文章目录
1. 介绍
本文将对YOLOv1框架进行详细的解读,将针对我看论文的一些疑问进行解读,仅作为个人笔记。
因为还没有读代码,因此只针对论文进行理解性解读,有错误的地方欢迎指出。
论文地址:https://arxiv.org/pdf/1506.02640.pdf
项目地址:https://pjreddie.com/darknet/yolo/
GitHub:https://github.com/AlexeyAB/darknet
参考博文1:https://zhuanlan.zhihu.com/p/24916786?utm_source=qq&utm_medium=social
参考博文2:https://blog.csdn.net/x_iunknown/article/details/83064787
2. 检测框架
相比于Fast-RCNN, Faster-RCNN 等,yolo系列秉承着一个流程,一个end-to-end的思想,没有分成两步进行(提取proposal+识别),而是采用如下流程,简洁明了。
将图片分成网格状 -> 每个网格预测若干个矩形框 -> 判断矩形框里是否有物体
2.1 图片划分成网格
将一幅图片划分成 7x7的网格,S=7.

2.2 网络设计
网络如下,借鉴了Googlenet的思想, 但没有用inception,转用1 x 1 卷积,3 x 3 卷积, 1 x 1卷积,这样有个好处,降维,减少计算量,比直接用3 x 3计算量小很多。
网络具体细节不解释了,看不懂图的话,请面壁思过。
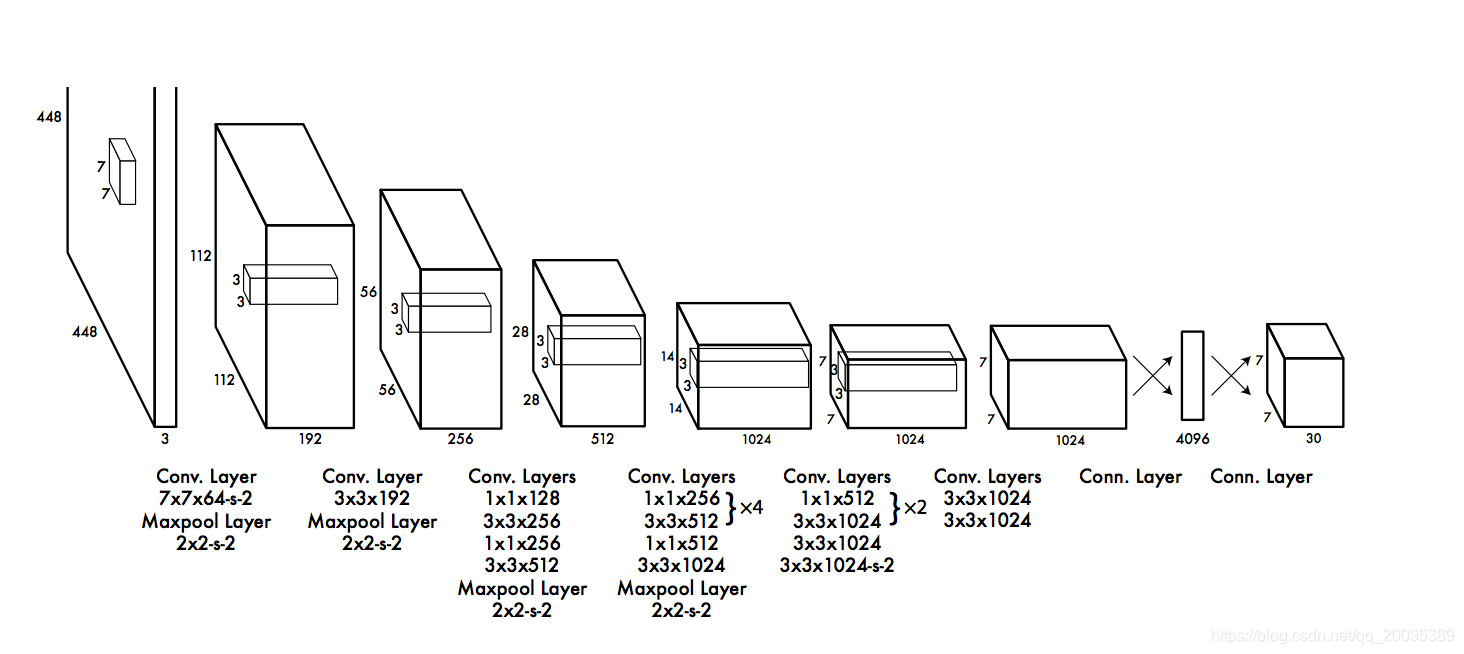
预训练网络:输入224 x 224, 数据集imagenet
后面训练的网络:输入变成448 x 448, 数据集pacal voc
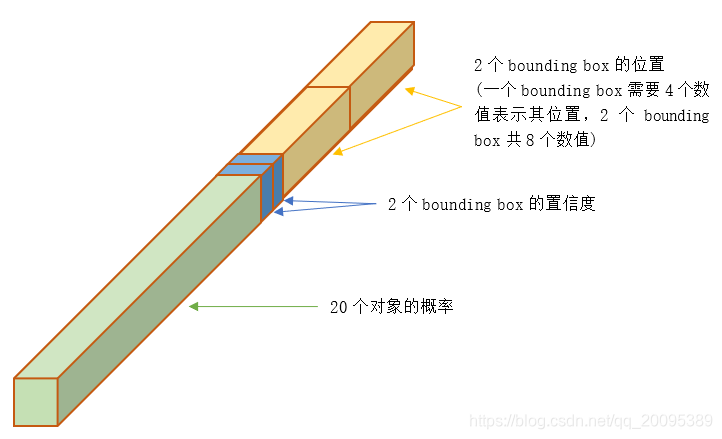
最后输出为 7x7x30:
【问题1】:为什么为30?
box1, box2, confidence1, confidence2 20个分类,其中box = (tx, ty, tw, th)。其实这边就体现出一个问题了,一个划分出的小格子里只能预测一个类,拿要是一个格子里有两个类呢?换句话说两个box都有效,但是yolov1只取一个类,因此可想而知,recall肯定不会太好,会漏掉很多物体。后面的yolo版本对这个问题会有改进。
2.3 训练
需要注意的几点
- 训练样本构造
- 448 x 448 输入(提高分辨率,增加小物体检出率)
- leaky 激活函数
- loss 函数设计
- 防止过拟合做的trick
2.3.1 训练样本构造
构造什么?就是最后那个30维向量。以如下图示为例

首先明确构造思想,中心点所在的网格对预测的对象负责。
蓝点对狗狗负责,黄点对自行车负责,红点对汽车负责。其他的点都不预测任何对象。
-
box 位置构造
box位置就是(tx,ty,tw,th),其中tx, ty被设计为相对于网格中心点的偏移,并归一化到0-1之间。tw,th被设计为相对于图像大小的比例,也被归一化到0-1之间。
【以狗狗为例】狗狗在(4,3)格子上,预测输出的中心点相对(4,3)格子的左上角的点偏移为tx=0.6, ty= 0.2。那么我们就可以推断出在实际的图中中心坐标点的位置。tw = 蓝色框的w/图像w, th = 蓝色框的h/图像h。 -
box 置信度构造
第一项为是否有对象的概率,例如对于上面的图,只有三个点概率为1,其他的概率为0,IOU是预测的和真实的框的重合率,标签的话也是只有0和1,因此只有蓝色,红色,黄色的格子置信度为1,其他为0。

【疑问】:bounding box 2是怎么弄的?随便?
如果对于小物体并且同种类别的话,可能两个都有效了,但是也有问题,如果是多个小物体呢?这也引出了YOLOv1的缺陷。
如果对于小物体并且同种类别的话,可能两个都有效了,但是也有问题,如果是多个小物体呢?这也引出了YOLOv1的缺陷。
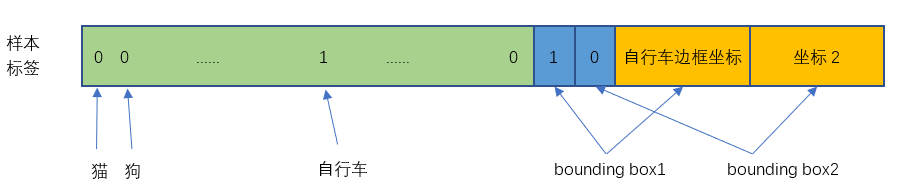
- 20个对象的分类概率
这个就非常简单了,是哪一类哪一类为1,否则为0
2.3.2 leaky 激活函数
YOLO的最后一层采用线性激活函数,其它层都是Leaky ReLU。更多细节请参考原论文。

2.3.3 loss 函数设计
公式中
意思是网格i中存在对象。
意思是网格i的第j个bounding box中存在对象。
意思是网格i的第j个bounding box中不存在对象。
l: 标签中的是否有对象
= 0.5,
= 5
调节不存在对象的bounding box的置信度的权重(相对其它误差)
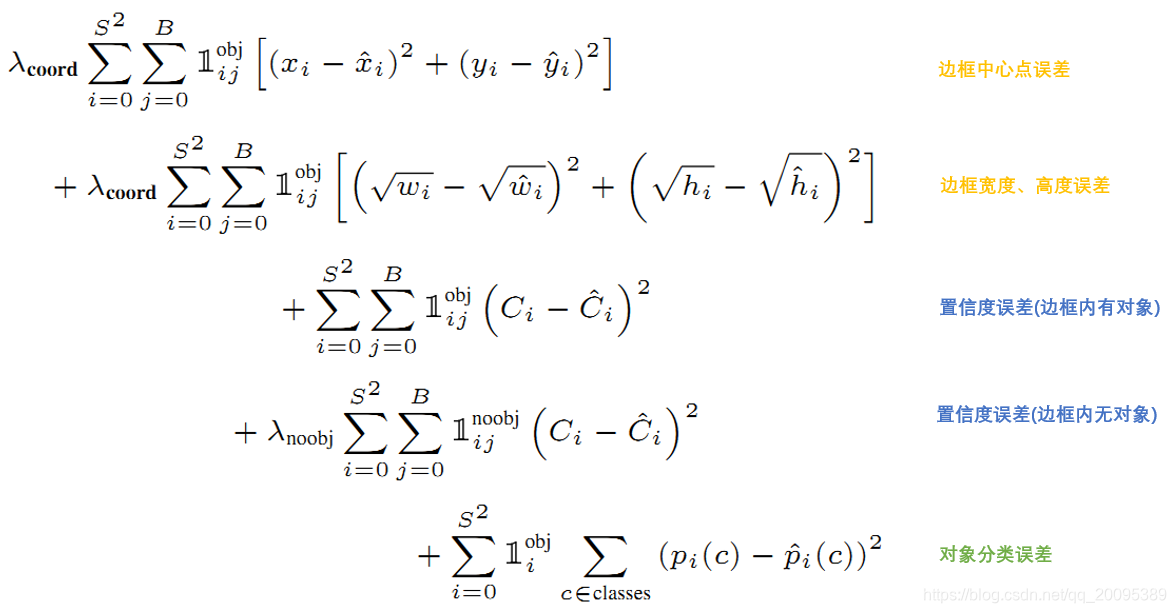
2.3.4 预防过拟合trick
- dropout layer : 第一个全连接层后面,0.5 drop
- 数据增强:20%数据集进行random scale and translation ,adjust the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.
2.4 预测
【NMS极大值抑制】
NMS步骤如下:
1)设置一个Score的阈值,低于该阈值的候选对象排除掉(将该Score设为0)
2)遍历每一个对象类别
2.1)遍历该对象的98个得分
2.1.1)找到Score最大的那个对象及其bounding box,添加到输出列表
2.1.2)对每个Score不为0的候选对象,计算其与上面2.1.1输出对象的bounding box的IOU
2.1.3)根据预先设置的IOU阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将Score设为0)
2.1.4)如果所有bounding box要么在输出列表中,要么Score=0,则该对象类别的NMS完成,返回步骤2处理下一种对象
3. yolov1局限性
- YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
- 由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。