前言
PointNet++是一个用于对不规则形状的点云数据进行分类和分割任务的深度神经网络。相对于传统的基于网格的3D数据表示方法,点云数据更易于获取和处理。PointNet++的另一个优势是它引入了多尺度层次结构,可以处理更为复杂的点云数据。相比于第一版的PointNet网络作者提出了许多新的想法,也取得了很不错的效果。
PointNet算法存在的问题
(1)一幅点云图像点数量太多,这会造成计算量过大从降低算法速度,如何解决?
(2)如何将点云划分为不同的区域,并且获取不同区域的局部特征?
(3)点云不均匀的时候应该如何解决这个问题?
带着这些问题我们接下来开始通过论文与源码来解决这些问题。
分类任务
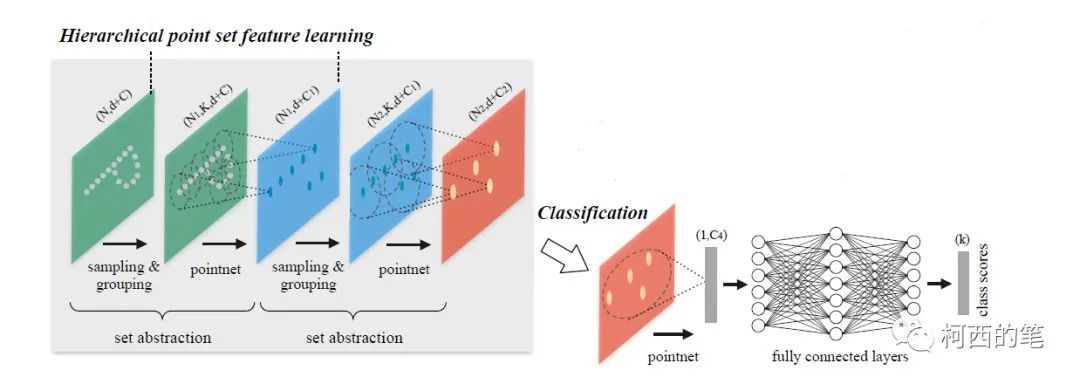
分层抽取特征 set abstraction
该模块主要由3个部分组成:
1.采样层(sample layer):在稠密的点云中抽取出一些相对重要的点作为中心点,即FPS(farthest point sampling)最远点采样法,也为了解决本文中的第一个问题。
2.分组层(group layer):找距离中心点附近最近的K个点,组成local points region。这操作有点像图像卷积,形成卷积图像,方便提取特征。解决第二个问题。
3.特征提取层(pointnet layer):特征提取层。对每个local points region提取特征。
FPS流程如下:
(1)随机选择一个点作为初始择采样点;
(2)计算未选择采样点集中每个点与已选择采样点集之间的距离distance,将距离最大的那个点加入已选择采样点集,
(3)根据新的采样点计算distance,一直循环迭代下去,直至获得了目标数量的采样点。
如下图在所有的点当中选出了5个点。

代码实现如下
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device) #[b,npoint] #npoint是要从很多的点中筛选出那么多
distance = torch.ones(B, N).to(device) * 1e10 #[b,N] #N指原来有N个点
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device) #[b] 在0-N中随机生成了B个点(随机选了个点作为初始点,并且用的索引
batch_indices = torch.arange(B, dtype=torch.long).to(device) #[b] 0-b
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3) #获得索引对应的位置的坐标
dist = torch.sum((xyz - centroid) ** 2, -1) #计算所有坐标和目前这个点的距离
mask = dist < distance #距离符合要求的
distance[mask] = dist[mask] #将符合要求的距离都放入
farthest = torch.max(distance, -1)[1] #最远距离对应的索引 [b]
return centroids #最终输出筛选的[n,npoint]个点的位置分组层流程如下:
(1)根据FPS筛选后获得相应的中心点
(2)将每一个中心点在原点集中根据距离筛选出附近需要的点数,以每个FPS点为中心形成一个个新的点集
(3)新的点集会做一个类似坐标归一化的操作形成3个新特征然后与原先每个点自带的特征结合形成特征提取前的新特征。
简图如下所示:
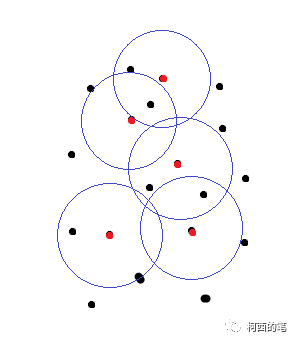
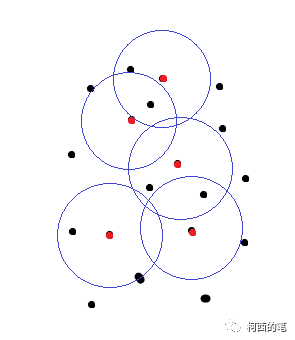
图一
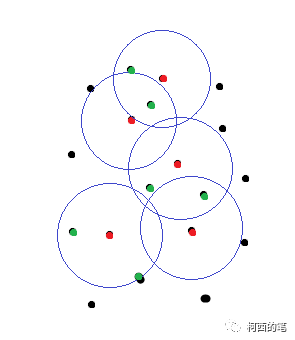
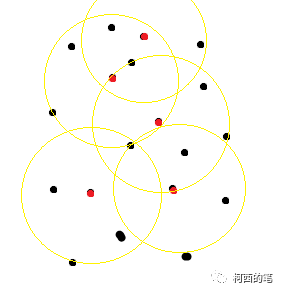
图二
图一中红点为FPS结果的中心点,黑点为初始的一些点。图二绿点是根据距离筛选后的点,这些点与红点将会组成一系列的点集。
在分组层中作者提出了3种方案:SSG(single scale grouping)、MSG(multi-scale grouping)多尺度、MRG(multi-resolution grouping)多分辨率。实际上就是采用不同的半径或不同的分辨率进行了多次采样分组。也是为了解决本文中的第三个问题。
SSG:就相当于只有一种半径做了分组采样
MSG:相当于在同分辨率下做了多个半径分组采样,然后再将点集结合起来。
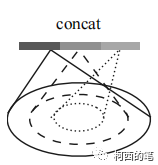
MRG
代码实现如下
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
"""
1.预设搜索区域的半径R与子区域的点数K
2.上面提取出来了 s 个点,作为 s个centriods。以这 s个点为球心,画半径为R的球体(叫做query ball,也就是搜索区域)。
3.在每个以centriods的球心的球体内搜索离centriods最近的的点(按照距离从小到大排序,找到K个点)。
如果query ball的点数量大于规模nsample,那么直接取前nsample个作为子区域;如果小于,那么直接对某个点重采样(此处直接复制了第一个点),凑够规模nsample
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1]) #[2,512,1024]
sqrdists = square_distance(new_xyz, xyz) #获得采样后点集与原先点集的距离[2,512,1024]
group_idx[sqrdists > radius ** 2] = N #将距离比半径大的,将此处置为1024
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample] #因为是0-1023的索引,不符合要求的变味了1024,再对索引排序,获得前nsample个 [b,s,nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample]) #拿了符合要求的第一个索引点索引,也就是中心点,并且复制了nsample次 [b,s,nsample]
mask = group_idx == N #查看那前nsample中有没有不符合要求的
group_idx[mask] = group_first[mask] #其中将不符合要求的点,全部换成符合要求的第一个点
return group_idx
def sample_and_group(npoint, radius, nsample, xyz, points, returnfps=False):
"""
Input:
npoint:
radius:
nsample:
xyz: input points position data, [B, N, 3]
points: input points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, npoint, nsample, 3]
new_points: sampled points data, [B, npoint, nsample, 3+D]
"""
B, N, C = xyz.shape
S = npoint
fps_idx = farthest_point_sample(xyz, npoint) # [B, npoint] #FPS最远点采样算法 获得需要点的索引
new_xyz = index_points(xyz, fps_idx) # [B, npoint,c] #将对应索引的点拿出来
idx = query_ball_point(radius, nsample, xyz, new_xyz) #[b,npoint,nsample] #进行query_ball处理,类似于卷积操作,找到new_xyz附近原xyz的nsample个点,返回对应的索引[b,npoint,nsample]
grouped_xyz = index_points(xyz, idx) # [B, npoint, nsample, C] #将对应索引的点拿出来
grouped_xyz_norm = grouped_xyz - new_xyz.view(B, S, 1, C) #每个点减去自己半径内中心的那个点进行归一化[B, npoint, nsample, C]
if points is not None: #points即原来点就存才的一些特征
grouped_points = index_points(points, idx) #将每个区域原先的特征拿出来 [b,npoint,nsample,D]
new_points = torch.cat([grouped_xyz_norm, grouped_points], dim=-1) # [B, npoint, nsample, C+D] #将归一化数据和原先的特征结合
else:
new_points = grouped_xyz_norm #如果原先没有特征的,那么数据就是归一化后的点
if returnfps:
return new_xyz, new_points, grouped_xyz, fps_idx
else:
return new_xyz, new_points特征提取层
该层就是一些基本卷积池化操作。最后FPS选中的那些点特征就会变多。

如此重复几次set abstraction层,在最后接一些全连接网络对点云进行分类。
分割任务
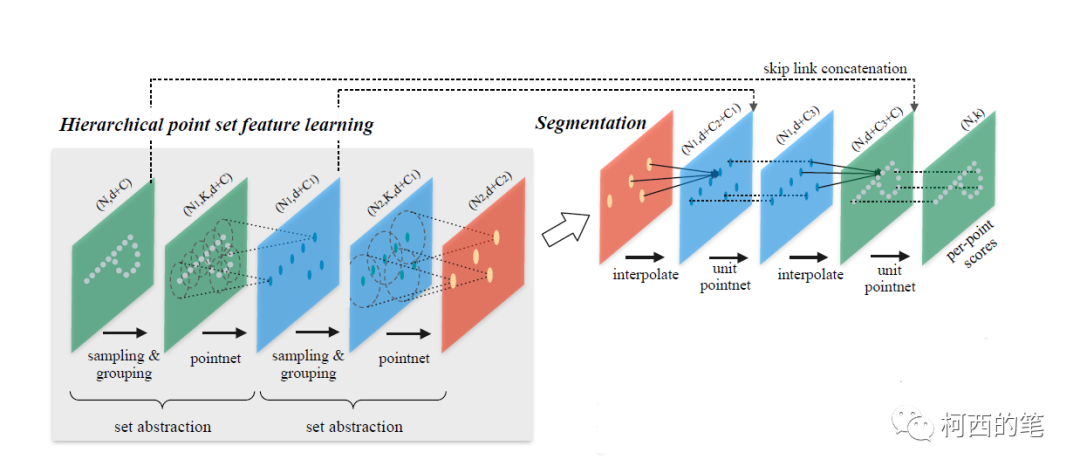
分割任务的特征提取器与分类任务是一样的,接下来就主要讲下上采样的环节。作者提出了一种基于距离插值的分层特征传播(Feature Propagation)策略。
大体流程如下:
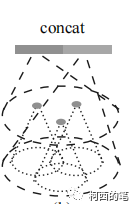
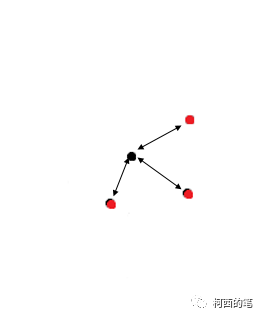
(1)计算反向距离加权平均的权重,如下图所示:红点即FPS特征提取后的点,实际上红点的特征数量也会比黑点要多。而上采样就是让这些黑点也产生符合的特征。
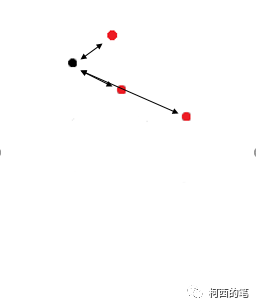
权重计算:每个黑点寻找出附近最近的3个红点,然后在每个红点根据距离权重为黑点分配特征。那么每个黑点都会产生新的特征。红点也是要进行如此的操作。即上图的所有点都会产生新特征。


(2)产生的新特征与上一层的特征进行cat操作,再通过卷积等完成特征融合。一步上采样结束。
代码实现如下
class PointNetFeaturePropagation(nn.Module): #上采样
def __init__(self, in_channel, mlp):
super(PointNetFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N] 上一层的
xyz2: sampled input points position data, [B, C, S] 现在层的
points1: input points data, [B, D1, N] 上一层的
points2: input points data, [B, D2, S] 现在层的
Return:
new_points: upsampled points data, [B, D', N]
"""
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1)
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = square_distance(xyz1, xyz2) #计算两点集各点之间距离[b,N,S]
dists, idx = dists.sort(dim=-1) #排序
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3] 获得距离最近的3点
dist_recip = 1.0 / (dists + 1e-8)
norm = torch.sum(dist_recip, dim=2, keepdim=True)
weight = dist_recip / norm #根据距离设置权重
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2) #[B,N,D2]
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1) #上采样cat [B,N,D1+D2]
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1) #[B,D1+D2,N]
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
return new_points #[B, D', N]至此,有关PointNet++的文章解析就完毕了!如有错误解读的地方,欢迎批评指正,我们共同进步!