MobileNet V1
论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
核心思想:用连续的depthwise卷积和pointwise卷积(separable depthwise convolution)替代标准卷积

假设输出的特征图尺寸为DF×DF:
flops_standard = Dk×Dk×M×N×DF×DF
flops_depthwise = Dk×Dk×1×M×DF×DF
flops_pointwise = 1×1×M×N×DF×DF
注:flops = paras×DF×DF
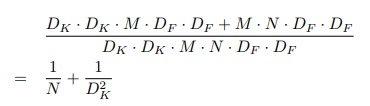
通过深度可分离卷积,计算量将会下降1/N+1/K2
深度可分离卷积层:

MobileNet V1结构:

MobileNet V2
论文:MobileNetV2: Inverted Residuals and Linear Bottlenecks
核心思想:在v1的基础上引入了Inverted Residuals和Linear Bottlenecks
1.Inverted Residuals
- Standard Residuals:标准残差块是将输入经过1×1卷积压缩通道,然后经过3×3卷积进行特征提取,最后经过1×1卷积恢复通道数。整个过程可以视为“压缩-卷积-扩张”。
- Inverted Residuals: 顾名思义,将标准残差块倒过来。首先将输入经过1×1卷积扩张通道,然后经过3×3卷积进行特征提取,最后经过1×1卷积压缩通道数。整个过程可以视为“扩张-卷积-压缩”。
动机:由于残差块中的3×3卷积采用的是depthwise卷积,不能改变通道数,造成特征提取受限于输入的通道数,所以先用1×1卷积扩张通道数。
2.Linear Bottlenecks
有人发现,在使用V1的时候,发现depthwise部分的卷积核容易费掉,即卷积核大部分为零。作者认为这是ReLU引起的,具体解释参考:https://zhuanlan.zhihu.com/p/70703846

从图中可以看到:当n = 2,3时,与Input相比有很大一部分的信息已经丢失了;而当n = 15,30时,有大量信息保存了下来。
可以认为:对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
所以作者将最后一个Relu6替换为Linear。

MobileNet V2网络结构:

MobileNet V3
论文:Searching for MobileNetV3
改进:
-
作者发现网络的最后阶段耗费计算资源比较多,为了提高效率,作者对这部分做了改进。

-
在网络深层使用h-swith(hard version of swith)激活函数减少计算开销
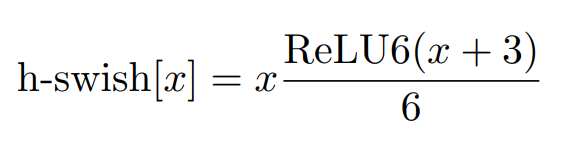
-
在v2的block中引入SE模块

-
NAS
