1 Hierachical Tasks Network
层次任务网络:从任务目标出发的

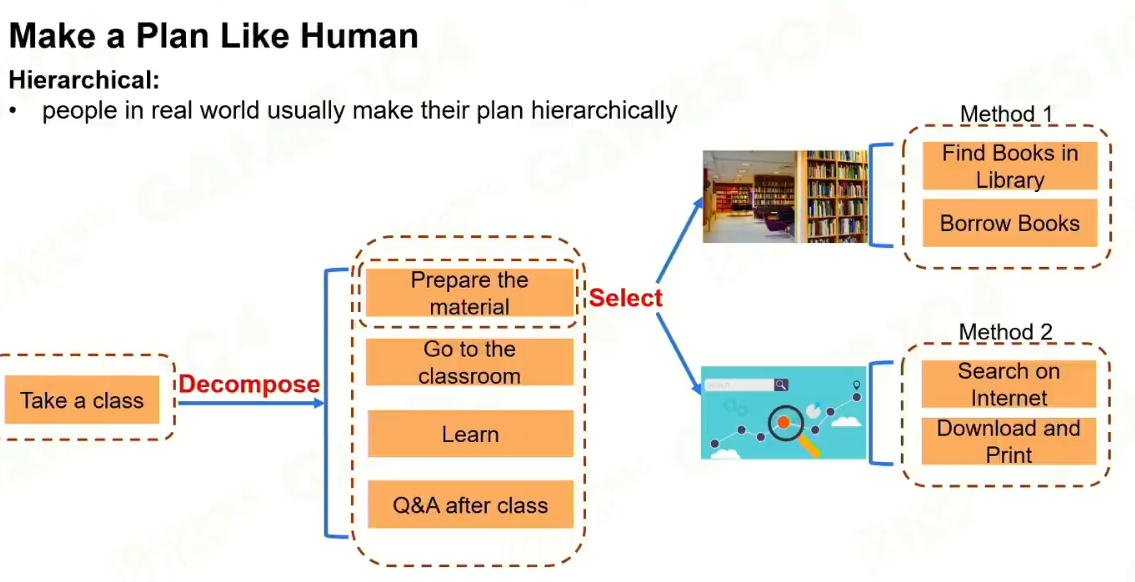
核心思想:定个计划,若干个完成的子任务。
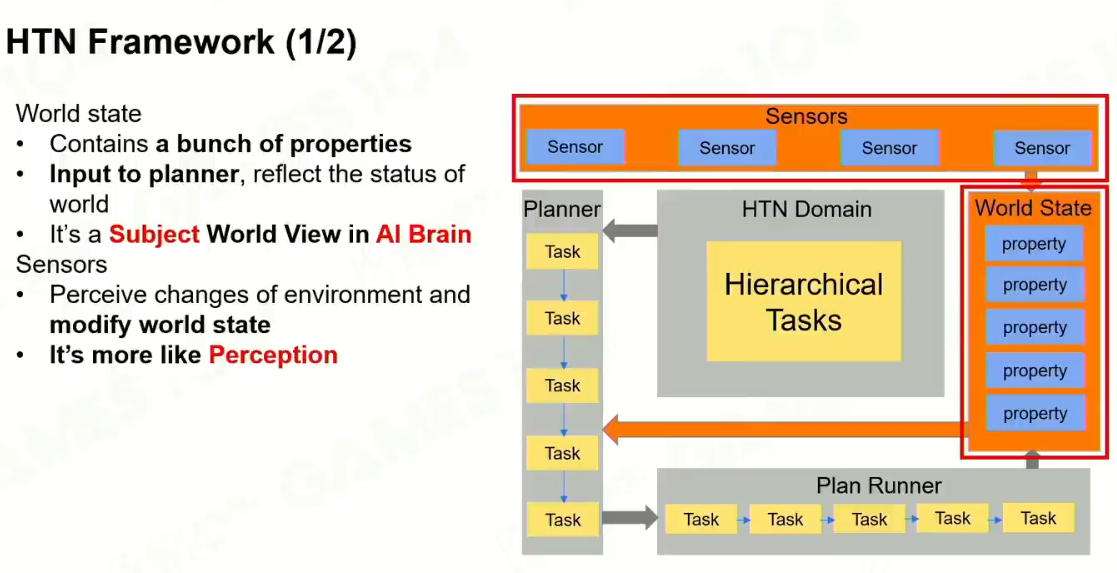
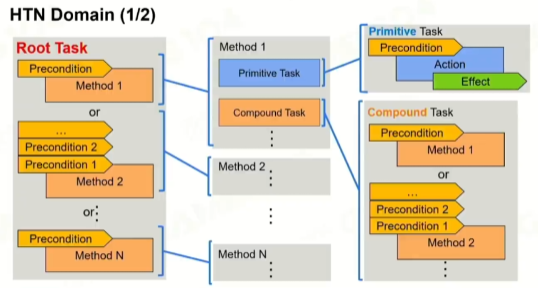
1 HTN框架
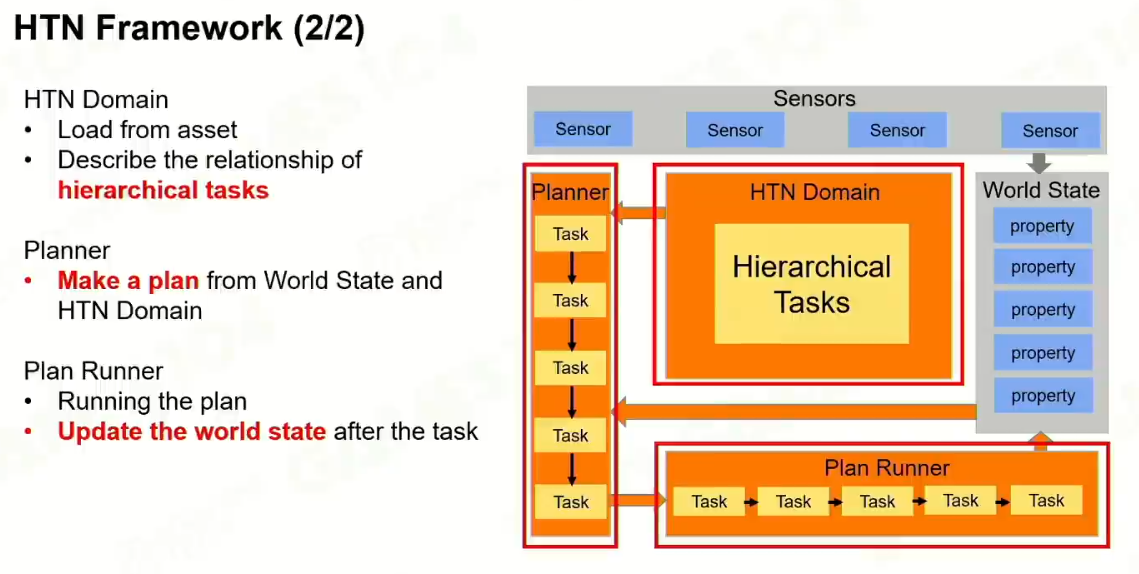
2 HTN Task Type

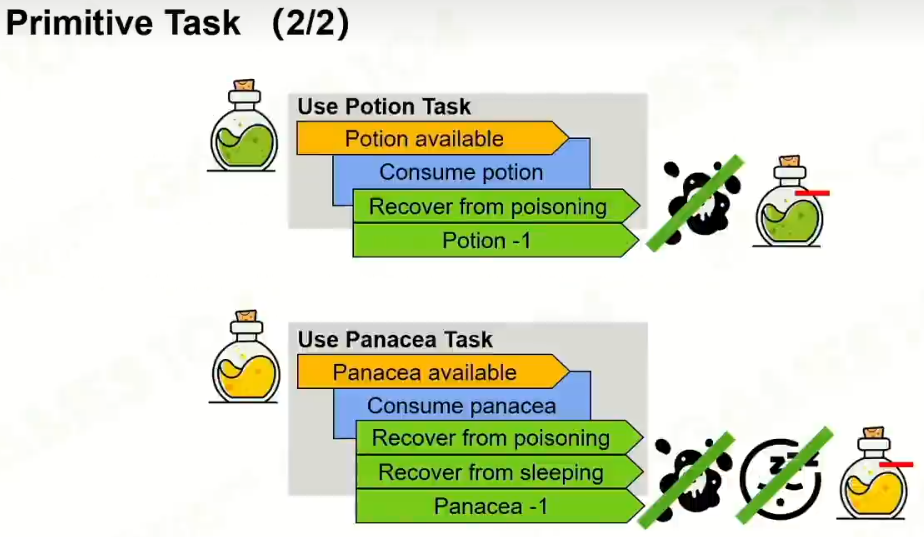
1 Primitive Task原子任务

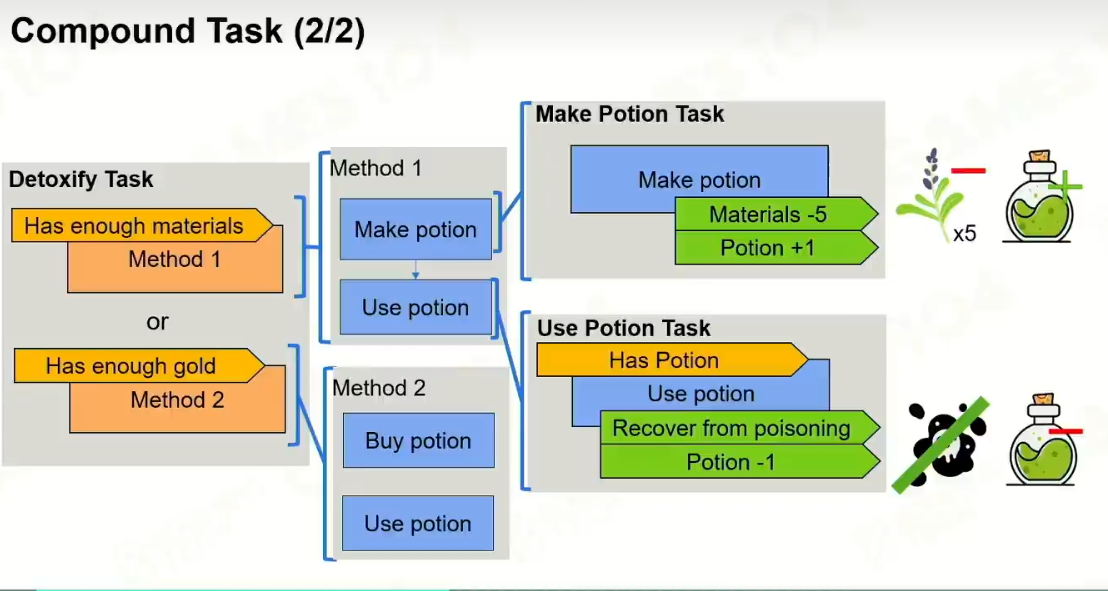
2 复合任务
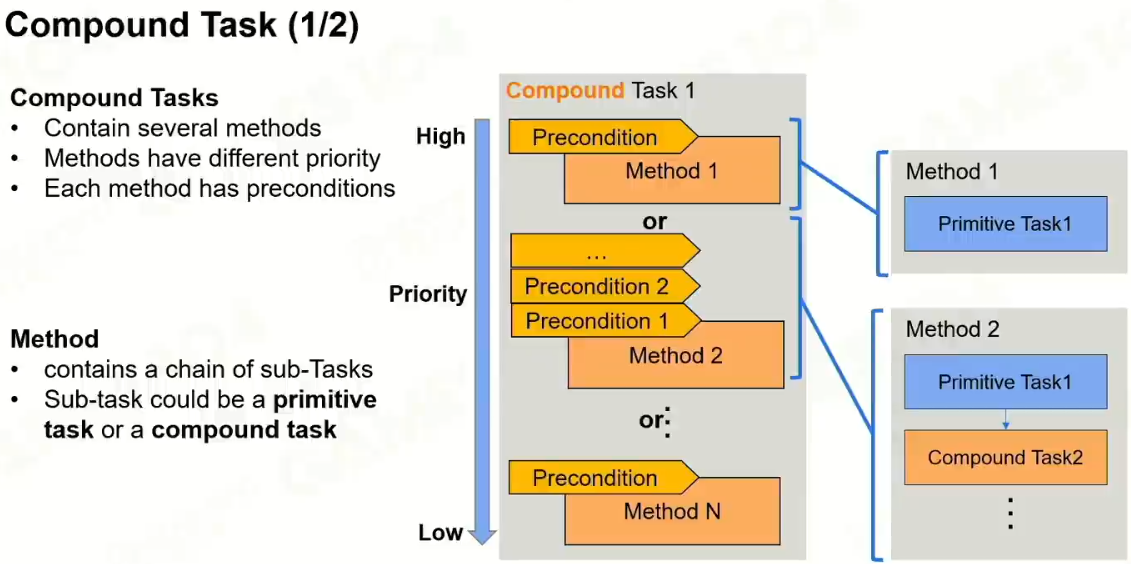
很方便构建自己的思维的行为树 。
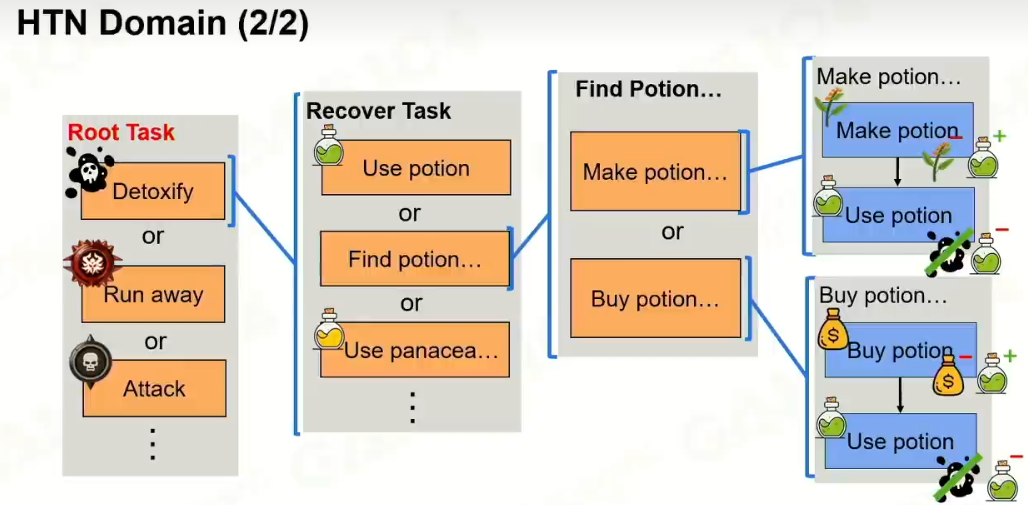
3 HTN Domain
HTN:可以和一般人进行沟通,行为树比骄傲麻烦
4 Planning
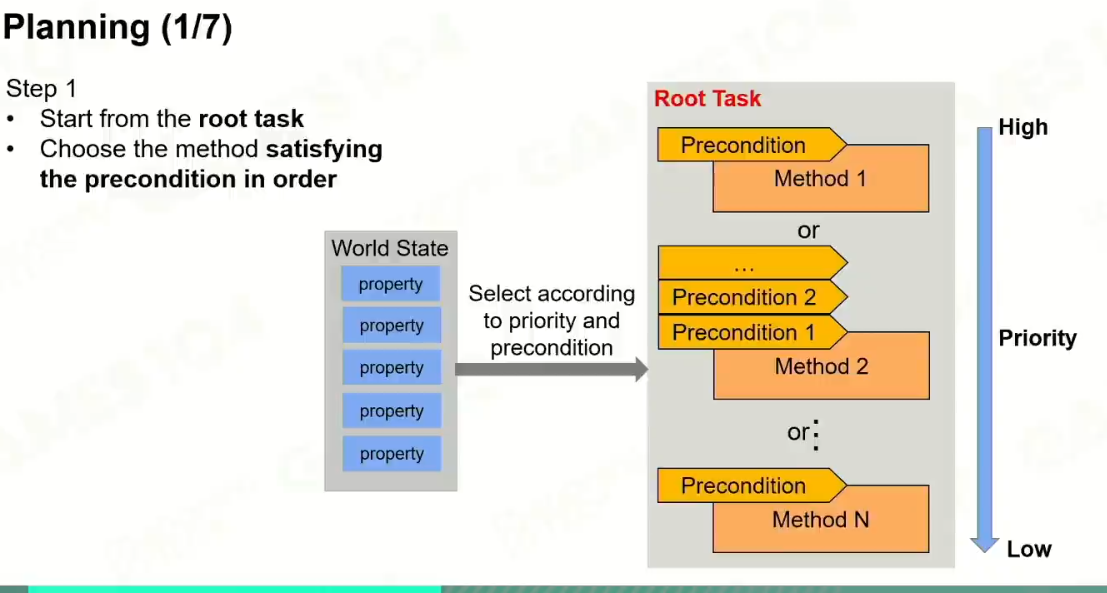
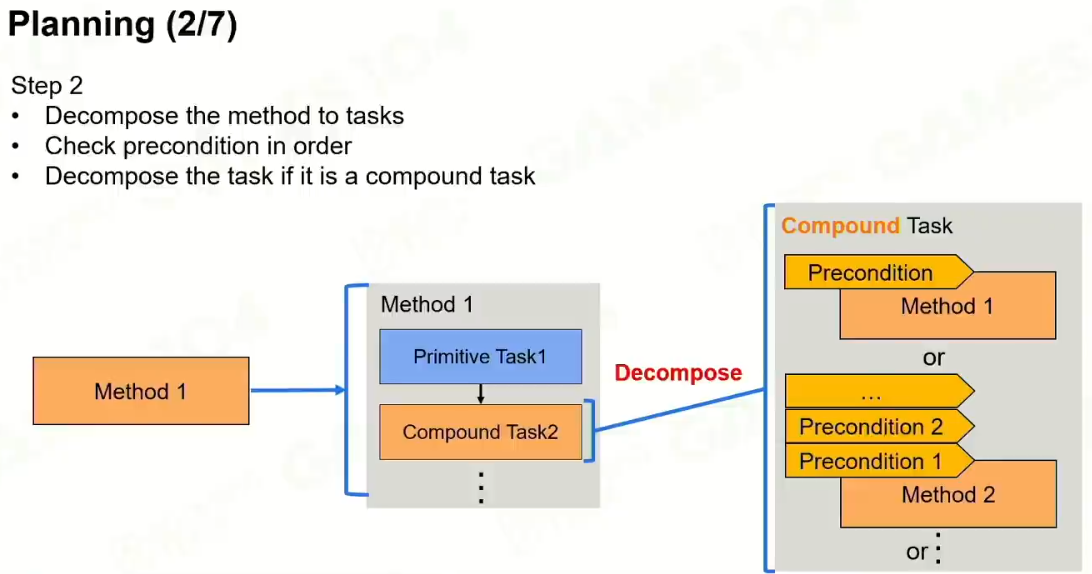
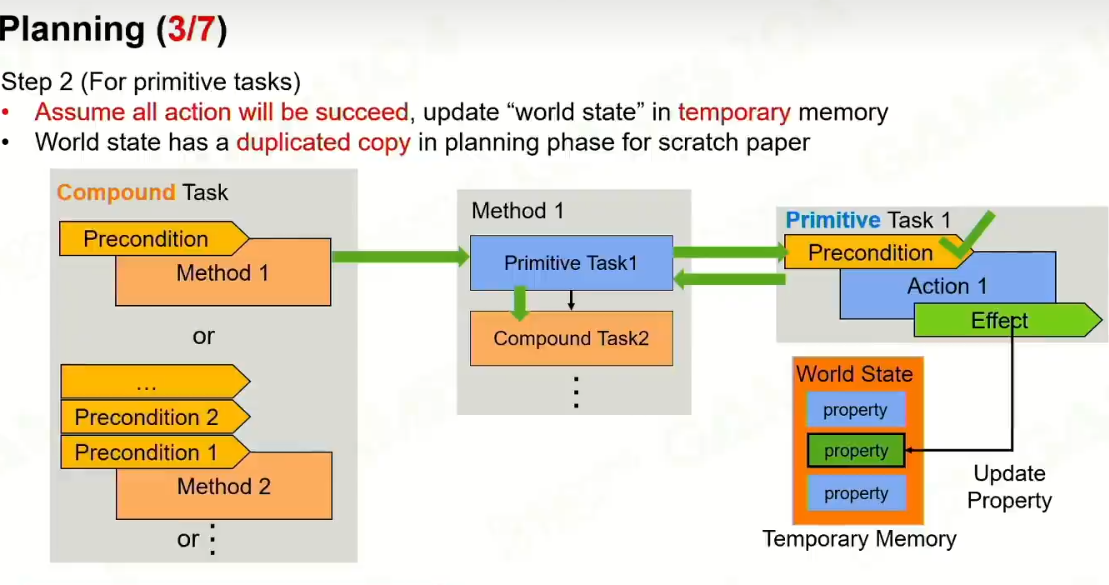
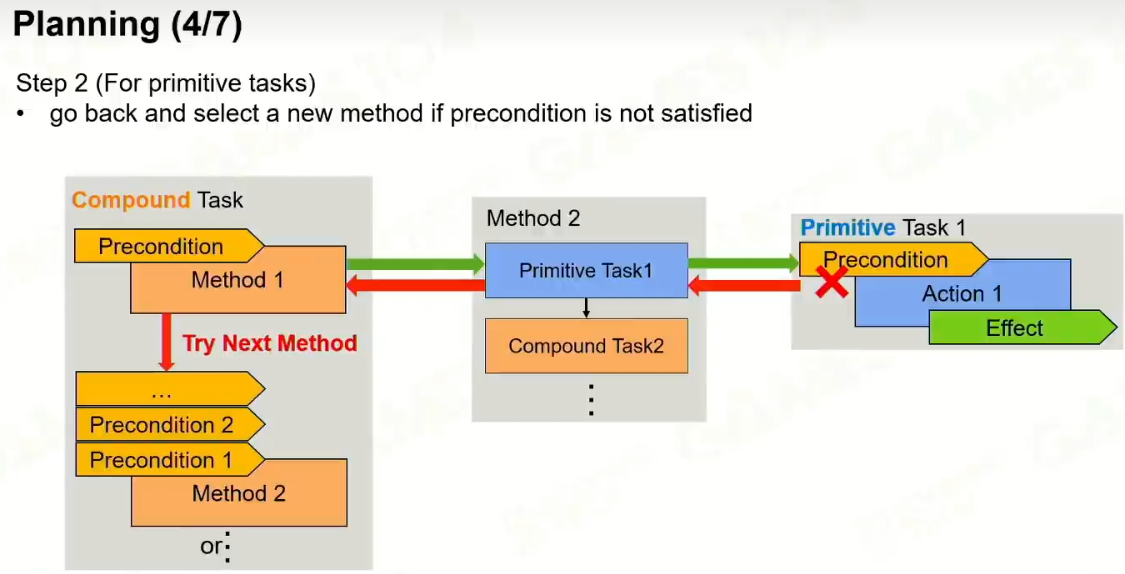
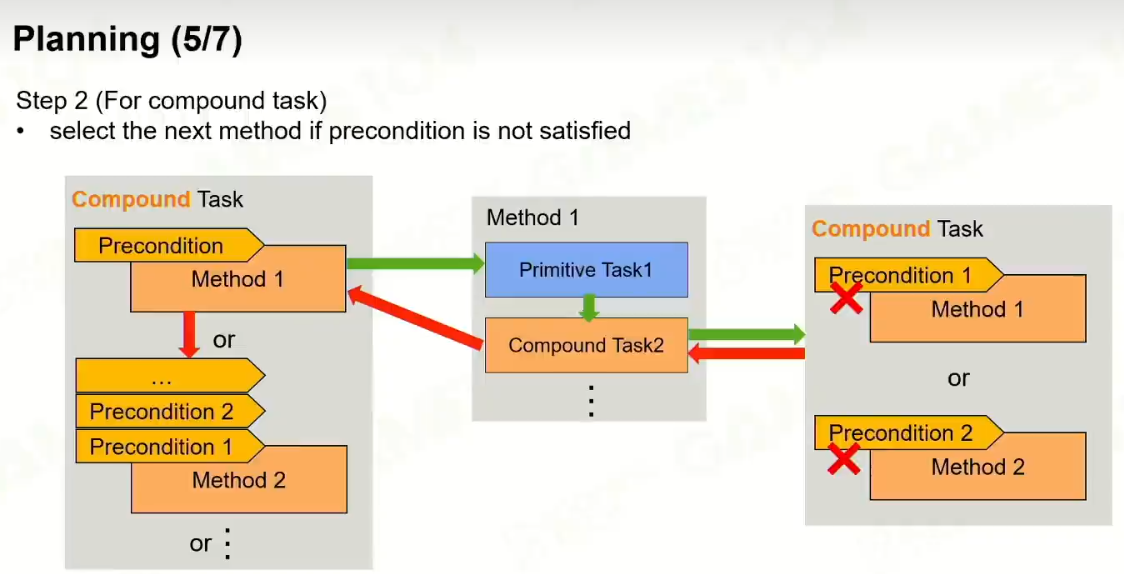
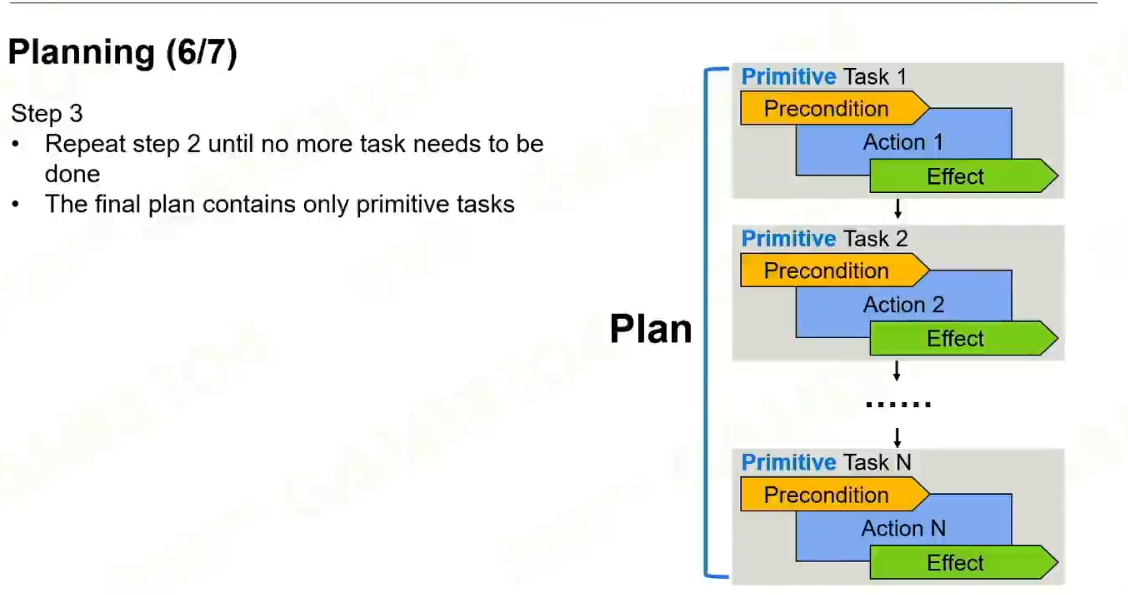
最后形成的是原子任务
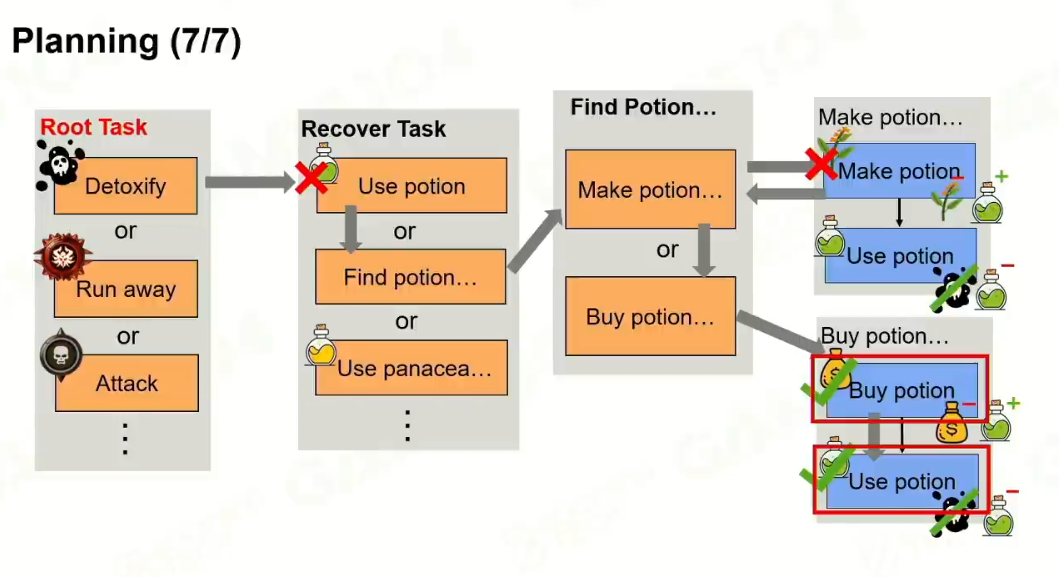
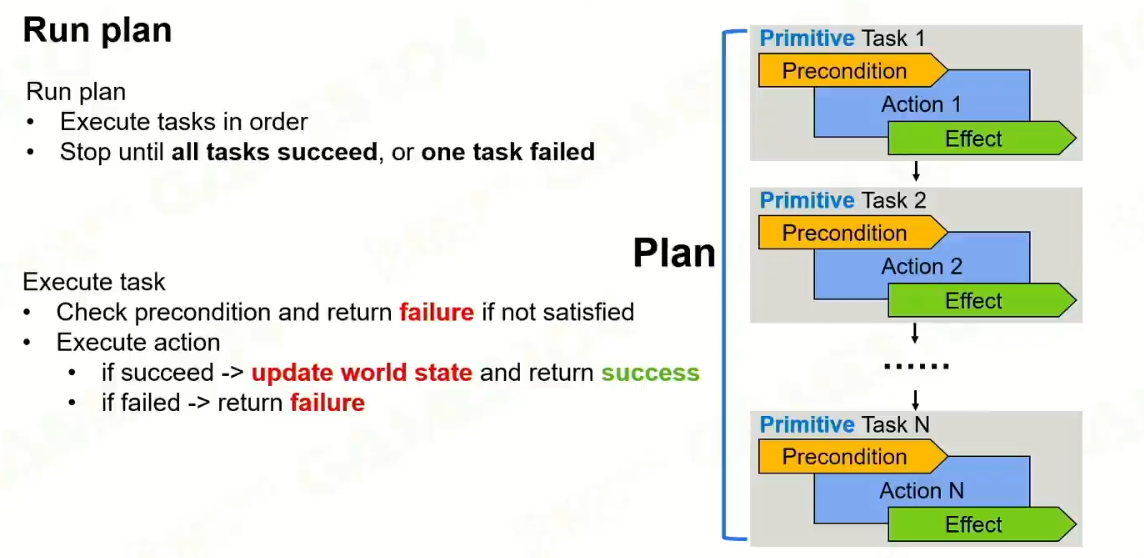
Replan是非常重要的。

5 总结
不好的地方:无法预测,任务可能失败。
对于设计师是有竞争的。
计划长 过于缜密,会有问题。

2 Goal oritented Action Planning
规划:
目标导向行为规划

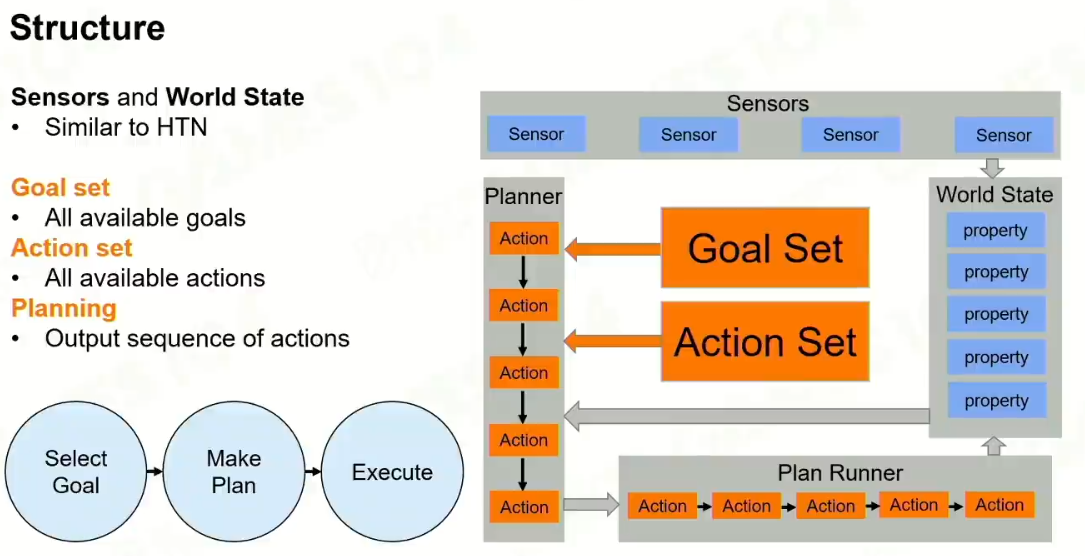
1 结构:
目标:在htn中没有显示的显示出来
但是在GOAP中是写的很清楚的。
是规划问题,不是计划问题。
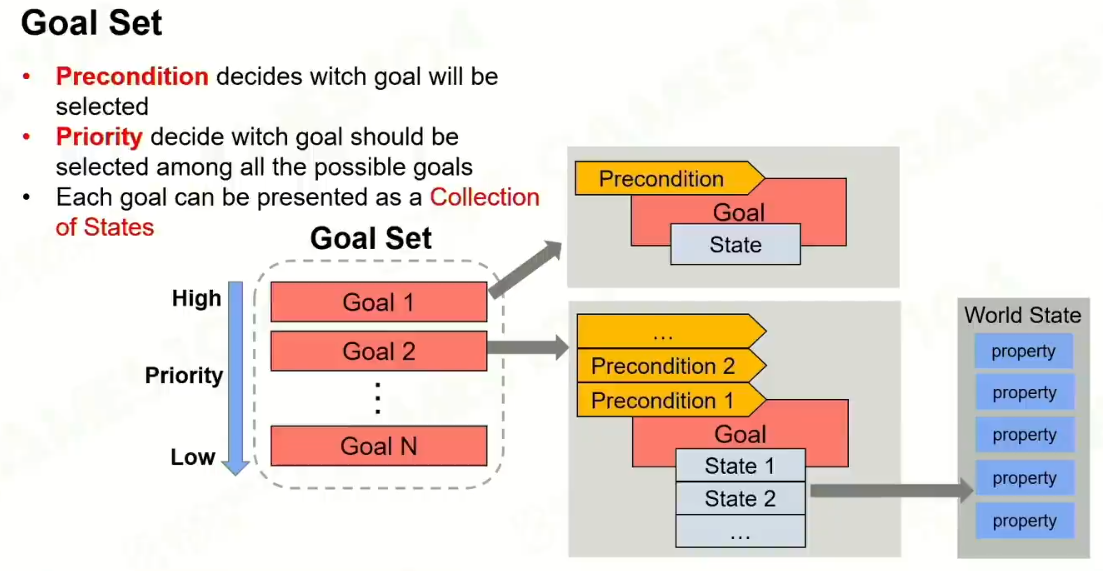
2 Goal set
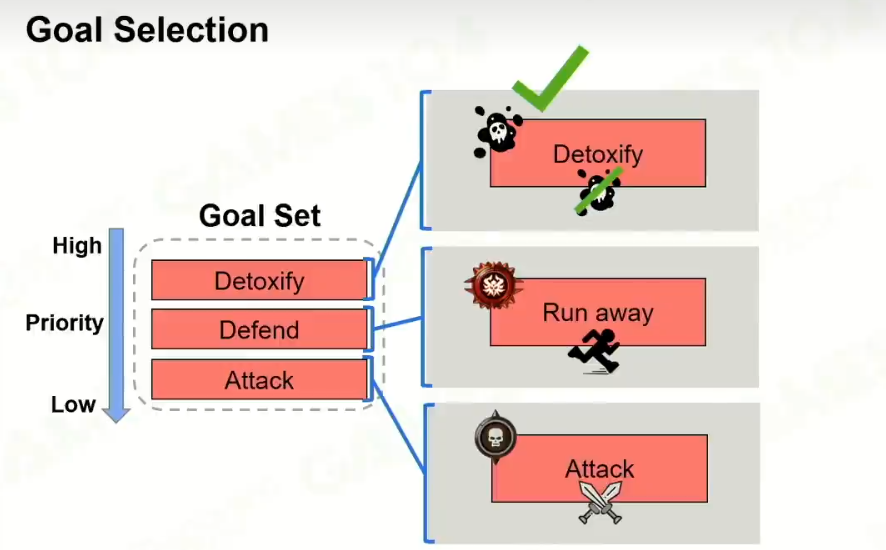
3 Goal selection
4 Action set
增加了额外的cost。
所有的动态规划问题都要考虑cost。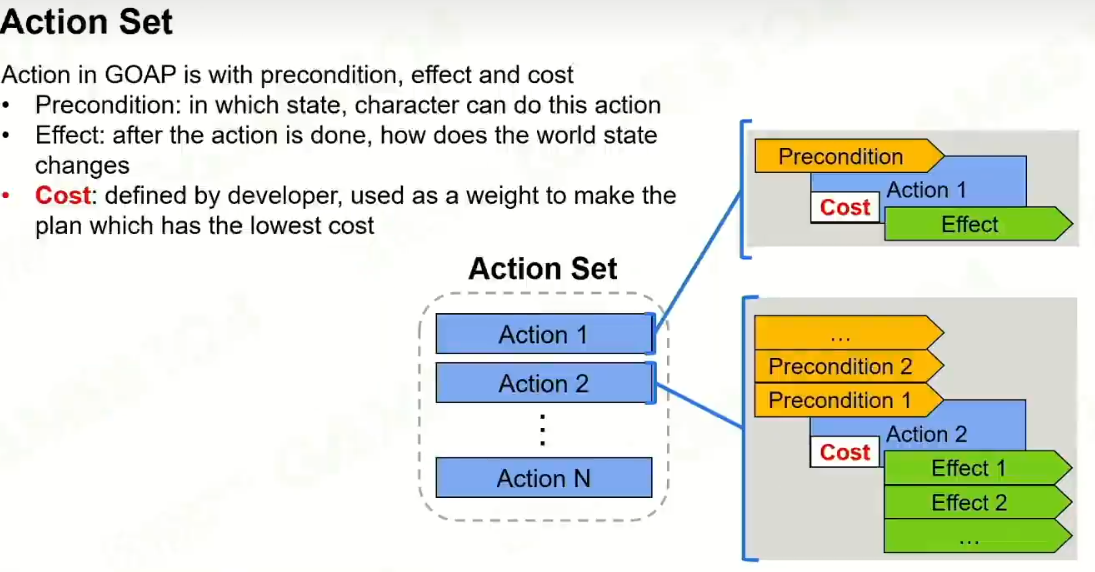
倒着去计划我的goal state。很像人类倒叙的思考方法。
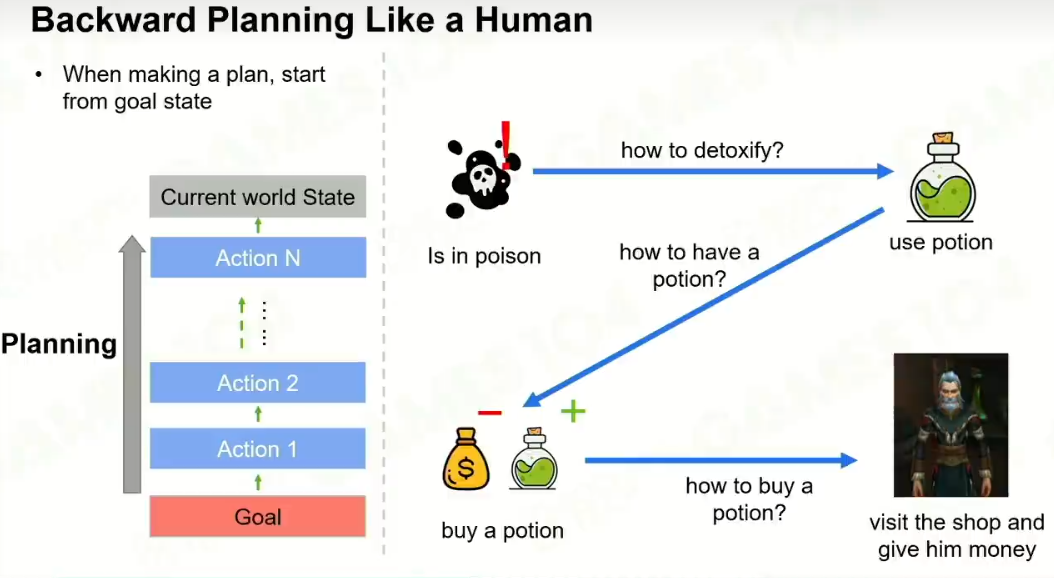
5 planning
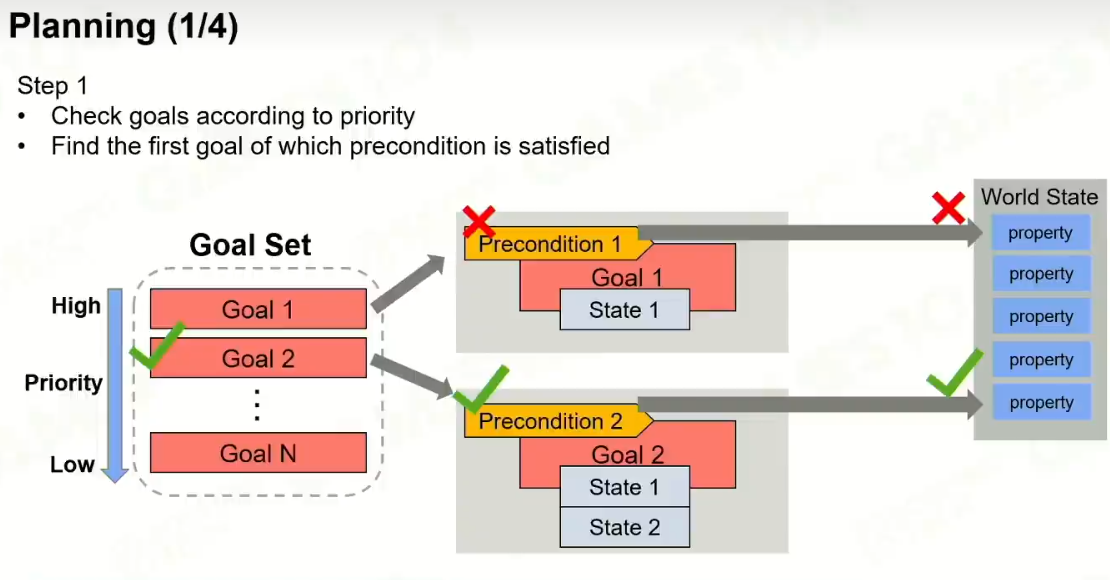
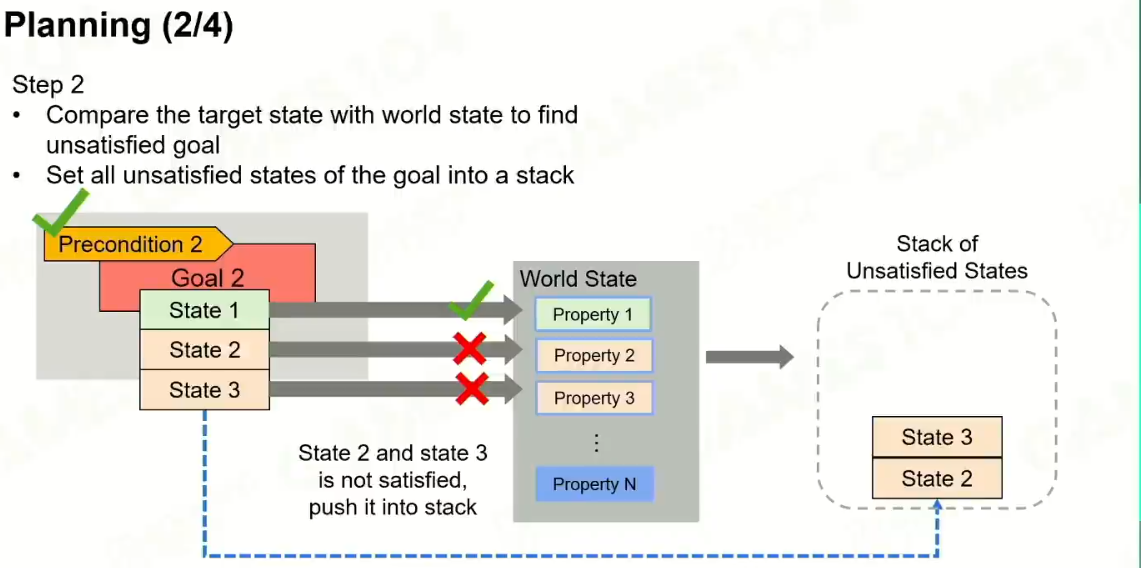
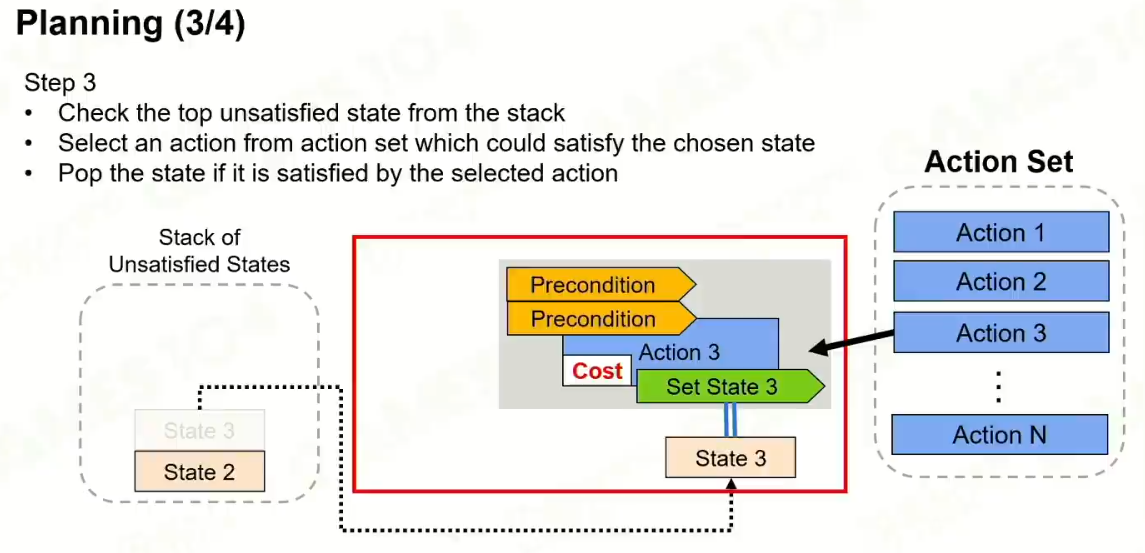
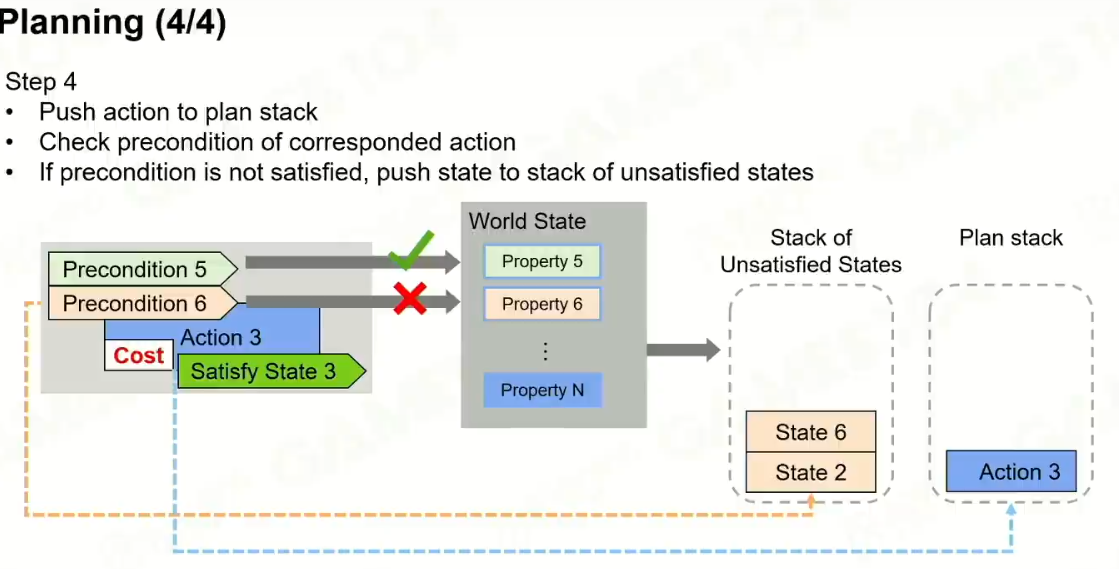
规划出一条路径,最后让unstatisfied states栈清空。
动态规划是一个np问题。
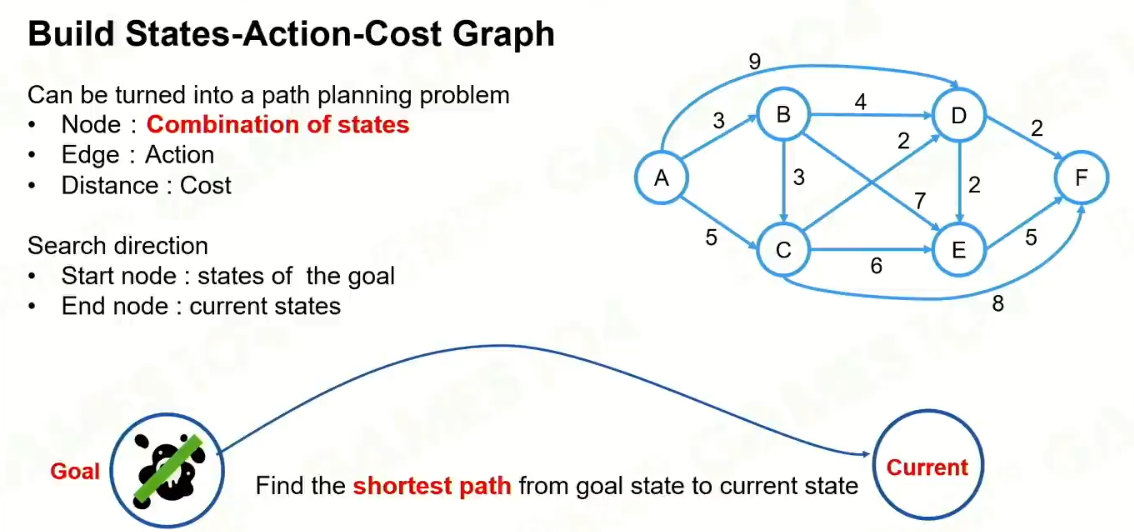
根据我的目标,展开成一个巨大的图,寻找一个最短路径。使用A*算法
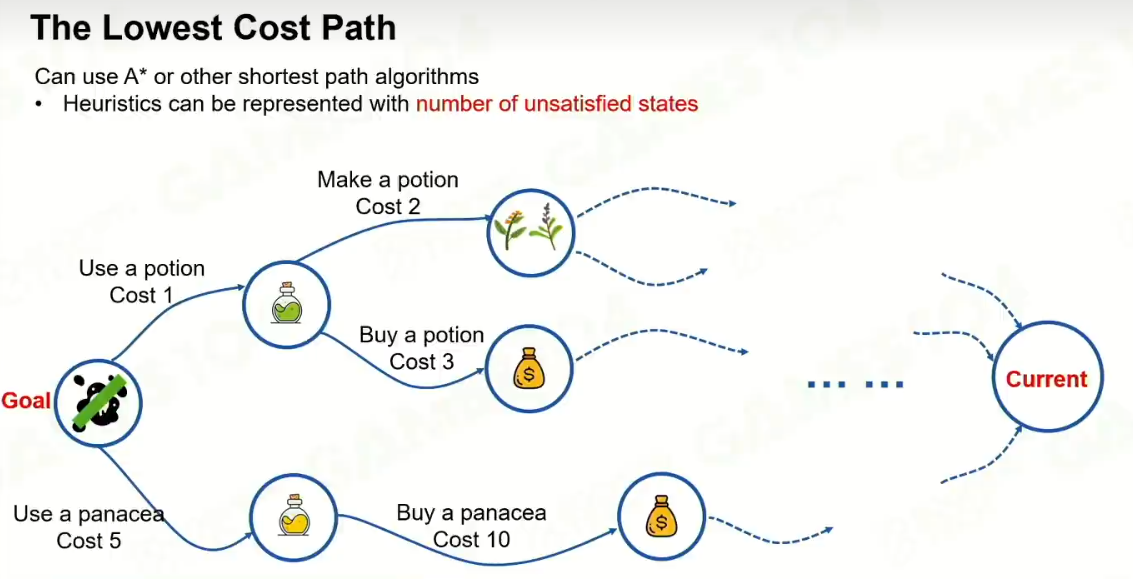
6 总结
第一次将目标和行为分开来。AI的行为很精彩。
缺点:计算量大;游戏的状态表达成定量的表达。

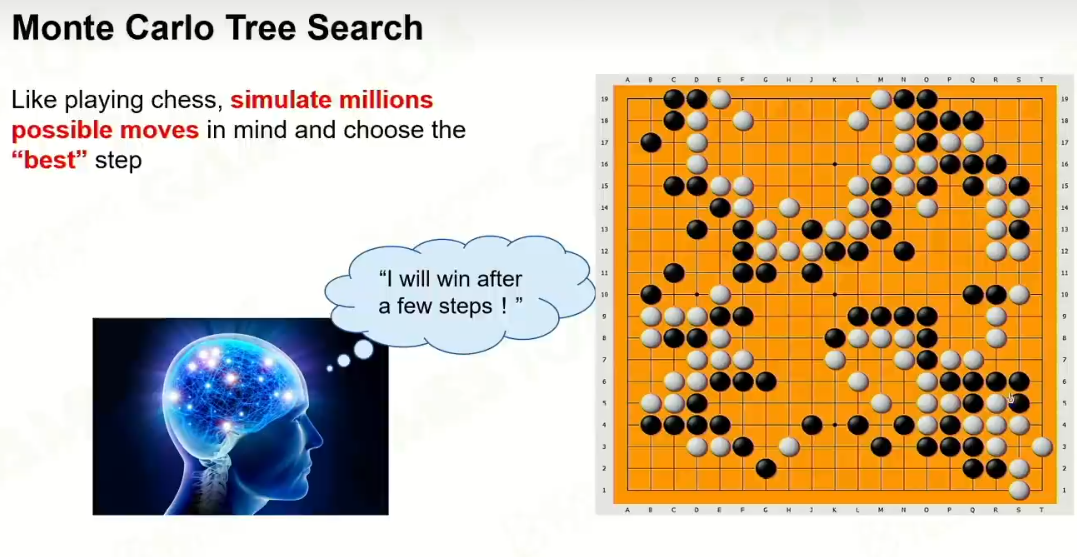
3 蒙特卡洛树搜索(MCTS)
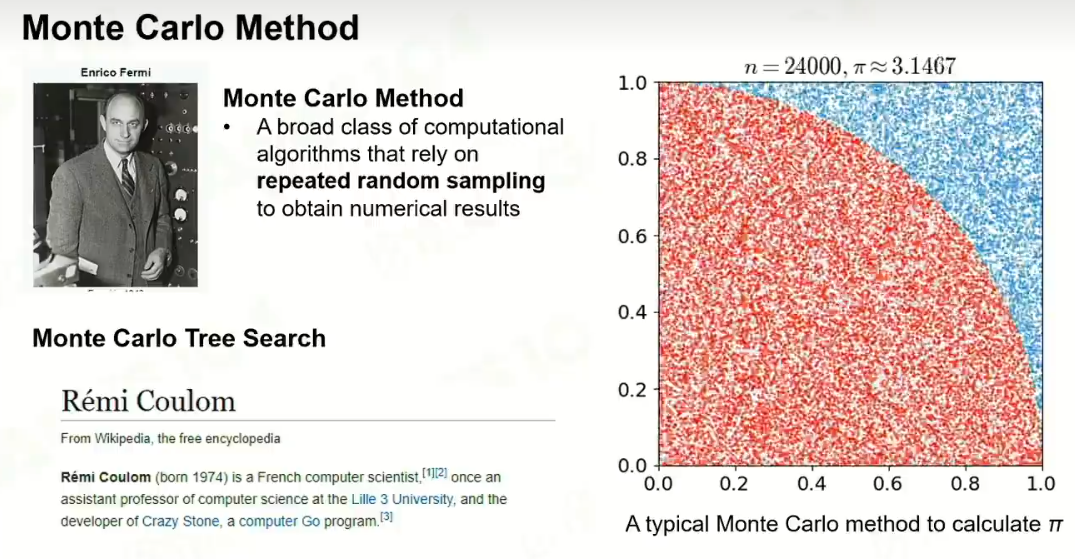
1 蒙特卡洛方法
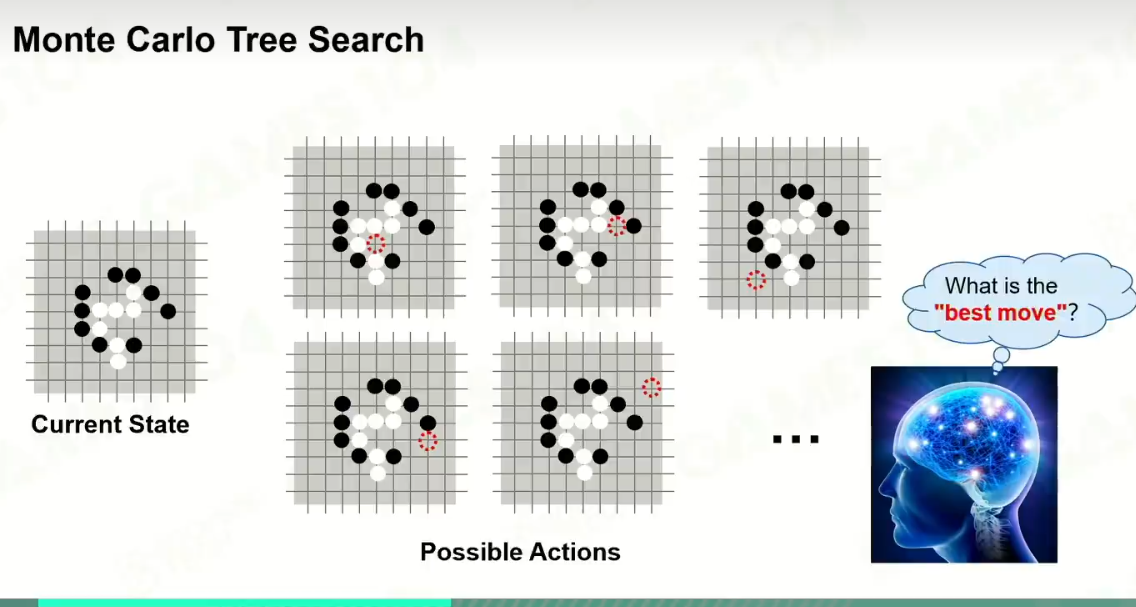
2 MCTS
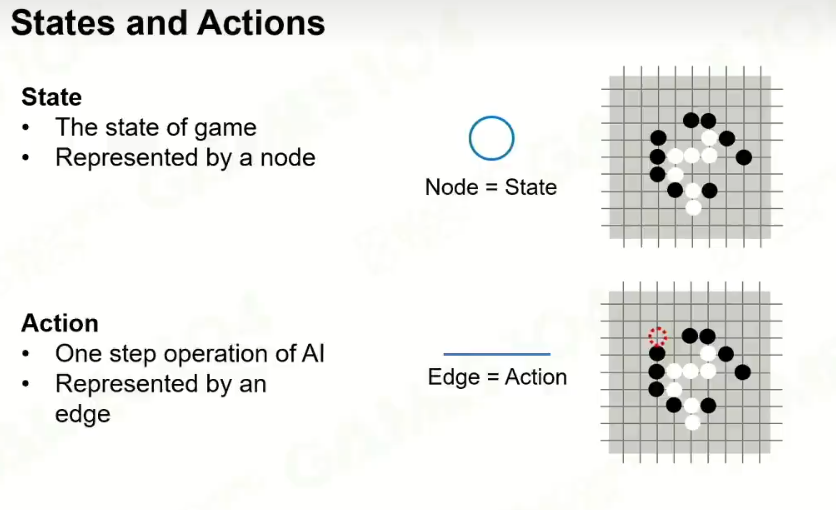
抽象为数学模型:
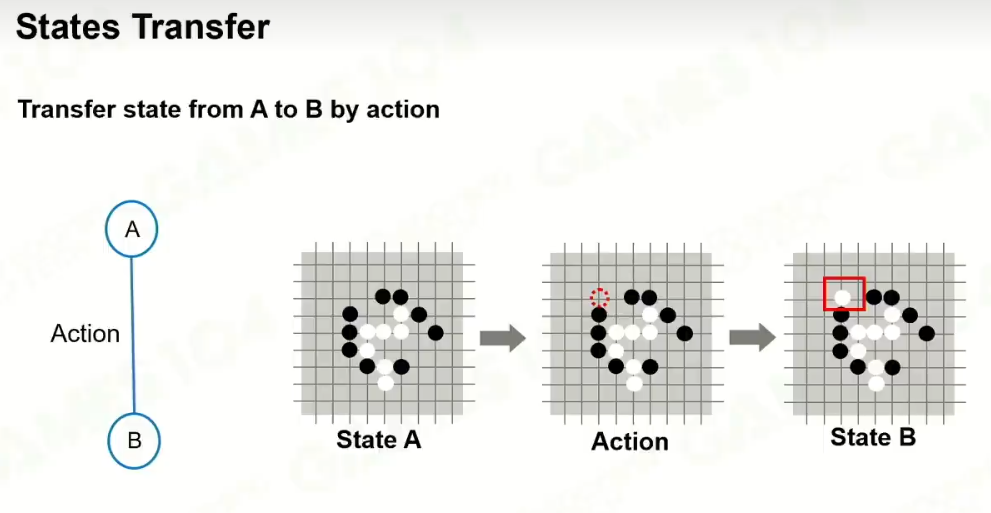
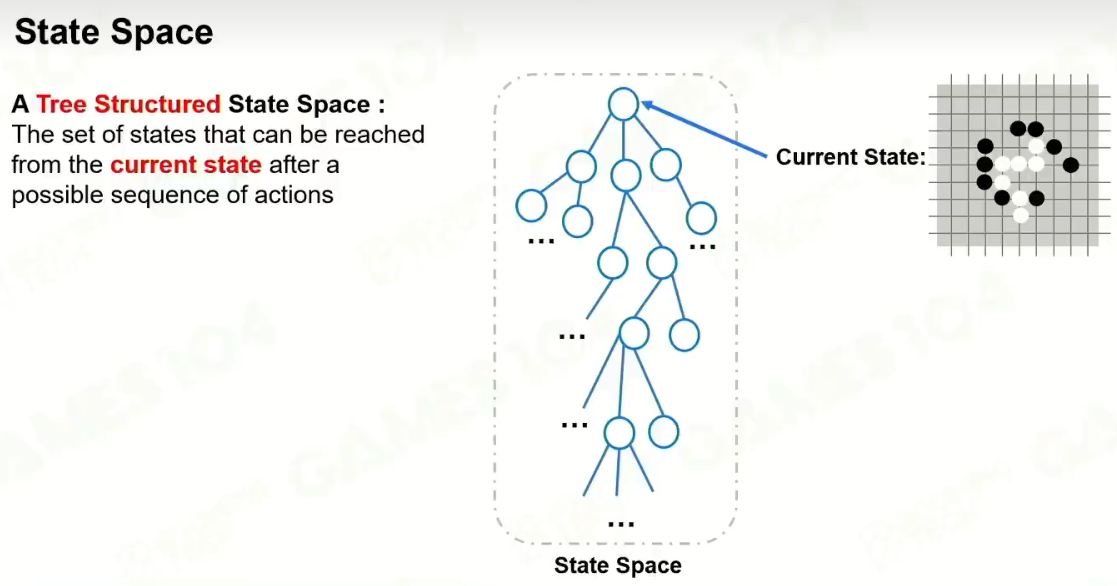
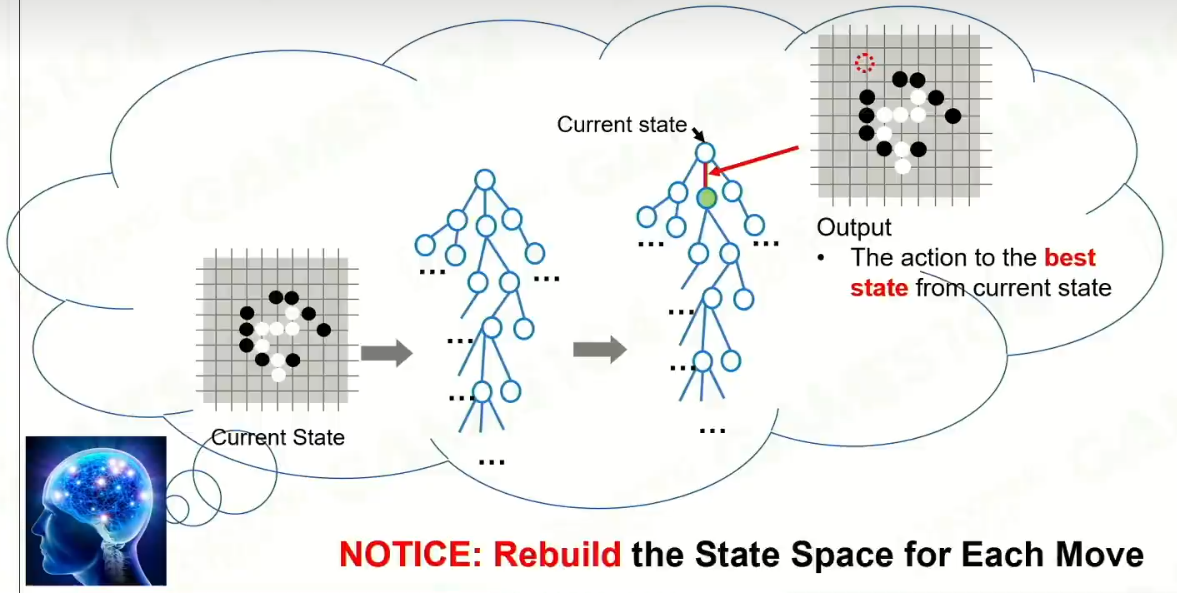
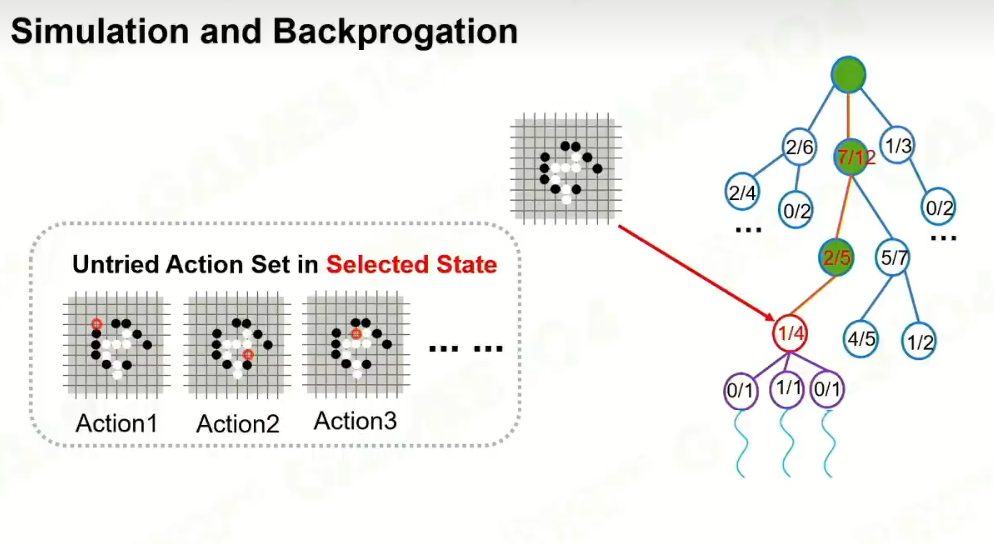
3 模拟

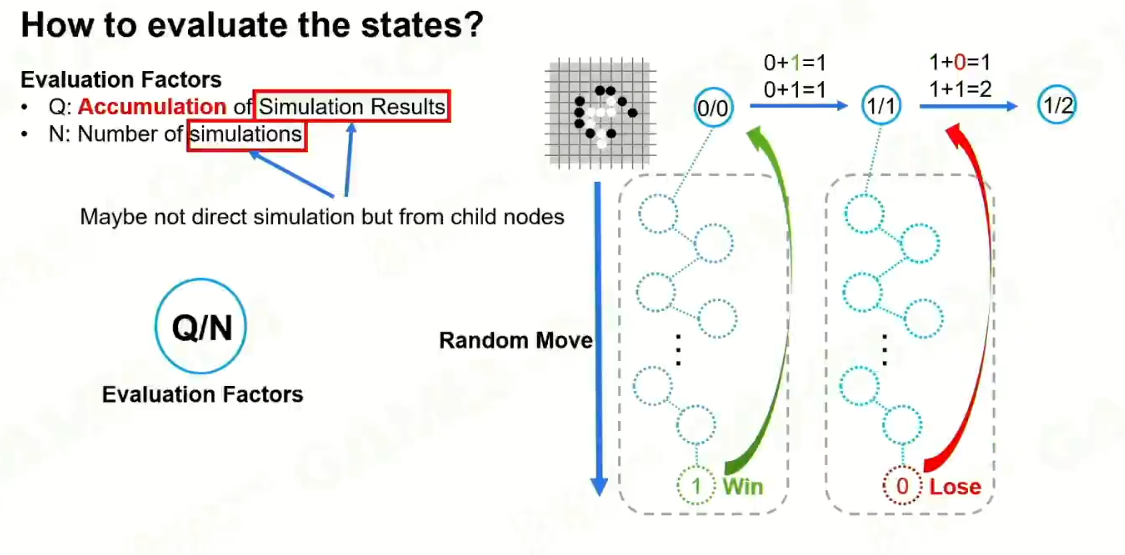
反向推导:
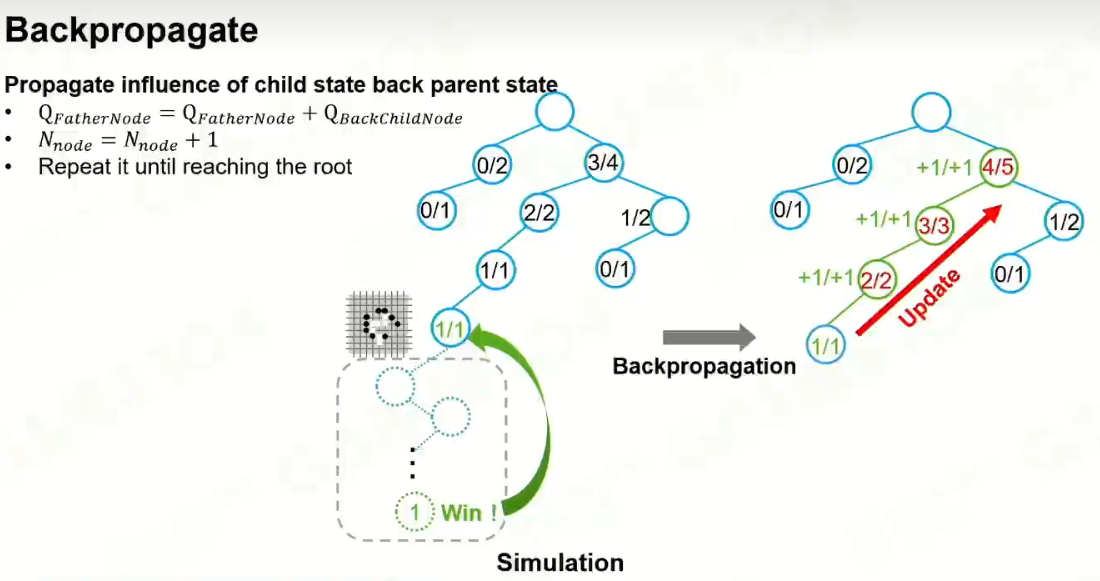
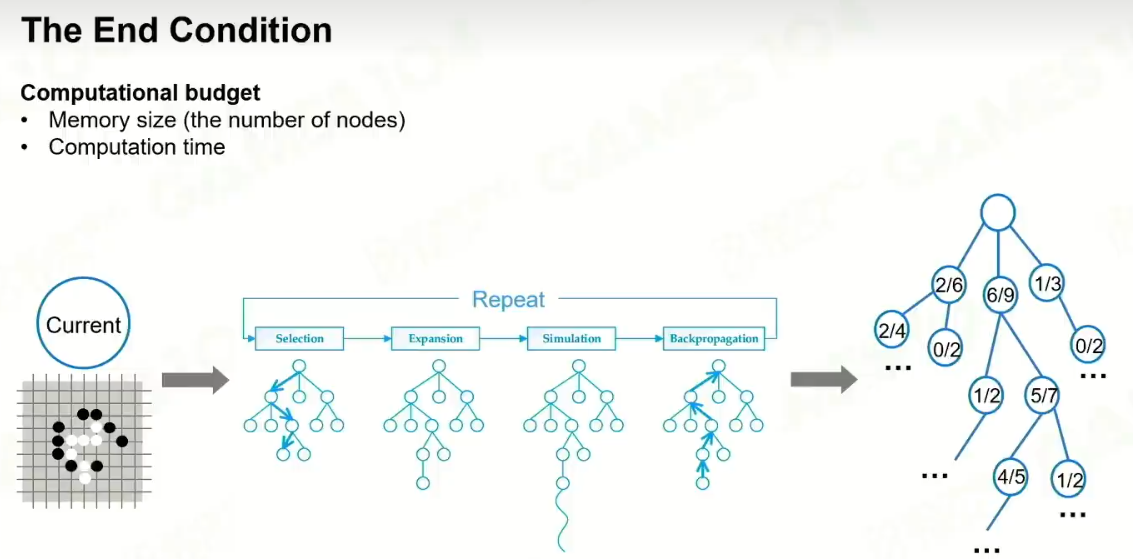
迭代:
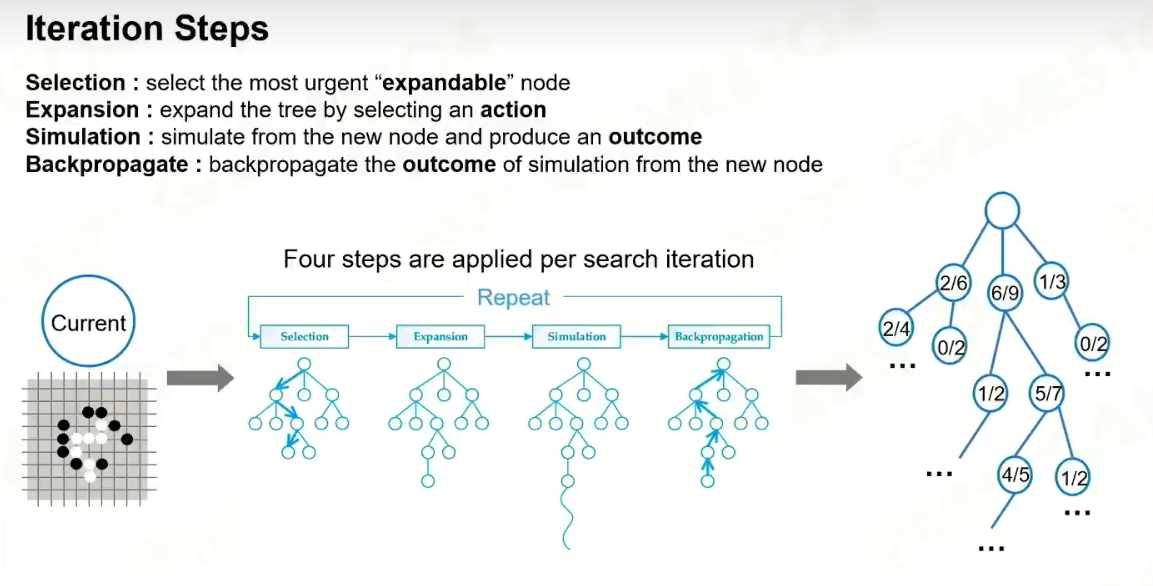
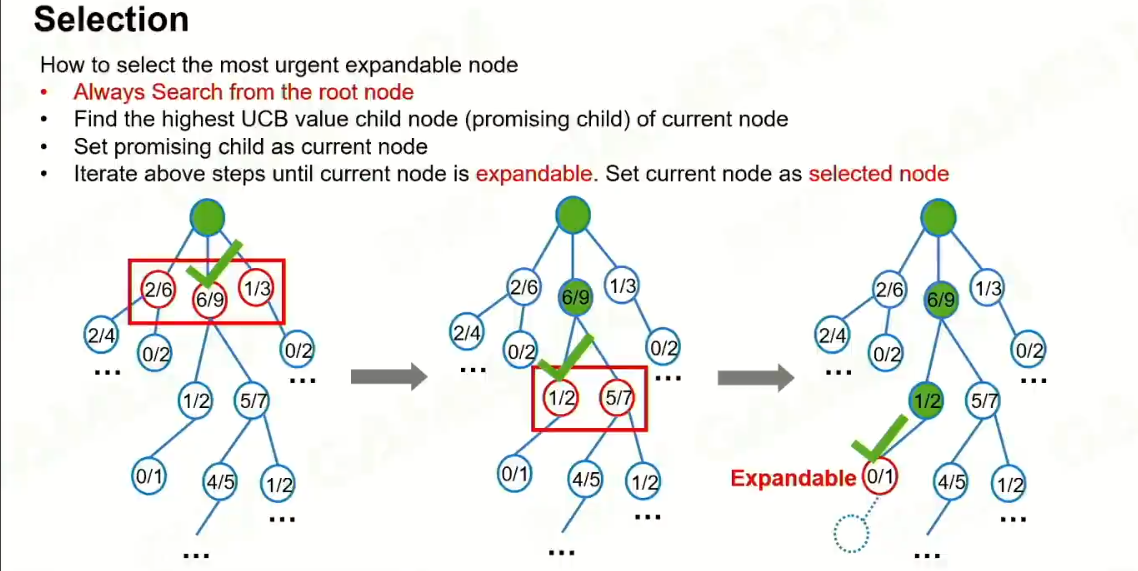
4 Selection
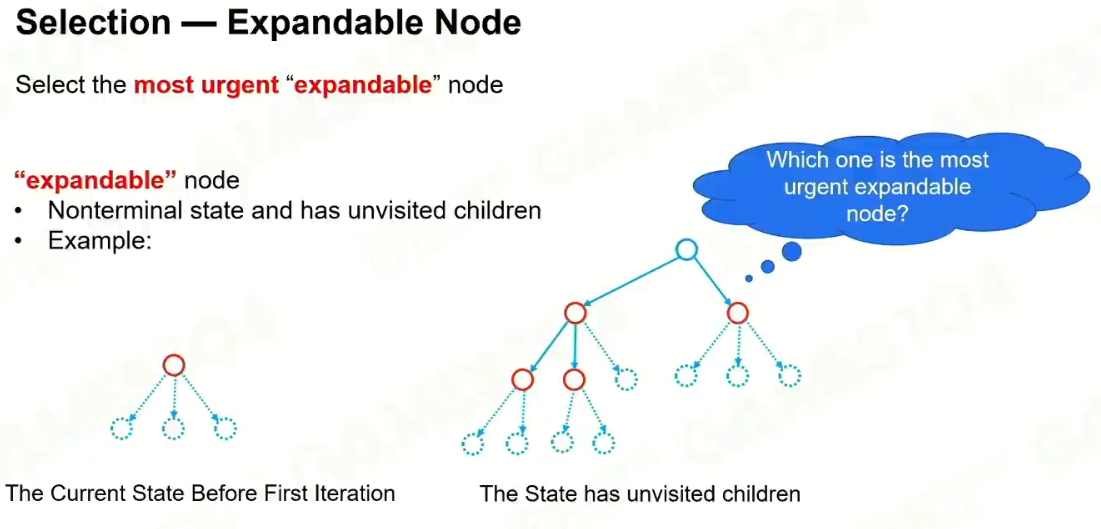
开发,探索。

UCB
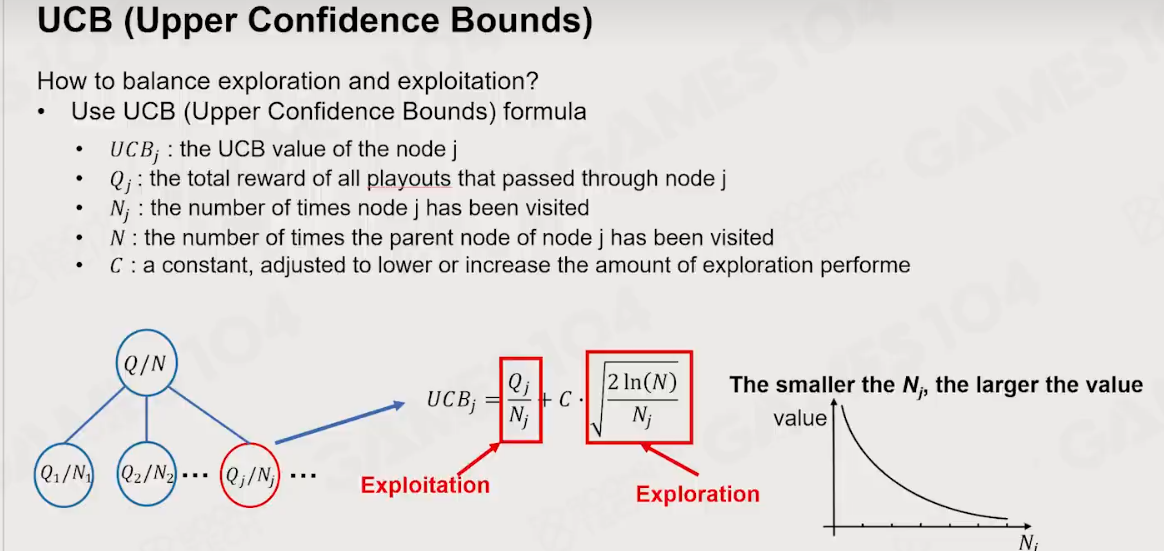
C----小,就保守点。
LCB
C的设置就是调了。
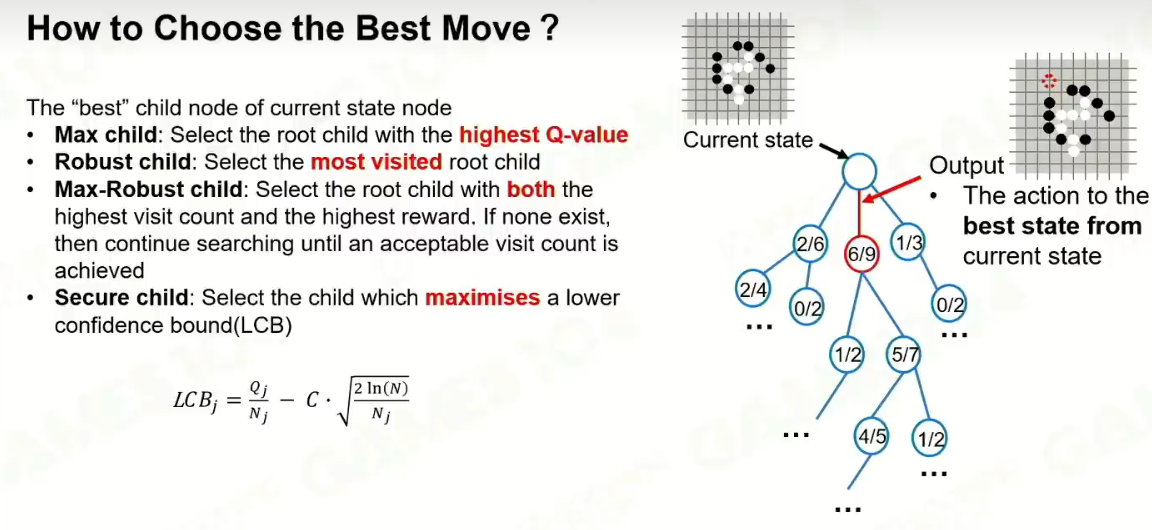
5 总结
对于复杂游戏很难定义赢还是输,不一定可以适合所有的游戏。
输出是非常明确的,MTCS是很符合的,否则不能只用MCTS。

4 deeplearning
1 Mechine learning Basic
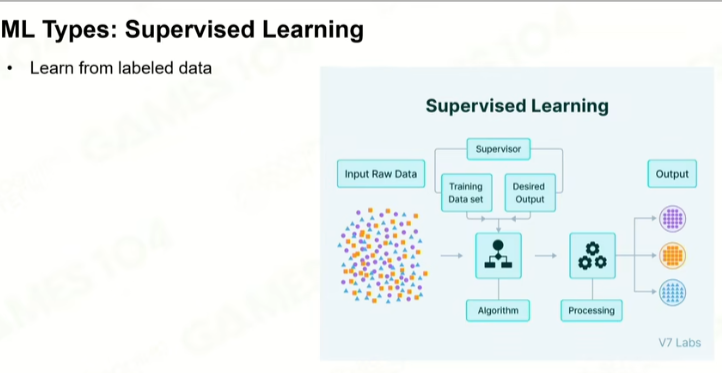
1 监督学习
核心基础是分类器。这个需要大量的数据,
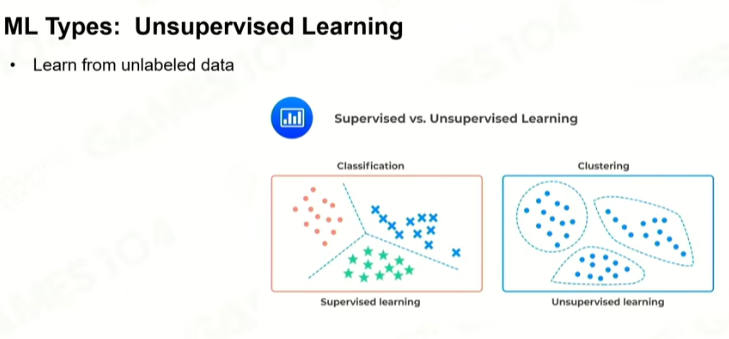
2 无监督学习
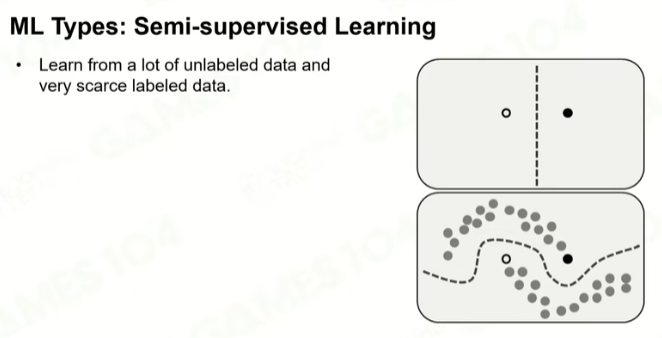
3 半监督学习
半监督学习。
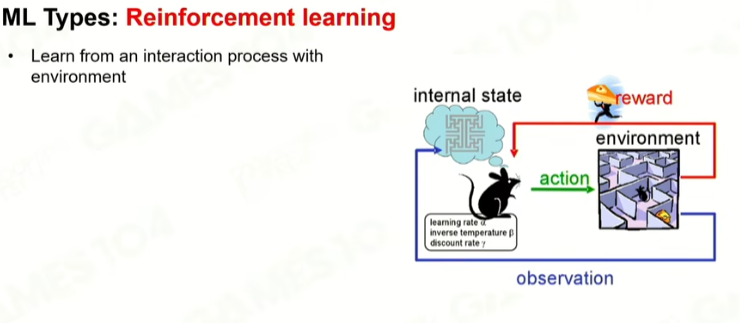
4 强化学习
没有监督者,没有人告诉你是对的,还是错的,做对了有奖励,做错了有惩罚。
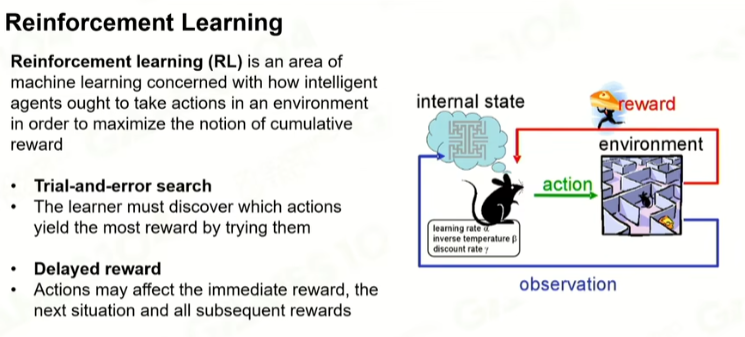
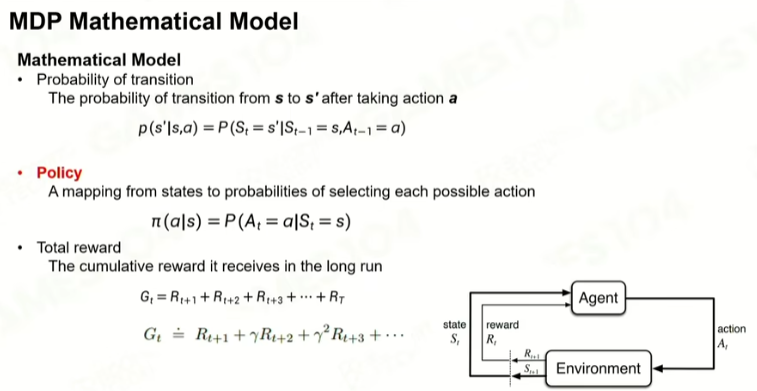
1 马尔可夫
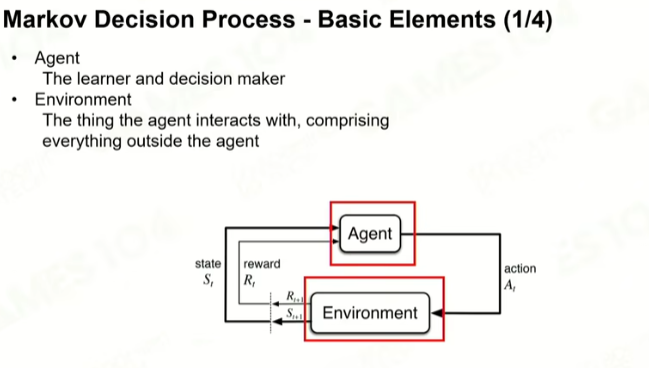
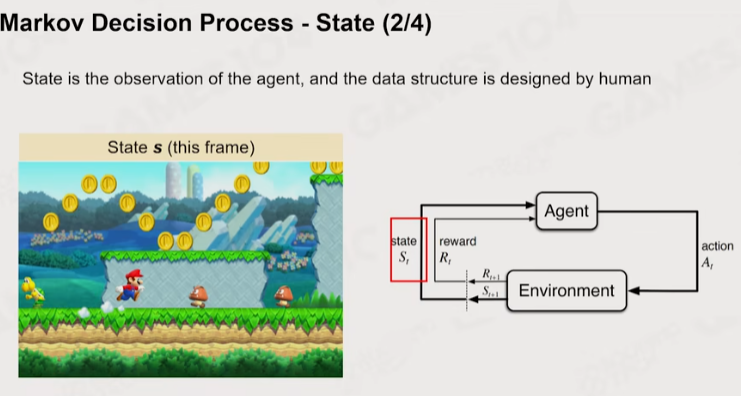
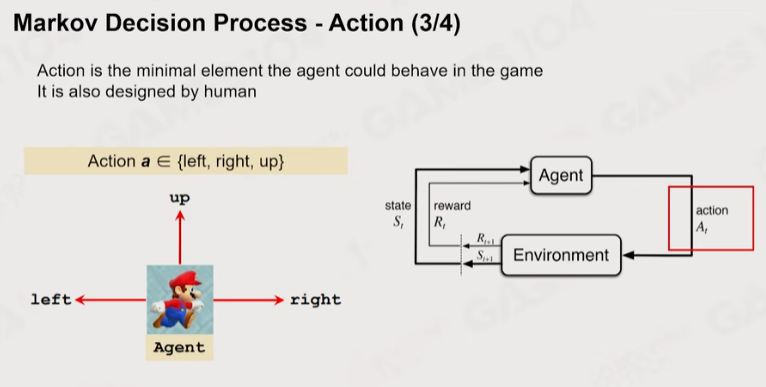
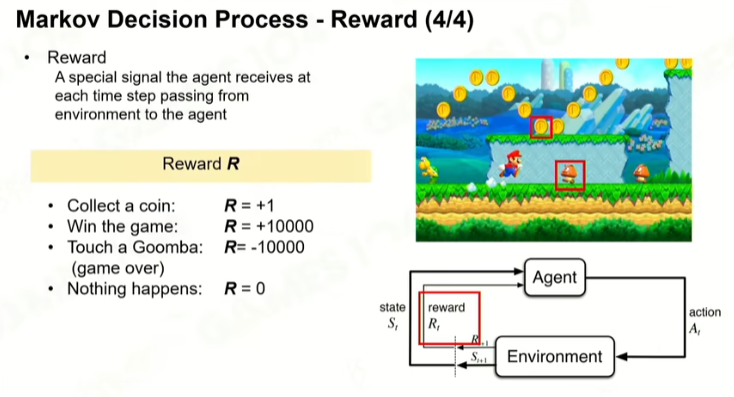
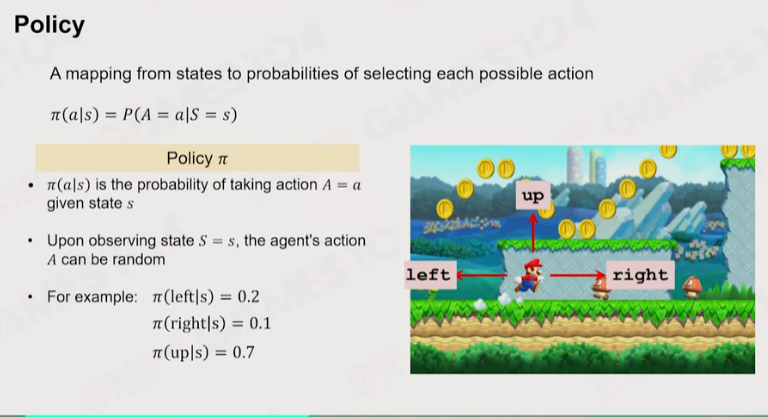
Policy:黑箱,
2 machine learning in game AI

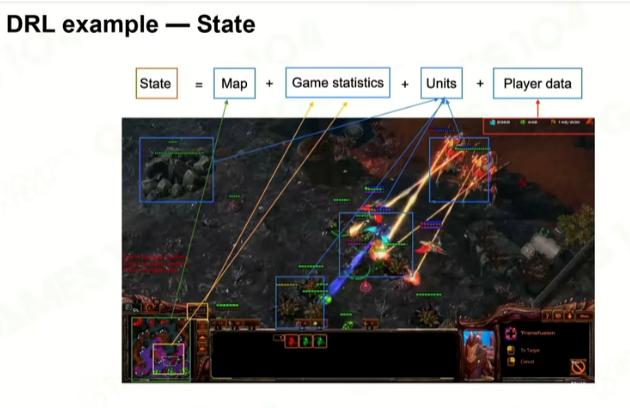
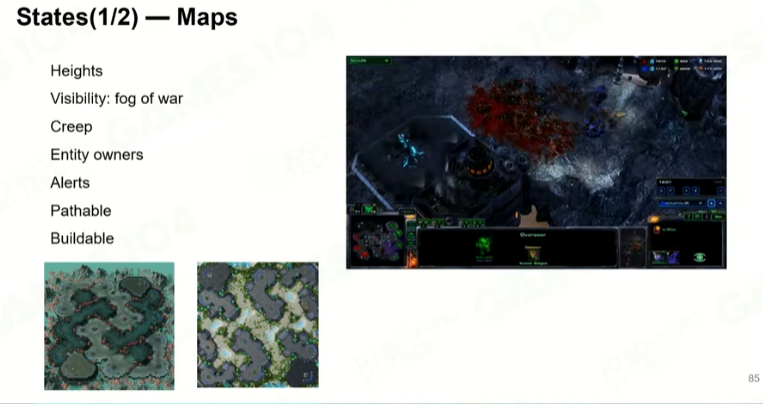
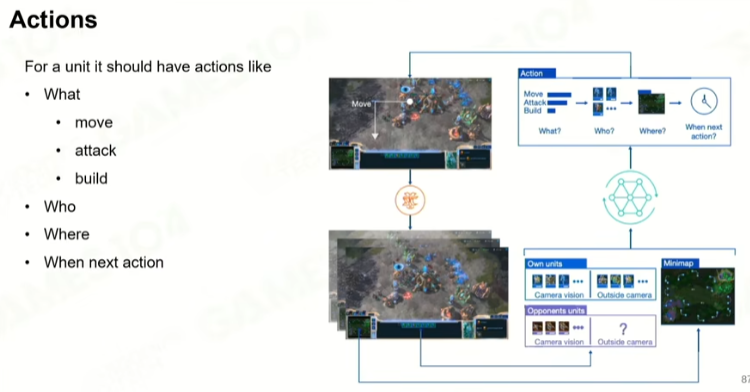
游戏的状态

时间状态的描述;



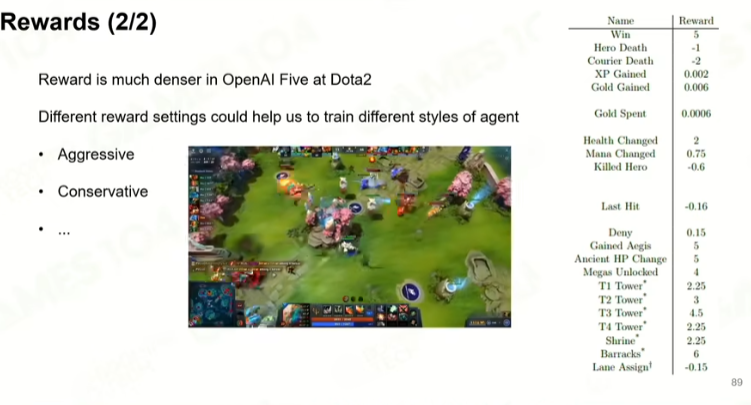
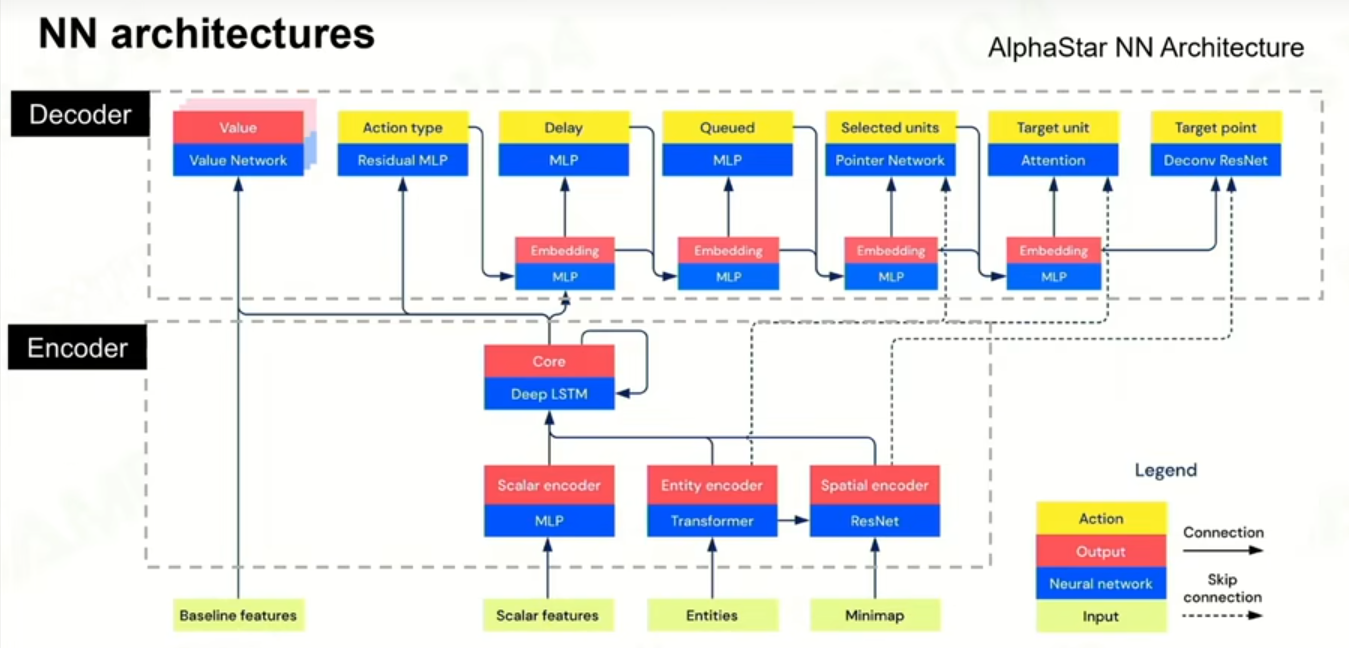

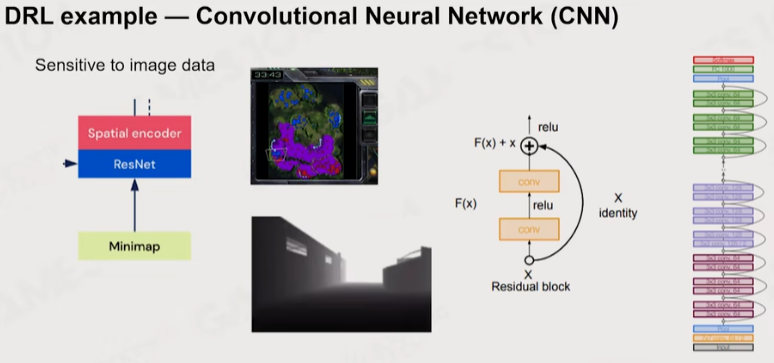
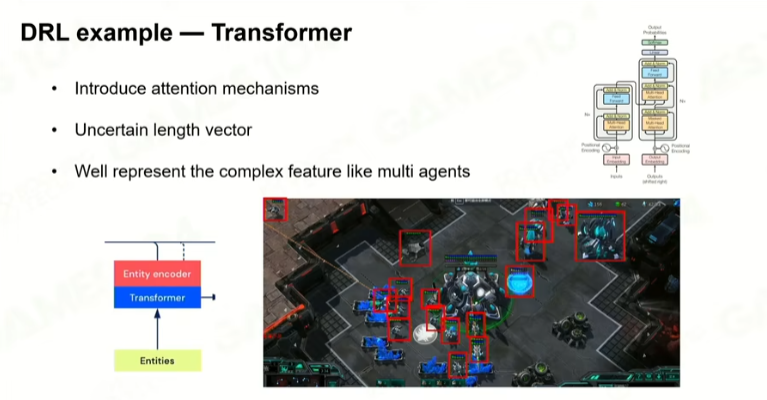
3 训练策略
用监督学习训练相对可以的网络,选择什么样的数据集去训练呢
选择比较优秀的玩家的数据。

然后强化学习:
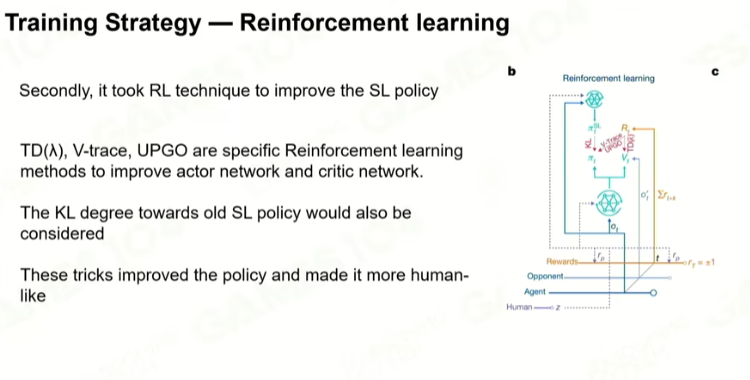
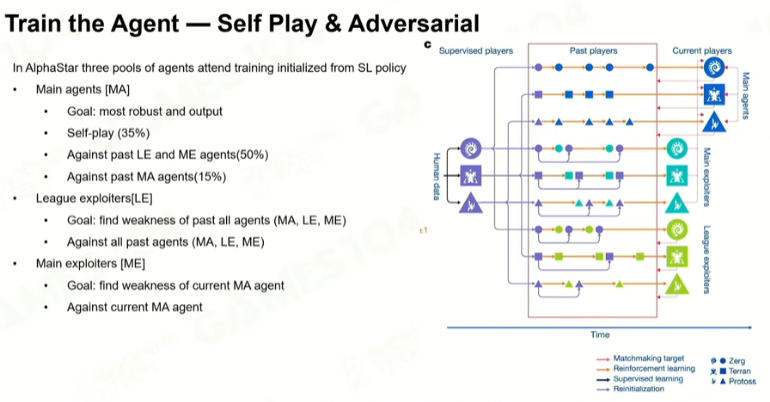
最怕做到局部最优解,而不是全局最优解。
5 问题


目前在cpu上。
6 视频
上:
https://www.bilibili.com/video/BV1iG4y1i78Q/?spm_id_from=333.788
下:
https://www.bilibili.com/video/BV1ja411U7zK/?spm_id_from=333.788&vd_source=5c9c50b5a07b211beafdf65d7cc7f8c8