0.核心思想
近朱者赤近墨者黑。具有相同标签的往往会聚集到一起,根据与待预测样本最近的k个邻居来进行预测。
- kNN是有监督学习
- 分类和回归都可以用kNN
1.算法原理
- 从训练集合中获取k个离待预测样本距离最近的样本数据。这个距离是特征属性之间的距离
- 根据1中获取得到的k个样本数据来预测当前待预测样本的目标属性值
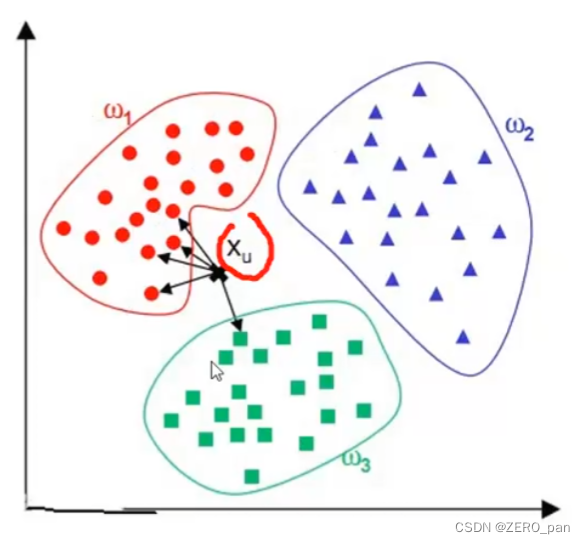
a.特征空间
如下图是两个特征的特征空间,是一个平面。
三个特征数的特征空间是立体的,4个,5个特征的特征空间没办法想象,但是存在,被称为超空间。
b.距离
闵氏距离
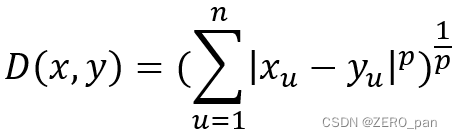
当p=2的时候就是欧氏距离;p=1是曼哈顿距离
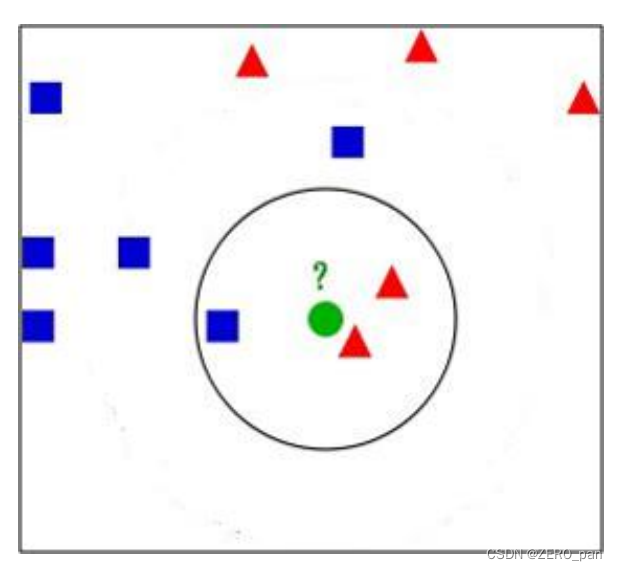
c.k的选择
k是kNN算法中的一个超参数。
看下图
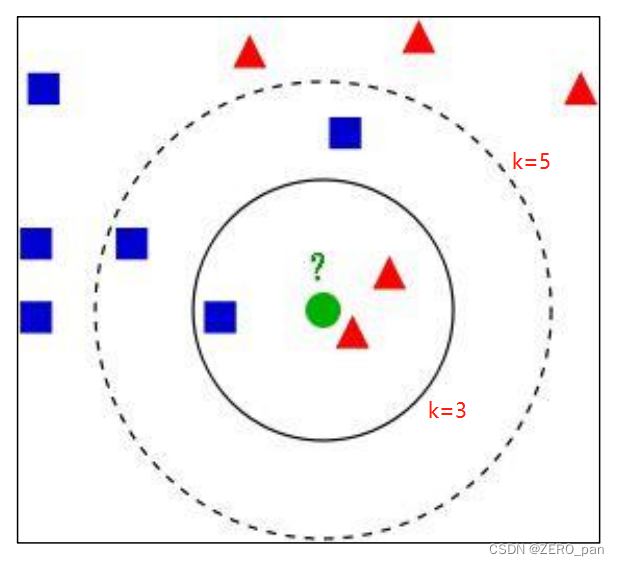
k=3,被预测为红色;k=5被预测为蓝色。
k值影响预测结果,因此我们需要通过实验(交叉验证)来选择一个比较合适的最终值。
k的两种特殊情况
- 当k=1(k小)的时候,能够在训练数据集上获得100的准确率。但是可想而知,过拟合,这也是为什么采用交叉验证的原因。
- 当k=训练样本数(k大),训练数据集上准确率就是样本数据的比例,容易欠拟合。
d.决策规则
- 分类模型中,主要使用多数表决法或者加权多数表决法
- 在回归模型中,主要使用平均值法或者加权平均值法
分类任务:加权多数表决法
每个邻近样本的权重是不一样的,越近权重越大,投票的时候说话分量越大。
一般情况下采用权重和距离成反比的方式来计算。因为每个人都是一票,所以把权重相加,最终预测结果是出现权重最大的那个类别。
比如下图中,假设三个红色点到待预测样本点的距离均为2,权重都是1/2;两个黄色点到待预测样本点距离为1,权重都是1,那么蓝色圆圈的最终类别为黄色(1+1>1/2+1/2+1/2)。
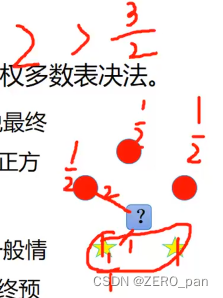
权重归一化
还有一个问题,这五个人的权重之和不是1,而是7/2.最好进行归一化,就是每一个人的投票权再除以7/2.比如,红色样本的投票权就是1/2 除以7/2.
不归一化也可行吧。
回归任务:加权平均值法
每个邻近样本的权重是不一样的,越近权重越大,投票的时候说话分量越大。
一般情况下采用权重和距离成反比的方式来计算。比如下图中,假设三个红色点值是3,到待预测样本点的距离均为2,权重都是1/7(1/2除以7/2);两个黄色点值为2,到待预测样本点距离为1,权重都是2/7(1除以7/2).(添加了归一化)
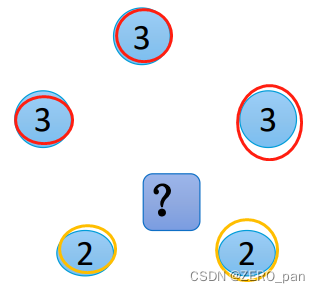
预测结果:
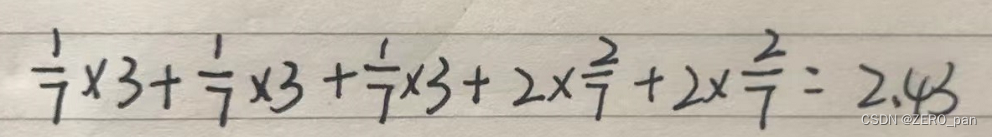
2.sklearn代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier as knn
#00数据加载
X,Y = load_iris(return_X_y=True)
#01数据划分
X_train,X_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=0)
#02训练
knn_clf = knn(n_neighbors=3,weights='uniform',algorithm='kd_tree')
knn_clf.fit(X_train,y_train)
#03测试
print('the score in train data:',knn_clf.score(X_train,y_train))
print('the score in test data:',knn_clf.score(X_test,y_test))