机器学习程序开发步骤
1.收集数据
2.准备输入数据
3.分析输入数据
4.训练算法
5.测试算法
6.使用算法
简单地说,k-近邻算法采用测量不同特征值之间的距离方法进行分类
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。 最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
为了实现算法,需要编写函数

示例:使用 k-近邻算法改进约会网站的配对效果

此函数将文本特征转化为数据特征储存如矩阵中
然后用matplotlab绘制散点图


为了使各个数据对计算的影响相同,需要归一化数值

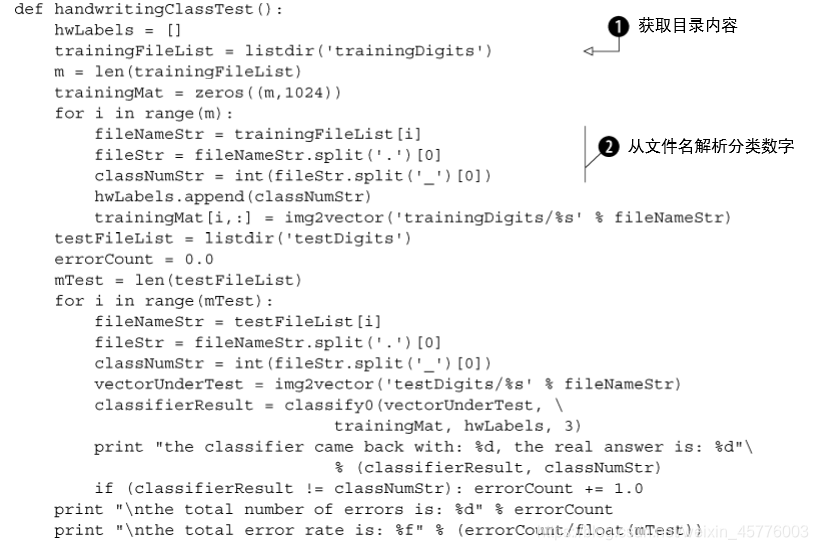
有了以上的函数和工具,可以构建测试程序
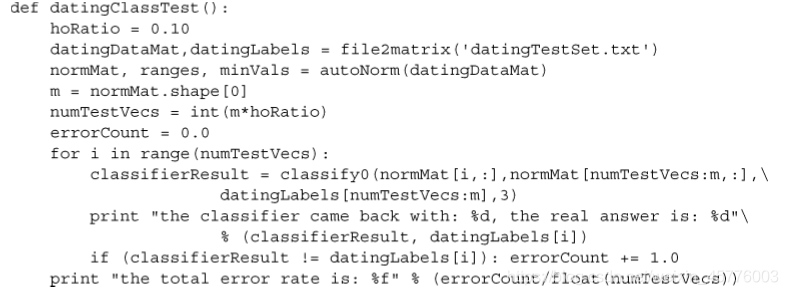
示例:手写识别系统
需要把二进制数储存的图像转化成矩阵

然后就可以将数据输入分类器中进行计算,得出测试程序