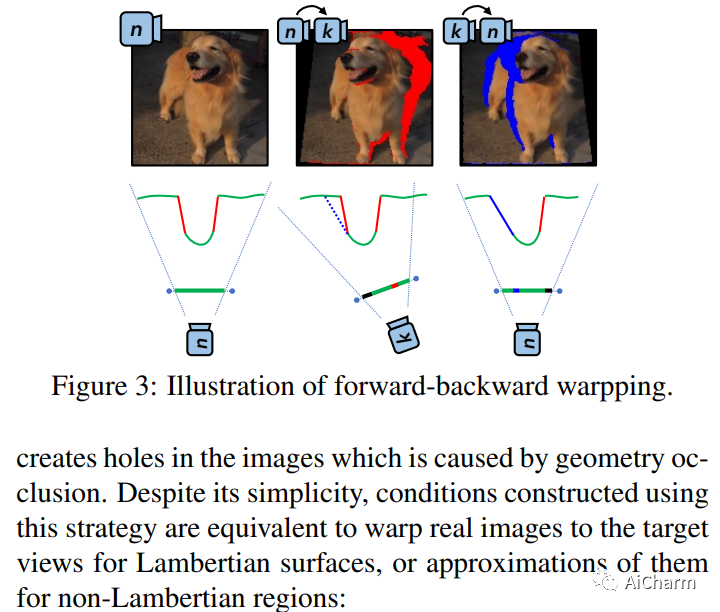
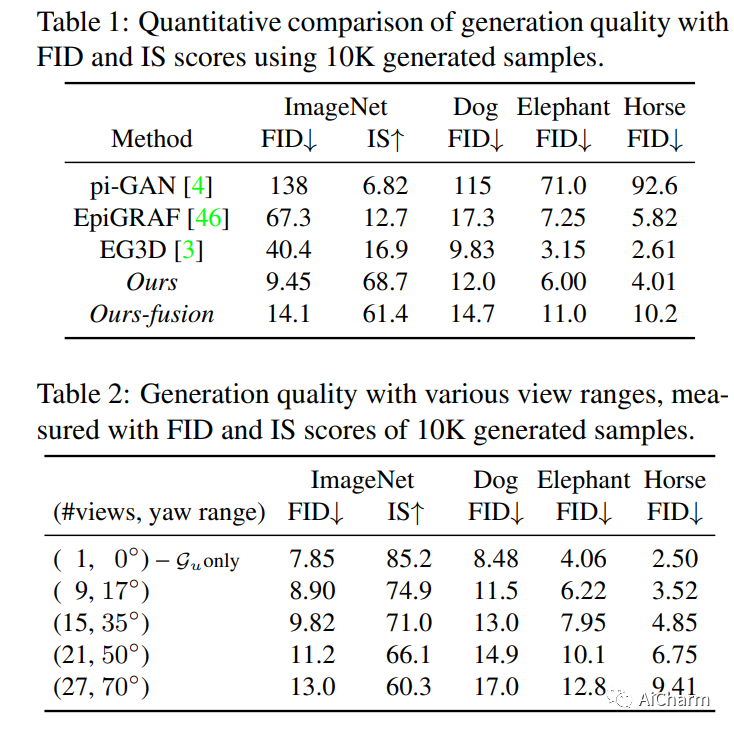
在本文中,我们介绍了一种利用 2D 扩散模型的新型 3D 感知图像生成方法。我们将 3D 感知图像生成任务制定为多视图 2D 图像集生成,并进一步制定为顺序无条件-条件多视图图像生成过程。这使我们能够利用 2D 扩散模型来提高该方法的生成建模能力。此外,我们结合来自单眼深度估计器的深度信息来构建仅使用静止图像的条件扩散模型的训练数据。我们在大规模数据集上训练我们的方法,即 ImageNet,这是以前的方法没有解决的。它产生的高质量图像明显优于以前的方法。此外,我们的方法展示了其生成具有大视角实例的能力,即使训练图像是多样且未对齐的,从“野外”现实世界环境中收集。
3.GlyphDraw: Learning to Draw Chinese Characters in Image Synthesis Models Coherently

标题:GlyphDraw:学习连贯地在图像合成模型中绘制汉字
作者:Jian Ma, Mingjun Zhao, Chen Chen, Ruichen Wang, Di Niu, Haonan Lu, Xiaodong Lin
文章链接:https://arxiv.org/abs/2302.01791v1
项目代码:https://1073521013.github.io/glyph-draw.github.io/


摘要:
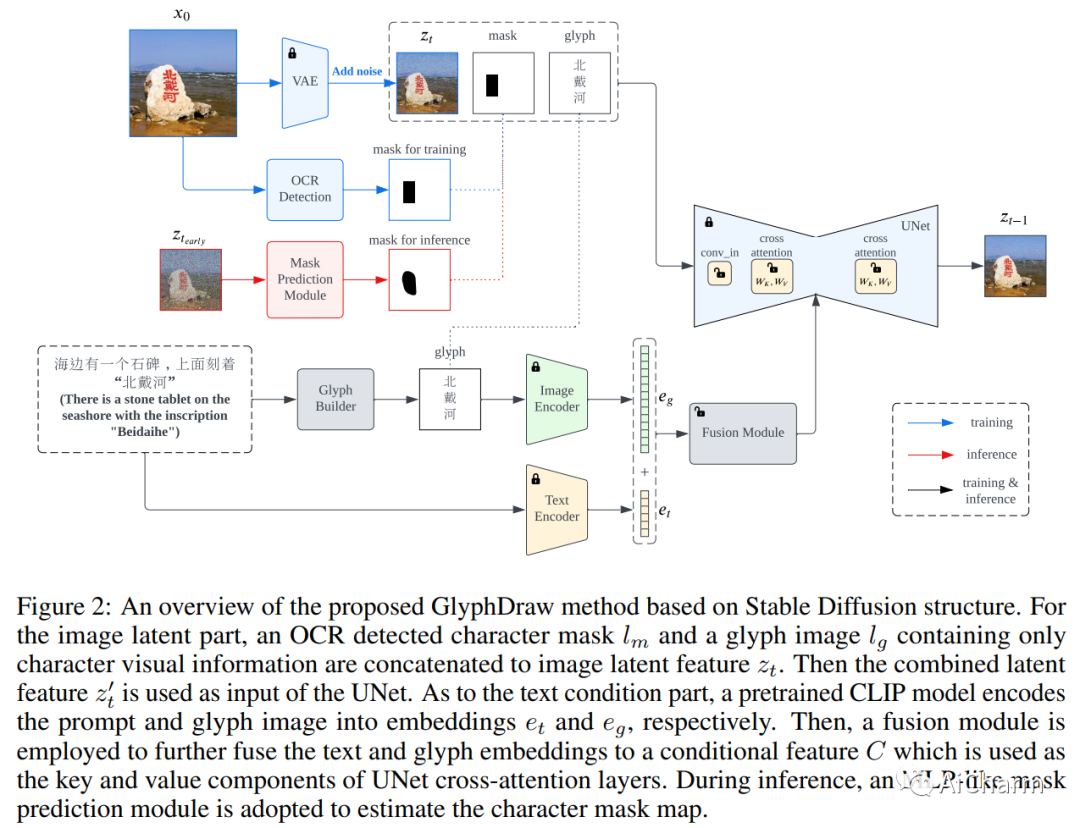
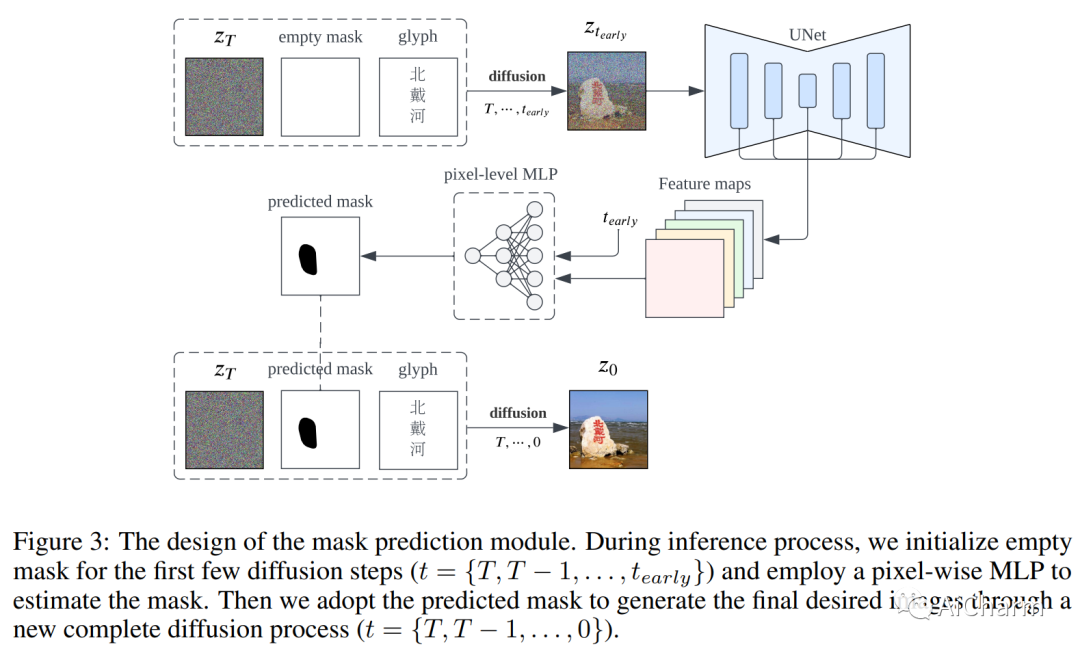
最近在语言引导图像生成领域取得的突破取得了令人瞩目的成就,能够根据用户指令创建高质量和多样化的图像。尽管合成性能令人着迷,但当前图像生成模型的一个重大限制是它们在图像中生成连贯文本的能力不足,特别是对于像汉字这样的复杂字形结构。为了解决这个问题,我们引入了 GlyphDraw,这是一个通用的学习框架,旨在赋予图像生成模型生成嵌入连贯文本的图像的能力。据我们所知,这是图像合成领域第一个解决汉字生成问题的工作。% 我们首先采用OCR技术采集带有汉字的图片作为训练样本,提取文字和位置作为辅助信息。我们首先精心设计图像-文本数据集的构建策略,然后专门在基于扩散的图像生成器上构建我们的模型,并仔细修改网络结构,使模型能够借助字形和位置信息学习绘制汉字。此外,我们通过使用各种训练技术防止灾难性遗忘来保持模型的开放域图像合成能力。大量的定性和定量实验表明,我们的方法不仅可以像提示中那样生成准确的汉字,而且可以自然地将生成的文本融入背景中。请参考这个 https 网址
更多Ai资讯:公主号AiCharm