前段时间系统整理了一下关于YOLO系列论文并进行一些补充解释,如下:
目录
3.1 Bag of freebies(BOF)——提升检测精度而不增加推理时间
3.2 Bag of specials(BOS)——小幅提高推理代价,带来极大性能提升
1. 目标检测发展时间线

2. 目标检测网络结构

Input:模型的输入——图片、图片块、图片金字塔
Backbones:特征提取器,先在分类数据集(如ImageNet)上进行预训练,再检测数据上进行微调
- GPU平台上运行的检测模型,常用的backbone有VGG、ResNet、DarkNet等
- CPU平台或边缘设备上运行的检测模型,常用的backbone为MobileNet、ShuffleNet、SqueezeNet等
Neck:融合不同特征层的特征,将浅层丰富的位置信息和深层丰富的语义信息进行融合,提升检测效果
- Additional blocks:SPP,ASPP,RFB,SAM
- Path-aggregation blocks:FPN,PAN,NAS-FPN,Fully-connected FPN,BiFPN,ASFF,SFAM
Heads: 物体定位和分类
- Dense Prediction:即one-stage方法
- anchor based:YOLO系列,SSD,RetinaNet,RPN
- anchor free:CornerNet,CenterNet,MatrixNet,FCOS
- Sparse Prediction:即two-stage方法
- anchor based:Faster R-CNN,R-FCN,Mask R-CNN
- anchor free:RepPoints
3. 目标检测优化技巧
3.1 Bag of freebies(BOF)——提升检测精度而不增加推理时间
- 数据增强
- 光度变换: 调整亮度,对比度,色相,饱和度和噪点
- 几何变换: 随机缩放,裁剪,翻转和旋转
- 模拟目标遮挡: random erase ,CutOut, Hide and Seek, grid Mask
- 图像融合:MixUp、CutMix、Mosaic
- GAN
- 边界框回归的损失函数
- IOU Loss
- GIOU Loss
- DIOU Loss
- CIOU Loss
- 正则化
- DropOut
- DropConnect
- DropBlock
- 标签平滑——Label Smoothing
- 数据不平衡——Focal Loss
3.2 Bag of specials(BOS)——小幅提高推理代价,带来极大性能提升
- 增强感受野
- SPP
- ASPP
- RFB
- 特征融合
- 跳层连接
- FPN
- SFAM
- ASFF
- BiFPN
- 后处理方式
- NMS
- soft NMS
- DIOU NMS
- 注意力模块
- 通道注意力(channel-wise) SE
- 空间注意力(point-wise) SAM
- 激活函数
- LReLU(解决当输入小于0时ReLU梯度为0的情况)
- PReLU(解决当输入小于0时ReLU梯度为0的情况)
- ReLU6(专门为量化网络设计)
- hard-swish(专门为量化网络设计)
- SELU(对神经网络进行自归一化)
- Swish(连续可微激活函数)
- Mish(连续可微激活函数)
4. 目标检测评价指标
4.1 速度指标
速度指标通常用每秒推断帧数FPS(Frames Per Second)衡量,受硬件影响较大
4.2 准确度指标
目标检测输入图像,输出图像中各个目标预测框的矩形坐标及各类别预测置信度,采用交并比IOU衡量预测框和标注框的重合程度,即预测框的定位是否准确

根据与标注框的关系,可将某一预测框划分为以下四类中的某一类,其中IOU阈值(一般为0.5)和置信度阈值(一般为0.2)由人工指定:
 (1)Precision(查准率):所有预测框中预测正确的比例,反映了模型“不把背景冤枉成目标”的准确性
(1)Precision(查准率):所有预测框中预测正确的比例,反映了模型“不把背景冤枉成目标”的准确性
(2)Recall(查全率、召回率):所有标注框中被正确预测的比例,反映了模型“不把目标放过为背景”的敏感性
 (3)Average Precision(平均精度,简称AP):将置信度阈值从0-1变化,计算每个置信度阈值对应的Precision和Recall,绘制成某类别的PR性能曲线(P和R均不能完整的表征网络的预测效果, 希望P和R同时为较大的值,即PR曲线与坐标轴围成的面积更大),其围成的面积为该类别的AP
(3)Average Precision(平均精度,简称AP):将置信度阈值从0-1变化,计算每个置信度阈值对应的Precision和Recall,绘制成某类别的PR性能曲线(P和R均不能完整的表征网络的预测效果, 希望P和R同时为较大的值,即PR曲线与坐标轴围成的面积更大),其围成的面积为该类别的AP
 取所有类别的AP和不同的IOU阈值,可分别计算[email protected]和[email protected]:0.95
取所有类别的AP和不同的IOU阈值,可分别计算[email protected]和[email protected]:0.95
[email protected]:IOU阈值取0.5时,各类别AP的平均值 
[email protected]:0.95:IOU阈值分别取以0.05为步长,从0.5增大至0.95的10个数时,各类别AP的平均值

5. YOLOv1
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法——找到图片中某个存在对象的区域,然后识别出该区域中具体是哪个对象,其最大的特点是运行速度很快,可以用于实时系统。
两阶段目标检测第一阶段提取潜在的候选框(Region Proposal),第二阶段用分类器逐一筛选每个候选框,YOLO创造性的将候选区和对象识别两个阶段合二为一。
实际上,YOLO并没有真正去掉候选区,而是采用了预定义的候选区,将图片划分为 7 x 7=49 个网格,每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49 x 2=98 个bounding box。

5.1 YOLOv1网络结构

输入图像的尺寸为448 × 448,经过24个卷积层2个全连接层,reshape操作,输出的特征图大小为7 × 7 × 30(PASCAL VOC数据集)。
主要思想:
- 将输入图像分成S*S网格,每个网格负责预测中心在此网格中的物体
- 每个网格预测B个bounding box及其置信度,以及C个类别概率
- bbox信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,均被归一化
- x, y 是bounding box中心点相对于所在grid cell左上角格点的坐标
- w,h 是bounding box相对于整幅图像的宽和高
- 置信度反映是否包含物体,以及包含物体情况下位置的准确性。定义为Pr(Object)×IoU,其中Pr(Object)∈{0,1}
5.2 输入和输出的映射关系


5.3 损失函数
图中自行车的中心点位于4行3列网格中,所以输出tensor中4行3列位置的30维向量如右上图所示
损失:网络实际输出值与样本标签值之间的偏差

损失函数:
5.4 YOLOv1优缺点
YOLOv1优点:
- 不需要提取候选框再对候选框逐一分类和回归(单阶段),一次前向推理得到bbox定位及分类结果,无复杂上下游处理工作,端到端训练优化,速度快,达到实时效率
- 迁移泛化好
- Background误差小,直接选用整图训练,能获取全局信息(RCNN系列只对候选框区域进行处理,管中窥豹)
YOLOv1缺点:
- 目标定位误差高,精度不足
- mAP低,准确度低,Recall低(比RCNN系列低)——“目标框不准,该检的检不出”
原因分析:
- 采用全连接层进行最终预测,而全连接层可以认为是作用在全图特征的函数,目标检测是一个局部预测问题,以全图特征预测局部对象的位置信息本身就是矛盾的
- YOLOv1采用7 x 7的网格划分,总共预测98个框,很难实现对图像上出现的目标有效覆盖,全部目标全部检出的能力差
- YOLOv1的每个网格单元仅产生一个预测框,一个网格只能预测一个物体,导致YOLO-V1针对分布较密集的小型目标会产生比较严重的漏检现象
6. YOLOv2
6.1 改进策略
YOLOv1虽然检测速度快,但定位不够准确,并且召回率较低。为了提升定位准确度,改善召回率,YOLOv2在YOLOv1的基础上提出了几种改进策略,如下图所示:

1)Batch Normalization——increase of 4% mAP
- YOLOv2中在每个卷积层后加Batch Normalization(BN)层,去掉了dropout层
- Batch Normalization层可以起到一定的正则化效果,能提升模型收敛速度,防止模型过拟合
2)High Resolution Classifier(高分辨率预训练分类网络)——mAP提高4%
- 一般的图像分类网络,以很小的图像分辨率在ImageNet上进行预训练,例如224 x 224
- YOLOv1网络输入为448 x 448,从小分辨率切换到大分辨率,导致性能的降低
- 为了使网络适应新的分辨率,YOLOv2先以224 x 224在ImageNet训练,再以448 × 448的分辨率在ImageNet进行10个epoch的微调,最后再以448 × 448在目标检测数据集上进行微调

3)Anchor Boxes——Recall提升7%,mAP降低0.3%
- YOLOv1将图片划分为7 x 7的网格,每个网格预测两个bounding box,与ground truth的IOU大的bbox负责拟合该ground truth,利用全连接层直接对边界框进行预测,导致丢失较多空间信息,定位不准
- YOLOv2去掉YOLOv1中的全连接层,使用类似Faster R-CNN和SSD的锚点机制,使用Anchor Boxes预测边界框,在卷积特征图上的每个位置绑定若干个具有不同尺度、不同长宽比的预定义Anchor Boxes,每个Anchor Boxes只需要在原有位置上进行微调,预测偏移量,仍旧是与ground truth的IOU大的Anchor Box负责拟合该ground truth,最后用来预测的卷积特征图为与之对应的包围框位置变换参数、置信度和目标类别概率
- 即:人工标注框的中心点落在哪个grid cell里面,就由这个grid cell产生的Anchor中与ground truth的IOU最大的Anchor负责预测,只需要预测出相对于本身的偏移量即可
- Motivation:解决一个网格中存在多个目标的问题(YOLOv1一个网格中只能检测一个目标)
注意⚠️:
Tips1:YOLOv2将feature map设为奇数长宽
 原因:奇数长宽的feature map有中心cell,若图像中有占主导的大目标,则它的中心点有确定的grid cell负责预测,而不是偶数长宽有四个grid cell去抢
原因:奇数长宽的feature map有中心cell,若图像中有占主导的大目标,则它的中心点有确定的grid cell负责预测,而不是偶数长宽有四个grid cell去抢
Tips2:mAP降低,Recall提升,则Precision降低了
原因:YOLOv1最多产生98个预测框,YOLOv2加入Anchor后产生845个预测框,尽可能可以把目标全部检测出来,所以Recall提升了,但845个框里面没用框的比例也增大了,Precision降低了(可以通过后处理来减少精度降低带来的影响,所以加Anchor是值得的)
- Faster RCNN的Anchor产生的9个候选框是“人为”选择的(事先设定尺度和长宽比参数,按照一定规则生成),YOLOv2为了选择更合理的候选框(很难与gt建立对应关系的Anchor实际上是无效的),使用了聚类(K-means)的策略 (对数据集长宽比进行聚类,实验聚类出多个数量不同anchor box组,分别应用到模型中,找出在模型的复杂度和高召回率之间折中的那组anchor box)

- 优点:使用anchor机制生成密集的anchor box,使网络能够直接在此基础上进行目标分类和边界框坐标回归,有效提高网络目标的召回能力,对小目标的检测有非常明显的提高
- 缺点:冗余框非常多,一张图片内的目标只是有限的,每个anchor设置大量的anchor box会产生大量的完全不包含目标的背景框,引起正负样本严重失衡的问题
- 注:预测框是以Anchor为基准,在Anchor基础上偏移得到的
4)Dimension Clusters(Anchor Box的宽高由聚类产生)
- YOLOv2采用k-means聚类算法对训练集中的边界框做了聚类分析,选用boxes之间的IOU值作为聚类指标
- 聚类分析得到的先验框比手动选择的先验框有更高的平均IOU值,这使得模型更容易训练学习
- 注意:在标准K-means在聚类时采用欧几里得(Euclidean)度量作为聚类的距离判定标准,而在这种度量下,大框往往会产生比小框更大的误差,因此,YOLOv2在K-means聚类中使用更能体现框重叠关系的距离度量IOU
5)Direct location prediction(绝对位置预测)——mAP提高5%
- YOLOv1每个grid cell预测两个框,这两个框野蛮生长,可以跑到图像中任何位置,YOLOv2加入Anchor后,预测相对Anchor的偏移量,按道理,这个偏移量仍可以全图乱窜,导致模型非常不稳定
- 即相对位置是随机的,意味着在训练时要求预测得到的偏移量变换系数“一会儿正一会儿负”,导致模型在训练时产生严重震荡
- 产生上述问题的原因在于目标包围框的位置不受到任何限制,出现的位置太过于随机
- YOLOv2沿用YOLOv1的方法,根据所在网格单元的位置来预测坐标,在进行生成预测框时,有时候生成的预测框会超出图片的边界线,因此为了解决这一个问题,提出了使用绝对位置预测来限制预测框出现的位置(YOLOv1只是从这个村子出生,它仍然可以纵横天下,但在YOLOv2里生老病死全在这个村里了)

- 如上图所示:
- Cx, Cy:grid cell左上角x, y坐标
- Pw, Ph:Anchor宽高 ——注:grid cell长宽归一化为1 x 1(需乘以grid cell下采样倍数,得到原始输入图像上预测框x,y坐标)
- bx, by:预测框x, y坐标
- bw, bh:预测框宽高
6)Direct location prediction(绝对位置预测)——mAP提高5%

- YOLOv2采用Darknet-19,包括19个卷积层和5个max pooling层
- 主要采用3 × 3卷积和1 × 1卷积,1×1卷积(先降维再升维)可以压缩特征图通道数以降低模型计算量和参数
- 每个卷积层后使用BN层以加快模型收敛同时防止过拟合
- YOLOv2通过缩减网络,使用416 × 416的输入,模型下采样的总步长为32,最后得到13 × 13的特征图,然后对13 × 13的特征图的每个cell预测5个Anchor Boxes,可以预测13 × 13 × 5 = 845个边界框
- 全卷积代替全连接: 与Faster R-CNN和SSD类似,YOLOv2利用具有小卷积核的全卷积层替换YOLOv1最后的全连接层进行目标框预测,该操作的实质即以局部特征代替全局特征来预测框,在一定程度上恢复局部框预测模式
7)Fine-Grained Features(细粒度特征)——提升了1%
- YOL v2借鉴SSD使用多尺度的特征图做检测,提出pass through层将高分辨率的特征图与低分辨率的特征图联系在一起,从而实现多尺度检测

- pass through拆分方法:

8)Multi-Scale Training(多尺寸训练)——在速度和精度上进行自由权衡
- YOLOv2采用多尺度输入的方式训练,在训练过程中每隔10个batches,重新随机选择输入图片的尺寸
- 由于Darknet-19下采样总步长为32,输入图片的尺寸一般选择32的倍数{320,352,…,608}
- 采用Multi-Scale Training, 可以适应不同大小的图片输入,当采用低分辨率的图片输入时,mAP值略有下降,但速度更快,当采用高分辨率的图片输入时,能得到较高mAP值,但速度有所下降

6.2 损失函数
论文中没有明确提出损失函数,下图来自同济子豪兄的损失函数解析:

6.3 输入和输出的映射关系

6.4 YOLOv2优缺点
- YOLOv2相较于之前的版本有了质的飞跃,主要体现在吸收了其他算法的优点,最主要的是引入了Anchor,同时利用了多种训练技巧,在网络设计上做了很多tricks,使得模型在保持极快速度的同时大幅度提升了检测的精度
- 单层特征图:虽然采用了Passthought层来融合浅层特征,增强多尺度检测性能,但仅仅采用一层特征图做预测,细粒度仍然不够,对小物体等检测提升有限,并且没有使用残差这种较为简单、有效的结构,受限于其整体网络架构,仍然没有很好地解决小物体的预测问题
7. YOLOv3
YOLOv3主要是融入目前较好的检测思想到YOLO中,在保持速度优势的前提下,YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,进一步提升了检测精度,尤其是对小物体的检测能力。具体来说,YOLOv3主要改进了网络结构、网络特征及后续计算三个部分。
7.1 YOLOv3网络结构
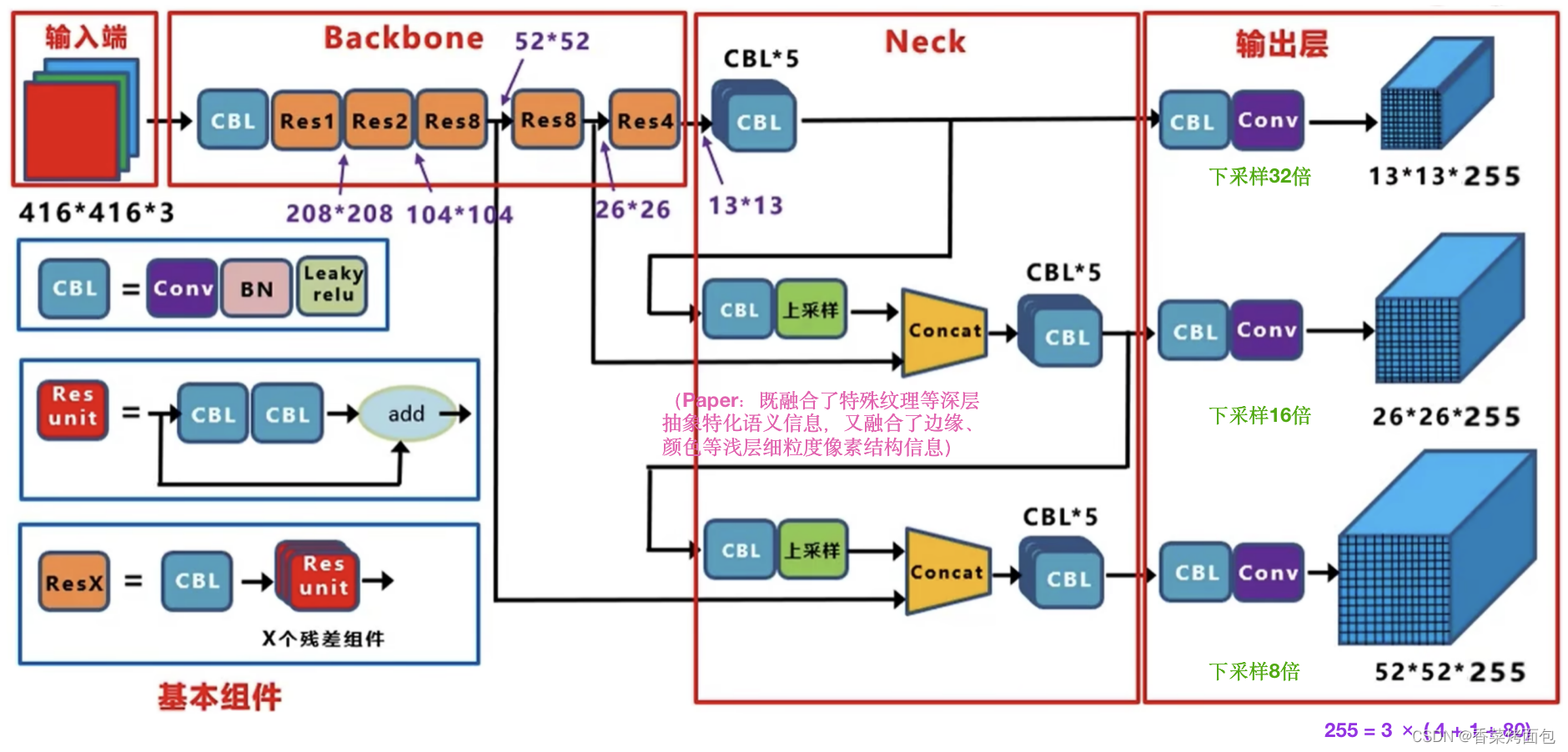
(来自江大白的网络结构图)
- 残差思想:Backbone DarkNet-53借鉴了ResNet的残差思想,在基础网络中大量使用了残差连接,因此网络结构可以设计的很深,并且缓解了训练中梯度消失的问题,使得模型更容易收敛
- 多层特征图:通过上采样与Concat操作,融合了深浅层的特征,最终输出了3种尺寸的特征图,有利于多尺度物体及小物体检测
- 无池化层:DarkNet-53没有采用池化,通过步长为2的卷积核来达到缩小尺寸的效果,下采样5次,总体下采样率为32(输入图像大小为32的倍数即可,输入越大,得到的三个特征图越大)
7.2 Backbone:Darknet-53
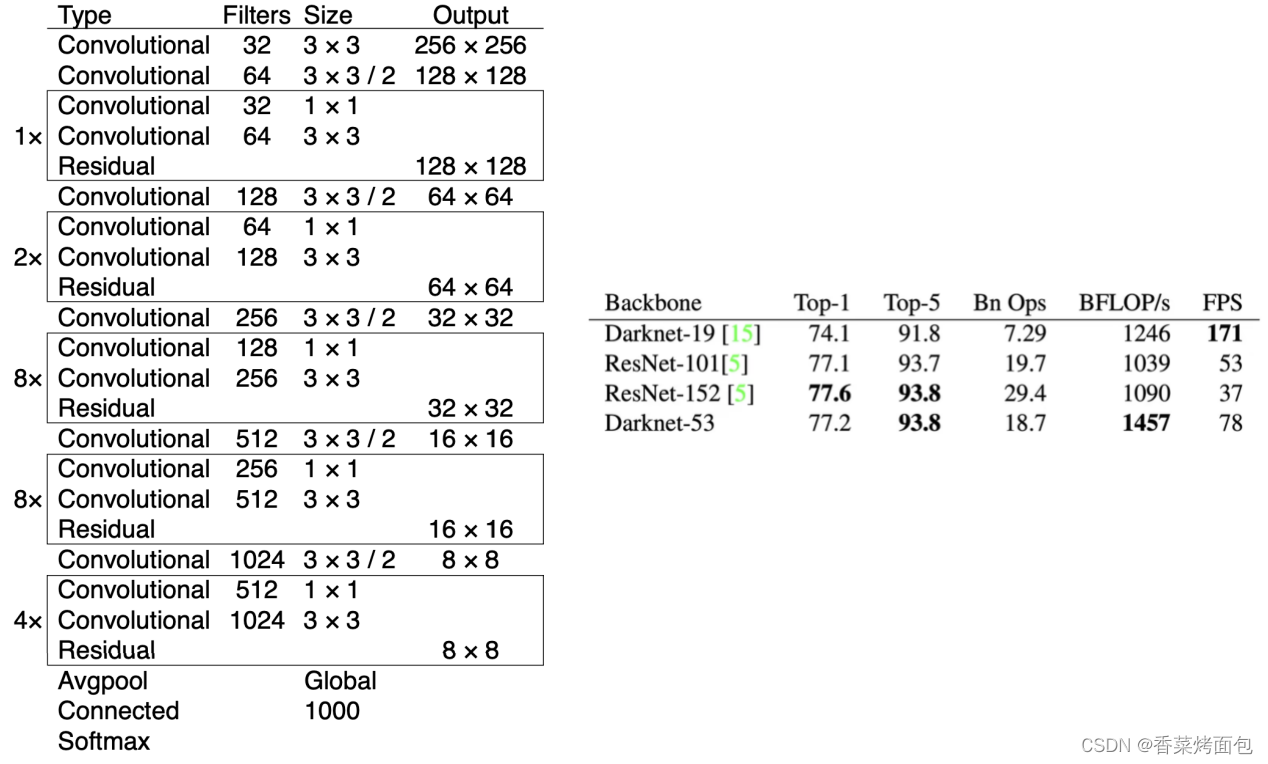
- Backbone:DarkNet-53(混合DarkNet-19和ResNet)——特征提取器(骨干网络提供食材,后续进行烹饪,好的食材不一定能做出好饭,但没有好食材肯定做不了好饭,骨干网络提取好的特征)
- Darknet-53采用连续的3 x 3卷积和1 x 1卷积,一共有53个带权重的层(52个卷积层+一个全连接),对于ResNet-152和ResNet101在分类精度上差不多,计算速度更快,网络层数更少
- Darknet-53能更高效利用GPU,更快进行前向推断(ResNet层数太多)

- YOLOv3在AP0.5表现好,说明当IOU阈值(影响正负样本的划分,从而影响模型训练结果)设置比较小时,大概能定位正确;当IOU阈值提升,例如提升至0.95时,预测框必须和GT非常重合,才能判定此框为TP,预测正确,此时YOLOv3性能较差——精准定位性能差
- YOLOv3在小目标和密集目标的改进:
- grid cell个数增加(YOLOv2和YOLOv3兼容任意图片大小输入——全卷积网络)
- 设置了针对小目标的Anchor
- 整合了多尺度的特征进行多尺度预测(FPN)
- 损失函数增加了惩罚小框项
- 网络结构使用跨层连接且骨干网络的特征提取能力增强
7.3 输入和输出的映射关系

- 输入:416x416的图像,通过Darknet网络得到三种不同尺度的预测结果(受FPN特征金字塔的启发),每个尺度都对应255个通道(85 x 3),包含着预测的信息,每个网格每个尺寸的anchors的预测结果
- YOLOv1:输入448 x 448,划分为7 x 7网格,无Anchor,生成B个bbox(B=2),产生7 x 7 x 2 = 98个预测框,类别数C=20,输出张量维度为7 x 7 x (5 x B + C)
- YOLOv2:输入416 x 416,每个grid cell五个Anchor,每个grid cell对应的原图感受野大小一样,对大小目标一视同仁(pass through),产生13 x 13 x 5 = 845个预测框,输出张量维度为13 x 13 x 5 x ( 5 + 20 )
- YOLOv3:输入416 x 416,生成13 x 13(大目标),26 x 26(中目标),52 x 52(小目标)三个尺度feature map,每个尺度三个Anchor,产生(13x13 + 26x26 + 52x52) x 3 = 10647个预测框,每个预测对应85维,分别是4(坐标值),1(置信度分数),80(coco类别数)
7.4 YOLOv3 Anchor

- YOLOv3每个grid cell分配三个Anchor(聚类),一共9个Anchor
- 13 x 13 feature map:对应原图的感受野是一个grid cell对应原图32 x 32的像素,下采样32倍,负责预测大目标,对应大Anchor
- 26 x 26 feature map:负责预测中目标
- 52 x 52 feature map:负责预测小目标

- 例如,落在某grid cell中的目标,由该grid cell的Anchor中与目标ground truth的IOU最大的Anchor预测该目标,但是每个尺度都有一个IOU最大的Anchor,究竟由哪个尺度的grid cell对应的Anchor预测呢?
- 由所有Anchor中与目标ground truth的IOU最大的Anchor负责预测,YOLOv3不再看中心点落在哪个grid cell里面,而是看谁IOU最大
7.5 正负样本匹配规则
- 正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例
- 一个预测框只能分配给一个ground truth负责预测(IOU最大的)
- 正例产生置信度loss、检测框loss、类别loss,类别标签对应类别为1,其余为0,置信度标签为1
- 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例
- 忽略样例不产生任何loss
- 负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例
- 负例只有置信度产生loss,置信度标签为0

注意⚠️:
- YOLOv1按照中心点分配对应的预测box,YOLOv3根据预测值寻找IOU最大的预测框作为正例,是由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分,忽略样例是Yolov3中的点睛之笔
- Yolov1/2中的置信度标签是预测框与真实框的IOU,而Yolov3是0和1,意味着该预测框是或者不是一个真实物体,是一个二分类
- Yolov1/2中使用IOU作为置信度阈值有何不好?
- 很多预测框与gt的IOU最高只有0.7(这个值本来就不高,把这个值作为标签,很难训练,若直接把标签设为1,明确告诉模型这就是正样本,好好学,当成偶像学,而不是只学0.7)
- COCO数据集中小目标非常多,IOU对像素偏移很敏感,无法有效学习——《Augmentation for small object detection》
7.5 输入和输出的映射关系

7.6 损失函数
下图来自同济子豪兄的损失函数解析:

注意⚠️:YOLOv3尝试使用了Focal Loss,mAP反而降低了两个点
原因分析:Focal Loss解决单阶段目标检测“正负样本不均衡,真正有用的负样本少”的问题,相当于是某种程度的难例挖掘。YOLOv3中负样本IOU阈值设置过高(0.5),导致负样本中混入疑似正样本(label noise),而Focal Loss又会给这些noise赋予更大的权重,因此效果不好
7.7 训练过程和测试过程

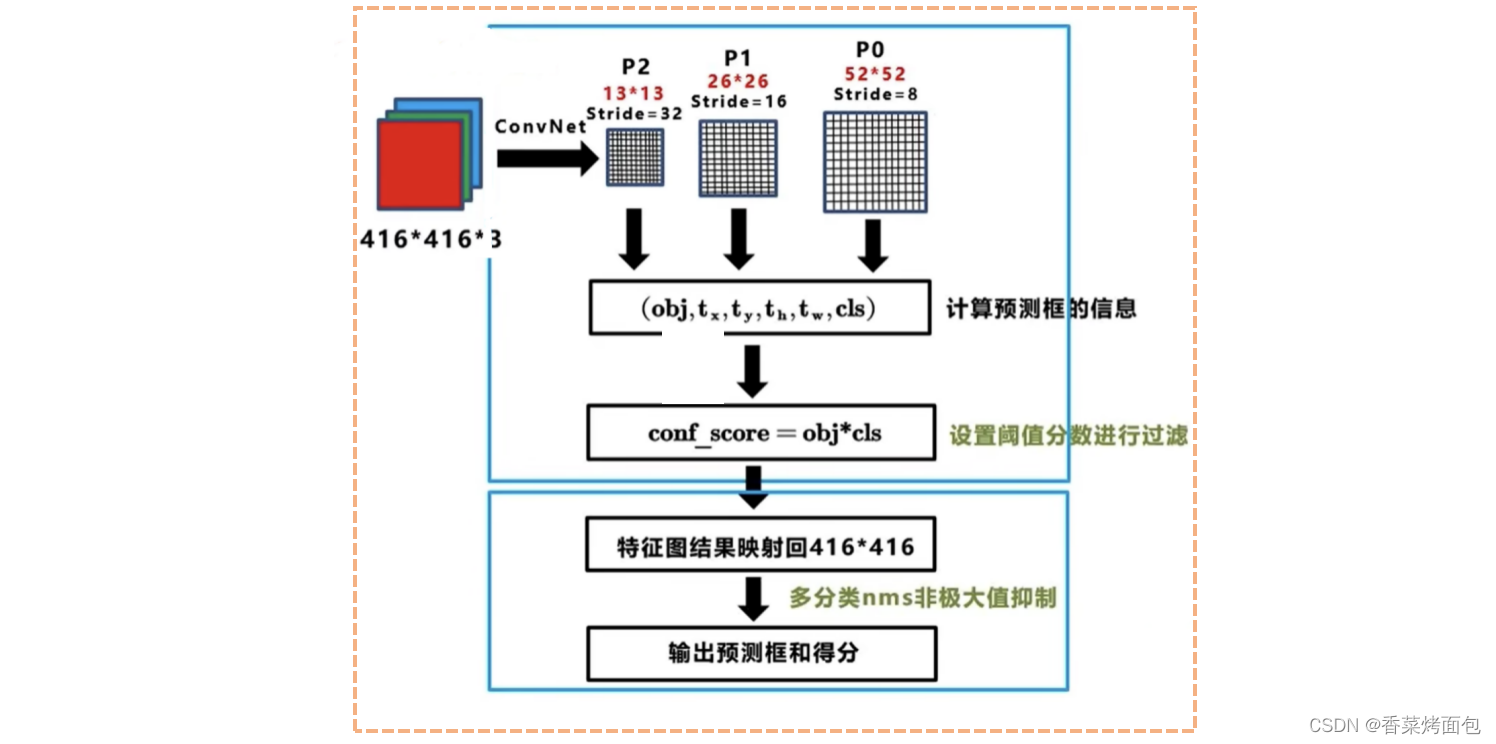
7.8 YOLOv3优缺点
YOLOv3优点:
- 推理速度快,性价比高
- 背景误检率低
- 通用性强
YOLOv3缺点:
- 召回率较低
- 定位精度较差
- 对于靠近或者遮挡的群体、小物体的检测能力相对较弱