CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Breaking Common Sense: WHOOPS! A Vision-and-Language Benchmark of Synthetic and Compositional Images

标题:打破常识:哎呀!合成和合成图像的视觉和语言基准
作者:Nitzan Bitton-Guetta, Yonatan Bitton, Jack Hessel, Ludwig Schmidt, Yuval Elovici, Gabriel Stanovsky, Roy Schwartz
文章链接:https://arxiv.org/abs/2303.07274
项目代码:https://whoops-benchmark.github.io/


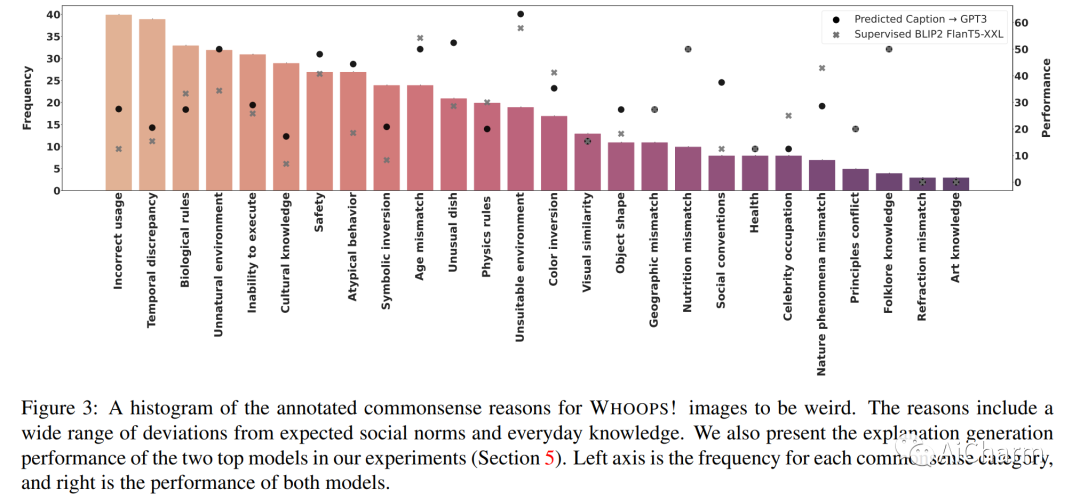


摘要:
怪异、不寻常和离奇的图像激起观察者的好奇心,因为它们挑战常识。例如,在 2022 年世界杯期间发布的一张图片描绘了著名足球明星莱昂内尔·梅西和克里斯蒂亚诺·罗纳尔多下棋,这调皮地违反了我们对他们的比赛应该在足球场上进行的预期。人类可以轻松识别和解读这些非常规图像,但 AI 模型也能做到吗?我们介绍了 WHOOPS!,这是一个新的视觉常识数据集和基准。该数据集由设计师使用公开可用的图像生成工具(如 Midjourney)创建的故意违背常识的图像组成。我们考虑对数据集提出的几个任务。除了图像说明、跨模态匹配和视觉问答之外,我们还引入了一项困难的解释生成任务,其中模型必须识别并解释给定图像异常的原因。我们的结果表明,最先进的模型(如 GPT3 和 BLIP2)在 WHOOPS! 上仍然落后于人类表现。我们希望我们的数据集能够激发具有更强视觉常识推理能力的 AI 模型的开发。
2.MELON: NeRF with Unposed Images Using Equivalence Class Estimation

标题:MELON:使用等价类估计的 Unposed 图像的 NeRF
作者:Axel Levy, Mark Matthews, Matan Sela, Gordon Wetzstein, Dmitry Lagun
文章链接:https://arxiv.org/abs/2303.08096
项目代码:https://melon-nerf.github.io/
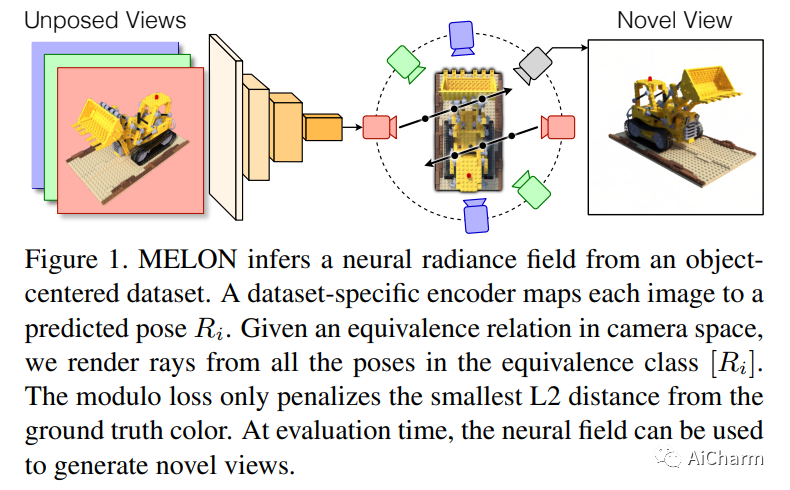


摘要:
神经辐射场可以从几张图像中实现具有逼真质量的新视图合成和场景重建,但需要已知且准确的相机姿势。传统的姿态估计算法在平滑或自相似场景上失败,而从未姿态视图执行逆向渲染的方法需要对相机方向进行粗略初始化。姿态估计的主要困难在于现实生活中的物体在某些变换下几乎是不变的,使得渲染视图之间的光度距离相对于相机参数是非凸的。使用匹配相机空间中局部最小值分布的等价关系,我们将这个空间减少到它的商集,其中姿态估计成为一个更凸的问题。使用神经网络来规范姿势估计,我们证明了我们的方法 - MELON - 可以从未摆姿势的图像中以最先进的精度重建神经辐射场,同时需要的视图比对抗方法少十倍。
3.OVRL-V2: A simple state-of-art baseline for ImageNav and ObjectNav

标题:OVRL-V2:ImageNav 和 ObjectNav 的简单最先进基线
作者:Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya, Naoki Yokoyama, Alexei Baevski, Zsolt Kira, Oleksandr Maksymets, Dhruv Batra
文章链接:https://arxiv.org/abs/2303.07798
项目代码:https://github.com/ykarmesh/OVRL
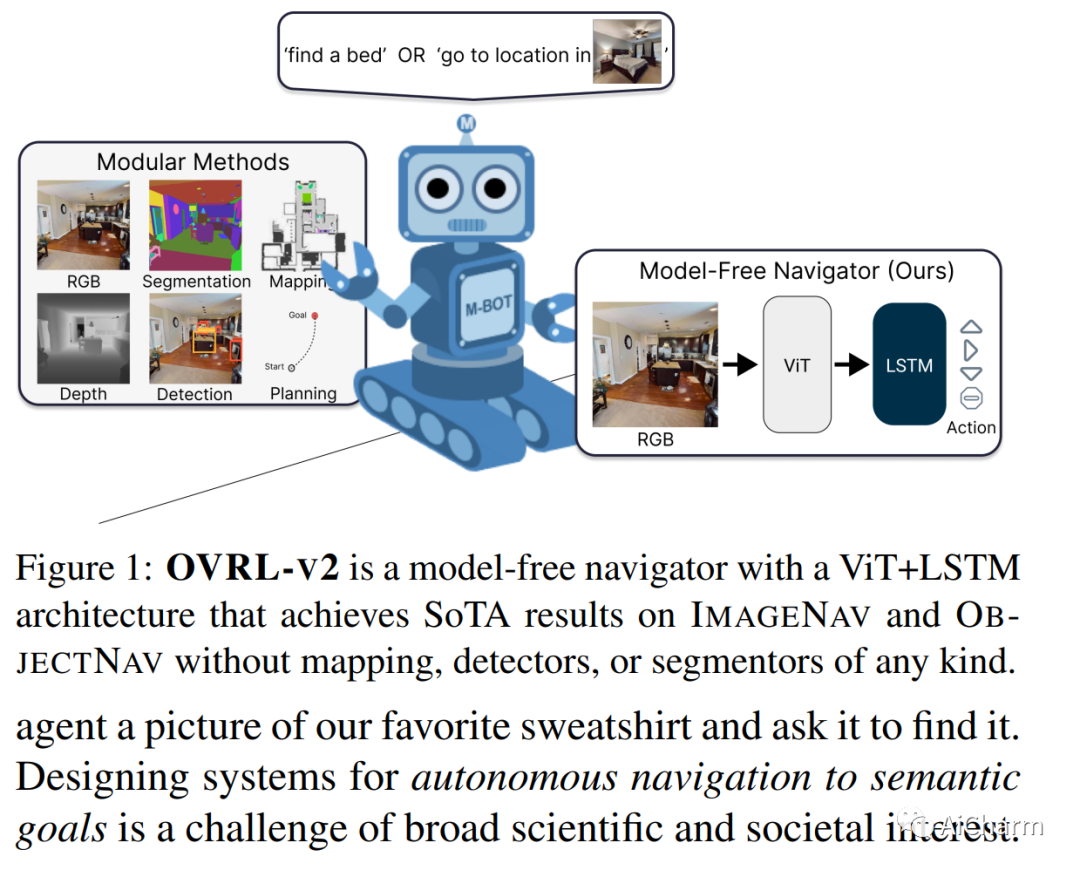
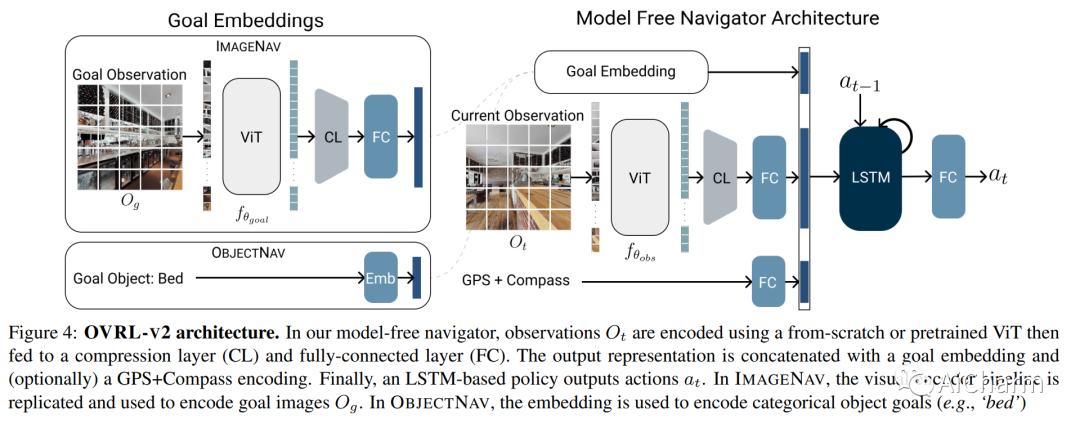
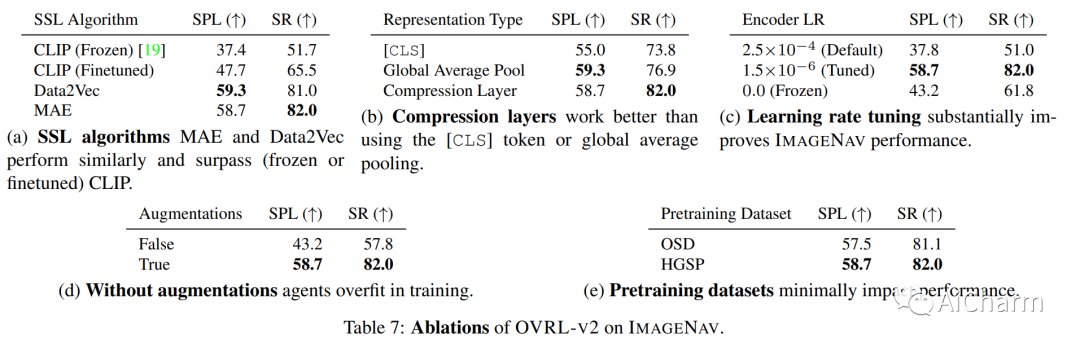
摘要:
我们提出了一个由任务不可知组件(ViT、卷积和 LSTM)组成的单一神经网络架构,该架构在 ImageNav(“转到 <this picture> 中的位置”)和 ObjectNav(“查找一把椅子”)任务,没有任何特定于任务的模块,如对象检测、分割、映射或规划模块。这种通用方法具有设计简单、可用计算正向缩放以及对多项任务的通用适用性等优点。我们的工作建立在最近成功用于预训练视觉转换器 (ViT) 的自我监督学习 (SSL) 的基础上。然而,虽然卷积网络的训练方法成熟且稳健,但 ViTs 的方法是偶然且脆弱的,并且在用于视觉导航的 ViTs 的情况下,尚未完全被发现。具体来说,我们发现 vanilla ViTs 在视觉导航方面的表现并不优于 ResNets。我们建议使用在 ViT 补丁表示上运行的压缩层来保存空间信息以及策略训练改进。这些改进使我们能够首次在视觉导航任务中展示正比例定律。因此,我们的模型将 ImageNav 上的最先进性能从 54.2% 提高到 82.0% 的成功率,并且与 ObjectNav 上的并发最先进性能相比具有竞争力,成功率为 64.0% 对 65.0%。总的来说,这项工作并没有提出一种全新的方法,而是提出了训练通用架构的建议,该架构可以达到当今最先进的性能,并可以作为未来方法的强大基线。
更多Ai资讯:公主号AiCharm