CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention

标题:LLaMA-Adapter:具有零初始注意力的语言模型的高效微调
作者:Yutao Cui, Cheng Jiang, Gangshan Wu, LiMin Wang
文章链接:https://arxiv.org/abs/2303.16199
项目代码:https://github.com/ZrrSkywalker/LLaMA-Adapter

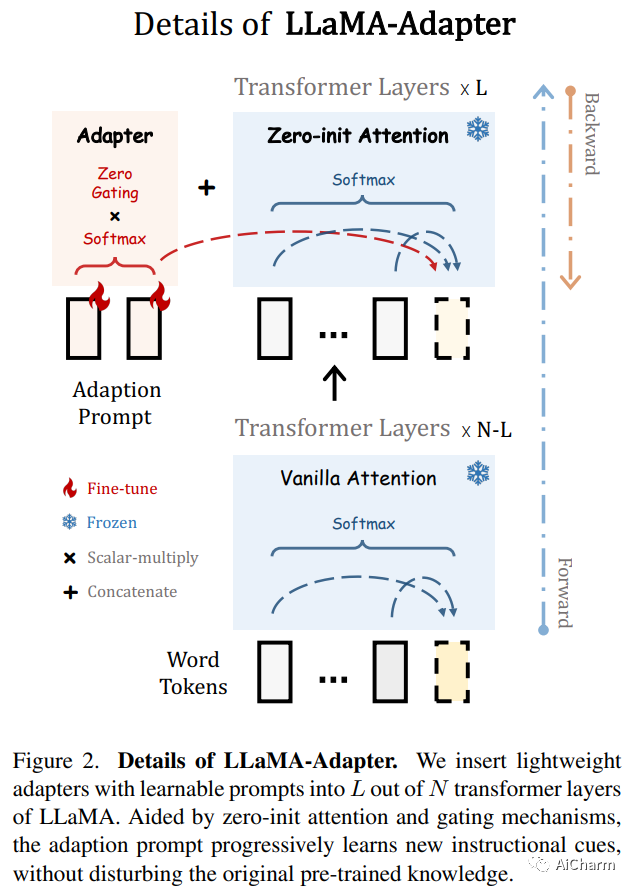
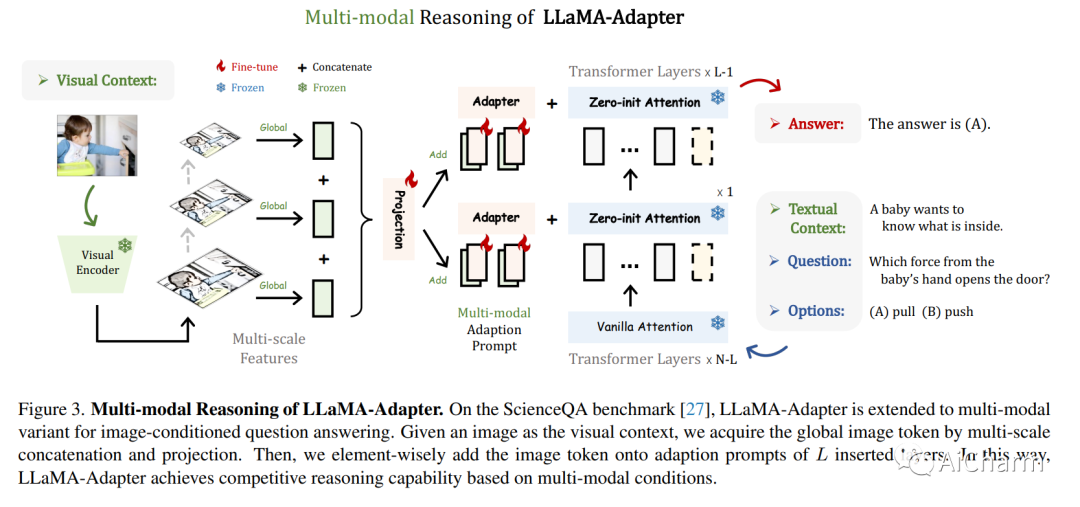

摘要:
我们提出了 LLaMA-Adapter,这是一种轻量级自适应方法,可以有效地将 LLaMA 微调为指令跟随模型。使用 52K 自我指导演示,LLaMA-Adapter 仅在冻结的 LLaMA 7B 模型上引入 1.2M 可学习参数,并且在 8 个 A100 GPU 上进行微调的成本不到一小时。具体来说,我们采用了一组可学习的自适应提示,并将它们添加到更高转换器层的输入文本标记中。然后,提出了一种具有零门控的零初始注意机制,该机制自适应地将新的教学线索注入 LLaMA,同时有效地保留其预训练知识。通过高效的训练,LLaMA-Adapter 生成高质量的响应,与具有完全微调的 7B 参数的羊驼相媲美。此外,我们的方法可以简单地扩展到多模态输入,例如图像,用于图像条件 LLaMA,从而在 ScienceQA 上实现卓越的推理能力。我们在这个 https URL 上发布我们的代码。
2.HOLODIFFUSION: Training a 3D Diffusion Model using 2D Images

标题:HOLODIFFUSION:使用 2D 图像训练 3D 扩散模型
作者:Animesh Karnewar, Andrea Vedaldi, David Novotny, Niloy Mitra
文章链接:https://arxiv.org/abs/2303.16509
项目代码:https://holodiffusion.github.io/
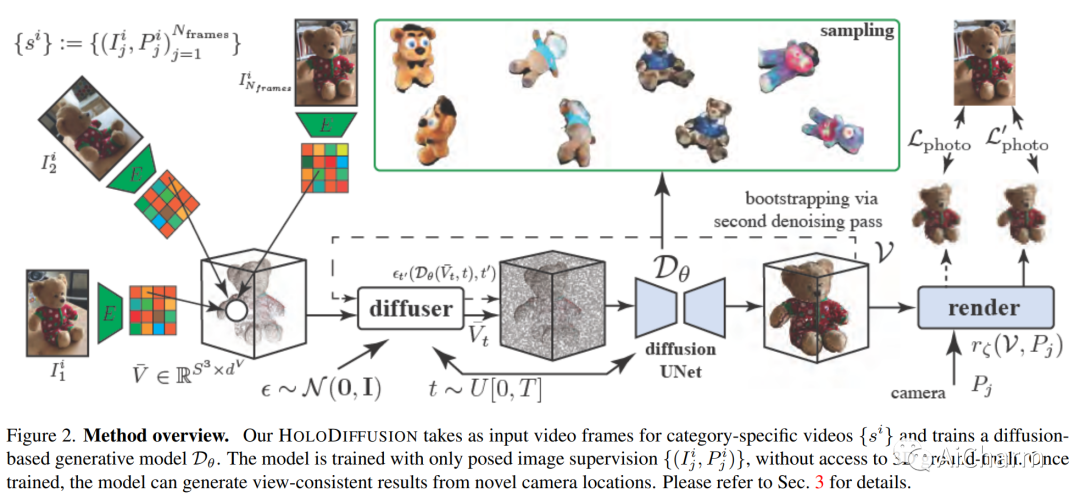

摘要:
扩散模型已成为 2D 图像生成建模的最佳方法。他们成功的部分原因在于有可能以稳定的学习目标对数百万甚至数十亿张图像进行训练。然而,由于两个原因,将这些模型扩展到 3D 仍然很困难。首先,寻找大量 3D 训练数据比寻找 2D 图像要复杂得多。其次,虽然扩展模型以在 3D 而不是 2D 网格上运行在概念上是微不足道的,但相关的内存和计算复杂性的立方增长使得这不可行。我们通过引入一种新的扩散设置来解决第一个挑战,该设置可以端到端地进行训练,仅使用用于监督的 2D 姿势图像;第二个挑战是提出一种将模型记忆与空间记忆分离的图像形成模型。我们使用之前未用于训练 3D 生成模型的 CO3D 数据集评估我们在真实世界数据上的方法。我们表明,我们的扩散模型具有可扩展性、训练鲁棒性,并且在样本质量和保真度方面与现有的 3D 生成建模方法相比具有竞争力。
3.Your Diffusion Model is Secretly a Zero-Shot Classifier

标题:您的扩散模型实际上是一个零样本分类器
作者:Alexander C. Li, Mihir Prabhudesai, Shivam Duggal, Ellis Brown, Deepak Pathak
文章链接:https://arxiv.org/abs/2303.16203
项目代码:https://diffusion-classifier.github.io/

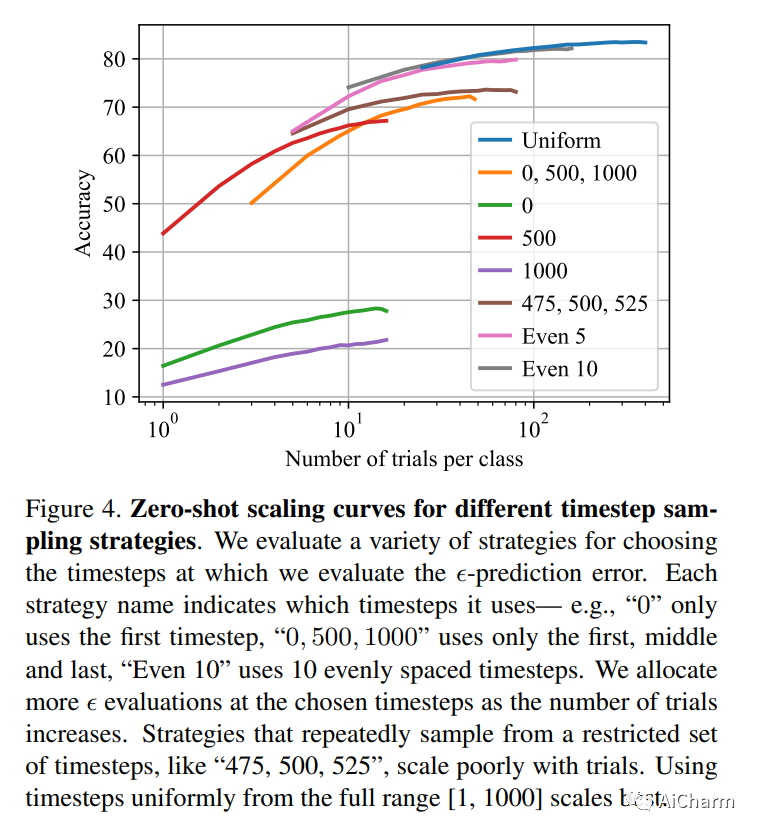


摘要:
最近的大规模文本到图像扩散模型浪潮极大地提高了我们基于文本的图像生成能力。这些模型可以为种类繁多的提示生成逼真的图像,并展现出令人印象深刻的构图泛化能力。到目前为止,几乎所有用例都只关注采样;然而,扩散模型也可以提供条件密度估计,这对于图像生成以外的任务很有用。在本文中,我们展示了从大规模文本到图像扩散模型(如 Stable Diffusion)的密度估计可用于执行零样本分类,而无需任何额外训练。我们称为扩散分类器的生成式分类方法在各种基准测试中取得了很好的结果,并且优于从扩散模型中提取知识的其他方法。尽管零镜头识别任务的生成方法和判别方法之间仍然存在差距,但我们发现我们基于扩散的方法比竞争判别方法具有更强的多模态关系推理能力。最后,我们使用扩散分类器从在 ImageNet 上训练的类条件扩散模型中提取标准分类器。尽管这些模型经过弱增强训练且没有正则化,但它们接近 SOTA 判别分类器的性能。总的来说,我们的结果是朝着对下游任务使用生成模型而不是判别模型迈出的一步。此 https URL 的结果和可视化
更多Ai资讯:公主号AiCharm