GordoA, Almazán J, Revaud J, et al. Deep Image Retrieval: Learning GlobalRepresentations for Image Search[C]// European Conference on Computer Vision. Springer,Cham, 2016:241-257
1.文献作者提出的问题及解决方案
1)图像检索的难点在于图像表达需要被压缩然而还要保留图像中的大部分细节文献提出的框架允许不同大小和纵横比的图像都可以精确的表达同时解决CNN网络缺少几何不变的特性。
2)深度学习的图像检索性能落后于传统方法的原因是缺少特定实例检索任务的数据集,基于深度学习的图像检索一般是使用Imagenet预训练的网络提取特征,这些特征在类间是有不同的语义,但是在类内的变化却是鲁棒的。
解决方案
1) 作者建立了一个检索的深度表达方式R-MAC(regional maximum activation ofconvolution),把多个图像区域聚集压缩成一个固定长度的紧凑型特征矢量,因此对于平移和缩放是有效的,这种表示可以处理不同长宽比的高分辨率图像,并获得相当好的准确性。我们注意到,构建R-MAC表示所涉及的所有步骤都是可区分的,因此可以以端到端的方式学习权重。
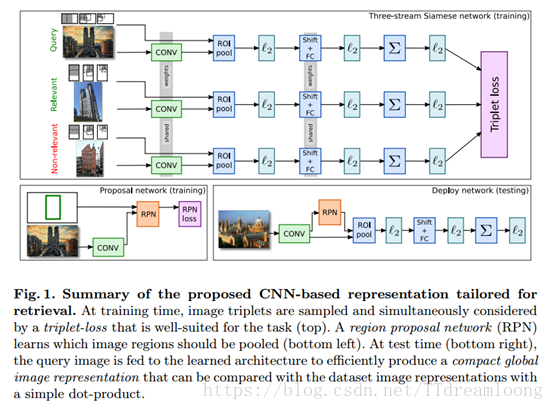
2) 作者第一个贡献是使用三流连体网络,通过使用三重排序损失优化图像检索任务的R-MAC表示的权重,如图1.
3)为了训练这个网络,利用公共的地标数据集。这个数据集通过查询具有不同地标名称的图像搜索引擎来构建,里面有大量错误标记图像。这不利于网络学习一个很好的表达。提出了一个自动清理过程,在清理的数据学习性能显著提高。
4)第二个贡献在于学习R-MAC描述符的池化机制。在[1]的原始结构中,固定网格决定了池化在一起的区域的位置。这里我们提出预测给定图像内容区域的位置。我们用边界框训练一个RPN网络对清洗处理的地标图片进行评估。性能显示得到显著的提升。
两个贡献的结合产生了一种新颖的架构,能够将一个图像编码成紧凑的固定长度的矢量。然后使用点积来比较不同图像的表示。我们的方法明显优于先前基于全局描述符的方法。测试时甚至比关键点匹配和空间验证的复杂方法更胜一筹。
2.目前基于CNN工作的介绍
基于CNN的相关工作
提出了一些改进来克服它们缺乏对缩放,裁剪和图像聚类的鲁棒性。 [4]进行区域交叉匹配,并累计每个查询区域的最大相似度。 [2]应用sum-Pooling对区域描述符进行白化。 [3]运用跨维加权和神经编码的聚合改进[2]。[1]提出了R-MAC,一种通过在固定布局的空间区域中聚合CNN的激活特征来产生全局图像表示的方法。产生的结果是一个固定长度的向量表示,当与重新排序和查询扩展相结合时,实现了接近现有技术的结果。我们的工作是通过区分学习代表参数和改进区域共享机制来扩展这个架构
1)在本文中,我们确认微调用于检索任务的预训练模型确实是至关重要的,但是认为如[5]中应该使用良好的图像表示(R-MAC)和排名损失而不是分类损失。
2)Siamese网络通常用于度量学习,降维,学习图像描述符和执行人脸识别。近来,三重网络(即三个流连体网络)已经被考虑用于度量学习和人脸识别。然而,这些连体网络通常依赖于比我们在这里使用的更简单的网络体系结构,这里涉及到几个区域的汇集和聚合。
3.文章的算法
3.1学习检索特定的目标
修改R-MAC。[1]提出R-MAC,一种适合图像检索的特定的全局图像表达,提取特征过程如图1.
(例如VGG16)被用来从图像中提取不依赖于图像大小或其纵横比的局部特征。使用具有重叠单元的多尺度固定网格,在图像的不同区域中局部特征被max-pooled。这些池化区域特征被独立的l2-normalized,PCA白化然后再一次l2-normalized,与空间金字塔不同的是,并不是串联连接区域描述符,而是将它们sum-aggregated和l2-normalized生成一个大小独立于图像中的区域数量的压缩向量。用点积比较两张图片的矢量可以解释为一个多对多的区域匹配。尤其是,不同区域的空间汇聚相当于感兴趣区域(ROI),这是可区分的。PCA投影可以通过移位和全连接(FC)层来实现,而不同区域的sum-aggregated的梯度和“l2-normalized”也可以容易地计算。因此,可以实现一个网络架构,给定一个图像和其区域的预先计算的坐标(仅取决于图像大小),在单个正向通道中生成最终的R-MAC表示。更重要的是,可以通过网络架构反向传播来学习卷积和投影的最佳权重。
学习特定实例。我们不同于以前的微调网络使用交叉熵损失优化分类进行图像检索。相反,我们考虑基于图像三联体的排名损失。
给出一个查询图像,一个与查询图像相关的图像,一个不相关的图像,使用权重共享的三联体Siamese网络,fig1. 请注意,网络中权重的数量和大小(卷积滤波器,移位和投影)与图像大小无关,因此我们可以为每个流提供不同大小和宽高比的图像。
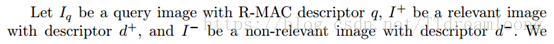
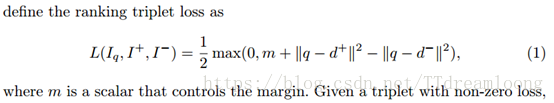
给出一个非零损失的triplet,梯度通过三流体网络进行反向传播,卷积层和PCA层 shifting层和全连接层都会更新。
这种方法有几个优点。首先,直接优化目标物体的排名,第二,我们可以使用和测试时同样分辨率的图片训练网路。最后,学习最优PCA可以被视为一种方法进行区别的优势度量学习学习一个相关图像更接近的新空间。
3.2 ROI池化
使用R-MAC固定的网格池化固定区域是为了确保感兴趣的目标至少被一块儿区域所覆盖。然而这种统一化的采样导致两个问题。第一,随着固定网格与图像内容相互独立,,固定的网格不能和感兴趣的目标对齐。第二,很多区域只有被背景覆盖。我们通过在全连接层网络之上建立一个R-MAC卷积层处理这个过程。解决的问题。第一,建议区域比固定的网格更能紧密的覆盖感兴趣的区域。第二,即使不能精确的与感兴趣区域重叠,更多的建议区域会与感兴趣区域重叠,每张图增加的感兴趣区域的数量不仅帮助他增加覆盖,也实现了多对多的匹配。
RPN背后的主要思想是针对一组具有各种大小和方面比率的候选框以及在所有可能的图像位置处预测描述每个框包含感兴趣对象的可能性的分数。同时,对于每个候选框,它执行回归以改善其位置。这是通过一个完全卷积网络实现的,该网络包括使用3×3滤波器的第一层和具有1×1滤波器的两个同胞卷积层,其针对图像中的每个候选框预测目标性分数和回归位置。然后对排序的框执行非最大抑制,以产生用于替换刚性网格的每个图像的k个最终提议。
为了训练RPN,我们根据盒子与感兴趣的地面实况区域的重叠程度,为每个候选盒子分配一个二进制类别标签,并且将具有多任务损失的目标函数最小化,所述多任务损失结合了分类损失和回归损失。然后通过反向传播和随机梯度下降(SGD)进行优化。
我们注意到,原则上可以同时学习RPN和图像的排序。但是,初步实验表明,正确加权两个损失是困难的,并导致不稳定的结果。在我们的实验中,我们首先学习使用固定网格的R-MAC表示,然后我们固定卷积层并学习RPN,它取代了固定网格。
3.3建立一个全局描述符
在测试时间,人们可以很容易地使用这个网络来表示一个高分辨率的图像。一个将图像馈送到网络,产生区域提议,在区域内汇集特征,将它们嵌入到更具判别性的空间中,聚合它们,并将它们归一化。所有这些操作都发生在一个正向传递中(见图1的右下部分)。这个过程也非常有效:我们可以使用一个Nvidia K40 GPU,每秒钟对大约5个高分辨率(即最大侧的724个像素)图像进行编码
4利用大规模噪声数据
为了训练我们的网络实例级图像检索,我们利用了一个大规模的图像数据集,地形数据集,其中包含约672个着名地标站点的约214K图像。其图像是通过图像搜索引擎中的文本查询收集的,没有经过彻底的验证。因此,它们包括各种各样的概况:网站的一般视图,像雕像或绘画的细节特写,所有中间情况,以及网站地图图片,艺术图画,甚至完全不相关的图像,见图2。

由于网址损坏,我们只能下载所有图片的子集。经过人工检查,由于部分重叠,我们合并了一些类。我们还删除了图片太少的课程。最后,我们仔细地删除了与牛津5k,巴黎6k和假期数据集重叠的所有课程,我们试验了这些数据集,参见第5节。我们获得了一组约192,000个图像,分成586个地标。我们把这个集合称为地标完整。对于我们的实验,我们使用168,882图像进行实际的微调,剩下的20,668个图像用于验证参数
清理地标数据集。正如我们所提到的,地标数据集呈现出很大的类内变异性,具有各种各样的视图和剖面,以及不可忽略的大量不相关的图像(图2)。虽然这不是针对分类的目标(网络可以适应这种多样性的训练,甚至是噪声),但是为了实例级别的匹配,我们需要用相同特定对象或场景的图像来训练网络。在这种情况下,可变性来自不同的观看比例,角度,照明条件和图像混乱。我们预处理的地标数据集,以达到这一点如下。
我们首先在每个地标类的图像中运行一个强大的图像匹配基线。我们比较每对图像使用不变的关键点匹配和空间验证。我们使用SIFT和Hessian-Affine关键点检测器并使用第一到第二相邻比率规则匹配关键点。这被称为优于基于描述符量化的方法。之后,我们用仿射变换模型验证所有匹配。这个繁重的程序是经济实惠的,因为它只在训练时间离线执行一次。
在不失一般性的情况下,我们描述了一个地标级别的清洁程序的其余部分。一旦我们获得了所有图像对之间的一组成对得分,我们构造了一个图,其节点是图像,边是成对匹配。我们修剪所有低分的边缘。然后我们提取图形的连接组件。它们对应于地标的不同轮廓; 见图2,显示了圣保罗大教堂的两个最大的连接组件。为了避免混淆,我们只保留最大的连接组件,丢弃其余的组件。这个清洁过程留下仍然属于586个地标之一的约49,000张图像(分成42,410次培训和6382张确认图像),称为Clean-Landmarks。
边界框估计。我们的第二个贡献(3.2节)是用学习的ROI选择器替换R-MAC描述符中区域的均匀采样。这个选择器是使用边界框注解来训练的,我们自动估计所有的地标图像。为了达到这个目标,我们利用清洁步骤中获得的数据。验证的关键点匹配的位置是有意义的提示,因为感兴趣的对象在地标的图片上始终可见,而分散注意力背景或前景对象是变化的,因此是不匹配的
我们把所有的地标图像的相联系的元素作为一个集合表示为图 。每对相互联系的图像 ,我们有一组用对应的仿射变换验证的匹配关键点 ,首先在图像i和j上定义一个初始边界框,由 和 表示作为包含所有匹配关键点的最小矩形。请注意,单个图像可能涉及许多不同的对。在这种情况下,初始边界框是所有框的几何中值。然后我们执行扩散过程,如图3所示。我们用 和仿射变换 预测 的值,在每次迭代过程中,边界框随着 更新, 代表更新步长(实验中设为0.1). 再次,单个图像的多个更新使用几何中值进行合并,这对于估计不良的仿射变换是鲁棒的。这个过程迭代直到收敛。从图3中可以看出,边界框的位置以及它们在图像之间的一致性得到改善。

5 实验结果
5.1 数据集和实验细节
数据集:我们在五个标准数据集上验证我们的结果,我们的实验主要是Oxford 5k建筑数据集和Pairs 6k数据集,分别包括5062和6412张图片。
每个数据集有55张查询图片,并且用感兴趣区域标注。为了在大规模场景中验证实例水平的检索,我们也考虑到了用100k distractor数据集扩展Oxford 5k 和Pairs 6k 到Oxford 105k和Pairs 106k的数据集,INRIA Holidays 数据集由1491张图片和500张不同的查询场景组成。
评价。对于所有数据集,我们使用标准的评估方案和报告平均精度(mAP)。按照惯例,在牛津和巴黎,只使用注释区域进行查询,而假期使用整个查询图像。此外,在假期验证时,查询图像将从数据集中删除,但不在牛津或巴黎。
实验细节。我们的实验运用Imagenet ILSVRC预训练VGG16作为初始值。除非明确指出,否则所有进一步学习均在地标数据集上执行。为了使用分类进行微调,我们遵循标准实践并将图像调整为多个比例([256 - 512]范围内的最短边),并提取随机裁剪的224×224像素。
这个微调过程在一个Nvidia K40 GPU上花费了大约5天的时间。在进行排名损失的微调时,以高效率的方式挖掘硬三元组是非常重要的,因为随机三元组大部分会产生简单的三元组或没有损失的三元组。作为一个简单而有效的方法,我们首先对大约一万张图像执行正向传递,以获得它们的表达。然后,我们计算所有涉及这些特征(margin m = 0.1)的三元组的损失,一旦已经计算出了这些表示,它们就是快速的。我们最后对三联体网络用大loss值进行了抽样,这可能被看作是一个很大的负面因素。使用带momentum的SGD训练网络,lr = 10-3和weight decay =5*10-5. 此外,由于图像很大,我们不能一次在内存中输入一个以上的三元组。为了执行批量SGD,我们累积了反向通道的梯度,并且每n次只更新权重,在我们的实验中n = 64。为了提高效率,我们每16个网络更新就只挖掘一个新hard triplets。在这个过程之后,我们可以在一台K40 GPU上每天处理大约650个批次的64个三元组。我们共处理了大约2000个批次,即3天的培训。为了学习RPN,我们对网络进行200k次迭代训练,权重衰减为5·10-5,学习率为10-3,迭代10万次后减少10倍。这一过程不到24小时。
5.2微调表示的影响
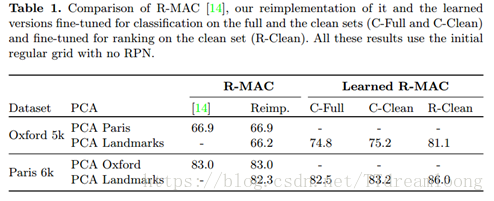
在本节中,我们报告了基线的检索实验以及基于排名损失的方法。所有的结果总结在表1中。首先,从第一和第二列可以看出,R-MAC的重新实现的准确度与原始文件的一致。我们还想强调以下几点:
PCA学习。 R-MAC根据目标数据集在不同的数据集上学习PCA. (即在牛津进行评估时在巴黎学习,反之亦然)。这样做的缺点是需要根据目标数据集生成不同的模型。相反,我们使用地标数据集来学习PCA。这导致性能略有下降,但是允许我们有一个可以用于所有数据集的通用模型。
微调分类。其中在ImageNet上预先训练的原始网络在分类任务上的地标数据集上被微调。我们使用完整版本和清洗版本的地标(表中由C-Full和C-Clean表示)来微调网络。这个微调已经对原始结果带来了很大的改进。另外值得注意的是,在这种情况下,清理数据集看起来只比使用完整的数据集带来一些改进。
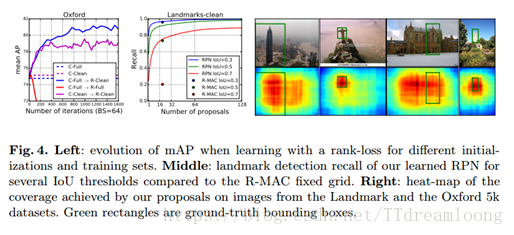
微调检索。我们使用的建议排名损失结果在最后一列,标注R-Clean。我们观察了如何使用较少原则的分类微调来带来一致的改进。与后者相反,我们发现使用清洗数据集训练我们的Siamese网络至关重要,因为基于三元组的训练过程不太容忍异常值。图4(左)通过绘制在不同设置的几个训练时期在牛津5k上获得的mAP来说明这些发现。它还显示了初始化网络的重要性,该模型首先被精细调整用于完整地标数据集的分类。即使C-Full和C-Clean获得非常相似的分数,我们推测用完整Landmark数据集训练的模型已经看到更多不同的图像,因此它的权重是一个更好的起点。
图片大小。 R-MAC认为使用高分辨率图像很重要(最长的一边调整为1024像素)。在我们的例子中,微调之后,我们发现在1024和724像素之间的精确度没有明显的差别。所有进一步的实验将图像调整到724像素,显着加快了图像编码和训练。

5.3建议网络的评估
评估提议。我们首先评估我们建议网络预测的区域的相关性。Fig4(中)说明在Landmarks-Clean验证集上的不同IoU随建议数量的改变的检测recall,并和固定网格的R-MAC获得的detection recall 进行对比。即使这些建议的数量很少,这些建议的的recall也比固定网格的高。
这与定量结果(表2)是一致的,其中32-64个提案已经超过了刚性区域。图4(右)将建议位置作为地标和牛津5k的一些样本图像上的热图可视化。这清楚地表明,这些建议是围绕着关注的对象而展开的。对于牛津5k图像,查询框有些任意定义。在这种情况下,正如预期的那样,我们的建议自然而然地与整个地标以查询不可知的方式一致。
检索结果。我们现在从检索性能的角度来评估这些建议,见表2.使用建议网络改进了固定网络的性能,即使是只对基本模型进行了微调(即没有排名损失)。在Oxford 5k上,排名损失和建议网络带来的改进是相辅相成的,精度从C-Full和固定网格模型的74:8mAP到达了使用排名损失和每张图片256个建议网络的83:1mAP。
6.梳理训练过程
1)基于pre-trainedmodel on Imagenet,可以采用AlexNet,VGGNet,Resnet等,取决与你想要的效果(performance和speed)对于VGGNet(如VGG16),摘掉全连接层,取而代之的是RPN+ RoI Pooling +shift + fc + L2等。
2)从Landmarks dataset,中挖掘出一个full-landmarks clean-landmarks的数据集(包括有类别标签的Full Datset和bounding box Clean Dataset)
3)先用rigid grid的方式产生region,用于fine-tune训练Siamese的triplet loss或classification,对应的数据集为CleanDataset和FullDataset。
4)然后用Clean Dataset来训练RPN
5)最后测试的时候,用RPN产生的proposals替代rigid grid。
训练过程是对文献的理解总结,但仍存在疑问,对Siamese networks的训练过程中如何共享权重不能理解,查阅Siamese networks提出的文献,具体实现要理解源码。另外需要阅读本篇论文的Extend version理解文章,Gordo A, Almazán J,Revaud J, et al. End-to-End Learning of Deep Visual Representations for ImageRetrieval[J]. International Journal of Computer Vision, 2017:1-18.
参考文献
[1]Tolias, G.,Sicre, R., J´egou, H.: Particular object retrieval with integral maxpooling ofcnn activations. In: ICLR. (2016)
[2] Babenko, A.,Lempitsky, V.S.: Aggregating deep convolutional features for image retrieval.In: ICCV. (2015)
[3]Kalantidis, Y.,Mellina, C., Osindero, S.: Cross-dimensional weighting for aggregated deepconvolutional features. In: arXiv preprint arXiv:1512.04065. (2015)
[4]Razavian, A.S.,Azizpour, H., Sullivan, J., Carlsson, S.: CNN features off-the-shelf: anastounding baseline for recognition. In: CVPR Deep Vision Workshop. (2014)
[5]Babenko, A.,Slesarev, A., Chigorin, A., Lempitsky, V.S.: Neural codes for image retrieval.In: ECCV. (2014)
寒假计划
1) 精读文献Gordo A, Almazán J, Revaud J, et al.End-to-End Learning of Deep Visual Representations for Image Retrieval[J].International Journal of Computer Vision, 2017:1-18.
2) 数据集的制作
3) 文献中的训练过程过于复杂,思考解决方法,查阅相关的文献
4) 阅读文献Zagoruyko S, Komodakis N. Learning to compareimage patches via convolutional neural networks[C]// Computer Vision andPattern Recognition. IEEE, 2015:4353-4361.
新整理思路:
MAC 最大卷积激活值:每个通道feature map各自max-pooling 取得的最大的值
R-MAC 选取特定的窗口 L=1 L=2 L=3 对于每一个窗口的feature map 论文中采用的是MAX pooling的方式,在L=3时,也就是采用图中所示的三种窗口大小,我们可以得到20个local特征,此外,我们对整个faturemap做一次MAXpooling会得到一个global特征,这样对于一幅图像,我们可以得到21个local特征(如果把得到的global特征也视为local的话),这21个local特征直接相加求和,即得到最终全局的global特征。
上面说到的20个local特征和1个global特征,采用的是直接合并相加的方式,当然我们还可以把这20个local特征相加后再跟剩下的那一个global特征串接起来。实际实验的时候,发现串接起来的方式比前一种方式有2%-3%的提升。在规模100万的图库上测试,RMAC pooling能够取得不错的效果,跟Crowpooling相比,两者差别不大。