1. 自监督学习
自监督学习是可以看做是一种特殊的无监督学习的一个子类别(但并非无监督学习),因为它利用了未标记的数据。
- 关键思想是让模型无需手动标签即可学习数据表示。一旦模型学会了如何表示数据,那么它就可以用较少量的标记数据用于下游任务,以达到与没有自监督学习的模型相似或更好的性能。
1.1 自监督学习步骤
- 基于对数据的理解,以编程方式从未标记的数据生成输入数据和标签
- 预训练:使用上一步中的数据/标签训练模型
- Fine-tune:使用预训练的模型作为初始权重来训练感兴趣的任务.
如果我们在第二步中使用带有手动标签的数据而不是自动生成的标签,那么它将受到监督预训练,称为迁移学习的一个步骤。
1.2 自监督学习的重要性
自监督学习在文本、图像/视频、语音和图形等多个领域取得了成功。本质上,自我监督学习挖掘未标记的数据并提高性能。就像 Yann Lecun 的蛋糕(视频、幻灯片)的比喻一样,这种自监督学习(蛋糕 génoise)每个样本可以吃数百万次,而监督学习(糖衣)只能吃 10 到 10,000 口。也就是说,自监督学习比监督学习能够从每个样本中获得更多有用的信息。
人类生成的标签通常关注数据的特定视图。例如,我们可以只用“马”一词来描述草地上的一匹马的图像(如下图所示)进行图像识别,并提供像素坐标进行语义分割。然而,数据中有更多的信息,例如,马的头和尾巴位于身体的另一侧,或者马通常在草地上(而不是在下面)。这些模型可以直接从数据中学习更好、更复杂的表示,而不是手动标签。更不用说手动标签有时可能是错误的,这对模型是有害的。一项实验研究表明,清理 PASCAL 数据集可以将 MAP 提高 13。即使没有与最先进的技术进行比较,我们仍然可以看到错误标签可能会导致性能更差。

数据标记成本高昂、耗时且劳动密集型。此外,监督学习方法需要针对新数据/标签和新任务使用不同的标签。更重要的是,事实证明,对于基于图像的任务(即图像识别、对象检测、语义分割),自监督预训练甚至优于监督预训练[参考]。
**换句话说,直接从数据中提取信息比手动标注更有帮助。**那么,根据任务的不同,我们现在或不久的将来可能不需要许多昂贵的标签来进行更先进的自我监督学习。
自监督学习的优越性在基于图像的任务中得到了验证,这要归功于图像领域中的大规模标记数据集,在最近的深度学习趋势中,图像领域比其他领域有着更长的历史。我相信未来类似的优势也会在其他领域得到证明。因此,自我监督学习对于推进机器学习领域至关重要。
1.3 如何使用自监督模型
通常,当自监督模型发布时,我们可以下载预训练的模型。然后,我们可以对预训练的模型进行微调,并将微调后的模型用于特定的下游任务。例如,最著名的自监督学习示例可能是 BERT(参考文献)。BERT 以自我监督学习方式对 33 亿个单词进行了预训练。我们可以针对文本相关任务(例如句子分类)对 BERT 进行微调,比从头开始训练模型所需的工作量和数据要少得多。基于经过微调的 BERT 模型,我创建了一个应用程序,用于预测推文消息是否来自 Hugging Face 上的 Elon Musk(链接)。我将单独写一篇文章来介绍我是如何创建它的。随意玩吧,玩得开心!
2. 自监督学习的种类
2.1 生成方法
恢复原始信息
a.非自回归:屏蔽标记/像素并预测屏蔽的标记/像素(例如,屏蔽语言建模(MLM))
b.自回归:预测下一个标记/像素;
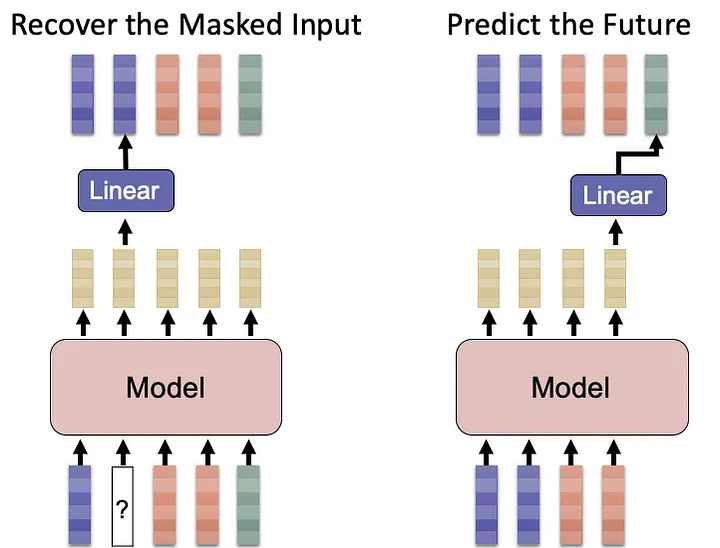
通过周围数据预测屏蔽输入是最早的自监督方法类别。这个想法实际上可以追溯到这句话,“你应该通过它所陪伴的人来认识一个单词。”——约翰·鲁珀特·费斯(John Rupert Firth,1957),一位语言学家。这一系列算法始于 2013 年文本领域的 word2vec ( ref )。word2vec 的连续词袋 (CBOW) 的概念是通过其邻居来预测中心词,这与 ELMo ( ref )和BERT 的掩码语言建模 (MLM)(参考)。这些模型都被归类为非自回归生成方法。主要区别在于,后来的模型使用了更先进的结构,例如双向 LSTM(用于 ELMo)和 Transformer(用于 BERT),而最近的模型生成了上下文嵌入。
在语音领域,Mockingjay ( ref ) 屏蔽了连续特征的所有维度,而 TERA ( ref ) 屏蔽了特征维度的特定子集。在图像领域,OpenAI 应用了 BERT 机制(参考文献)。在图领域,GPT-GNN 还屏蔽了属性和边(参考)。这些方法都屏蔽了部分输入数据并试图将它们预测回来。
另一方面,另一种生成方法是预测下一个标记/像素/声学特征。在文本领域,GPT系列型号(ref&ref)是该类别的先驱。APC ( ref ) 和 ImageGPT ( ref ) 分别在语音和图像领域应用了相同的思想。有趣的是,由于相邻的声学特征很容易预测,因此通常要求模型预测后面序列中的标记(至少 3 个标记之外)。
自监督学习(尤其是 BERT/GPT)的巨大成功促使研究人员将类似的生成方法应用于图像和语音等其他领域。然而,对于图像和语音数据,生成屏蔽输入更困难,因为选择有限数量的文本标记比选择无限数量的图像像素/声学特征更容易。性能改进不如文本字段。因此,研究人员在接下来的会议中还开发了许多其他非生成方法。
2.2 预测任务
基于数据的理解、聚类或增强来设计标签
a:预测上下文(例如,预测图像块的相对位置,预测下一个片段是否是下一个句子)
b:预测聚类每个样本
c的id:预测图像旋转角度
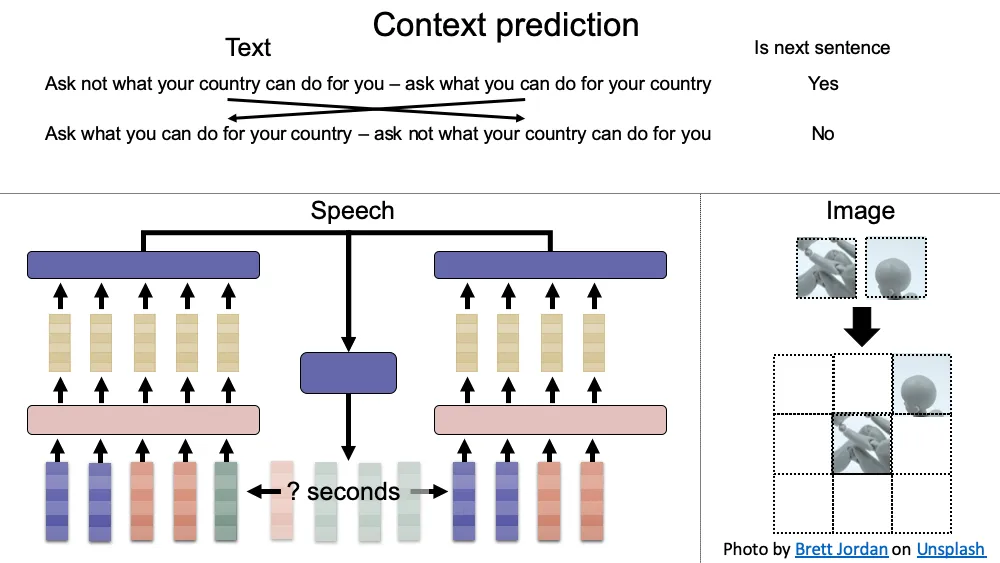
主要思想是设计更简化的目标以避免数据生成。最关键和最具挑战性的一点是任务需要处于适当的难度级别才能让模型学习。
例如,在预测文本字段中的上下文时,BERT 和 ALBERT 都预测下一个片段是否是下一个句子。BERT 通过随机交换下一个片段与另一个片段(下一句预测;NSP)来提供负训练样本,而 ALBERT 通过交换上一个和下一个片段(句子顺序预测;SOP)来提供负训练样本。SOP 已被证明优于 NSP(参考文献)。一种解释是,通过主题预测很容易区分随机句子对,以至于模型没有从 NSP 任务中学到太多东西;而SOP允许模型学习连贯关系。因此,需要领域知识来设计好的任务和实验来验证任务效率。
像 SOP 一样预测上下文的想法也应用于图像领域(预测图像块(ref)的相对位置)和语音领域(预测两个声学特征组(ref)之间的时间间隔)。
另一种方法是通过聚类生成标签。在图像领域,DeepCluster应用了k-means聚类(参考)。在语音领域,HuBERT 应用了 k 均值聚类(ref),而 BEST-RQ 采用了随机投影量化器(ref)。
图像领域的其他任务有:通过图像的颜色通道预测灰度通道(反之亦然;ref),重建图像的随机裁剪块(即修复;ref),重建原始分辨率的图像( ref ),预测图像的旋转角度 ( ref ),预测图像的颜色 ( ref1,ref2,ref3 ) 并解决拼图游戏 ( ref )。
2.3 对比学习
又名对比实例辨别):根据增强创建的正负样本对设置二元分类问题
对比学习的关键概念是根据对数据的理解生成正负训练样本对。模型需要学习一个函数,使得两个正样本具有较高的相似度分数,两个负样本具有较低的相似度分数。因此,适当的样本生成对于确保模型学习数据的底层特征/结构至关重要。
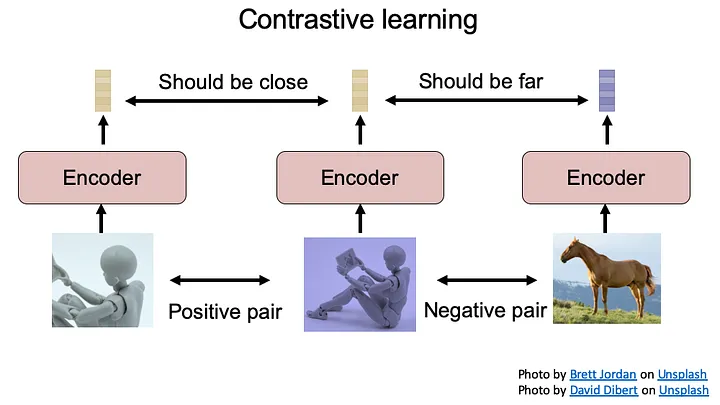
2.3.1 图像领域对比学习
图像领域的对比学习应用来自同一原始图像的两种不同的数据增强来生成正样本对,并使用两个不同的图像作为负样本对。
最关键和最具挑战性的两个部分是增强的强度和负样本对的选择。如果增强太强以至于同一样本的两个增强样本之间没有关系,则模型无法学习。同样,如果增强量太小以至于模型可以轻松解决问题,那么模型也无法为下游任务学习有用的信息。至于选择负样本对,如果我们随机分配两个图像作为负样本对,它们可能是同一类(例如,猫的两个图像),这会给模型带来冲突的噪声。如果负对很容易区分,那么模型就无法学习数据的底层特征/结构。对比学习最著名的例子是 SimCLR (v1,v2)和MoCo(v1,v2)
2.3.2 音频领域对比学习
对于语音领域,一种方法是应用像 SimCLR ( Speech SimCLR ) 这样的增强。另一种方法是使用相邻特征作为正对,使用不同样本的特征作为负对(例如,CPC、 Wav2vec ( v1 , v2.0 ) 、VQ-wav2vec和Discret BERT)。在图领域,DGI最大化了图块表示和图的全局表示之间的互信息,并最小化了损坏图的块表示和原始图的全局表示之间的互信息。
一个有趣的认识是,文本领域自监督学习的分类实际上在概念上类似于对比学习。分类最大化正类的输出并最小化负类的输出。同样,对比学习也会最大化正对的输出并最小化负对的输出。关键区别在于分类具有有限数量的负类(在文本标记的情况下),而对比学习具有无限数量的负类(在图像和声学特征的情况下)。理论上,我们可以通过给定少量的类来设计图像/语音的分类器。一类是一张原始图像,输入是增强图像。然而,
2.4 自举 方法
使用两个相似但不同的网络从同一样本的增强对中学习相同的表示;
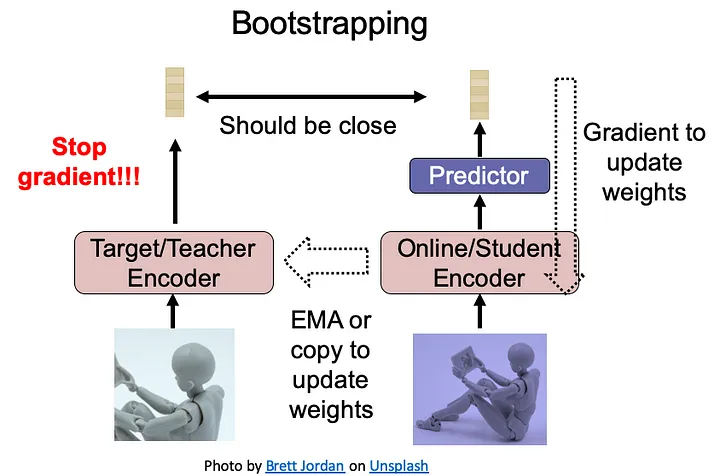
研究人员进一步开发了引导方法来避免使用负例,因为训练的计算量很大,并且不容易选择好的负例。自举方法的关键思想是 1)从同一原始样本的两次增强中生成一对正样本(就像对比学习一样);2)设置一个网络作为目标网络(也称为教师网络),另一个网络作为在线网络(也称为学生网络),其架构与目标网络相同,加上一个额外的前馈层(称为预测器) ; 3)固定目标/教师网络的权重,仅更新在线/学生网络;4)根据在线/学生网络的权重更新目标/教师网络的权重。
最重要的设计是1)在线网络需要有预测器(附加层);2)只能更新在线网络的权重;否则网络就会崩溃(即无论输入如何都输出相同的值)。
在图像领域,BYOL通过在线/学生网络权重的指数移动平均(EMA)更新目标/教师网络的权重(参考);而 SimSiam 只是简单地复制权重(参考)。
Meta 的 Data2vec 是图像、语音和文本字段的统一框架(参考)。它还需要 EMA 来更新目标/教师网络,但它使用掩蔽预测任务。它向目标/教师网络提供原始数据,向在线/学生网络提供屏蔽数据。一项重要的设计是,其目标是预测目标/教师网络中前几层的屏蔽输入区域/标记的平均嵌入。
2.5 正则化
根据假设/直觉添加损失和正则化项:
a:正对应该相似
b:同一批次中不同样本的输出应该不同
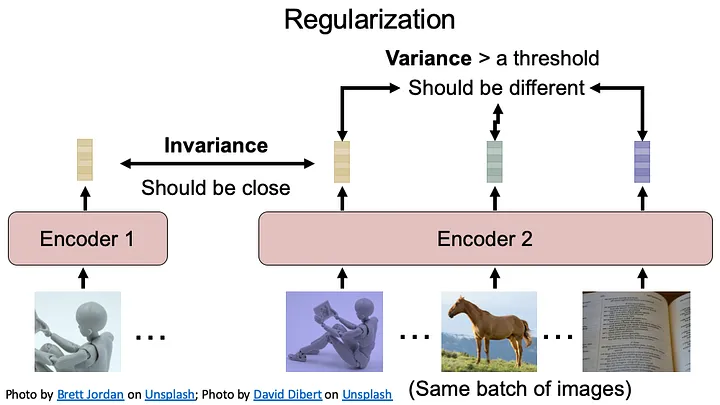
这是另一种方法,只需要正例对,不需要负例。令人惊讶的是,这些方法可以对两个网络使用相同的架构,并且它们也不需要“停止梯度”机制来在训练期间仅更新其中一个网络。通过添加额外的正则化项,模型也不会崩溃。目标函数项包括:
不变性:损失项使同一正对的两个嵌入尽可能相似。Barlow Twins和DeLoRes的不变性项力求在图像场和音频场中将互相关矩阵的对角线元素分别等于 1;在图像领域,VICReg 最小化两个嵌入之间的均方欧氏距离 ( ref )。
方差:正则化项使同一批次中的样本保持足够的差异,因为它们不是同一样本。Barlow Twins和DeLoRes的冗余减少项试图分别将图像场和音频场中互相关矩阵的非对角线元素等同于 0。在图像领域,VICReg 的方差项使用铰链损失来保持同一批次中样本的嵌入输出的标准偏差高于阈值(参考)。VICReg 的协方差项最小化协方差矩阵中非对角项的大小,以对每对嵌入去相关。该术语可以极大地提高性能并最大化使用嵌入向量的所有维度的效率。然而,这并不是防止信息崩溃所必需的(参考)。
VICReg 论文表明,与其他自监督框架(Barlow Twins 和 SimCLR)相比,VICReg 对于不同的网络架构更加稳健。因此,它可以实现未来的多模态应用。