PointNet的缺点:
- PointNet不捕获由度量空间点引起的局部结构,限制了它识别细粒度图案和泛化到复杂场景的能力。
利用度量空间距离,我们的网络能够通过增加上下文尺度来学习局部特征。
- 点集通常采用不同的密度进行采样,这导致在统一密度下训练的网络的性能大大降低。
新的集合学习层来自适应地结合多个尺度的特征。
一,介绍:
PointNet++:分层方式处理在度量空间中采样的一组点 。
- 通过基础空间的距离度量将这组点分割成重叠的局部区域。
- 提取局部特征来捕获来自小邻域的精细几何结构; 这些局部特征被进一步分组为更大的单元并被处理以产生更高级的特征。
- 重复这个过程直到我们获得整个点集的特征。
需要解决的问题:
- 如何生成点集的划分
- 如何通过局部特征学习抽象点集或局部特征。
这两个问题是相关的:
点集的分割必须产生跨分区的共同结构,以便像卷积设置那样共享局部特征学习者的权重。
PointNet++在嵌套的分割输入集上递归的运用pointNet
每个分区:相邻的球。每个分区包含质心位置和规模。质心通过最远采样点算法获得(FPS)
感受野依赖输入数据和度量。
二.问题描述:
X = (M; d) 是离散的度量空间,m是点,d是距离度量。m的密度不均匀,
三.方法:
可以看作增加了层次结构的pointNet,
- 复习pointnet:缺乏不同规模上捕捉局部上下文的能力。(采用分层特征学习框架)
- 分层架构:
New architecture builds a hierarchical grouping of points and progressively abstract larger and larger local regions along the hierarchy.
At each level, aset of points is processed and abstracted to produce a new set with fewer elements.
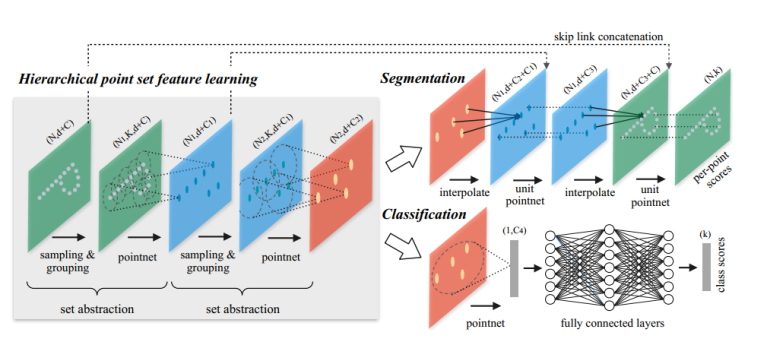
抽象层的三个关键层:
Sampling layer : selects a set of points from input points (确定局部区域的图心)
Grouping layer : 分组层通过查找质心周围的“邻近”点来构建局部区域集。
PointNet layer :使用小型PointNet将局部区域模式编码为特征向量

输入:N * (d + c) 矩阵,d纬度坐标,c点特征纬度。
输出:. It outputs an N0 × (d + C0) matrix of N0 subsampled points with d-dim coordinates and new C0-dim feature vectors summarizing local context
采样层:迭代最远点采样(FPS)来选择点x1,x2...的子集 ,(距离其余的子集在欧几里得空间上距离最远)
分组层:
输入:大小为N(d + C)的点集和大小为NId的一组质心的坐标
输出:groups of point sets of size N0 × K × (d + C),where each group corresponds to a local region and K is the number of points in the neighborhood of centroid points
使用方法:bell查询(和cnn相比)
pointNet层:
输入:N0 local regions of points with data size N0×K×(d+C)
输出:输出中的每个局部区域都由其质心和局部特征抽象出来,这些特征对质心的邻域进行编码。 Output data size is N0 × (d + C0)
将局部的点坐标进行转化,通过使用相对坐标和点要素,我们可以捕捉到局部区域内的点对点关系 。
3.3 对不均匀采样的鲁棒特征学习:
we should look for larger scale patterns in greater vicinity.
density adaptive PointNet layers
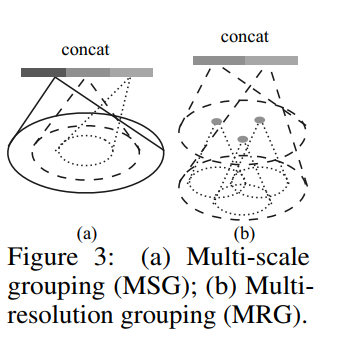
Multi-scale grouping (MSG).
- apply grouping layers with different scales
- according PointNets to extract features of each scale
- Features at different scales are concatenated to form a multi-scale
feature.
(各种稀疏性的训练集)
Multi-resolution grouping (MRG). (这种更好)
MSG的计算成本太高。新方法:still preserves the ability to adaptively aggregate information according to the distributional properties of points。
当局部区域的密度较低时,第一个矢量可能不如第二个矢量可靠,因为在计算第一个矢量中的子区域包含更稀疏的点并且更多地受到抽样不足的影响。 在这种情况下,第二个向量应该加权得更高。
当局部区域的密度很高时,第一个矢量提供更精细的细节信息,因为它具有以较低分辨率递归地检查较高分辨率的能力。
3.4 Point Feature Propagation for Set Segmentation
在集合抽象层中,对原始点集进行二次抽样。 然而,在集合分割任务中,比如语义点标注,
我们希望获得所有原始点的点特征。
方法1:
always sample all points as centroids in all set abstraction levels (高成本)
方法2:
propagate features from subsampled points to the original points
hierarchical propagation strategy with distance based interpolation and across level skip links
In a feature propagation level, we propagate point features from
Nl × (d + C) points to Nl-1 points where Nl-1 and Nl (with Nl ≤ Nl-1) are point set size of input and output of set abstraction level l.
我们通过在Nl1点的坐标处插入Nl个点的特征值f来实现特征传播。在插值的众多选择中,我们使用基于k近邻的反向距离加权平均值。

The interpolated features on Nl-1 points are then concatenated with skip linked point features from the set abstraction level.
结果:
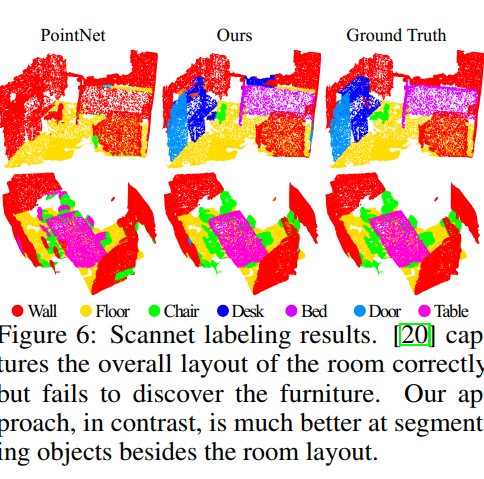
本质:是PointNet的分层版本
PointNet的不足:
1)无法很好地捕捉由度量空间引起的局部结构问题,由此限制了网络对精细场景的识别以及对复杂场景的泛化能力。
2)欠缺了对局部特征的提取及处理,比如说点云空间中临近点一般都具有相近的特征,同属于一个物体空间中的点的概率也很大,就好比二维图像中,同一个物体的像素值都相近一样。
3)点云数据的一个特征是数据密度不同,体现出近多远少等问题,而在密度不同的情况下,使用统一的模板处理这些数据显然是不对的,基于此,PointNet++的作者提出了密度适应的网络结构。
PointNet++解决的问题:
1.如何对点云进行局部划分
对数据集进行划分,提取局部特征,然后不断抽象,提取更高维的特征,是PointNet++的基本思路,那么首先的问题是如何定义局部,PointNet++给出的解决思路是使用点球模型,从全部数据集中选出若干质心点,然后选取半径,完成覆盖整个数据集的任务。在质心点的选取上,采用的是FPS算法,即随机选取一个点,然后选择离这个点最远的点加入到结果集中,迭代这个过程,直到结果集中点的数量达到某个给定值,在PointNet++中,很常见的一个词是metric,即度量,PointNet++中的很多东西都是依赖度量的,而在PointNet中,其实对于度量并不是很强调,或者细究的话都有可能不需要是度量空间(这个度量指的是什么呢?)。在读到中心点的集合后,第二个问题是如何选择半径,其实半径的选取是个很麻烦的事,在点云数据集中,有些地方比较稠密,有些地方比较稀疏,稠密的地方必然半径要小,而稀疏的地方必然半径要大,不然可能都提取不出什么特征,此时引出第二个问题——密度适应,若半径确定,即局部大小确定,此时训练的模板大小也就确定了。
2.如何对点云进行局部特征提取
每个图层都有三个子阶段:采样,分组和PointNeting。在第一阶段,选择质心,在第二阶段,把他们周围的邻近点(在给定的半径内)创建多个子点云。然后他们将它们给到一个PointNet网络,并获得这些子点云的更高维表示。然后,他们重复这个过程。
(这两个问题是关联的)
3.如何进行密度适应?
论文中提到的处理密度适应的方法有两种
方法1为MSG,即把每种半径下的局部特征都提取出来,然后组合到一起.
作者在如何组合的问题上提到了一种random dropping out input points的方法,存在两个参数p和q,每个点以q的概率进行丢弃,而q为在[0,p]之间均匀采样,这样做,可以让整体数据集体现出不同的稠密性和均匀性。MSG有一个巨大的问题是运算的问题,然后作者提出we can avoid the feature extraction in large scale neighborhoods at lowest levels,因为在低层级处理大规模数据,可能模板处理能力不够,感受野有些过大,基于此,作者提出了MRG。
方法二MRG有两部分向量构成,分别为上一层即Li-1层的向量和直接从raw point上提取的特征构成,当点比较稀疏时,给从raw point提取的特征基于较高的权值,而若点比较稠密,则给Li-1层提取的向量给予较高的权值,因为此时raw point的抽象程度可能不够,而从Li-1层的向量也由底层抽取而得,代表着更大的感受野。当局部区域的密度较低时,第一个矢量可能不如第二个矢量可靠,因为在计算第一个矢量中的子区域包含更稀疏的点并且更多地受到抽样不足的影响。 在这种情况下,第二个向量应该加权得更高。 当局部区域的密度很高时,第一个矢量提供更精细的细节信息,因为它具有以较低分辨率递归地检查较高分辨率的能力。
整体的网络结构:
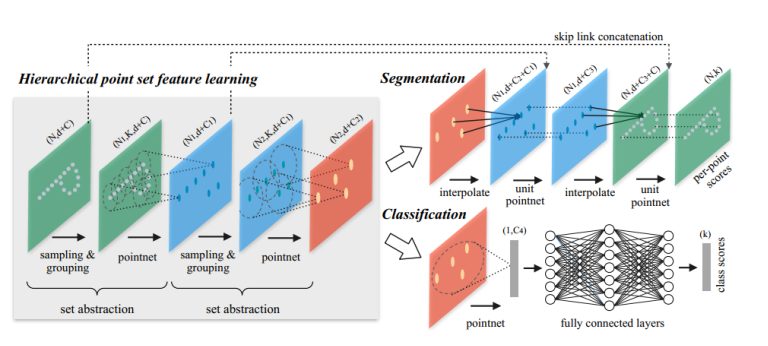
在整体网络结构中,首先进行set abstraction,这一部分主要即对点云中的点进行局部划分,提取整体特征,如图可见,在set abstraction中,主要有Sampling layer、Grouping layer、以及PointNet layer三层构成,sampling layer即完成提取中心点工作,采用fps算法,而在grouping中,即完成group操作,采用mrg或msg方法,最后对于提取出得点,使用pointnet进行特征提取。在msg中,第一层set abstraction取中心点512个,半径分别为0.1、0.2、0.4,每个圈内的最大点数为16,32,128。在classification的处理上,与pointnet相似。
分割和语义部分:
在集合抽象层中,对原始点集进行二次抽样。 然而,在集合分割任务中,比如语义点标注,
我们希望获得所有原始点的点特征。
方法1:
always sample all points as centroids in all set abstraction levels (高成本)
方法2:
propagate features from subsampled points to the original points
hierarchical propagation strategy with distance based interpolation and across level skip links

In a feature propagation level, we propagate point features from
Nl × (d + C) points to Nl-1 points where Nl-1 and Nl (with Nl ≤ Nl-1) are point set size of input and output of set abstraction level l.
我们通过在Nl1点的坐标处插入Nl个点的特征值f来实现特征传播。在插值的众多选择中,我们使用基于k近邻的反向距离加权平均值。
插值及回溯的方式,对于l - 1层的点,它有l层点插值后与在set abstraction时得到的特征进行1 * 1的卷积,最终得到l - 1层的点的值,一直回溯,最终得到原始点的score。插值公式如下:
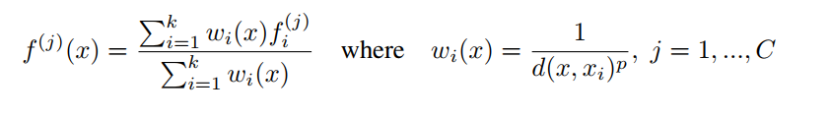
The interpolated features on Nl-1 points are then concatenated with skip linked point features from the set abstraction level.