
无监督学习: Kaiming一作 动量对比(MoCO)论文笔记
最近在读Kaiming大神的Momentum Contrast (MoCo) 论文,里面提到"contrastive learning",所以顺着contrastive梳理几篇相关论文。Kaiming在MoCo的摘要里面最后一句提到“This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.” ,感觉最近学界和业界对unsupervised learning的热情和关注也越来越强烈。上一篇笔记self-supervised learning也是这方面相关,感兴趣的可以看之前的文章:bingo:Self-Supervised几篇相关paper。
Contrastive Learning
比较早期的一篇论文是 Yann LeCun在CVPR06年提出的。假设给定一组输入数据 ,我们的目标是找到一个函数
,来进行数据降维和特征学习。与传统监督学习使用
这种数据+标签的输入不同的是,这篇文章使用的是成对数据
作为输入。如果
和
是相似数据,则
;反之,
。
针对成堆数据,定义欧式距离: 。Contrastive Learning的损失函数针对相似数据和不相似数据采用不同形式:
,
其中 是相似数据损失函数(平方损失),
是不相似数据损失函数(margin loss),如图1。
拉近相似数据的距离,
推开不相似数据,使得他们的距离至少为m。
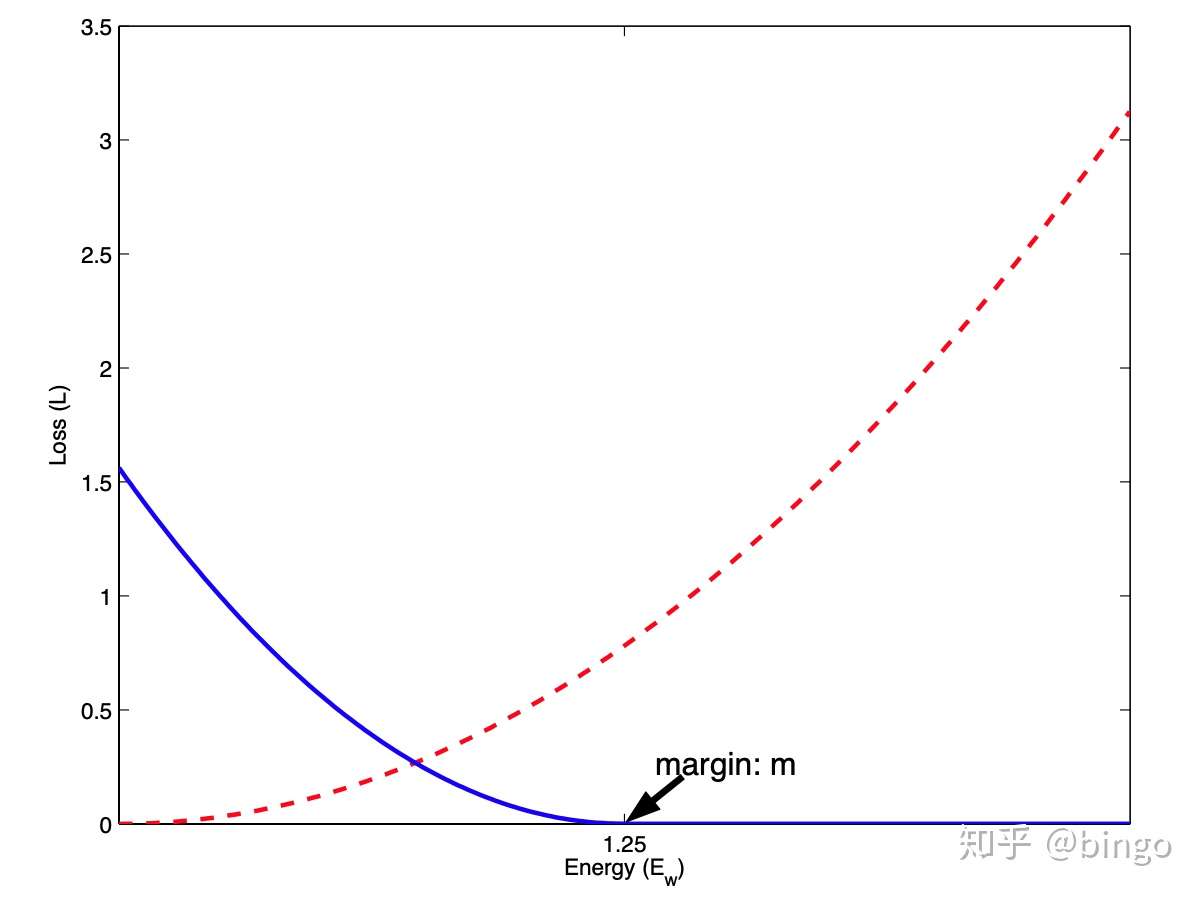 图1. Contrastive Learning两个损失函数图
图1. Contrastive Learning两个损失函数图
最后,整个损失函数定义如下:
。
基于这种思想的contrastive loss、triplet loss等方法在最近各种应用比如人脸、reid、图片分类检索都得到了广泛应用。
Contrastive Predictive Coding (CPC)
CPC是deepmind出品的非常有代表性的无监督学习方法,可以用于图片、文本、语音以及强化学习。
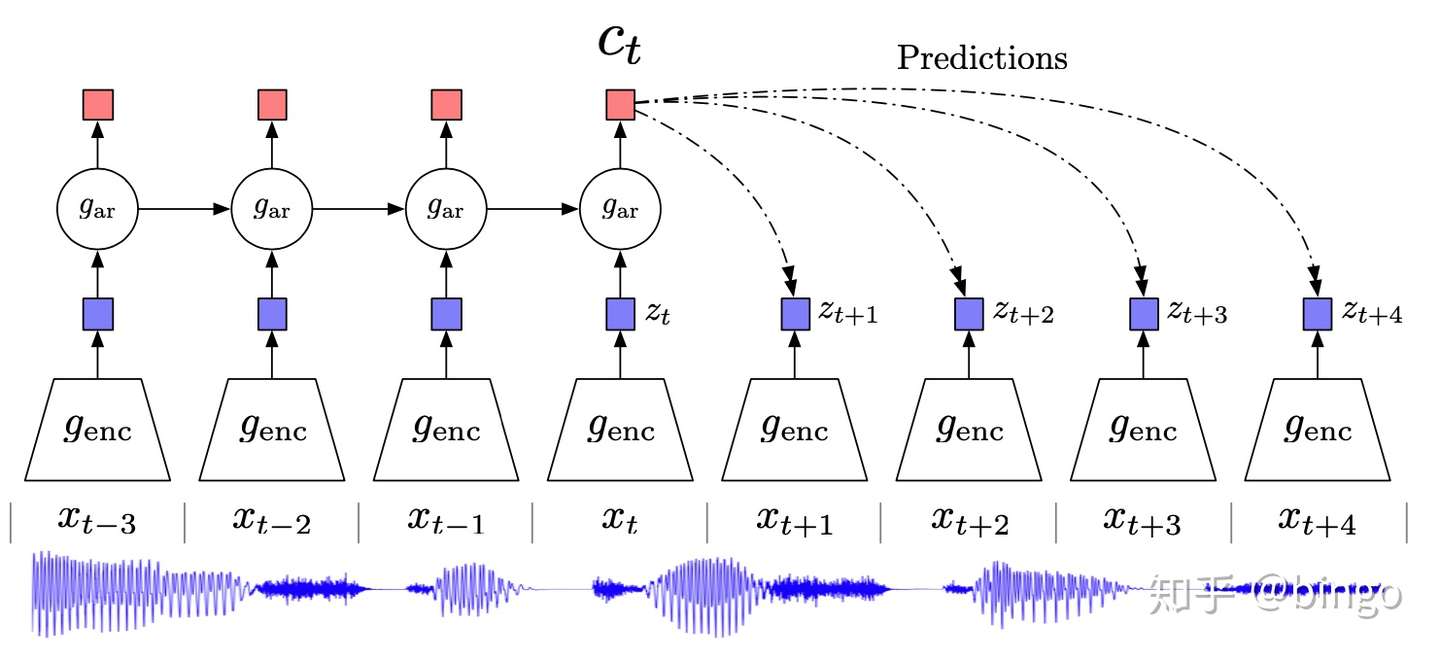 图2. CPC语音识别框架。通过context vector c_t预测未来序列,模型经过训练之后,c_t可以作为可靠的特征表示。
图2. CPC语音识别框架。通过context vector c_t预测未来序列,模型经过训练之后,c_t可以作为可靠的特征表示。
CPC的出发点是最大化context vector 和数据输入
之间的互信息(Mutual Information),使得
包含足够的原始数据信息,因而可以作为新的特征表示。互信息定义如下:
。
具体实现的时候,CPC使用一个函数来建模 里面的分数项:
,
有了 之后,CPC提出基于采样的InfoNCE(noise-contrastive estimation )损失函数:
。
每次从 采样一个正例样本,从
采样
个负例样本用于训练。
CPC的主要思想就是基于context信息的未来数据预测,以及通过采样的方式进行训练。InfoNCE这种基于采样高效训练方式,也在后面两篇文章中得到了应用。
Non-Parametric Instance Discrimination
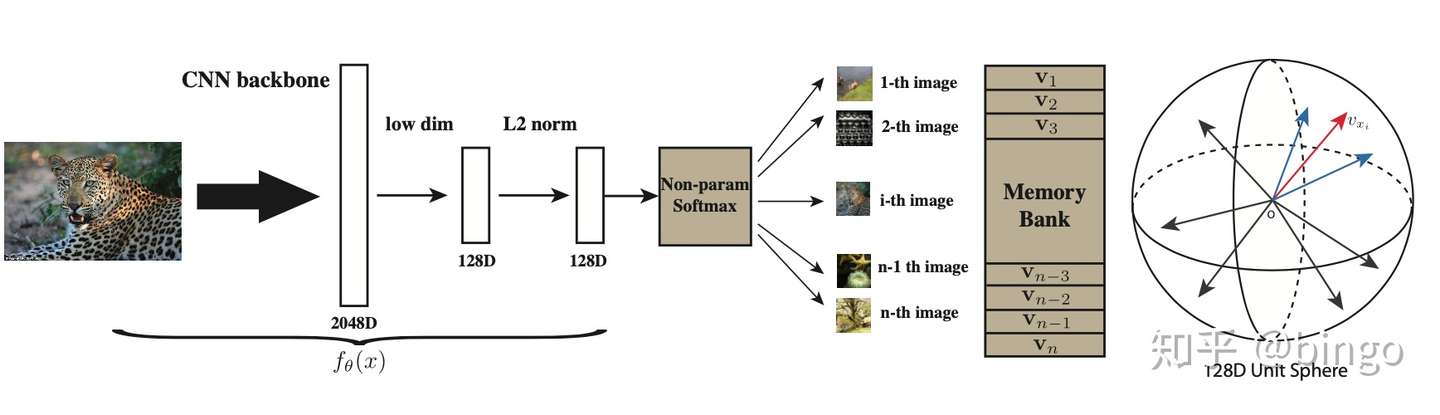 图3. 通过非参数softmax,将类别分类问题,转化成对每个样本进行分类。L2-norm之后的特征分布在球面空间。
图3. 通过非参数softmax,将类别分类问题,转化成对每个样本进行分类。L2-norm之后的特征分布在球面空间。
这篇文章的思路是将softmax分类转化成非参数化方法,进行每个样本的区分。正常softmax函数形式如下:
,
是分类器,
是单个样本特征。
通过替换 为
,并且限制
,可以得到非参数化的softmax函数:
,
是temperature参数,控制softmax的平滑程度。
非参数的softmax主要思路是每个样本特征除了可以作为特征之外,也可以起到分类器的作用。因为L2-norm之后的特征乘积本身就等于cos相似性, 。相似的思想在few-shot问题里也得到了应用,例如,Imprinted Weights和 Dynamic few-shot。
为了减少计算量,这篇文章提出了memory bank的概念:维护一个memory bank ,使用样本特征
来更新memory
。
另外,这篇文章也使用了NCE采样的方式加速训练,这里不展开细节。
最后一点是,这篇文章加入了近似正则化项 ,来使训练过程更加平滑和稳定。
Momentum Contrast (MoCo)
这篇文章延续了Kaiming一贯的风格简单有效,而且放出了简短的pytorch代码。
首先,从NLP的无监督例如BERT出发 ,作者指出Computer Vision的无监督学习需要建立dictionary:因为数据信号是连续的,分布在空间高维,并且不像NLP那样结构化。将现有的无监督方法归类为dictionary learning之后,作者提出建立dictionary依赖两个必要条件:1. large,dictionary的大小需要足够大,才能对高维、连续空间进行很好的表达;2. consistent,dictionary的key需要使用相同或者相似的encoder进行编码,这样query和key之间的距离度量才能够一致并且有意义。
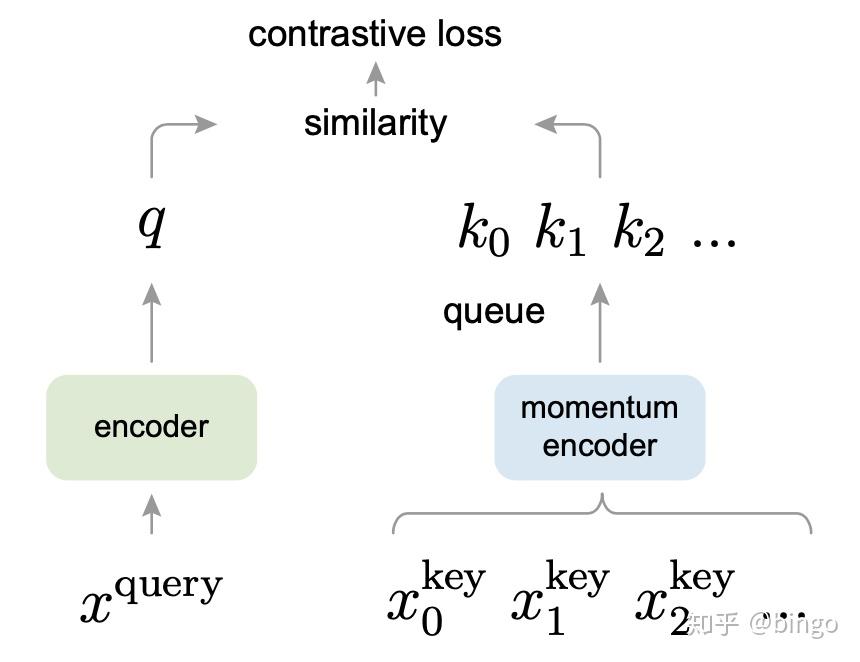 图4. Momentum Contrast框架
图4. Momentum Contrast框架
如图4,large这个条件是通过一个先进先出队列实现,consistent这个条件通过momentum更新的encoder来实现,类似于DL里面常用的exponential decay技巧。
MoCo的损失函数和上一篇文章一样,使用的是InfoNCE:
,
和
如上图所示,使用不同encoder进行编码。
队列:训练过程中维持一个队列,每个最新的mini-batch数据进入队列,最旧的数据出队列,保持dictionary的large和consistent特性。
Momentum更新:momentum encoder的更新规则如下:
。
方法对比(梯度回传):end-to-end方法同时对query和key的encoder进行梯度回传,能够保持参数处于最新状态,但是由于只有当前mini-batch数据,所以dictionary size不能太大,否则显存放不下。memory bank是上面一篇文章的方法,它可以维持比较大的dictionary size,但是由于每次使用到query之后才会对memory进行更新,无法保证key和query时刻处于一致状态。constrastive loss很好的解决了dictionary size和consistency两方面的问题。
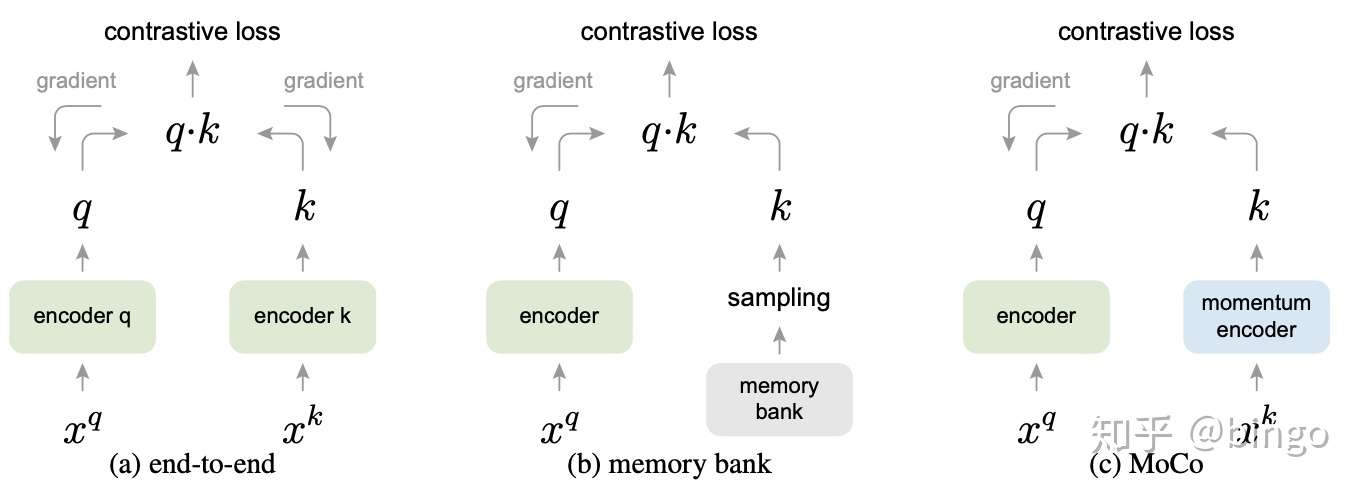 图5. 不同模型梯度回传模式
图5. 不同模型梯度回传模式
Pytorch代码:

本文涉及到的paper有:
- Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In CVPR, 2006
- Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv:1807.03748, 2018.
- Zhirong Wu, Yuanjun Xiong, Stella Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In CVPR, 2018.
- He, Kaiming, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. arXiv:1911.05722, 2019.
2 条评论
query和key所用的同一个编码器的参数不同,这样不会造成不一致吗?为什么会work呢?
我怎么觉得伪代码里面labels那里有点问题,就是应该是个[N,K+1]的矩阵,第一位为1,请问一下您觉的labels为什么是zeros(N)?