根据训练期间接受的监督数量和监督类型,可以将机器学习分为以下四种类型:监督学习、非监督学习、半监督学习和强化学习。
监督学习
在监督学习中,提供给算法的包含所需解决方案的训练数据,成为标签或标记。

简单地说,就是监督学习是包含自变量和因变量(有Y),同时可以用于分类和回归。
常见算法:
- K近邻算法
- 线性回归
- logistic回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
无监督学习
无监督学习的训练数据都是未经标记的,算法会在没有指导的情况下自动学习。


简单地说,就是训练数据只有自变量没有因变量(就是没有Y)。
常见算法:
- 聚类算法
- K均值算法(K-means)
- 基于密度的聚类方法(DBSCAN)
- 最大期望算法
- 可视化和降维
- 主成分分析
- 核主成分分析
- 关联规则学习
- Apriori
- Eclat
半监督学习
有些算法可以处理部分标记的训练数据,通常是大量未标记的数据和少量标记的数据,这种成为半监督学习。
如照片识别就是很好的例子。在线相册可以指定识别同一个人的照片(无监督学习),当你把这些同一个人增加一个标签的后,新的有同一个人的照片就自动帮你加上标签了。

大多数半监督学习算法都是无监督和监督算法的结合。例如深度信念网络(DBN)基于一种相互堆叠的无监督式组件。
强化学习
强化学习是一个非常与众不同的算法,它的学习系统能够观测环境,做出选择,执行操作并获得回报,或者是以负面回报的形式获得惩罚。它必须自行学习什么是最好的策略,从而随着时间推移获得最大的回报。
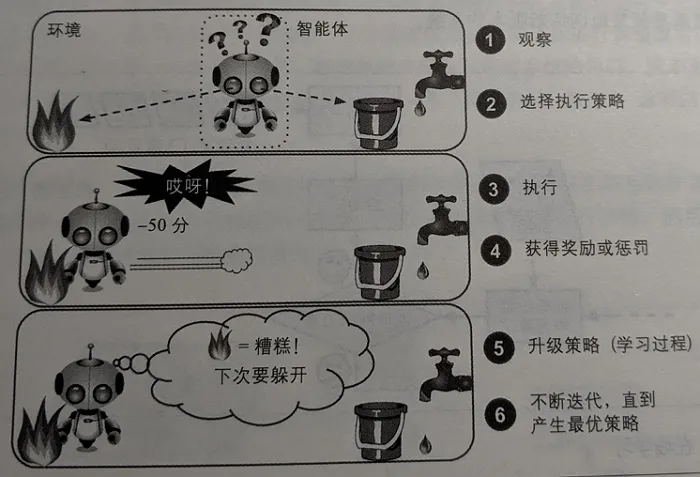
例如,许多机器人通过强化学习算法来学习如何行走。AlphaGo项目也是一个强化学习的好例子。