文章目录
代理任务:个体判别,每一张图片都是自己的类,每一张图片都尽可能和其他图片分开。
对比学习:需要有正负样本,让正负样尽可能的分开,负样本越多对比学习效果更好
一、Inst Disc
研究意义价值
提出了个体判别的代理任务,提出使用memory bank数据结构存储大量负样本,是MoCo的前身。
个体判别(instance discrimination)
将每一张图片都看作是一个类别,希望模型可以学习图片的表征,从而把各种图片都区分出来。
特点
把每一张图片都看做一个类别,通过卷积神经网络学习每一张图片(每个实例)的特征,从而把每一张图片都分开。
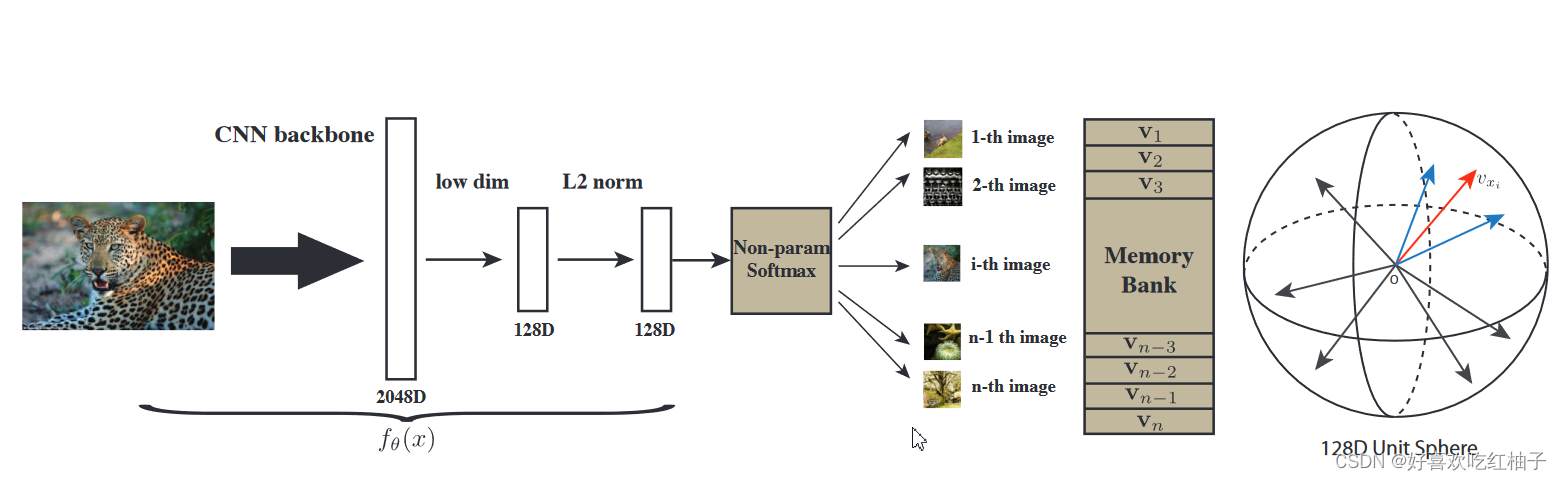
实现方法
通过CNN给图片编码成一个128维的特征,然后在特征空间中将这些特征尽可能分开。
如何训练CNN
使用对比学习中的正负样本进行训练。
正样本:图像本身
负样本:数据集中除了正样本的其他图片。
大量负样本如何存储
数据结构:memory bank(字典),后文简称mb,把所有图片的特征向量都存储在一个memory bank中。
以ImageNet数据集为例,数据集中共有128万张图片,因此memory bank字典就需要有128万行,所以需要把图片的特征维度尽可能减小来降低内存。
在论文中选择了128维的向量。
前向传播过程
- 图片特征向量大小:batchsize = 256, 256张图片进入编码器中,通过ResNet50生成一个2048维特征向量,再降维形成128维的向量。
- 正样本:一批次为256个
- 负样本:从mb中随机抽取的4096个图片的特征向量
- loss function:NCE loss
- 更新mb:利用NCE loss去更新CNN的参数。本次更新结束后,会将CNN编码得到的向量替换掉memory bank中原有的存储。就这样循环往复的更新CNN和memory bank,最后让模型收敛,就训练好一个CNN encoder了
Proximal Regularization
为模型的训练加一个约束,使得mb可以进行动量式的更新。
超参数设置
- loss中温度的设置:0.07
- epoch = 200
- 负样本个数:4096
- batchsize = 256
- initial learning rate = 0.03
Moco中的超参数设置都与该设置相同。
二、Inva Sread
SimCLR前身
特点
- 不使用其他数据结构去存储大量负样本,正负样本均来源于一个mini-batch。
- 只使用一个编码器进行端到端的学习。
原理
对比学习的思想。
- 相似的图片通过编码器后生成的特征应该类似,保持特征不变性
- 不相似的图片通过编码器后生成的特征应该有很大的差异,尽可能分散
代理任务:个体判别
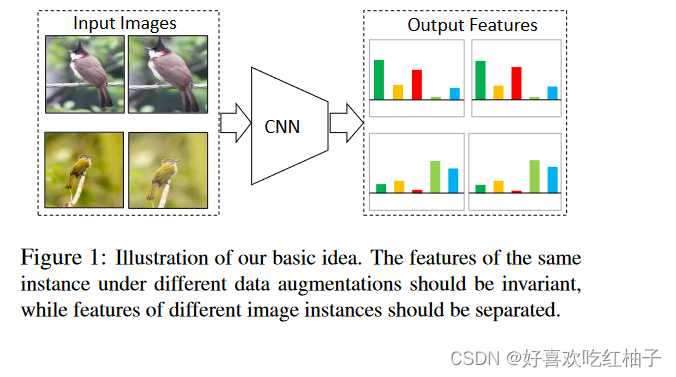
如何选取正负样本
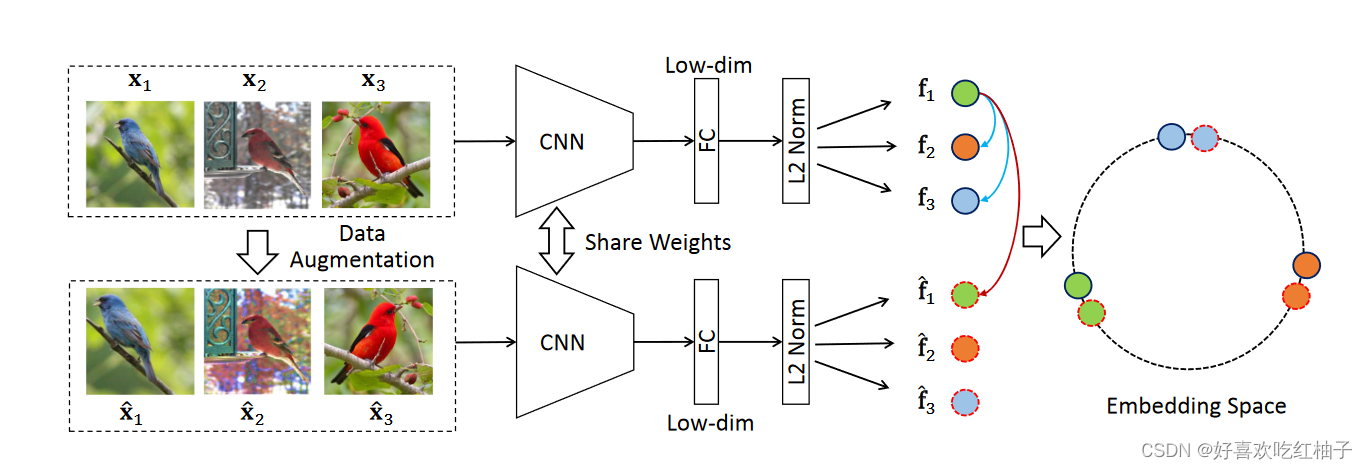
画图理解一下正负样本如何选取:
假设一个mini-batch为256张图片(x1-x256),经过数据增强后会再次得到256张图片(x1’-x256’),原图和其经过数据增强后的图片即成为一个正样本对(positive sample pair),即256对,除了正样本对之外的图片即为负样本,即(256-1)个负样本对(negetive sample pair)
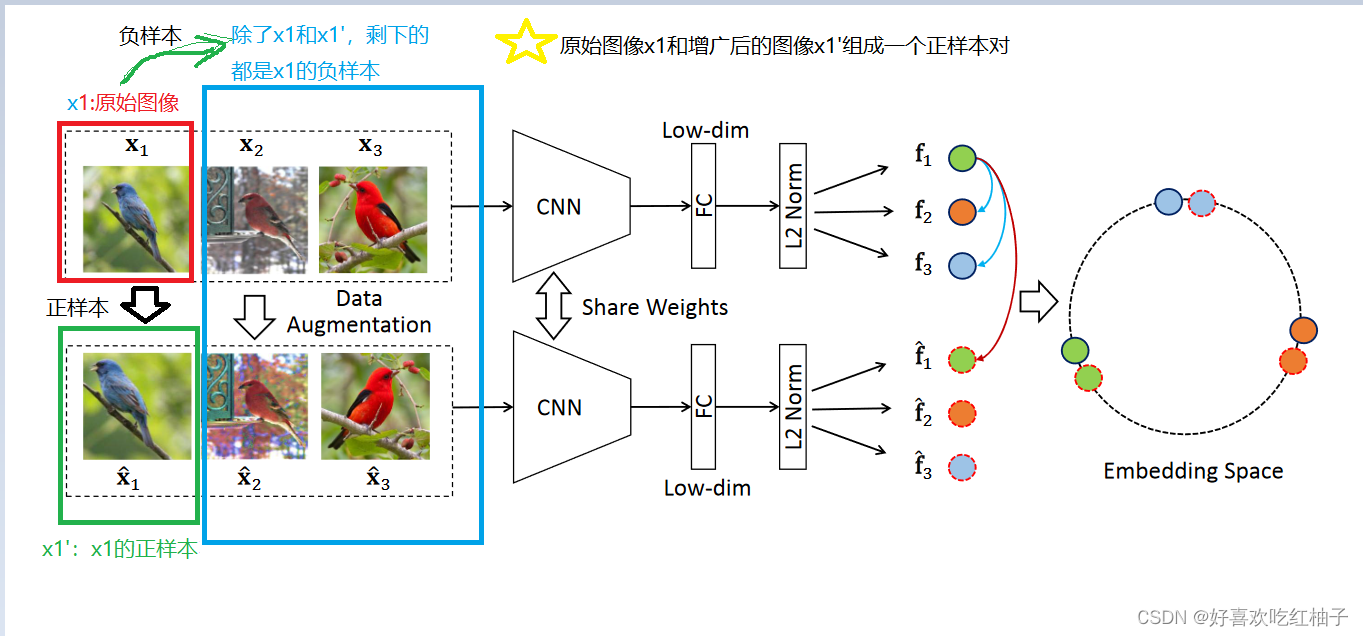
为什么从一个batch中选择正负样本?
可以使用一个编码器进行端到端的学习。
前向传播过程
图像和增广后的图像分别经过CNN编码器输出2048维向量,两个编码器是权值共享的,所以相当于是一个编码器,然后经过降维输出128维向量,在embedding space中让正样本之间向量尽量靠近,让负样本之间向量尽量远离。
目标函数
NCE的变体。
模型效果不够好的原因
- 没有使用字典进行存储负样本,负样本数量不够大,导致对比学习的效果不够好。
- 没有足够强大的数据增广。
- 没有SimCLR中的projection head。
MoCo
动量对比学习方法做无监督表征学习。
具体讲解见:自监督学习之对比学习:MoCo模型超级详解解读+总结
SimCLR
模型
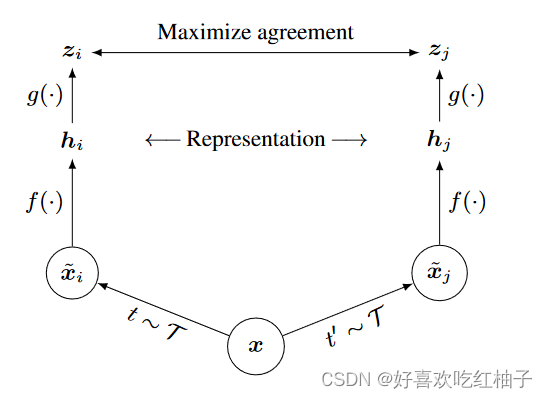
正负样本对的选取
把原图进行不同的数据增广后得到xi和xj,该两张图片互为正样本,一个batch中的其他图片均为其负样本。如一个batch中有n张图片,对每张图片都进行两次数据增广,经过数据增广后该batch中则会包含2N张图片,其中有N对互为正样本对,则有N-1对为其负样本对。

Proection Head
模型中的g(.)函数:全连接层(20482048)-> BN -> 激活函数 -> 全连接层(2048128) -> BN
前向传播过程
 ,
,
注意:projection head只在训练的时候使用,在后续下游任务时去掉g函数那一层,使用h特征向量做下游任务。
和Inva Sread的区别
- 更多的数据增强: 多种数据增强的方法进行使用。
- 更大的batchsize进行训练。
- 加了一个projection head:加一个非线性变换。
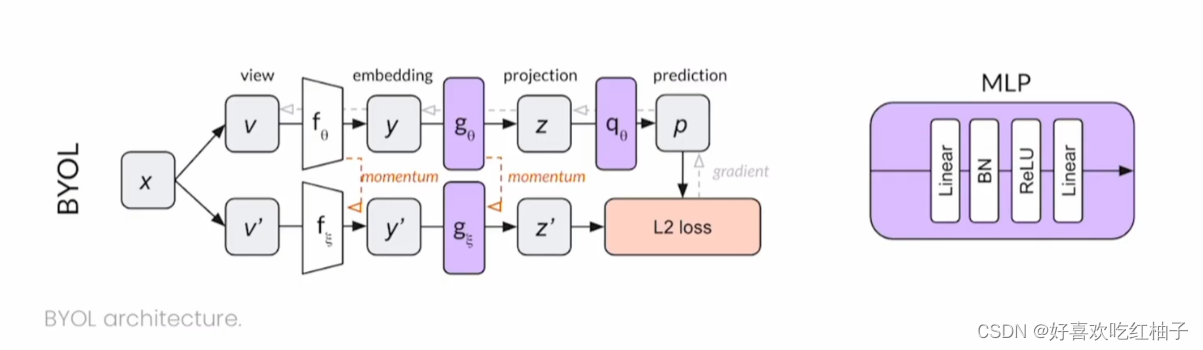
BYOL
无需负样本就可以做对比自监督学习。
模型
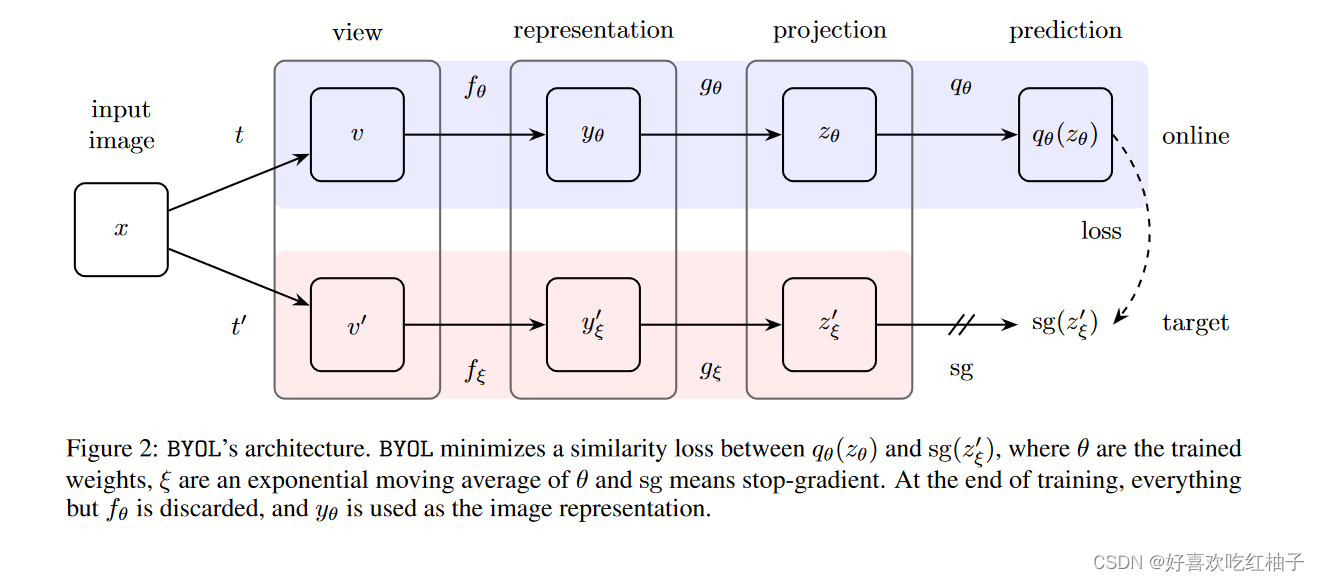
目标函数
MSE loss
BYOL模型中的BN作用
模型进行隐式的负样本学习。
参考
Unsupervised Feature Learning via Non-Parametric Instance Discrimination
SimCLR知乎解读