预训练
1)特征提取要解决的问题是怎么分别量化文字和图像,进而送到模型学习?
特征抽取:
文本:倾向于bert等大模型
图像:神经网络,VIT等
2)特征融合要解决的问题是怎么让文字和图像的表征交互?
最简单的:相加/拼接,然而也可设计更巧妙的结构啦
3)预训练任务就是怎么去设计一些预训练任务(PreTask)来辅助模型学习到图文的对齐信息?
跨模态的特征融合等
预训练主流方法
特征提取: 文本端的表征标配就是bert的tokenizer,更早的可能有LSTM; 图像的话就是使用一些传统经典的卷积网络,按提取的形式主要有三种Rol、Pixel、Patch三种形式。
特征融合:目前的主流的做法不外乎两种即双流two-stream或者单流single-stream; 前者基本上就是双塔网络,然后在模型最后的时候设计一些layer进行交互,所以双流结构的交互发生的时间更晚。后者就是一个网络比如transformer,其从一开始就进入一个网络进行交互,所以单流结构的交互时间发生的更早且全程发生,更灵活。
预训练PreTask: 这里就是最有意思的地方,也是大部分多模态paper的idea体现。这里就先总结一些常见的标配任务,一些特色的任务后面paper 单独介绍
Masked Language Modeling ( MLM )
Masked Region Modeling(MRM)
Image Text Maching (ITM)
自监督学习
意义
经过海量无标签数据的学习后可以习得一个强大的特征提取器,在面对新的任务,尤其是医疗影像等小样本任务时,也能提取到较好的特征。
常见用途
相对位置预测:预测一张图像中随机选择的两个图像块之间的相对位置
图像修复:预测一张图像中被遮挡的部分拼图游戏:将图像中打乱的9个图像块复原
旋转角度预测:预测图像中物体的旋转角度
图像着色: Lab图像中利用L亮度通道,预测ab色彩通道
跨通道预测: L通道和ab通道相互预测
计数:预测鼻子、眼睛、爪子、头的数量
实例区分:分类,一张图像和其增强的图像为一类,和其他图像为不同类
对比预测编码: 根据“过去的”信息,预测“未来的”信息
基于对比学习的视觉自监督算法
概念
对比学习的概念很早就有了,它是无监督学习的一种方法。没有监督信息,又不需要重构数据,那如何学习呢? -- 数据增强+互信息
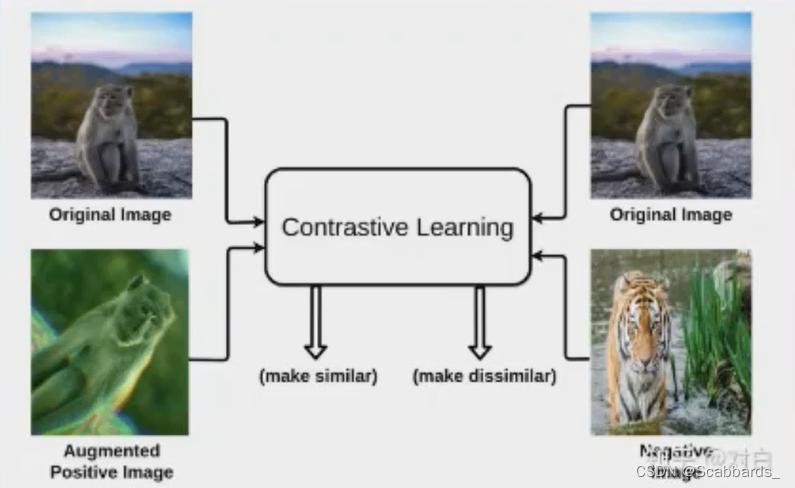
其核心是通过计算样本表示间的距离,拉近正样本,拉远负样本。也就是说,当我们能够区分该样本的正负例时,得到的表示就够用了
公式
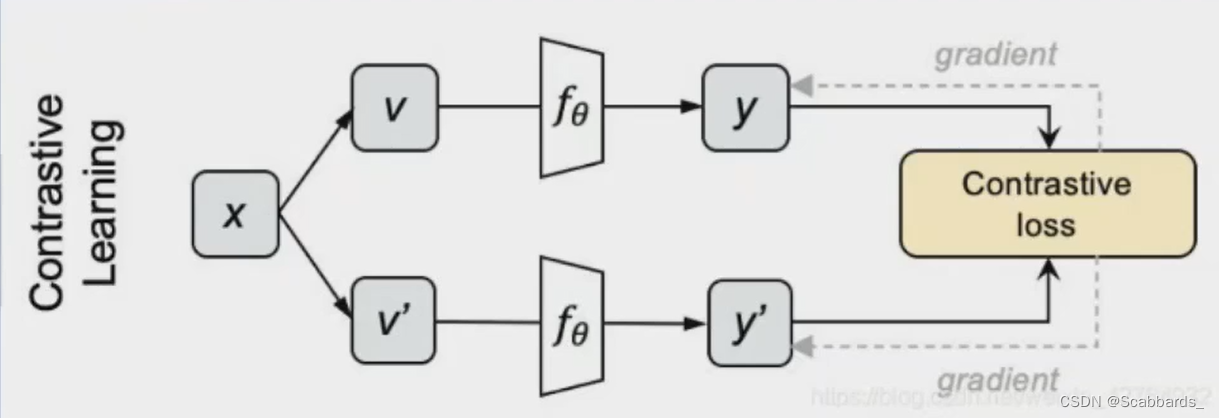
1. 采样N个图片,用不同的数据增强方法为每个图片生成两个view
2. 分别将他们输入网络,获得编码表示y和y'
3. 对上下两批表示两两计算cosine,得到NxN的矩阵,每一行的对角线位置代表y和y’ 的相似度, 其余代表y和N-1个负例的相似度。对每一行做softmax分类,采用交叉熵损失作为loss,就得到对比学习的损失了
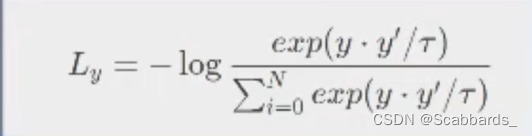
其中 t \ tau t 是可调节的系数,点乘后的结果的量级不适合 softmax运算,通过一个 t \tau t 系数控制
实现方式
end-to-end
使用当前batch中的样本作为dictionary
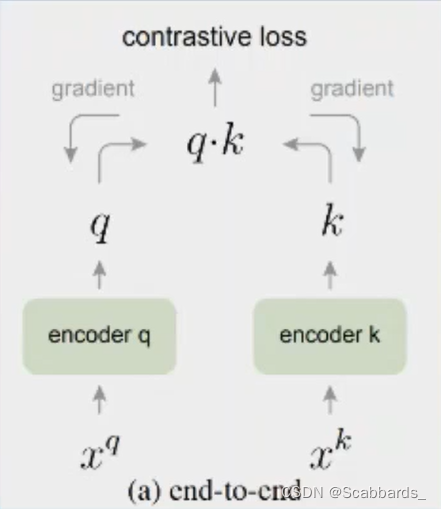
缺点:受限于GPU,batch不可能太大dictionary也就大不了
memory bank 存储队列
设立memory bank,把之前编码好的样本存储起来
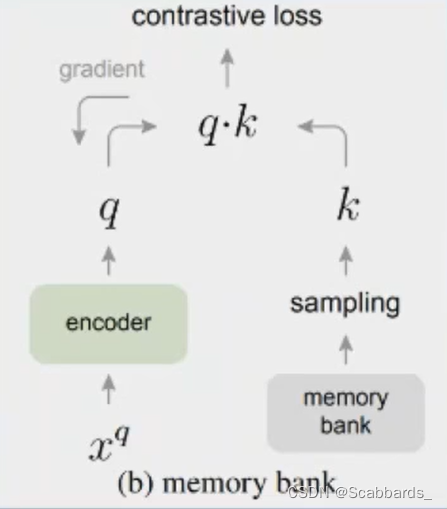
存储好的编码都是之前的编码器计算的,而 左侧编码器一直在更新.会有两侧不一致的情况,影响目标优化
MoCo
Moco解决了上述方法的劣势
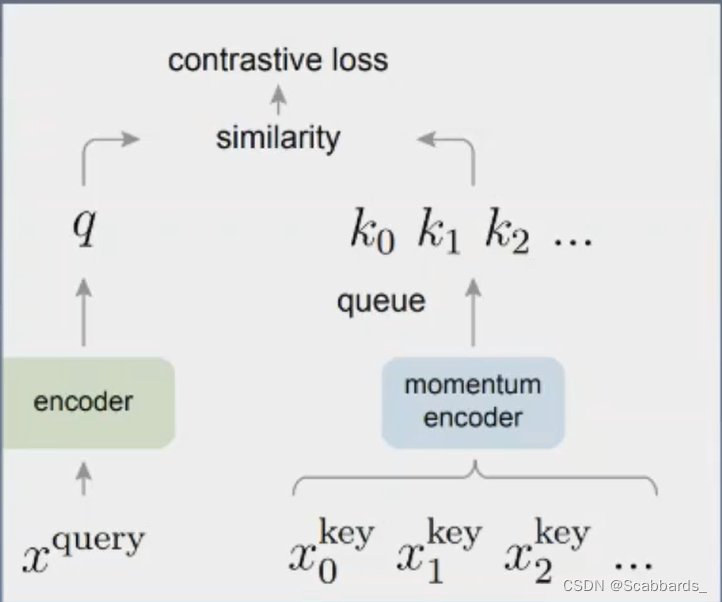
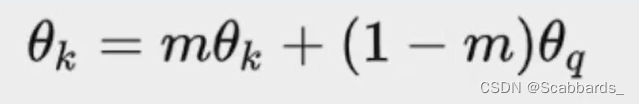

损失函数
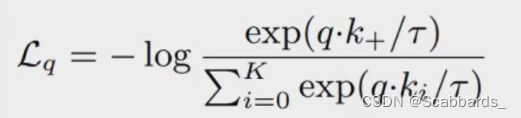
假设其中有一个 positive样本 k+ ,其余均是 negative 样本,则根据 nfoNCE 的损失,损失表示为:
其中 q 和 k+ 可以有多种构造方式。本文用了一种较为简单的方式:
(1) 一种图片进行 random resize;
(2)进行两次224*224的随机Crop得到两个图像分别作为 q 和 k+ ;
(3)进行增强操作,包括 random color jttering, random horizontal fliprandom grayscale conversion 等
用途
因为对比学习是看是否相似,所以可以用于检索,图搜图
基于mask的视觉自监督算法
随着 Vision Transformer (ViT) 在 2021 年霸榜各大数据集,如何基于 ViT 构建更加合适的自监督学习范式成为了该领域的一大问题。最初,DINO 和 MoCo v3 尝试将对比学习和 ViT相结合,取得了不错的效果。不过长期以来,由于 CV 和 NLP 领域数据和基础模型之间的差异NLP 的 Masked Language Modeling (MLM) 码模式机制没能成功应用于 CV 领域,但最近 ViT的逢勃发展,为掩码学习机制应用于视觉自监督打开了一扇大门。
实现方式
BEIT
受BERT的启发,作者提出了一个预训练任务,即 masked image modeling (MIM)MIM对每个图像使用两个视图,即图像patch和视觉token。作者将图像分割成一个网格的patches,这些patch是主于Transformer的输入表示。此外,作者将图像“tokenize”为离散视觉token,这是通过离散VAE的潜在代码获得的。在预训练期间作者随机mask部分图像patch,并将损坏的输入到Transformer。该模型学习恢复原始图像的视觉token,而不是mask patch的原始像素。
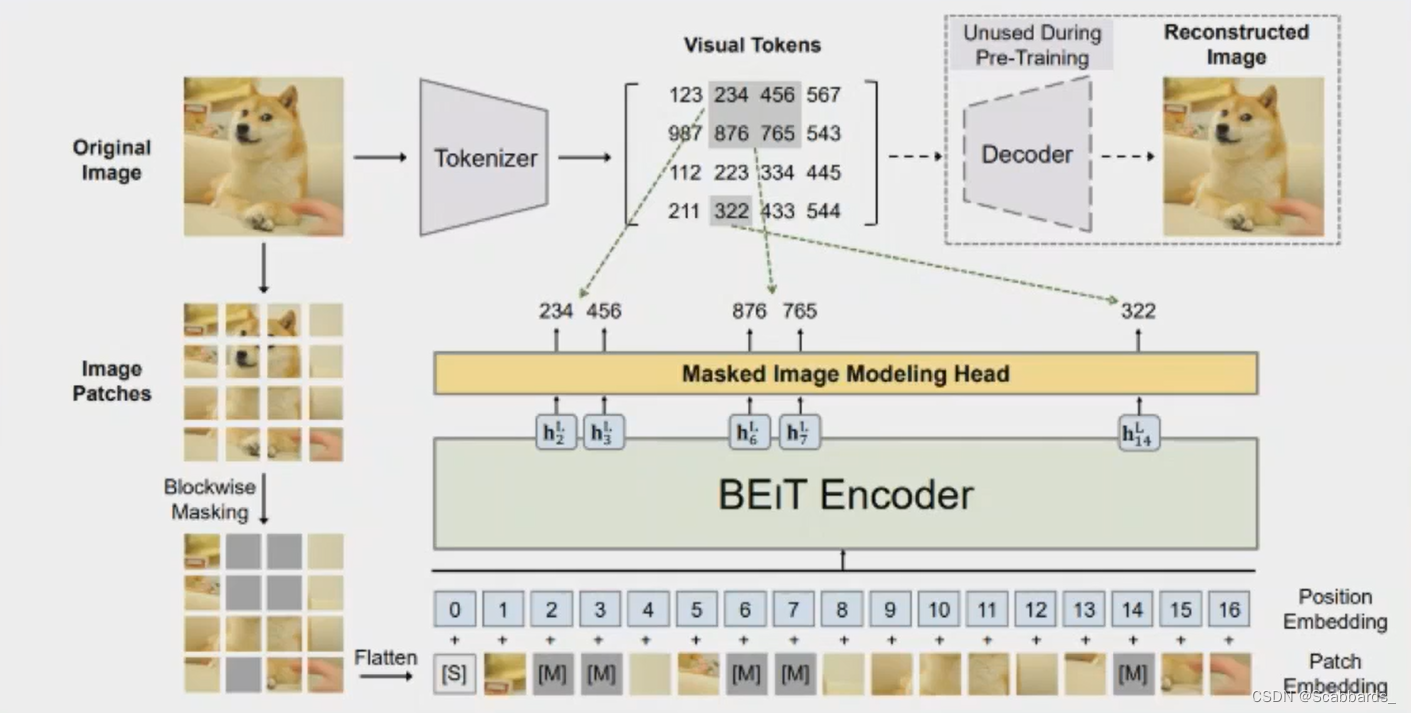
图像有两个表示视图,即图像patch 和视觉token 。这两种类型分别作为预训练的输入和输出表示。
Visual Token
目的:得到监督信号
通过离散变分自编码器 (DVAE)学习image tokenizer。在视觉token学习过程中,有两个模块,即tokenizer 和解码器 。tokenizer据视觉码本(即词汇表)将图像像素x映射为离散的tokens z。解码器学习基于token z重建输入图像x。重建目标可以写成。由于潜在的视觉token是离散的,模型训练是不可微的。因此,作者采用Gumbel-softmax用来训练模型。此外,在dVAE训练过程中,在tokenizer上加入一个统一的先验。
作者将每个图像标记为14X14的视觉token grid。词汇表大小设置为8192。
Image Patch
2D图像被分割成一系列patch,以便标准Transformer可以直接接受图像数据。形式上,作者reshape图片H*W*C为个(H*W)/(P*P)个patch,其中C是通道数,(H,W) 是输入图像分辨率, (P,P) 是每个patch的分辨率。图像patch被展平成向量并线性投影,这类似于BERT中的单词嵌入。图像块保留原始像素,并在BEIT中用作输入特征。
在本文的实验中,作者将每幅224X 224的图像分割成一个14X14的图像网格,其中每个图像网格的大小为16X16。
下游任务
跨模态检索
任务: 给定文本或者图像任一模态的query,在其他模态的gallery中检索最相似的匹配结果
应用:电商商品检索 (以文搜图)
实现
Matching Function Learning,对应单塔结构中的ITM。
Representation Learning,对应双塔中的对比学习+余弦相似度
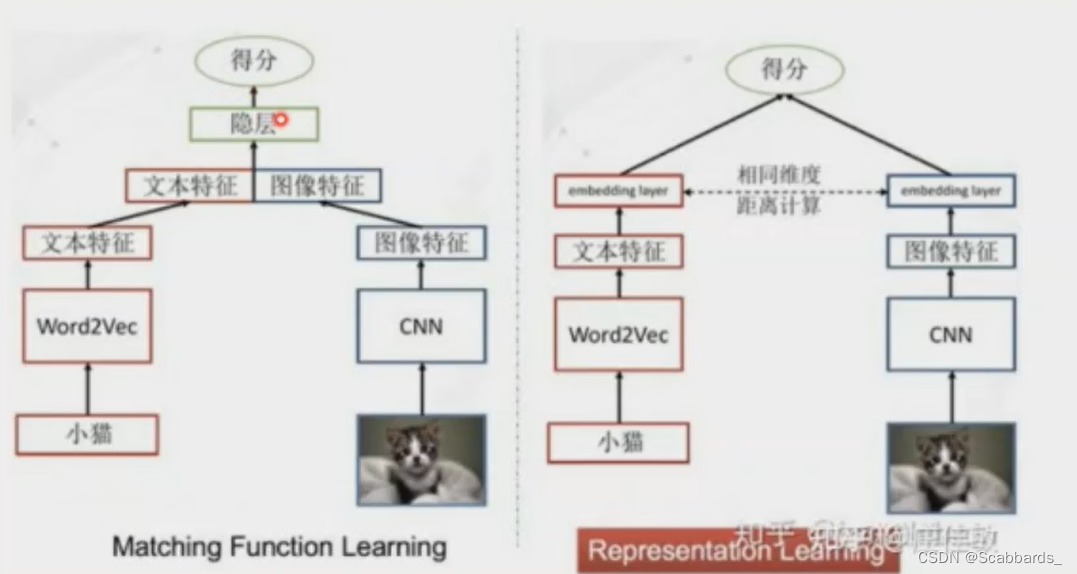
左侧跨模态相似性度量方法的主要思路是将图文特征进行融合,再经过隐层,目标是让隐层学习出可以度量跨模态相似度的函数。
右侧为公共空间特征学习方法,一般称为双塔结构是将图像和文本隐射到一个公共空间中得到分别得到多模态表示即最后一层的表示,从而可以直接使用cosine计算相似度,图像和文本相互独立没有交互,希冀于学习到一个优秀的表示就可以进行相似度度量。
研究热点和思路
其实主要做项目,研究做的少
1.针对某个特定领域提出一个新的跨模态检索数据集,如电商领域,遥感领域等,提供benchmark;
2. 跨模态信息对齐,如何引入合适的监督信号;
3. 跨模态信息如何更好的交互,如何把单塔和双塔结合 :
4. 跨模态检索难样本挖掘:
zeroshot分类
将类别标签通过一种prompt处理转换成一个text描述,然后计算图片与每个类别标签映射成的text之间的相似度,取相似度最高的作为分类标签

应用:类别属于开集(openset) 的分类任务
实现
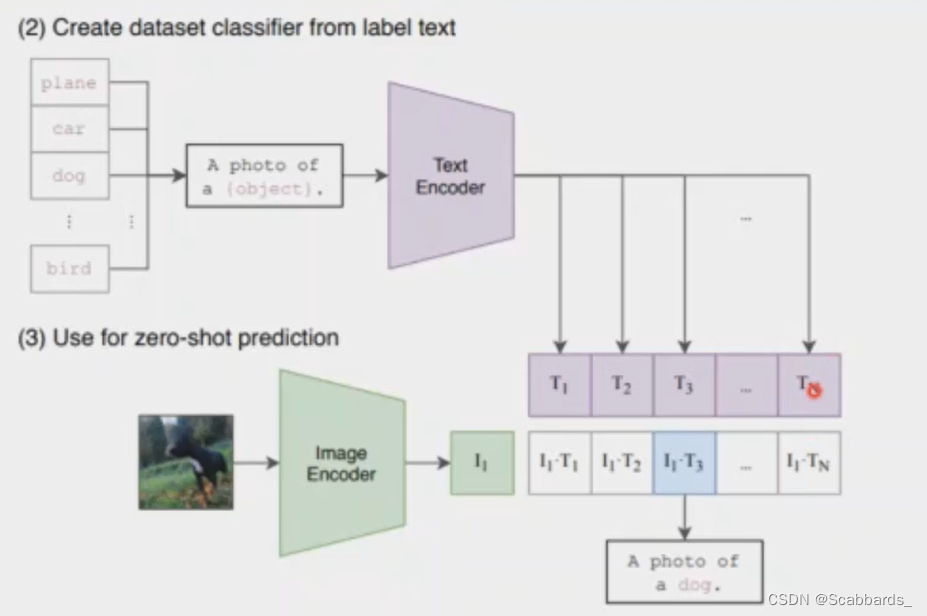
将类别标签通过一种prompt处理转换成一个text描述
然后计算图片与每个类别标签映射成的text之间的相似度,取相似度最高的作为分类标签
dog -> A photo of a dog
**提词器的设计也需要花费大量时间来调整,因为微小的措辞变化可能会对性能产生巨大影响(例如下图a,在“a photo of [CLASS]”中的[CLASS]前加个“a”直接涨了将近6个点?! !)
如何设计合适的prompt;
https://arxiv.org/abs/2109.01134
Image Captaining
任务: Encoder: 图片输入到Encoder中,得到视觉Features,Encoder可以采用CNN或Transformer; 视觉特征经过Decoder,解码成一个words序列,Decoder可以采用LSTM或者Transformer
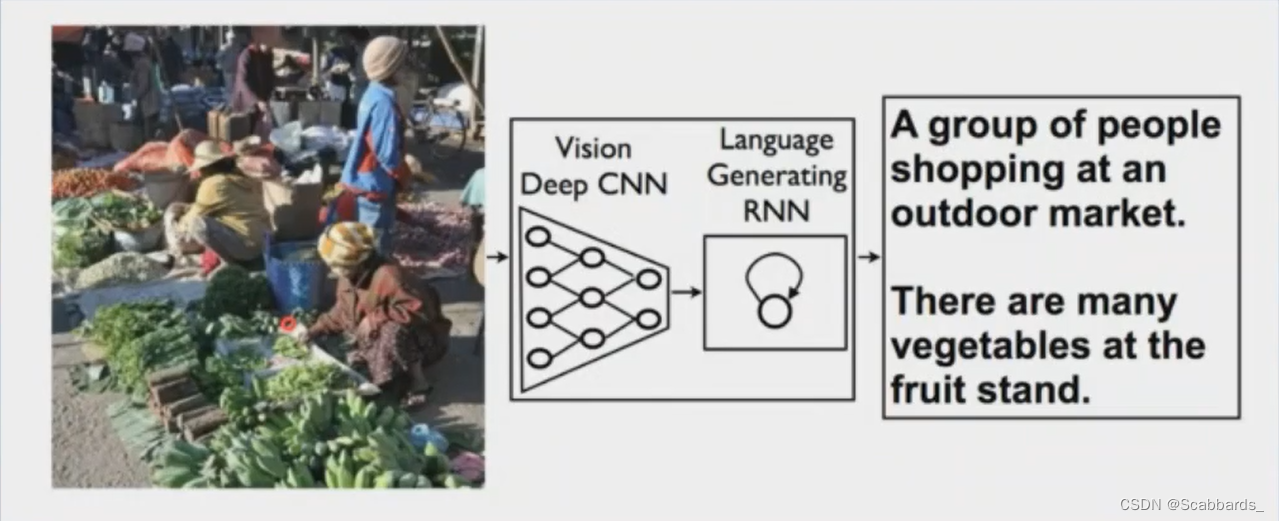
Encoder: 图片输入到Encoder中,得到视觉Features,Encoder可以采用CNN或Transformer。
Decoder:视觉特征经过Decoder,解码成一个words序列,Decoder可以采用LSTM或者Transformer。
实现
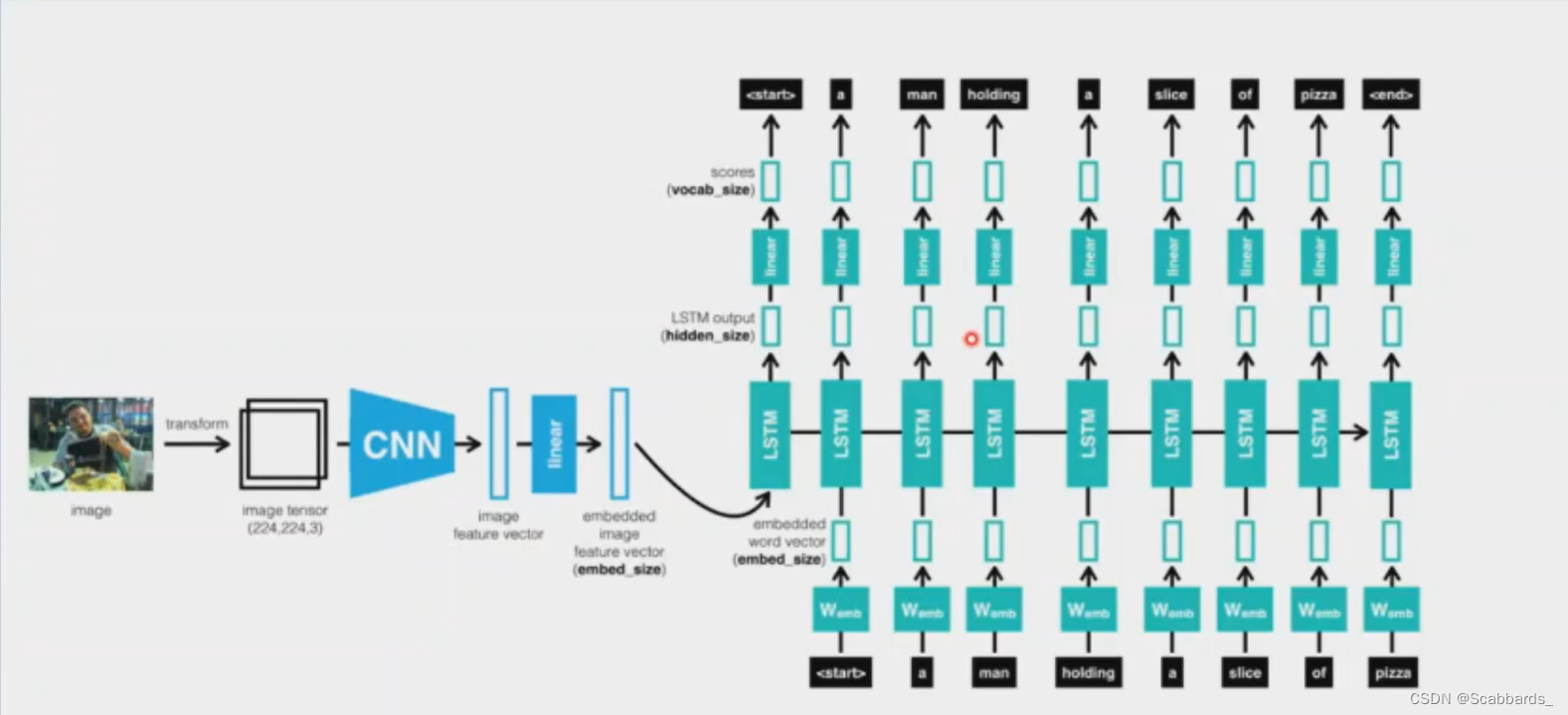
我们将所有输入作为序列传递给LSTM,序列如下所示:
1.首先从图像中提取特征向量
2.然后是一个单词,下一个单词等。
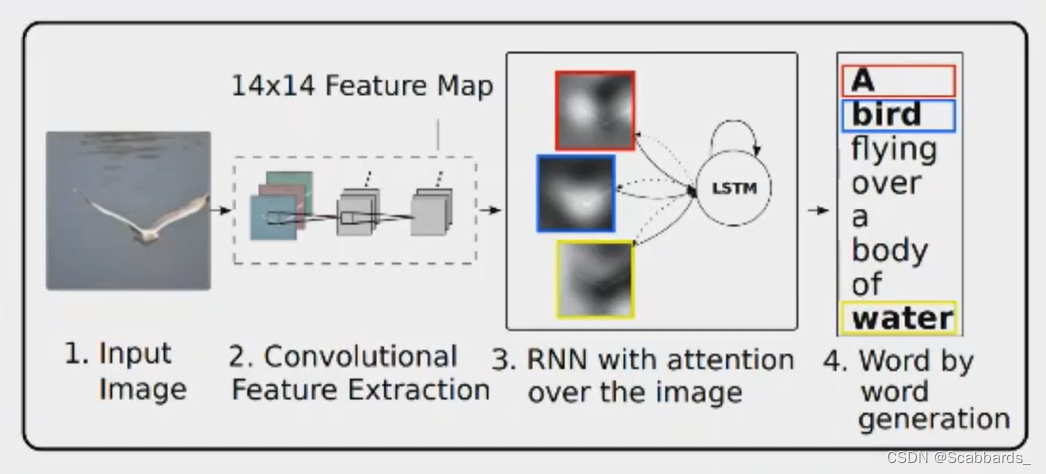
1)经过CNN进行卷积提取图片特征信息最终形成图片的特征图信息
2)attention对提取的特征图进行加强与抑制作为后续进入LSTM模型的输入数据,不同时刻的attention数据会受到上一时刻LSTM模型输出数据而有所调整
3)LSTM模型最终输出文本信息

**encoder阶段,文中使用的是CNN(卷积神经网络),用于提取特征图向量
为了得到特征向量与图片具体位置的对应,作者从浅层的卷积核中提取了特征而非全连接层,通过输入a aa的子集,这使得decoder能够选择性地专注于图片的某个部分

Decoder阶段:使用LSTM作为decoder,每一步生成一个词
缺点:
效率低
对于长时间的建模能力比较弱
研究热点和思路
1) 针对某个特定领域提出一个新的ImageCaptioning数据集,如电商领域(商品描述自动生成),遥感领域等,提供benchmark;
2) 设计更鲁棒的模型结构,主要是基于Transformer;
3) 语义对齐;