K-近邻算法
- 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
通俗来讲,就是距离相近的两个样本,大概率属于同一个类别,这样通过已知的类别可以判断出未知样本的类别。 - 公式
欧氏距离:
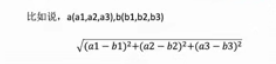
k-近邻算法:需要做标准化处理
k 取值:k取值小,容易受异常点影响
k取值很大,容易k值数量(类别)波动
性能问题:
k的取值非常影响程序的性能,数量越大越慢 - sklearn k-近邻算法API

- 优缺点
优点:简单,易于理解,易于实现,无需估计参数,无需训练
缺点:
- 懒惰算法,对测试样本分类时计算量大,内存开销大
- 必须指定k值,k值选择不当则分类精度不能保证
- 使用场景
小数据场景,几千~几万样本,具体场景具体业务去测试
