在PointNet++中,特征提取的采样点是通过最远点采样法得到的。其基本思想就是:
①首先随机取一个点a,然后遍历其余剩余的点,计算与a的距离,得到最远距离点b;
②遍历剩余点与a,b的距离,得到距离最远的点c;
③重复执行以上,直到取够设定点的个数。
具体可举例,下图展示的是一个batch中的计算过程,程序中8个batch同时进行的。
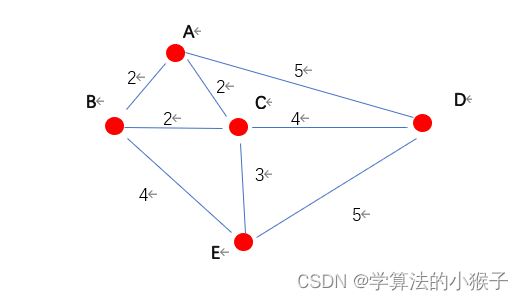
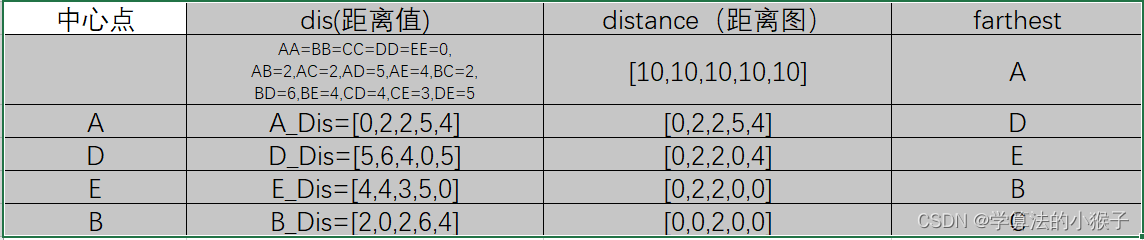
①随机选取中心点A,建立距离分布图distance并赋很大的值;
②分别计算A点到B、C、D、E点距离,得到A_Dis;将A_Dis与distance比较,如果Dis中存在小于distance中的值,就将其更新到distance中;然后根据新的distance图,获得最大距离值的点D;
③以D点为中心点,计算与其他点的位置,得到D_Dis;将D_Dis与distance比较,如果Dis中存在小于distance中的值,就将其更新到distance中;然后根据新的distance图,获得最大距离值的点E;
④重复以上循环,得到中心点B,C。
其程序及详解可参考源码。
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3],如batch=8,输入点N=1024,位置信息xyz=3
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint],返回值是采样后的中心点索引
"""
device = xyz.device
B, N, C = xyz.shape
'''构建一个tensor,用来存放点的索引值(即第n个点)'''
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)#8*512
'''构建一个距离矩阵表,用来存放点之间的最小距离值'''
distance = torch.ones(B, N).to(device) * 1e10 #8*1024
'''batch里每个样本随机初始化一个最远点的索引(每个batch里从1024个点中取一个)'''
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)#type为tensor(8,)
'''构建一个索引tensor'''
batch_indices = torch.arange(B, dtype=torch.long).to(device)#type为tensor(8,)
for i in range(npoint):
centroids[:, i] = farthest #第一个采样点选随机初始化的索引
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)#得到当前采样点的坐标 B*3
dist = torch.sum((xyz - centroid) ** 2, -1)#计算当前采样点与其他点的距离,type为tensor(8,1024)
mask = dist < distance#选择距离最近的来更新距离(更新维护这个表)
distance[mask] = dist[mask]#将新的距离值更新到表中
'''重新计算得到最远点索引(在更新的表中选择距离最大的那个点)'''
farthest = torch.max(distance, -1)[1]#max函数返回值为value,index,因此取[1]值,即索引值,返回最远点索引
return centroids