首先介绍一下yolo的名字来源:you only look once, 翻译过来就是你只需要看一次,所以显而易见yolov3是单阶段目标检测算法。
那么:1.为什么yolov3会成为“单”阶段目标检测算法而不是“二”阶段呢?
2.为什么yolov3会被关注?为什么我要从yolov3开始给大家讲?
3.yolov3相比于最开始的传统rcnn系列网络最精妙的地方你觉得是哪里?
带着这些问题,我们开始接下来的学习吧,学习完之后,在评论区留下你的答案吧!
注意我在这里直接开始了yolov3的讲解并没有说明目标检测的原理和现状,在后面我会讲rcnn系列,在那里我会从头开始讲,初学者建议从rcnn开始。
在yolov3出来之后yolo才被正式关注的,值得注意的是,往后的yolo(v4-v5)在整体架构上都与yolov3差别不大,所以了解yolov3是学习yolo系列算法不可缺少的一步。
YOLOv3算法的基本思想可以分成两部分:
YOLOV3框架如上图所示,其实,整个框架可划分为3个部分:分别为Darknet-53(实际只用了52层)结构(特征提取)、特征层融合结构(上图concat部分)、三个侦测头(Y1,Y2,Y3),那这三个部分有啥作用或者说怎样工作的呢?
下面从网络结构的输入说起,给一张图像x(大小:416×416)输入到Darkenet-53网络结构,进行一系列的卷积以及参差网络,分别得到原图:1/8(大小:52×52)、1/16(大小:16×26)、1/32的特征图(即feature map),这个过程就是所谓的特征提取过程。
可能大家想问得到这3个不同尺寸的feature map有什么用呢?为什么要分3个featrue map?
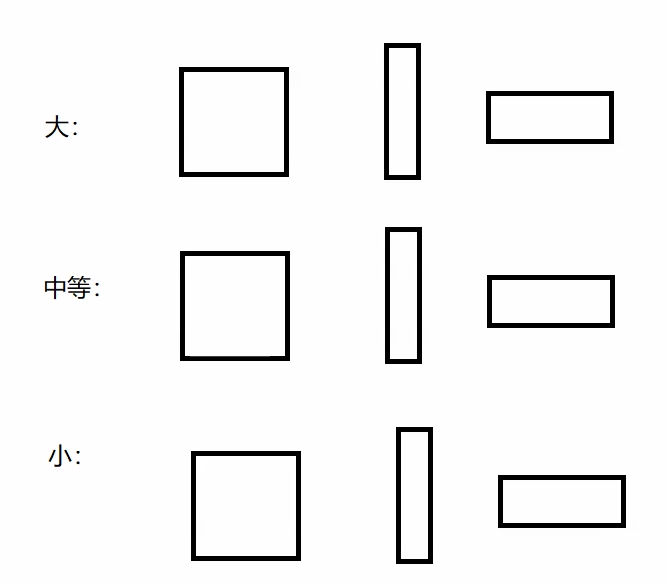
传统的faster-RCNN采用了2000个锚框,而yolov3跨时代的只采用了9个,世界上的矩形框可以分为:大、中、小,每个大小又对应三种框即(这就是yolov3最精妙的地方之一):
有了3个不同尺寸的feature map,本应该直接利用这些特征进行分类检测的,但考虑到这样的特征层可能表现能力不够,或者说,提取的这些特征不能充分的反应原图中的目标信息。所以接下来需要将3个特征图进行特征融合,以获得更强的特征表现力,从而达到更好的效果;其中由于尺寸不一样,中间需要进行上采样以及下采样(其实就是卷积),使特征图变成相同大小,然后进行堆叠、融合及相应的卷积等操作后,得到最终的3个特征层,即上图中的13×13×255(Y1)、26×26×255(Y2)、52×52×255(Y3),这3个特征图恰好分别为原图像x的1/32、1/16、1/8.
到这,其实整个YOLOV3的框架基本上就讲完了。
综上所述,对于整个框架,我们抛开其他的细节不看,其实就是将一张大小为416×416×3的输入图像x,经过大量的卷积操作,变成了比它小得多的特征图。下面进行原理讲解:
