大家好,今天和大家分享一篇基于何恺明团队提出moco优化的算法。提出了一个监督学习和自监督统一的框架,表征能力更强,在多个下游任务上性能超越了 moco v3。
论文:https://arxiv.org/pdf/2210.05557.pdf
代码:https://github.com/wangck20/OPERA
创新点:
基于深度学习中度量学习的监督(fully supervised,FSL)和自监督(self-supervised learning,SSL)学习的统一框架
端到端可训练,在CNN和ViT上的各种任务性能都有所提高
在DeiT-B上,对比学习框架的性能与MIM方法(如MAE)相当
论文:OPERA: Omni-Supervised Representation Learning with Hierarchical Supervisions
摘要
现代计算机视觉中的预训练-微调范式促进了自监督学习的成功,这往往比监督学习获得更好的可迁移性。然而,随着大量标记数据的可用性,一个自然的问题出现了:如何训练一个更好的模型,同时包含自监督和监督信号?在本文中,我们提出了具有层次监督 (OPERA) 的 Omni-suPERvised Representation 学习作为解决方案。我们从标记和未标记的数据中提供了统一的监督视角,并提出了一个监督和自监督学习的统一框架。我们为每个图像提取一组分层代理表示,并对相应的代理表示进行自我和完全监督。卷积神经网络和视觉转换器的大量实验证明了 OPERA 在图像分类、分割和对象检测方面的优越性。
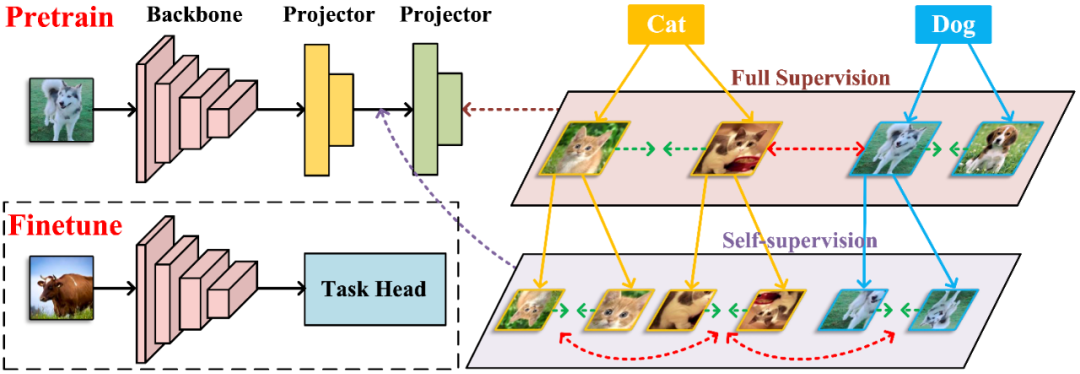
方案
本文首先提出了相似学习框架下自监督学习(SSL)和全监督学习(FSL)的统一观点。然后,建议 OPERA 对相应的层次表示施加层次监督,以获得更好的可转移性。最后,详细说明了提议的 OPERA 框架的实例化。
1、 相似性学习的统一框架
通常,FSL和SSL在监督形式和优化目标上都有所不同。为了统一两者,这里提供了一个统一的相似性学习框架,包括两个训练目标:
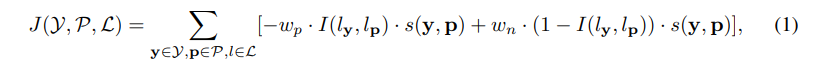
2、 分层表示的分层监督
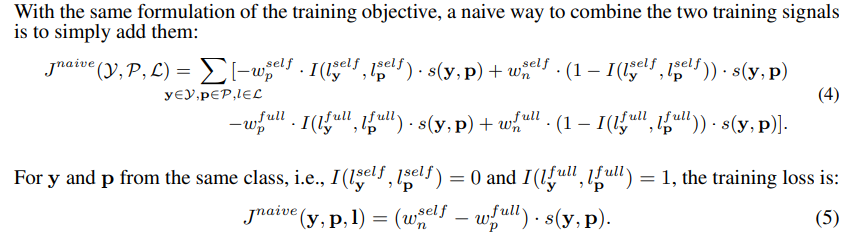
上面的推导表明这两个训练信号是矛盾的,可能会相互抵消。 如果我们对监督学习和自监督学习采用类似的损失函数,这是存在问题的。
现有方法(Nayman 等人,2022;Wei 等人,2022;Wang 等人,2022c)通过随后施加两个训练信号来解决这个问题。他们倾向于首先获得一个自监督的预训练模型,然后使用监督学习对其进行调整。不同的是,我们提出了一种更有效的方法自适应地平衡这两个权重,以便我们可以同时使用它们:
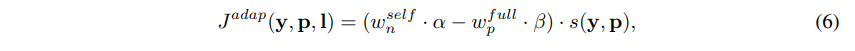
其中,α和β是可依赖于y和p以获得更大灵活性的调制因子。
3、 全方位监督表示学习
为了有效地结合自监督和监督学习来学习表示法,OPERA进一步分层提取一组代理表示法来接收相应的训练信号。
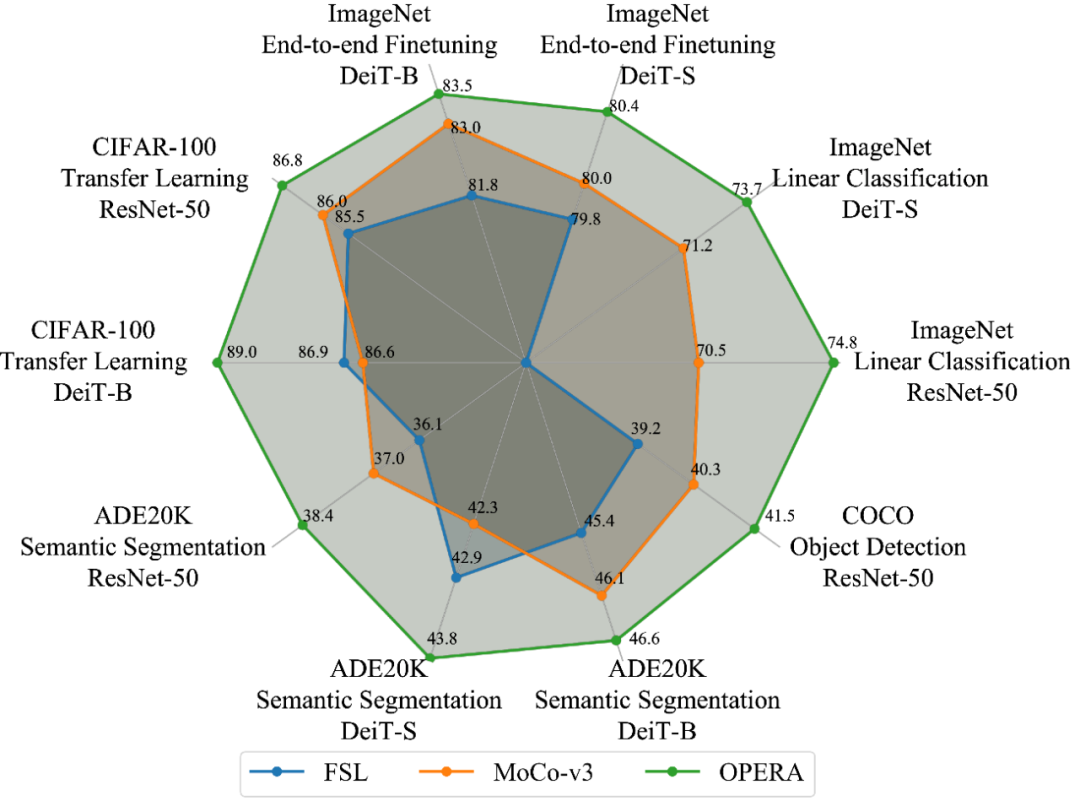
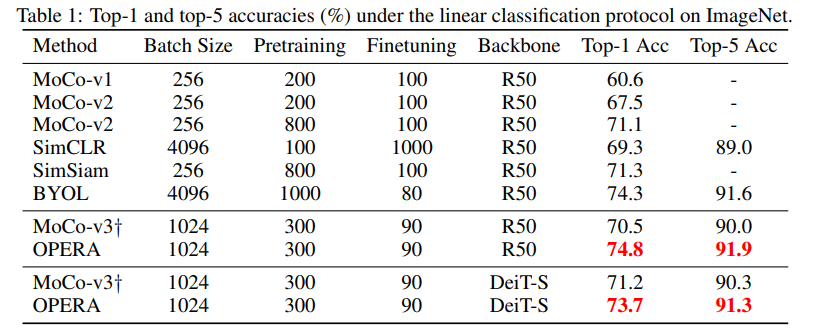
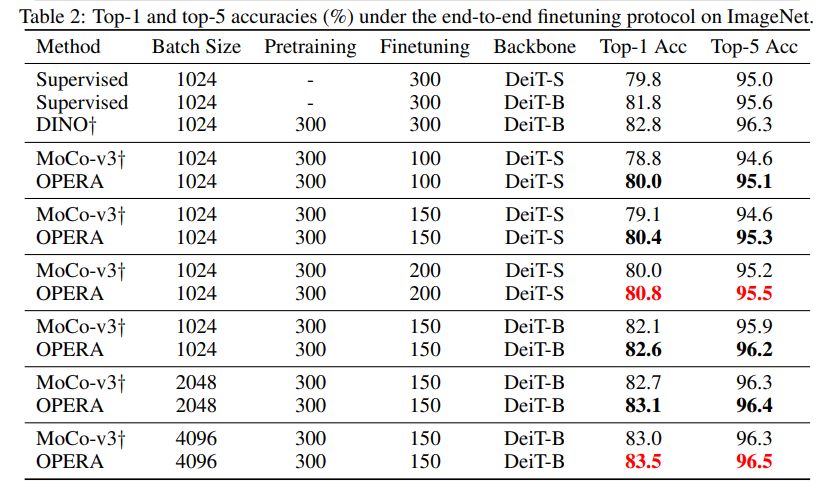
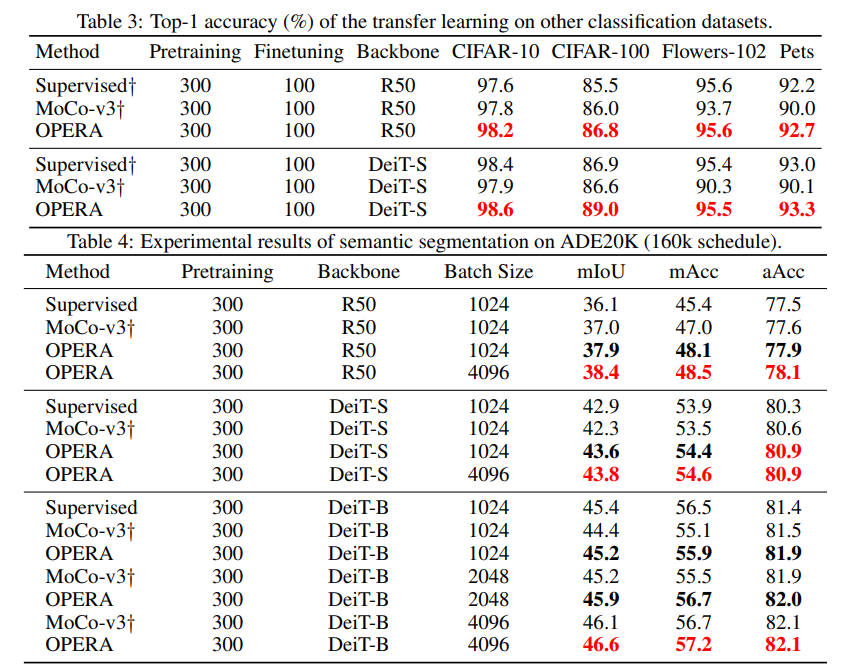
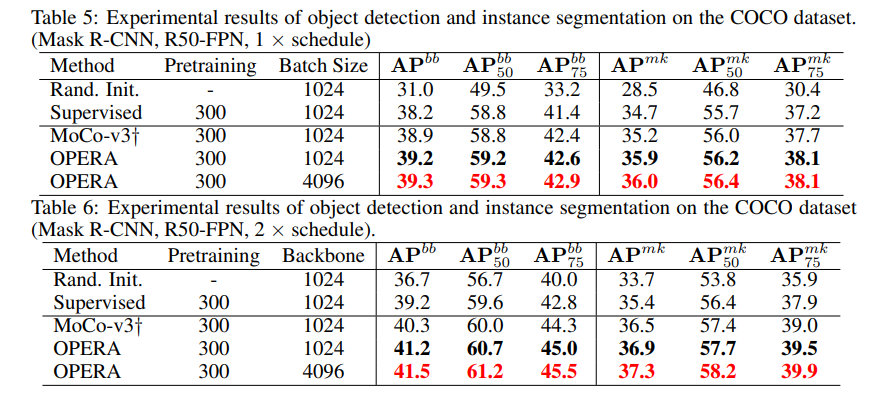
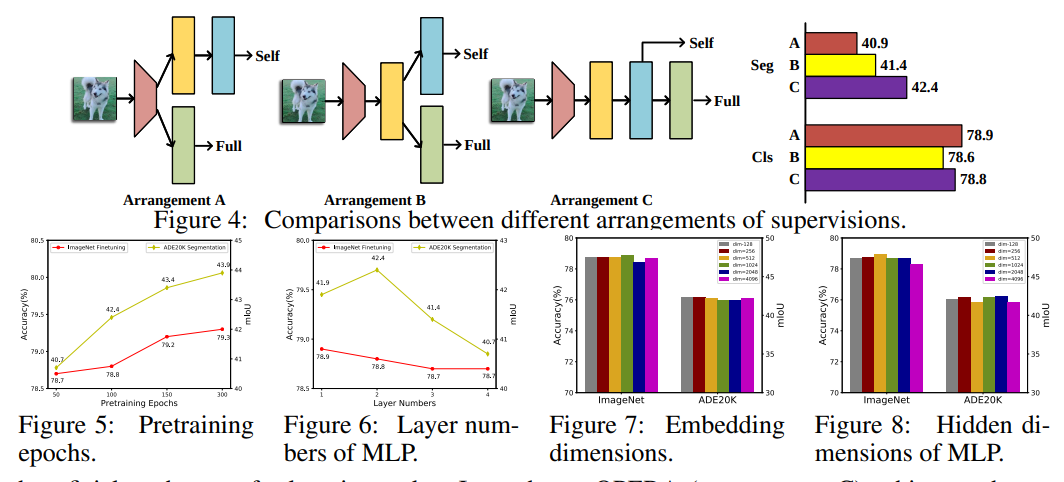
实验结果对比
今天的分享就到这里,大家喜欢的话,可以多多支持,感谢!