KNN(K-Nearest Neighbor,K近邻)算法作为一种分类算法,它的实现原理比较简单:1.指定K值;2.计算当前点与样本点中的距离,并按从小到大顺序排列;3.在距离最小的前K个点中,统计样本的标签数量,将当前点分类到同类最多的类别里面去(也就是少数服从多数的原则)。
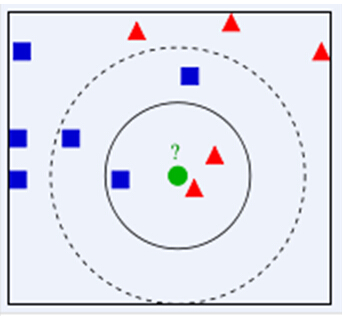
KNN算法简单有效,不需要对训练集进行训练,被称为一种lazy learning(懒惰学习)的算法。但是它的计算复杂度与样本数量n成正比O(n),样本数量越大,计算复杂度越高。
决定KNN算法性能的三个的基本要素是:K 值选择,距离度量,分类决策规则。
一、对于K值得选择:如果K值太小,预测的结果会对近邻的样本点十分敏感,如果附近的点恰好是噪音点,那么预测就会出错。也就是说,K值较小,会使得整体模型非常复杂,容易发生过拟合。“学习”的近似误差会减小,但是估计误差会增大(还不太懂这句话,先放着)。
如果K值较大,则距离当前点很远的样本点也会对分类结果差生影响,如果远处的点较多,则很可能使得分类错误。也就是说,K值较大时,整体模型变得简单,很多有用的信息被忽略了(比如K=N时,就相当于是在找全体样本中数量最多的类别了)。“学习”的近似误差减小了,但是估计误差会增大。
在实际中,K一般取个较小的值,然后通过交叉验证来选择最优的K值。
二、距离的度量主要有曼哈顿距离和欧氏距离。比如在传统的欧式距离中,各个特征的权重相同,对分类的贡献也相同,则是不符合实际的情况的。通过对分类影响较大的特征加权,可以使不重要的特征减小影响。也有的改进方法是通过删除部分不相关的特征属性后,再来计算距离。
三、决策规则上,有的采用权值的方法(和该样本距离小的邻居权值大)来改进算法,如WAkNN (weighted adjusted k nearest neighbor)。
另外,针对KNN算法需要遍历所有的样本,计算速度较慢的问题,可以通过建立高效的索引来提高KNN效率。
还有对KNN的改进方法FKNN等,暂时不了解,待进一步学习后再来更新吧!
总结KNN的优缺点如下:
| KNN | |
| 优点 | 1)简单、有效; 6)特别适合于多分类问题(multi-modal,对象具有多个类别标签),KNN要比SVM表现要好; |
| 缺点 | 1)KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多; 2)类别评分不是规格化的(不像概率评分);(不是太懂规格化的意思??) 3)输出的可解释性不强,例如决策树的可解释性较强; 4)该算法在分类时有个主要的不足是,当样本不平衡时,比如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数而导致分类错误,我们希望数量不影响运行结果,可以采用权值的方法(和该样本距离小的邻居权值大)来改进; 5)计算量较大,目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。 |