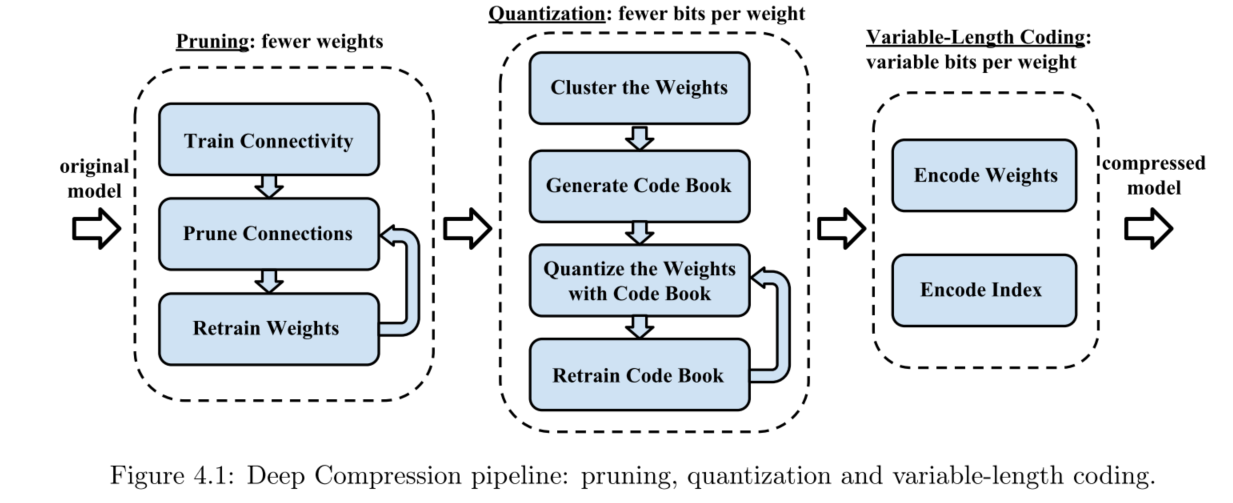
Trained Quantization and Deep Compression
本章内容来在ICLR 2016论文《Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding》。
DeepCompression由剪枝、量化和变长编码组成,它可将神经网络在无损精度情况下压缩一个数量级。DeCp是一种3段管道方法。
- Prune,移除冗余的连接。
- 量化,多个连接共用权重,缩小了参数空间,每个参数可用更小的位数表示。
- Huffman coding,用霍夫曼编码对分布不均匀的量化的权重进行编码(边长编码可无损的使用最小空间保存参数)。
一个重要的发现是剪枝与量化是互不干扰的,所以可以联合实现更高的压缩率。
Trained Quantization and Weight Sharing
量化和权重共享实际就是一种粗粒度编码方式以减少权重需要的存储位数(极端情况下可以达到二值化编码)。
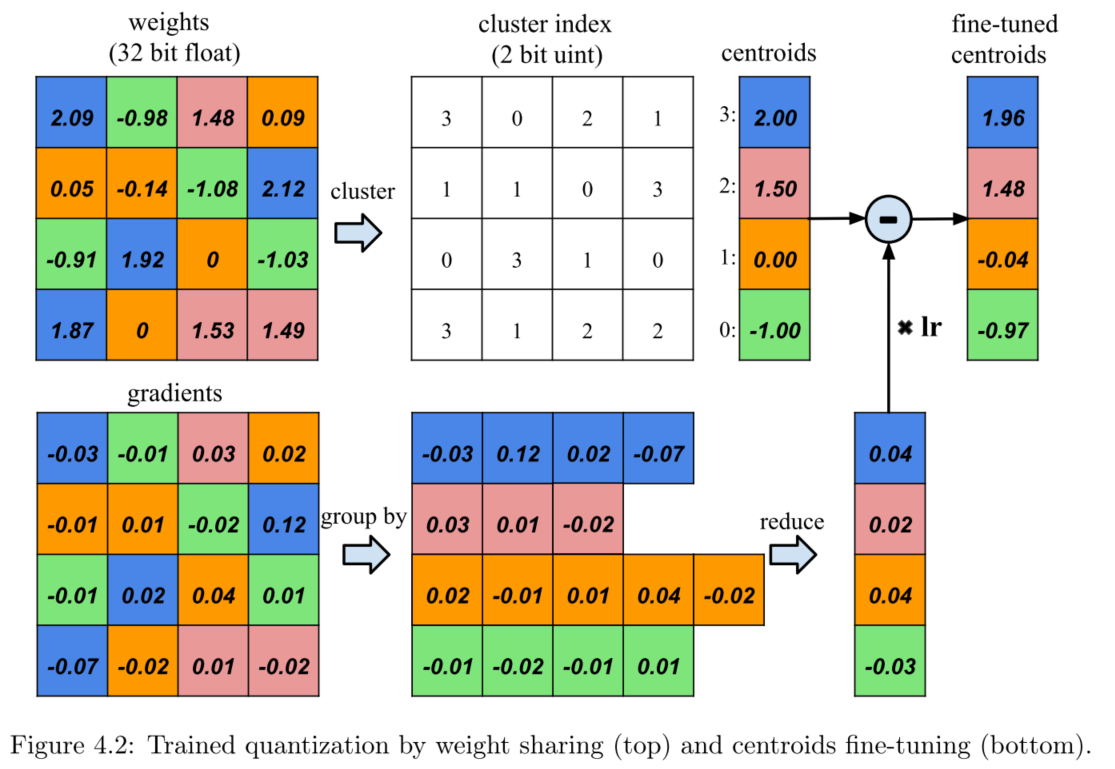
上图是权值共享的过程,参数矩阵进行分组,然后保存其index值即可,每个所以index对应真实的参数值,这个参数值有weight和gradients乘学习率lr更新得到。
权值分组采用k-means 聚类算法。不同layer不会共享权值!相当于每层都有其单独的分组值。不同层的相同索引值对于的不是相同的权值值。
Storing the Meta Data
整个方案会产生两类元数据:
- 剪枝得到的稀疏网络的非零权重的索引
- 量化会为每个layer产生一个codebook
稀疏网络的元数据存储
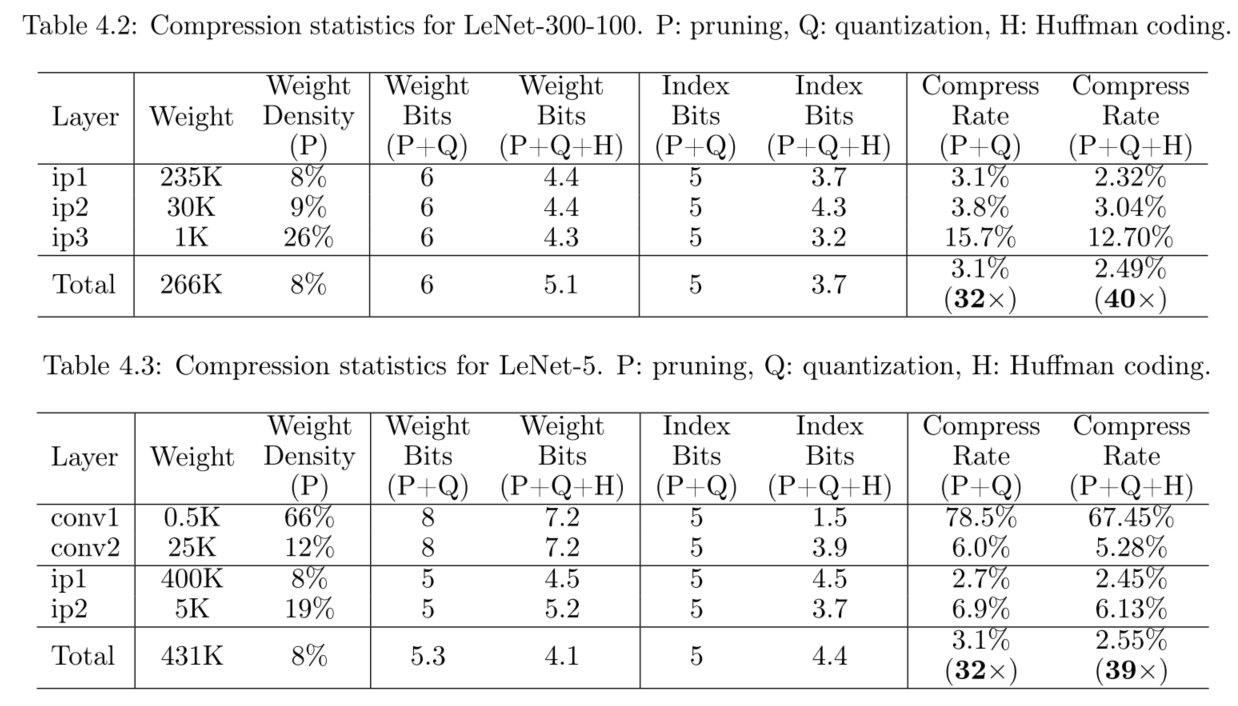
剪枝后的稀疏网络,我们需要存储非零权重值及其位置索引。通过保持相对索引可以最小化需要的数据位数。采用4位就足够使用,最大可以表示16个索引相对位置。考虑稀疏度普遍为10%,即10个坑里有1个非零值,所以采用16的最大相对间隔是合理的上界,若超出16,有两种处理方案。
- 填充零:当相对索引差大于16,则填充一个0。优点是不需要修改其他逻辑。缺点是填充的0造成计算周期的浪费(相当于要计算这个无意义的0)
- 特殊编码解决:保留一个最后的编码作为一个相对索引溢出的标签,用来占位提示溢出,下一个相对位置直接从这个占位处开始计算即可。优点是这种方法不会浪费计算资源。缺点是这种方案下实际可用的最大索引只有15,浪费了一个专用标签码,需要有额外的定制逻辑去处理这个标签码,使得计算更难去并行。
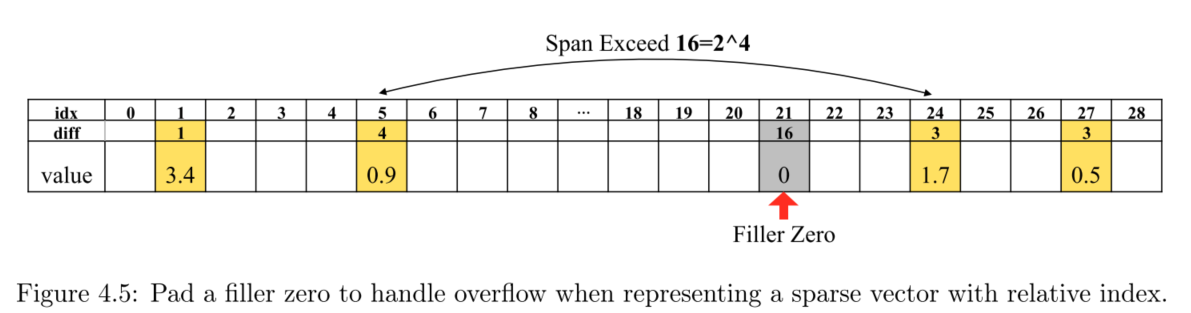

实验发现真正出现溢出的情况很少,所以额外的计算浪费微不足道,所以最终采用方案1,补零法。
量化的码本存储
量化过程,如采用4-bit,即16个【索引-值】对,1到16分别表示16种量化(聚类)之后的参数值。这样1层需要16对,50层的网络需要50x16=800对,每个【索引-值】对4btye,则总共只有3kb。
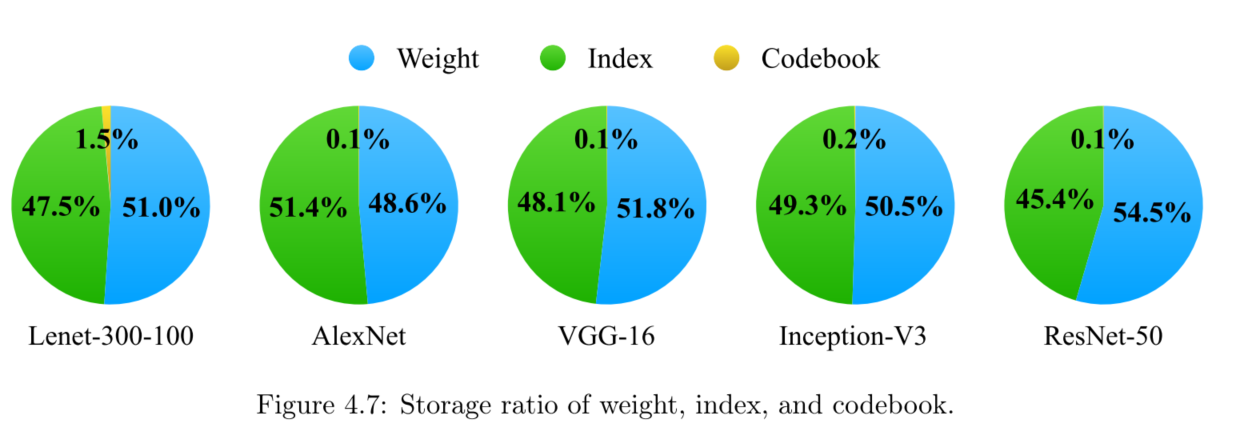
各部分存储情况分解表(breakdown)
Variable-Length Coding
目前为止,经过上面的步骤,网络经过剪枝,然后参数经过量化,目前用固定位的数来表示权重,但是这时候遇到一个问题,由于权重分布问题,应该采用一种更节约空间的变长编码来保存数据。如下参数分布:
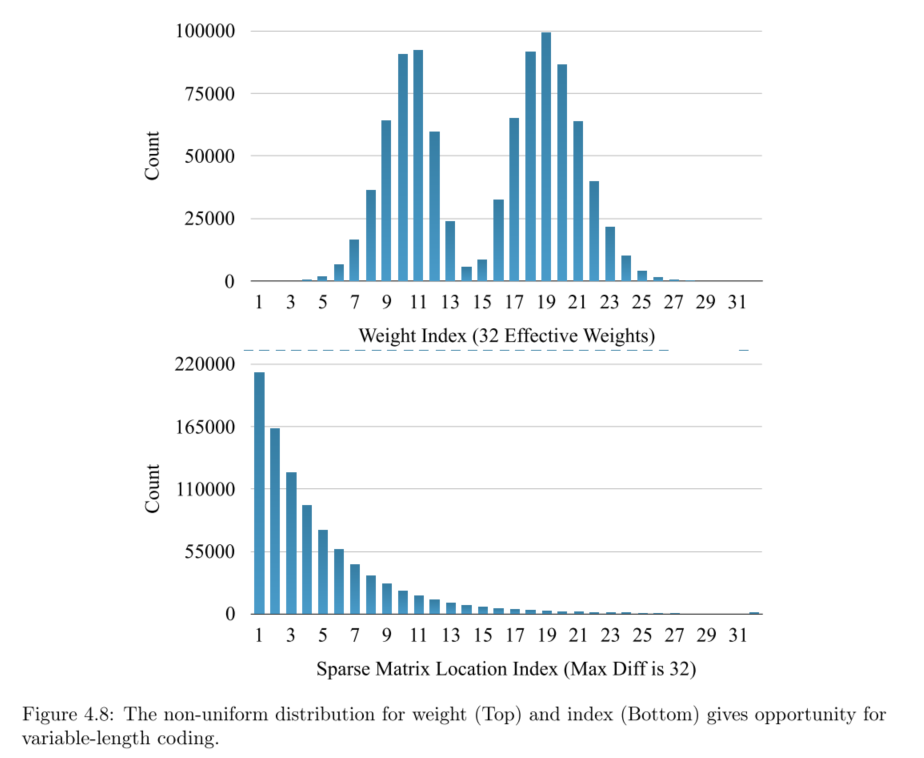
采用最优前缀编码算法(这里采用霍夫曼编码,Huffman)对量化的权重和稀疏的索引矩阵进行编码,可以节省20%-50%的模型存储容量。
Experiments
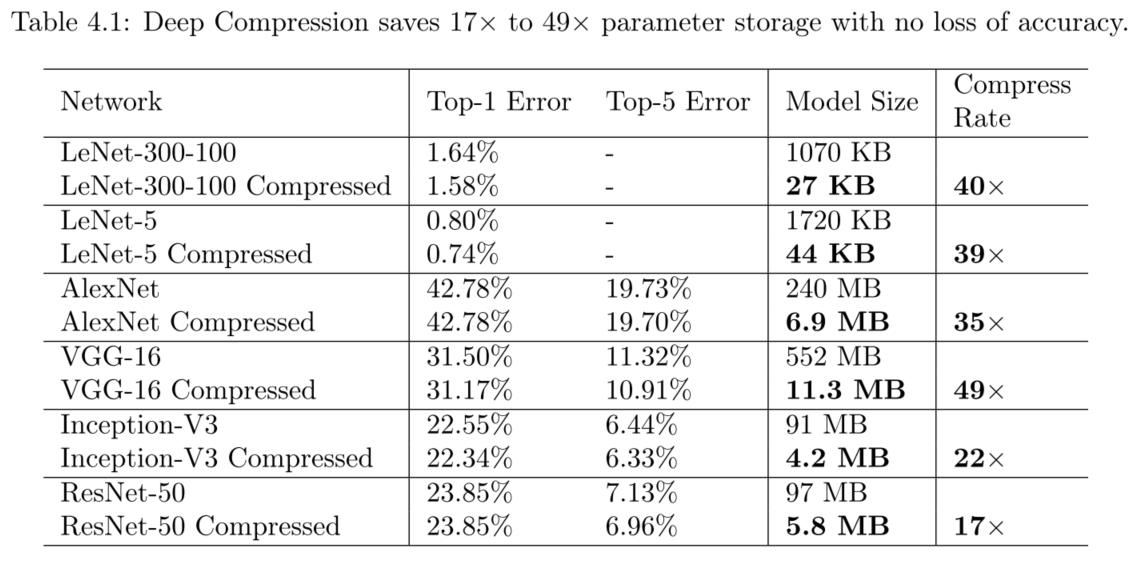
在LeNet-300-100,LeNet-5,AlexNet,VGG-16,Inception-V3 和 ResNet-50上进行了剪枝、量化和霍夫曼编码的实验。在无损准确率的情况下压缩网络17x到49x,ResNet-50网络从100MB压缩到5.8MB,这足够将模型放入片上RAM(on-chip SRAM),消除了对高能耗的DRAM的存储需求。(SRAM相对价格稍高,但能耗少,DRAM需要动态不停刷新)。
实验采用caffe和Pytorch实现。实现如下:
- 量化和权重共享:每层维护一个码书结构存储了共享的权重(经过聚类中心确定权重),然后权重矩阵采用稀疏的索引矩阵表示,每一个共享的权值的更新根据该权值的所有index位置的梯度进行更新。
- 之后模型确定了(fine-tuning完成之后),再进行off-line Huffman编码。
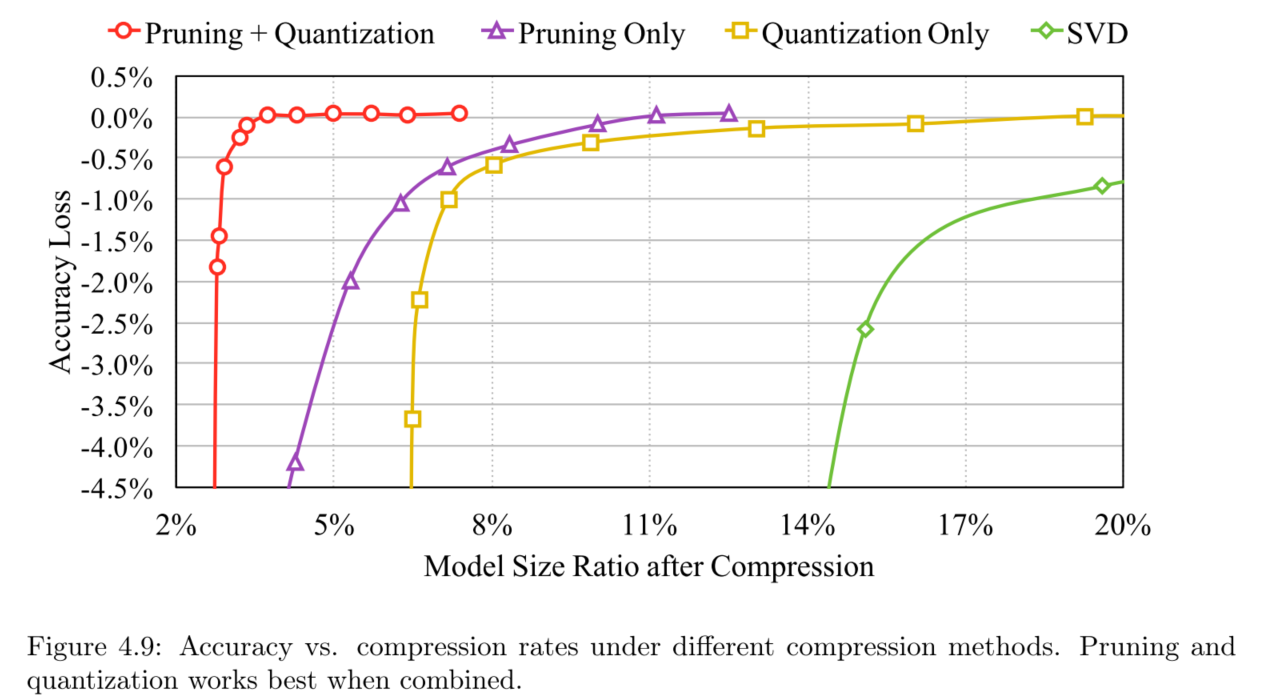
无损情况下的各网络模型的压缩率
-
LeNet(LeNet-300-100、LeNet-5) + MNIST :
-
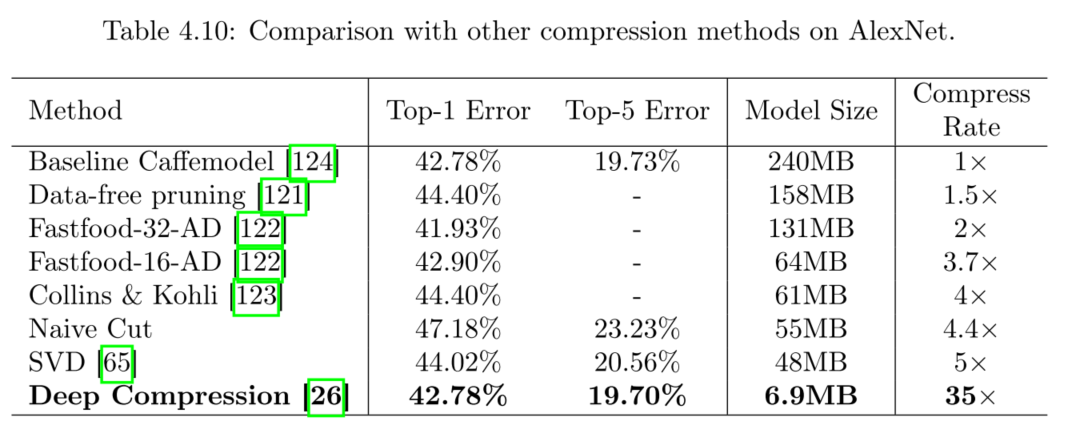
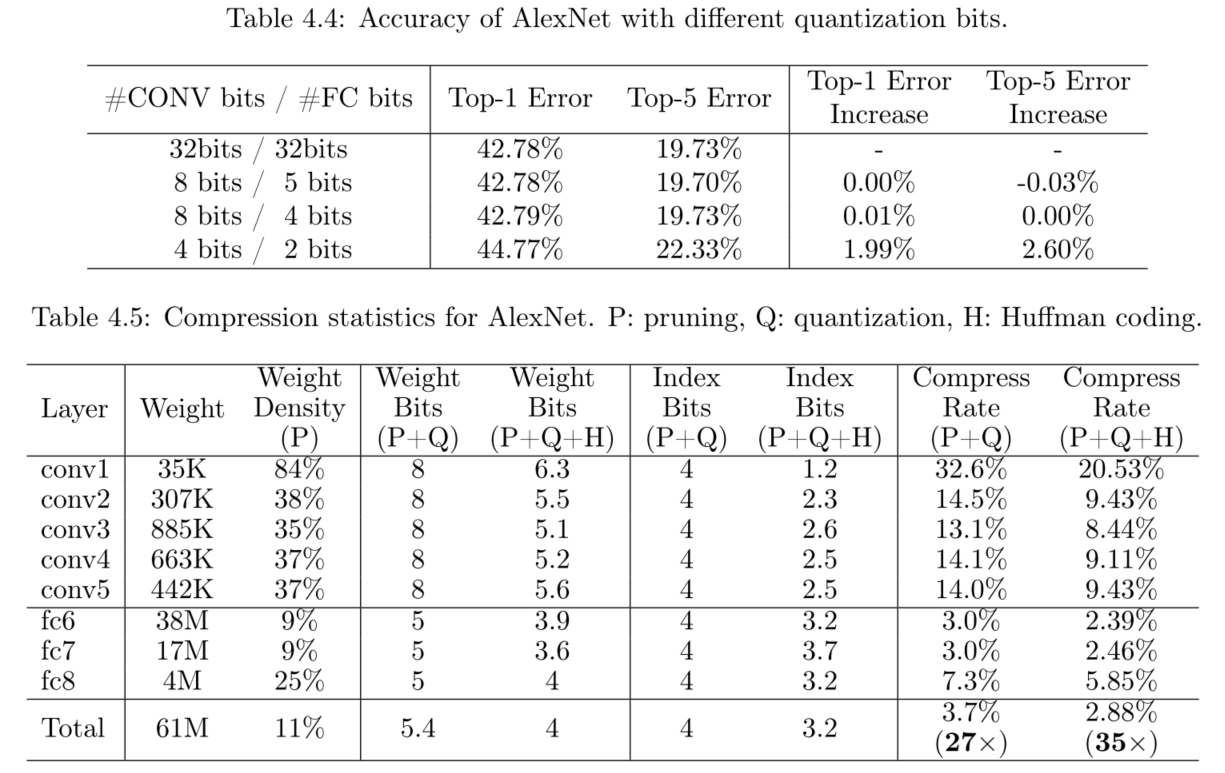
AlexNet + ImageNet ILSVRC-2012:采用Caffe model作为对比。
**实验思路:**首先确定最优的位数,然后再分别实验P+Q和P+Q+H,实验充分!这里有一个平衡取舍的问题,用8bit & 5bit能获得最好的准确率,但是8bit & 4 bit能更好的在硬件上实现,天然位对齐,且压缩率会进一步上升一些。
-
VGG-16 + ILSVRC-2012、 Inception-V3、ResNet-50:略,实验详情见论文。
结论
下图描述不同压缩率下的准确度损失(分别在pruning、quantization或者他们的组合,以及和SVD的对比)
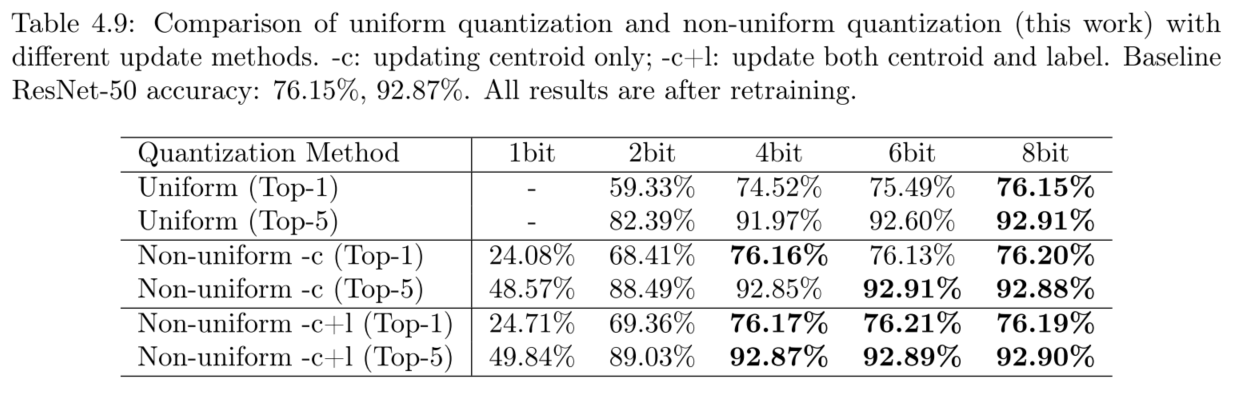
- 剪枝与量化可以分开工作,但组合之后压缩率提升巨大。
- Deep Compression比SVD低秩分解好很多
- 重训练过程非常重要!
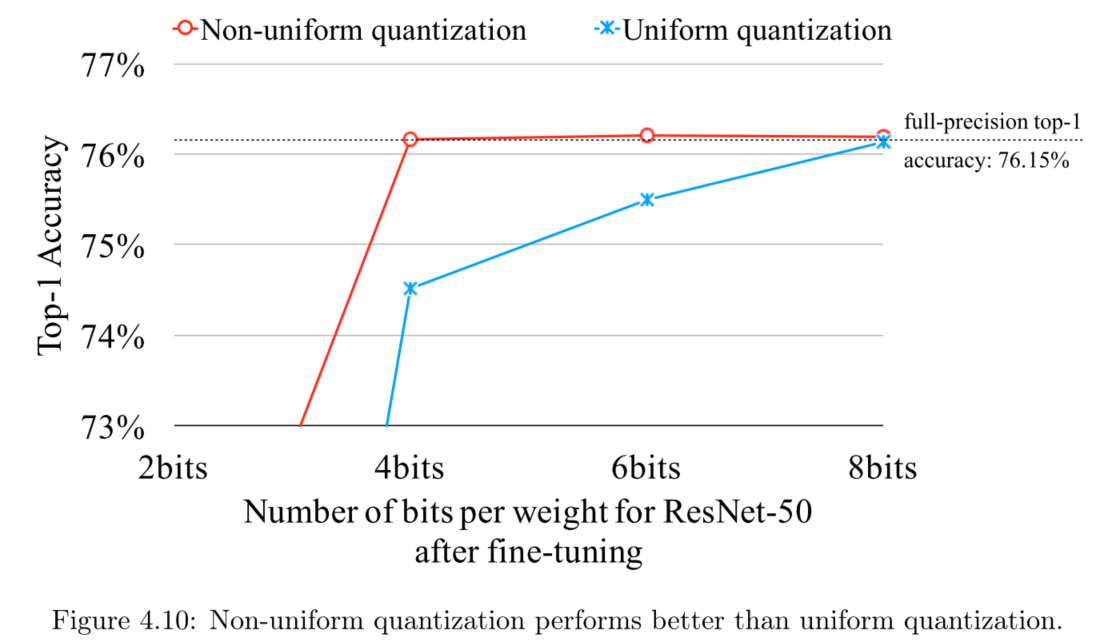
- 表4.9中统一量化和非统一量化指的是 adjacent code 是否可变。(这里没看懂)
与其他压缩方法的对比: