YOLOv1
YOLOv1是单阶段目标检测方法,不需要像Faster RCNN这种两阶段目标检测方法一样,需要生成先验框。Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测。

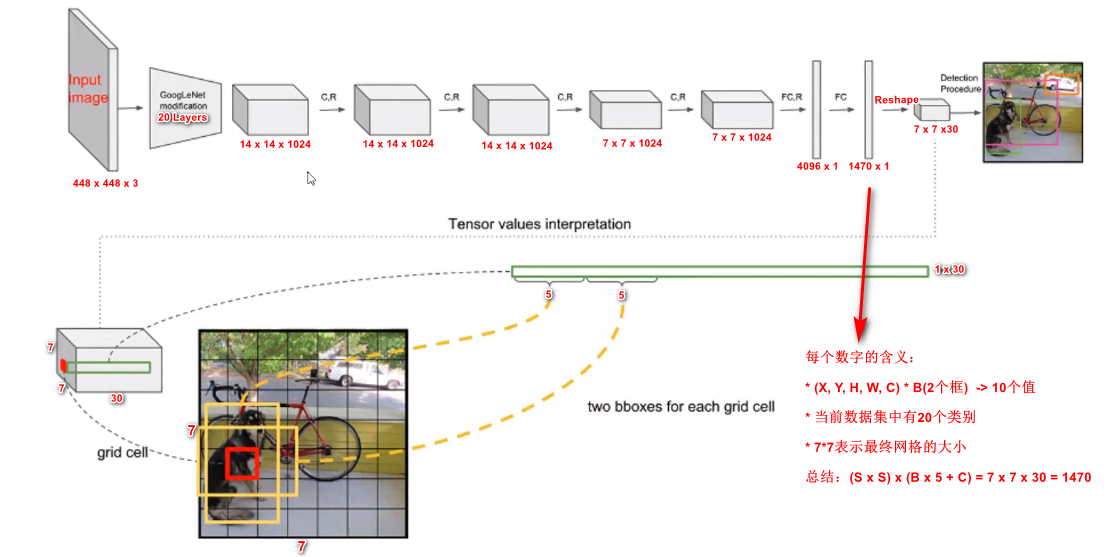
整个YOLO目标检测pipeline如上图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN系列算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。
具体来说,YOLO将全图划分为 S × S S×S S×S的格子, 每个格子负责对落入其中的目标进行检测,一次性预测所有格子所含目标的边界框、置信度、以及所有类别概率向量。
论文思想
- 将一幅图像分成SxS个网格,如果某个object的中心落在这个网格中,则这个网络就负责预测这个object
- 每个网格要预测B个bounding box,每个bounding box,除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测c个类别的分数
网格单元(Grid Cell)
YOLO将目标检测问题作为回归问题。会将输入图像分成 S × S S \times S S×S的网格(cell),如果一个物体的中心点落入到一个cell中,那么该cell就要负责预测该物体,一个格子只能预测一个物体,会生成两个预测框。
对于每个网格单元cell:
- YOLOv1会预测两个边界框
- 每个边界框包含5个元素: ( x , y , w , h ) (x,y,w,h) (x,y,w,h) 和 边界框的置信度得分(box confidence score)
- 只负责预测一个目标
- 预测 C C C 个条件概率类别(conditional class probabilities)

为了评估PASCAL VOC,YOLO V1使用 7×7 的网格(S×S),每个单元格回归2个边界框 和 20个条件类别概率。条件类别概率 (conditional class probability) 是检测到的目标属于特定类别的概率(每个单元对每个类别有一个概率)。
最终的预测特征由边框的位置、边框的置信度得分以及类别概率组成,这三者的含义如下:
- 边框位置:对每一个边框需要预测其中心坐标及宽、高这4个量, 两个边框共计8个预测值
- 边界框宽度w和高度h用图像宽度和高度归一化。因此 x , y , w , h x, y, w, h x,y,w,h 都在0和1之间。 x x x 和 y y y 是相应单元格的偏移量。
- 置信度得分(box confidence score) c :框包含一个目标的可能性(objectness)以及边界框的准确程度。类似于Faster RCNN 中是前景还是背景。由于有两个边框,因此会存在两个置信度预测值。
- 类别概率:由于PASCAL VOC数据集一共有20个物体类别,因此这里预测的是边框属于哪一个类别。
一个cell预测的两个边界框共用一个类别预测, 在训练时会选取与标签IoU更大的一个边框负责回归该真实物体框,在测试时会选取置信度更高的一个边框,另一个会被舍弃,因此整张图最多检测出49个物体。
网络结构

YOLO输入图像的尺寸为 448 × 448 448 \times 448 448×448,经过24个卷积层,2个全连接的层(FC),最后在reshape操作,输出的特征图大小为 7 × 7 × 30 7 \times 7 \times 30 7×7×30。
- YOLO主要是建立一个CNN网络生成预测 7 × 7 × 1024 7 \times 7 \times 1024 7×7×1024 的张量,
- 然后使用两个全连接层执行线性回归,以进行 7 × 7 × 2 7 \times 7 \times 2 7×7×2 边界框预测。将具有高置信度得分(大于0.25)的结果作为最终预测。
- 在 3 × 3 3 \times 3 3×3的卷积后通常会接一个通道数更低 1 × 1 1 \times 1 1×1的卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。
- 除了最后一层使用了线性激活函数外,其余层的激活函数为 Leaky ReLU ;
- 在训练中使用了 Dropout 与数据增强的方法来防止过拟合。
- 对于最后一个卷积层,它输出一个形状为 (7, 7, 1024) 的张量。 然后张量展开。使用2个全连接的层作为一种线性回归的形式,它输出 个参数,然后重新塑形为 (7, 7, 30) 。
损失函数
YOLO V1每个网格单元能够预测多个边界框。为了计算true positive的损失,只希望其中一个框负责该目标,为此选择与GT具有最高IOU的那个框
- YOLO正样本选择
- 当一个真实物体的中心点落在了某个cell内时,该cell就负责检测该物体。
- 具体做法是将与该真实物体有最大IoU的边框设为正样本, 这个区域的类别真值为该真实物体的类别,该边框的置信度真值为1。
- YOLO负样本选择
- 除了上述被赋予正样本的边框,其余边框都为负样本。负样本没有类别损失与边框位置损失,只有置信度损失,其真值为0。
YOLO使用预测值和GT之间的误差平方的求和(MSE)来计算损失。 损失函数包括
- localization loss -> 坐标损失(预测边界框与GT之间的误差)
- classification loss -> 分类损失
- confidence loss -> 置信度损失(框里有无目标, objectness of the box)

坐标损失
坐标损失也分为两部分,坐标中心误差和位置宽高的误差,其中 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj 表示第i个网格中的第j个预测框是否负责obj这个物体的预测,只有当某个预测框对某个物体负责的时候,才会对box的coordinate error进行惩罚,而对哪个物体负责就看其预测值和GT box的IoU是不是在那个网格的所有box中最大。
我们可以看到,对于中心点的损失直接用了均方误差,但是对于宽高为什么用了平方根呢?这里是这样的,我们先来看下图:

上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
如果W和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,这更加符合我们的实际判断。所以,算法对位置损失中的宽高损失加上了平方根。
而公式中的 λ c o o r d \lambda_{coord} λcoord 为位置损失的权重系数,在pascal VOC训练中取5。
置信度损失
置信度也分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。
其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0.第二项代表预测框bounding box和真实标记的box之间的IoU。值越大则box越接近真实位置。
confidence是针对预测框bounding box的,由于每个网格有两个bounding box,所以每个网格会有两个confidence与之相对应。
从损失函数上看,当网格i中的第j个预测框包含物体的时候,用上面的置信度损失,而不包含物体的时候,用下面的损失函数。对没有物体的预测框的置信度损失,赋予小的loss weight, 记为在pascal VOC训练中 λ n o o b j \lambda_{noobj} λnoobj取0.5。有有物体的预测框的置信度损失和类别的loss的loss weight正常取1。
类别损失
类别损失这里也用了均方误差。其中 1 i o b j \mathbb{1}^{obj}_{i} 1iobj 表示有无物体的中心点落到网格i中,如果网格中包含有物体object的中心的话,那么就负责预测该object的概率。
YOLOv1的缺点
由于YOLOV1的框架设计,该网络存在以下缺点:
- 每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。
- 原始图片只划分为7x7的网格,当两个物体靠的很近时,效果比较差。
- 最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
- 对于图片中比较小的物体,效果比较差。这其实是所有目标检测算法的通病。