一、MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 论文链接:https://arxiv.org/abs/1704.04861
- 论文翻译:https://blog.csdn.net/qq_31531635/article/details/80508306
- 论文详解:https://blog.csdn.net/hongbin_xu/article/details/82957426
- 论文代码:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.py
二、MobileNet算法
1、Depthwise Separable Convolution
- Depthwise Separable Convolution实质上是将标准卷积分成了两步:depthwise卷积和pointwise卷积,其输入与输出都是相同的;
- 假设输入特征图维度为: , 为输入的宽/高, 为输入通道数;
- 假设输入特征图维度为: , 为输入的宽/高, 为输出通道数;
- 假设卷积核尺寸为: , 为卷积核的宽/高;
2、标准卷积

- 卷积核参数: ;
- 计算量: ;
3、深度可分离卷积
- 两个组成部分:depthwise卷积和pointwise卷积;
- depthwise卷积:对每个输入通道单独使用一个卷积核处理;
- pointwise卷积:
卷积,用于将depthwise卷积的输出组合起来;

4、depthwise卷积
- 输入: ,输出: ,卷积核: ;
- 卷积核参数:分开为 个通道,每个通道都是 ,共 ;
- 计算量: ;
5、pointwise卷积
- 输入: ,输出: ,卷积核: ;
- 卷积核参数: ;
- 计算量: ;
6、上述第四第五步总的计算量:
7、Standard Convolution 和Depthwise Separable Convolution对比
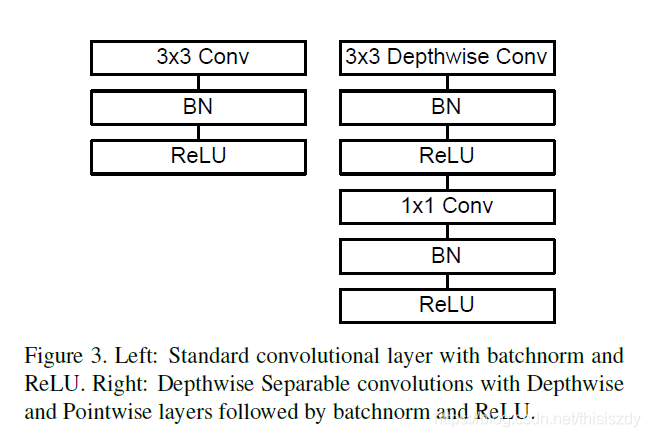
8、MobileNet结构

9、控制MobileNet模型大小的两个超参数
- Width Multiplier: Thinner Models:
1、用 表示,该参数用于控制特征图的维数,即通道数;
2、对于深度可分离卷积,其计算量为: ; - Resolution Multiplier: Reduced Representation:
1、用 表示,该参数用于控制特征图的宽/高,即分辨率;
2、对于深度可分离卷积,其计算量为: ;
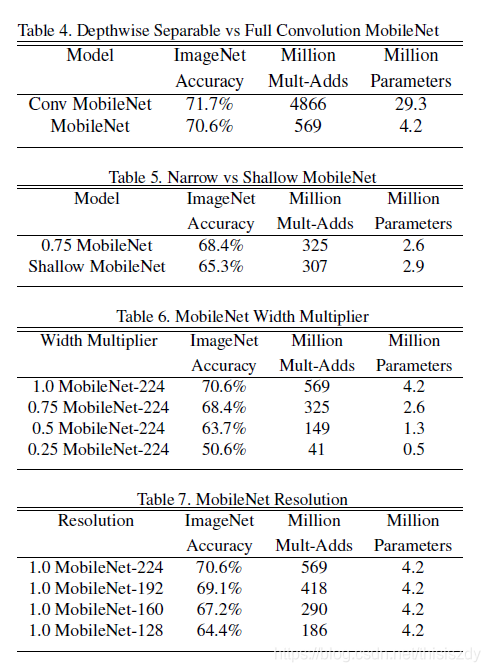
10、结果
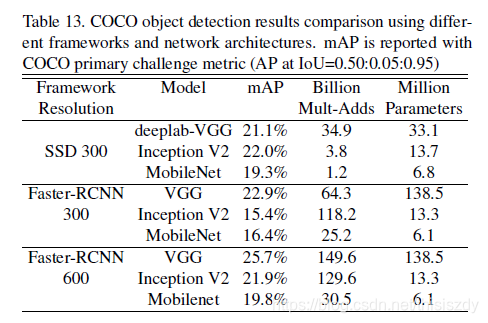
目标检测下使用MobileNet:
附:pytorch代码:
class MobileNet(nn.Module):
def __init__(self):
super(MobileNet, self).__init__()
def conv_bn(inp, oup, stride): # 第一层传统的卷积:conv3*3+BN+ReLU
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride): # 其它层的depthwise convolution:conv3*3+BN+ReLU+conv1*1+BN+ReLU
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn( 3, 32, 2), # 第一层传统的卷积
conv_dw( 32, 64, 1), # 其它层depthwise convolution
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000) # 全连接层
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x