3D目标检测(一)—— PointNet,PointNet++,PointNeXt, PointMLP
目录
3D目标检测(一)—— PointNet,PointNet++,PointNeXt, PointMLP

前言
在3D目标检测中,可以大致分为基于图像、基于点云和基于多模态融合的三种方法。而基于点云处理的3D目标检测中,如何有效处理点云数据信息是其中的重点。常见的处理点云的方法有两种,一种为将无序的点云处理成有规则的体素或者柱体(voxel or pillar)等来进行处理,被称为Voxel-Based,另一种则是直接在原始点云上进行操作的Point-Based方法。
本文主要介绍如何Point-Based中的经典网络PointNet,PointNet++和其发展PointNeXt、PointMLP。
零、网络使用算法
有许多对于点云预处理的算法,如FPS,ball-query等,在这里介绍一下,方便大家对于后续网络结构的了解和认识。
FPS最远点采样法
对于点云来说,每次采集的信息少则是上万个点,多则则是几十万个点,如果把这些点都塞到网络结构中进行处理,毫无疑问对于显存等的消耗都是十分巨大的,故如何对这些点进行采样降低点云的数量的同时,最大程度保留其中蕴含的特征是研究之一。
而FPS最远点采样,则是其中比较常用的方法之一,其核心思想则是使采样后的点集中的点互相相距最远,从欧式空间来看,这种方法最大限度的使点在空间中较为分散的分布,概率上能最大保留空间中点的特征。这里引用知乎文章FPS理解,来介绍其主要步骤。
- 随机选取点P0为起始点,获得初始集合S={P0},并定义初始距离矩阵D,其中D[i]记录集合中每个点Pi到集合S中点的最远距离。
- 计算点云中的点到P0的距离,更新距离矩阵D[i],选择D[i]最大值对应的点P1加入集合,S={P0,P1}
- 循环第二个步骤,直至S中集合的点数达到设定值
代码如下
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1]
return centroids
其具体效果大致如下
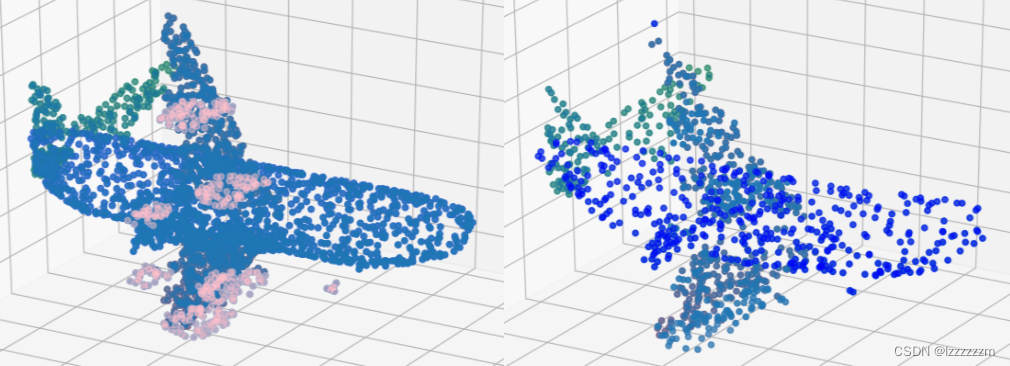
而FPS算法不仅可以使用欧式空间来进行采样,同样也可以嵌入网络中,在特征空间利用特征向量来计算出特征距离矩阵,利用此来进行FPS。
Ball-query球查询
点云数据除了无序性的特征外,还存在着邻域相关性的特征,即点与点之间不是孤立的关系,相邻的点云构成的具有特征的点云集,故如何有效概括区域点云,则是ball-query要干的事。
ball-query的思想十分简单,即设定球心,将球心半径内的和球心最近的点聚类起来作为一个领域。而在PointNet系列中,其球心的一般是由FPS算法采样后的点确立的,故这两个算法经常同时使用,统称为QueryAndGroup
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3],一般为FPS采样确定的点
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
sqrdists = square_distance(new_xyz, xyz)
group_idx[sqrdists > radius ** 2] = N
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
mask = group_idx == N
group_idx[mask] = group_first[mask]
return group_idx一、PointNet

PointNet是直接处理点云的开山之作,我们假设如果没有现在这么多处理点云的方法,在我们拿到点云数据时,应该如何考虑通过神经网络进行处理。
通过分析,我们可以得出点云数据有着如下几大特点。
- 无序性:点云中的点不像图像中的像素一样,具有严格的顺序,即如果通过一个数据存储点云,随机的打乱数组的顺序,并不会有任何影响。
- 点与点之间存在联系:虽然点之间没有顺序的概念,但空间中相邻的点构成的领域具有联系性,能够表征整体的特征,每个点不是孤立的。
- 变换不变性:这点和图像是类似的,即不管如何旋转和翻转部分的点,其代表的整体还是同样的。
根据上述特点,当拿到一个(B,N,C)维度的点云数据时,应该利用什么神经网络的什么结构能处理呢。其实最直观,最简单的方法则是利用汇聚层来进行处理,不管是max pooling还是avg pooling,在图像领域里的作用都是将处理好的特征汇聚起来,集合成更有全局性的特点,且根据max pooling和avg pooling的数学表达max()和mean()操作,均满足点云中的无序性特征要求。
但对于一个sample的点云(N,3)来,其初始只有XYZ三个坐标维度的特征,直接进行汇聚操作,得到的特征都是十分浅层的特征,没法利用来做什么后续的操作。那根据图像领域利用卷积来获得高维特征,最后进行汇聚的思路,点云框架也可以这么设计,而由于点云是二维的特征,没法利用卷积,则使用全连接层(也可以认为是一维卷积)的方法,来对点云进行升维,在PointNet中,则将初始点云由(N,3)经过MLP一步步从3维升维至64维,最后为1024维度,在升维后,通过max pooling操作将(N,1024)的特征,汇聚成1024的特征向量,完成对点云的特征处理。
而在点云送入神经网络前,由于每个物体采集到点云的数量不一样,为了方便处理,会利用FPS算法或者就随机采样将点云采样到相同的数量来进行处理。
至于PointNet中还有input transform模块和feature transform模块,则是考虑到变换不变性来设计的,但在后续的论文中,被认为其对整体的效果并不大,这里就不讲述了。
所以PointNet作为开山之作,其提供的最重要的思想就是,对于无序的点云,可以沿用图像领域的经验,对点云先升维,然后利用max pooling或者avg pooling等汇聚操作来处理特征。
二、PointNet++
根据上述对PointNet的讲解,可以知道PointNet只是提出了一种直接处理点云的整体的框架,但其在处理时,并没有考虑到点云的第二个特征,即点与点之间的局部特征特点,故PointNet++则是基于此在PointNet的基础上对局部区域进行改进的框架。
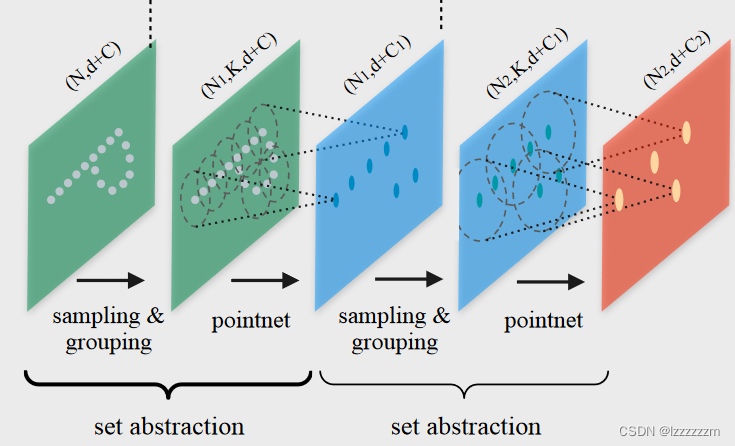
PointNet++的设计思路也很直观,既然PointNet是缺少局部特征处理的,而在图像领域中卷积的作用就是把一个个局部的特征提取出来生成高维的特征,可在点云里无法利用卷积核这种方便的操作,于是作者就引入了sampling&grouping的操作,被称为set abstraction(SA)层来模拟这种卷积的操作。
像图示如此,作者对原始的N个点进行FPS采样得到N1个点,并将采样后的N1个点作为中心点,使用ball-query算法来形成K个领域,而后将每个领域都单独的经过PointNet层,即上述PointNet框架中的mlp升维+汇聚操作,这样采样后的N1个点就可以认为汇聚了其对应区域中点的特征。经过上述操作,原本N个带有d+C特征的点,被采样升维为N1个带有d+C1个特征点,其中d一般为原始坐标特征xyz。至此,SA层的设计思路一直被沿用,可以认为就是当初图像领域中conv+bn+relu层的点云版本。
可以用上述的数学表达式来表示PointNet++的网络结构,其中表示特征聚合操作(在PointNet++为max_pooling),
表示局部的特征提取器(在PointNet++为MLP),
则表示第
个采样点的第
个领域的特征。
PointNet++可以说奠定了点云处理的框架都依此数学表达式来构建,后面的更多工作都在上做许多文章,如引入attention机制或者用CNN,GNN等方法。
MSG-PointNet++
作者另外还考虑到了点云在收集时,不同的区域中点云的稀疏性可能会差别很大,有可能某个角落的点云数量只有少数几个,那么这种情况就会导致grouping后的点云区域中只有少量的点云,而少量的点云无法有效的概括局部特征。解决这个问题,最简单的想法就是加大ball-query中球的半径,那么可以保证每个领域点的数量都不会太少,但领域的半径过大,就会导致网络对于精细局部的建模不够。综合上述因素,作者提出multi-scale grouping(MSG)的思路,即在每层grouping的时候,不仅使用一个半径来进行grouping,而使用多个半径来进行grouping,把这几个半径grouping的结果邻域送入PointNet后最后拼接起来形成最后的新特征。
PointNet++的核心思想就是考虑在PointNet的基础上,利用邻域的概念,对局部特征进行了有效的建模,提出的SA层,也成为现在直接处理点云框架中最常用的backbone module。
三、PointNeXt
个人认为PointNeXt本身是一篇偏向于工程性的文章,但其提出了如何做大PointNet系列的一个思路。最直观的做大PointNet获得高性能的方法,就是加多几个SA层,并把维度升的更高,以获得更大感受野和更深层的特征,但PointNeXt通过实验证明,单纯的这么做,对网络没有太大的提升,反而会影响网络的性能,作者给出的解释在于过深的网络结构会导致梯度消失和过拟合现象的产生,于是作者仿照Resnet的成功,也在PointNet++的基础上,在网络中引入了残差结构,来构造更深更大的网络。
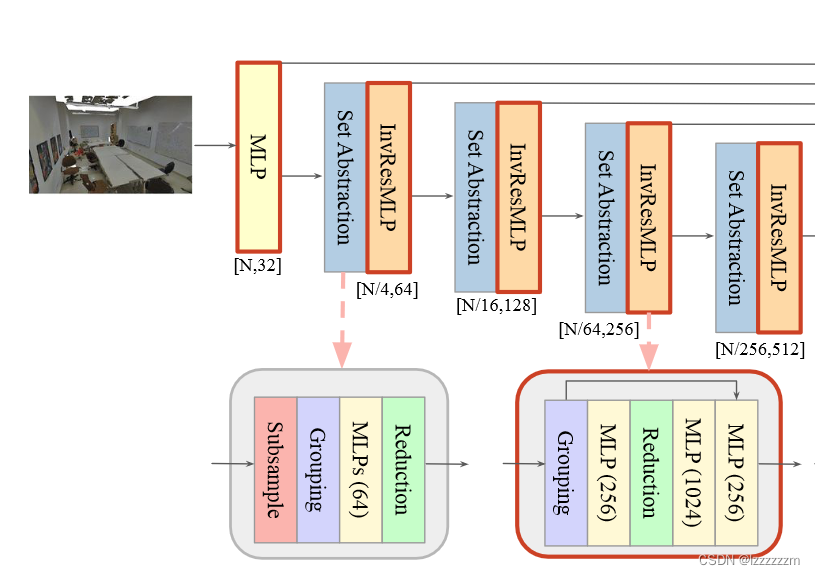
网络的处理module,在原来SA层的基础上,加入了InvResMLP残差结构,InvResMLP模块中,把原先的SA层中的3层MLP,划分为作用在grouping后的MLP,来提取邻域特征,和后两层MLP来提取点特征以此增强网络的性能。在PointNeXt中用这种SA+InvResMLP的结构来当成基础处理模块。
PointNeXt其他贡献在于其做了大量的实验,去说明调参的重要性(doge),这里就不介绍了。而PointNeXt的主要思想则是通过残差结构的设计来做大模型,以此提升模型的整体性能,也给网络的设计提供了一种方向。
四、PointMLP
PointMLP和PointNeXt的整体方向都是希望通过残差结构的MLP来提升原有PointNet架构的性能,并且也同时考虑了grouping前的局部区域特征,可以认为是同一方向但两种设计思路的方法。
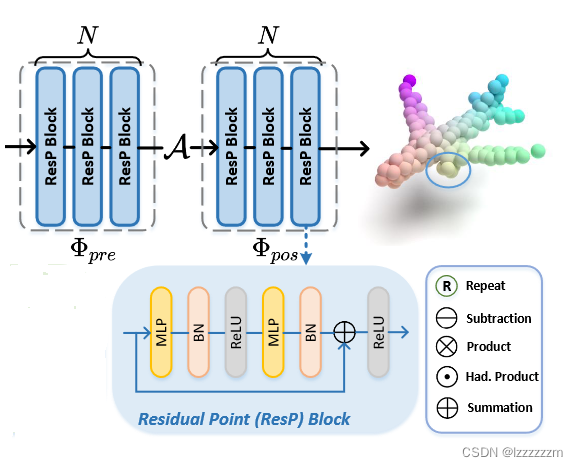
PointMLP用数学表达的话,可以以下面的公式来呈现
可以看到其相对PointNet++而言,其多了来学习聚合后的深层信息,其实PointNeXt中的InvResMLP可以认为是
的一种,所以PointNext和PointMLP其实在数学表达上是一样的。而其中的差别在于其中MLP层的设计,PointMLP中在MLP层之间还加入了BN RELU的设计(感觉上没什么创新,本质上都是MLP层+pooling层的组合罢了)
另外文章还指出了如果单纯堆叠这样的处理结构,网络效果并不会变好,反而变差,作者分析是由于区域的局部稀疏和不规则导致的(我个人感觉是网络设计问题,因为PointNeXt并没有考虑这个问题,但也work),与是设计了一个类似归一化的映射模块,在点云输入到网络前就需要经过此模块进行处理,来解决区域稀疏性的问题。

其中表示
区域内的第j个点,其需要通过上述公式进行区域归一化映射,k表示第
附近拥有k个领域点,d表示点代表的维度信息,n则是总的点数。这个模块的功能,作者并没有进行过多的消融实验,如加入这个模块后,其他网络的性能是否有提升等,所以其泛用性还有待验证。
总结
本文介绍了3D目标检测中Point-Based方法中的Backbone处理方法,介绍常用backbone PointNet,PointNet++及其发展PointNeXt和PointMLP。这些种类的方法其实都是基于MLP和pooling层的结构,除此之外,也有许多方法如PointCNN尝试使用CNN来处理点云,和DGCNN尝试使用图网络来处理点云等。