原文链接:https://arxiv.org/pdf/2010.04159.pdf
0.摘要
Deformable DETR是一种改进的物体检测模型,旨在解决DETR模型在收敛速度和特征空间分辨率方面的限制。DETR模型是近期提出的一种无需手动设计组件的物体检测方法,并且在性能方面表现出色。然而,由于Transformer注意力模块在处理图像特征映射时存在一定的限制,DETR模型存在收敛速度较慢和特征空间分辨率有限的问题。 为了缓解这些问题,我们提出了Deformable DETR模型。该模型的注意力模块仅关注参考点周围的一小组关键采样点。相对于DETR模型,Deformable DETR模型在性能方面表现更好,特别是对小目标的检测能力更强,而且只需10倍的训练迭代次数。 我们在COCO基准测试上进行了大量实验证明了我们方法的有效性。我们还在https://github.com/fundamentalvision/Deformable-DETR上发布了代码,供研究者们使用。 总之,Deformable DETR是一种改进的物体检测模型,通过改进注意力机制来提升模型性能。我们的实验证明了Deformable DETR在解决DETR模型收敛速度慢和特征空间分辨率有限问题方面的有效性。
1.引言
现代物体检测器通常使用许多手工设计的组件,如锚点生成、基于规则的训练目标分配和非极大值抑制(NMS)后处理。它们并不是完全端到端的。最近,Carion等人提出了DETR模型,以消除对这些手工设计组件的需求,并构建了第一个完全端到端的物体检测器,实现了非常有竞争力的性能。DETR模型采用了简单的架构,通过结合卷积神经网络(CNN)和Transformer编码器-解码器来利用Transformer的多功能和强大的关系建模能力来替代手工设计的规则,在适当设计的训练信号下进行训练。尽管DETR模型设计有趣且性能良好,但它也存在一些问题:
(1)相比现有物体检测器,DETR模型需要更长的训练迭代才能收敛。例如,在COCO基准测试中,DETR模型需要500个训练迭代才能收敛,这比Faster R-CNN模型慢10到20倍。
(2)DETR模型在检测小目标方面的性能相对较低。
现代物体检测器通常利用多尺度特征,其中小目标是从高分辨率特征图中检测出来的。然而,高分辨率特征图会导致DETR模型的复杂度不可接受。上述问题主要可以归因于Transformer模块在处理图像特征映射方面的不足。在初始化时,注意力模块对特征图中的所有像素几乎均匀分配注意力权重。需要长时间的训练迭代才能学习到注意力权重集中在稀疏有意义的位置上。另一方面,Transformer编码器中的注意力权重计算与像素数量的二次计算成正比。因此,处理高分辨率特征图具有非常高的计算和内存复杂度。在图像领域,可变形卷积是一种强大而高效的机制,用于关注稀疏的空间位置。它自然地避免了上述问题。然而,它缺乏元素关系建模机制,这是DETR模型成功的关键。
在本文中,我们提出了Deformable DETR,用于缓解DETR模型的收敛速度慢和复杂度高的问题。它结合了可变形卷积的稀疏空间采样和Transformer的关系建模能力。我们提出了可变形注意力模块,作为从所有特征图像素中提取出突出的关键元素的预过滤器,关注一小组采样位置。该模块可以自然地扩展到聚合多尺度特征,无需FPN的帮助。在Deformable DETR中,我们使用(多尺度)可变形注意力模块替代了处理特征图的Transformer注意力模块。Deformable DETR通过快速收敛和计算与内存效率,为我们利用各种端到端物体检测器提供了可能性。我们探索了一种简单而有效的迭代边界框细化机制来提高检测性能。我们还尝试了一个两阶段的Deformable DETR,其中区域提议也是由Deformable DETR的变体生成的,然后进一步输入解码器进行迭代边界框细化。在COCO基准测试上进行了大量实验证明了我们方法的有效性。与DETR相比,Deformable DETR可以在更少的训练迭代次数下取得更好的性能(尤其是对于小目标)。我们提出的两阶段Deformable DETR的变体可以进一步提高性能。代码已经在https://github.com/fundamentalvision/Deformable-DETR上发布。
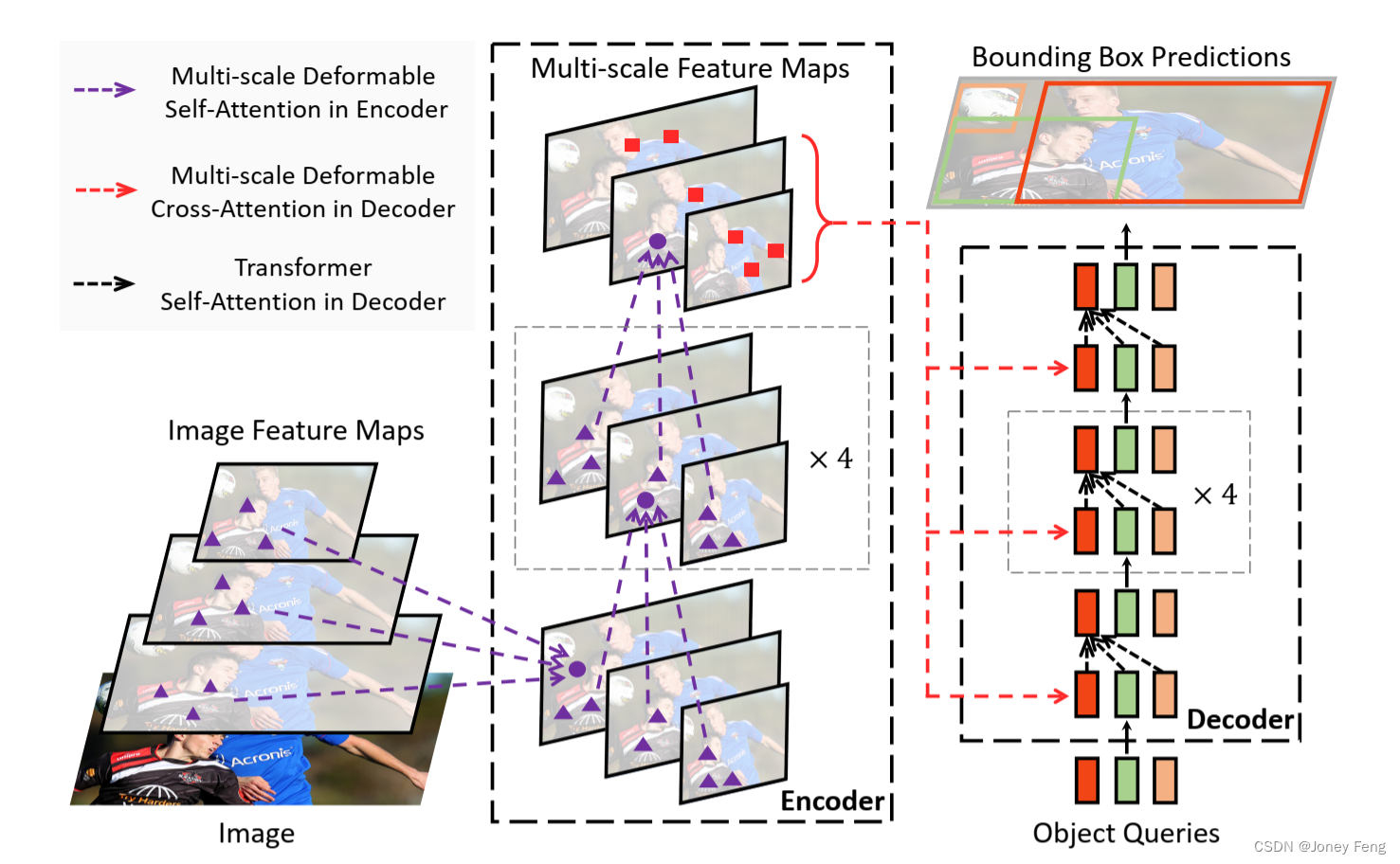
图1:所提出的Deformable DETR物体检测器的示意图。
2.相关工作
高效的注意力机制。Transformer(Vaswani et al., 2017)包括自注意力和交叉注意力机制。Transformer的一个最著名的问题是,在大量关键元素数量下,时间和内存复杂度很高,这在许多情况下阻碍了模型的可扩展性。最近,为解决这个问题进行了许多努力(Tay et al., 2020b),在实践中可以大致分为三类。 第一类是在关键元素上使用预定义的稀疏注意力模式。最直接的范例是将注意力模式限制在固定的局部窗口中。大多数工作(Liu et al., 2018a; Parmar et al., 2018; Child et al., 2019; Huang et al., 2019; Ho et al., 2019; Wang et al., 2020a; Hu et al., 2019; Ramachandran et al., 2019; Qiu et al., 2019; Beltagy et al., 2020; Ainslie et al., 2020; Zaheer et al., 2020)都遵循这种范例。尽管将注意力模式限制在局部邻域可以降低复杂度,但会丢失全局信息。为了补偿这一点,Child et al.(2019)、Huang et al.(2019)、Ho et al.(2019)、Wang et al.(2020a)在固定间隔上关注关键元素,从而显著增加关键元素的感受野。Beltagy et al.(2020)、Ainslie et al.(2020)、Zaheer et al.(2020)允许少量特殊标记可以访问所有的关键元素。Zaheer et al.(2020)、Qiu et al.(2019)还添加了一些预定义的稀疏注意力模式,直接关注远距离的关键元素。 第二类是学习数据相关的稀疏注意力。Kitaev et al.(2020)提出了基于局部敏感哈希(LSH)的注意力机制,将查询和关键元素分别哈希到不同的桶中。Roy et al.(2020)提出了类似的想法,其中k-means找出了最相关的关键元素。Tay et al.(2020a)学习块置换以实现块状稀疏注意力。 第三类是探索自注意力中的低秩特性。Wang et al.(2020b)通过在大小维度上进行线性投影,而不是通道维度上的投影,减少了关键元素的数量。Katharopoulos et al.(2020)和Choromanski et al.(2020)通过核化近似重新定义了自注意力的计算。 在图像领域中,高效的注意力机制的设计(例如Parmar et al.(2018)、Child et al.(2019)、Huang et al.(2019)、Ho et al.(2019)、Wang et al.(2020a)、Hu et al.(2019)、Ramachandran et al.(2019))仍然局限于第一类。尽管在理论上减少了复杂度,但Ramachandran et al.(2019)和Hu et al.(2019)承认,与相同的FLOPs相比,这些方法在实现上比传统的卷积要慢得多(至少慢3倍),这是由于内存访问模式的固有限制。另一方面,正如Zhu et al.(2019a)所讨论的,卷积的变种,例如可变形卷积(Dai et al., 2017; Zhu et al., 2019b)和动态卷积(Wu et al., 2019),也可以看作是自注意力机制。特别是,可变形卷积在图像识别中的效果比Transformer的自注意力要更有效和高效。同时,它缺乏元素关系建模机制。
我们提出的可变形注意力模块受到可变形卷积的启发,属于第二类。它只关注从查询元素的特征预测出的一小组固定的采样点。与Ramachandran et al.(2019);Hu et al.(2019)不同,可变形注意力在相同的FLOPs下只比传统卷积稍微慢一点。
目标检测中的多尺度特征表示。目标检测中的一个主要困难是有效地表示不同尺度的物体。现代目标检测器通常利用多尺度特征来适应这一点。作为开创性的工作之一,FPN(Lin et al., 2017a)提出了一种自顶向下的路径来组合多尺度特征。PANet(Liu et al., 2018b)在FPN之上进一步添加了一条自底向上的路径。Kong et al.(2018)通过全局注意力操作将所有尺度的特征进行融合。Zhao et al.(2019)提出了一个U形模块来融合多尺度特征。最近,NAS-FPN(Ghiasi et al., 2019)和Auto-FPN(Xu et al., 2019)通过神经网络架构搜索自动设计跨尺度连接。Tan et al.(2020)提出了BiFPN,它是PANet的一个重复简化版本。我们提出的多尺度可变形注意力模块可以通过注意力机制自然地聚合多尺度特征图,而无需使用这些特征金字塔网络的帮助。
3.回顾Transformers和DETR
Transformer中的多头注意力机制。Transformer(Vaswani et al., 2017)是一种基于注意力机制的网络架构,用于机器翻译。给定一个查询元素(例如输出句子中的目标词)和一组键元素(例如输入句子中的源词),多头注意力模块根据衡量查询-键对兼容性的注意力权重,自适应地聚合键的内容。为了使模型能够关注来自不同表示子空间和不同位置的内容,不同注意头的输出通过可学习的权重进行线性聚合。设q ∈ Ωq索引具有表示特征zq ∈ ℝC的查询元素,k ∈ Ωk索引具有表示特征xk ∈ ℝC的键元素,其中C是特征维度,Ωq和Ωk分别指定了查询和键元素的集合。然后通过以下方式计算多头注意力特征:
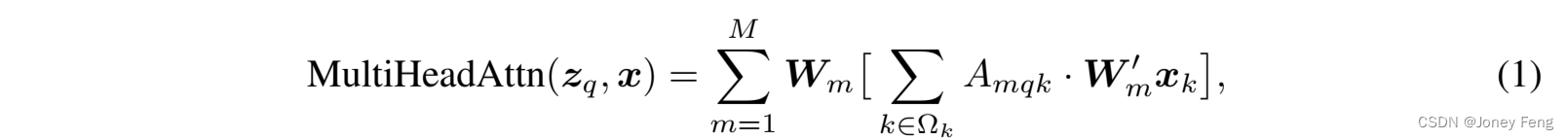
其中m索引了注意力头,Wm0 ∈ ℝCv×C和Wm ∈ ℝC×Cv是可学习的权重(默认情况下,Cv=C=M)。注意力权重Amqk被归一化为Pk2Ωk Amqk =1,其中Um;Vm ∈ ℝCv×C也是可学习的权重。为了消除不同的空间位置的歧义,表示特征zq和xk通常是元素内容和位置嵌入的连接/求和。Transformer存在两个已知问题。一是Transformer需要长时间的训练才能收敛。假设查询和键元素的数量分别为Nq和Nk。通常在适当的参数初始化下,Umzq和Vmxk遵循均值为0,方差为1的分布,这使得当Nk很大时,注意力权重Amqk≈N1k。这将导致输入特征的梯度模糊不清。因此,需要长时间的训练计划,以便注意力权重可以集中在特定的键上。在图像领域中,键元素通常是图像像素,Nk可能非常大,收敛过程很繁琐。另一方面,多头注意力的计算和内存复杂度可以非常高,因为存在大量的查询和键元素。式(1)的计算复杂度为O(NqC2 +NkC2 +NqNkC)。在图像领域中,查询和键元素都是像素,Nq =Nk C,复杂度主要由第三项决定,为O(NqNkC)。因此,多头注意力模块在特征图大小上存在二次复杂度增长的问题。
DETR(Carion et al.,2020)是建立在Transformer编码器-解码器架构之上的,结合了基于集合的匈牙利损失,通过二分图匹配强制每个真实边界框的唯一预测。我们简要地回顾一下网络架构如下。给定由CNN骨干(例如ResNet(He et al.,2016))提取的输入特征图x ∈ ℝC×H×W,DETR利用标准的Transformer编码器-解码器架构将输入特征图转换为一组对象查询的特征。在对象查询特征(由解码器生成)之上添加了一个3层的前馈神经网络(FFN)和一个线性投影作为检测头。FFN作为回归分支,用于预测边界框坐标b ∈ [0,1]4,其中b = fbx,by,bw,bhg编码了归一化的框中心坐标、框的高度和宽度(相对于图像尺寸)。线性投影作为分类分支,用于生成分类结果。对于DETR中的Transformer编码器,查询和键元素都是特征图中的像素。输入是ResNet特征图(带有编码的位置嵌入)。设H和W分别表示特征图的高度和宽度。自注意力的计算复杂度为O(H2W2C),随着空间大小的增长呈二次增长。对于DETR中的Transformer解码器,输入包括来自编码器的特征图和N个由可学习的位置嵌入表示的对象查询(例如,N = 100)。解码器中有两种类型的注意力模块,即交叉注意力模块和自注意力模块。在交叉注意力模块中,对象查询从特征图中提取特征。查询元素是对象查询,键元素是来自编码器的输出特征图。其中,Nq = N,Nk = H×W,交叉注意力的复杂度为O(HWC2 + NHWC)。复杂度随着特征图的空间大小线性增长。在自注意力模块中,对象查询相互作用,以捕捉它们之间的关系。查询和键元素都是对象查询。其中,Nq = Nk = N,自注意力模块的复杂度为O(2NC2 + N2C)。在对象查询的数量适中时,复杂度是可以接受的。
DETR是一种吸引人的目标检测设计,它消除了许多手工设计的组件的需求。然而,它也有自己的问题。这些问题主要可以归因于Transformer的注意力机制在处理图像特征图作为键元素时的不足之处:
(1) DETR在检测小物体方面的性能相对较低。现代目标检测器使用高分辨率的特征图来更好地检测小物体。然而,高分辨率的特征图会导致DETR中的Transformer编码器的自注意力模块的复杂度不可接受,因为它与输入特征图的空间大小呈二次复杂度增长。
(2) 与现代目标检测器相比,DETR需要更多的训练周期才能收敛。这主要是因为处理图像特征的注意力模块很难训练。例如,在初始化时,交叉注意力模块几乎在整个特征图上都是平均关注。然而,在训练结束时,注意力图被学习得非常稀疏,只关注物体的极端部分。似乎DETR需要一个长时间的训练计划来学习这种注意力图中的显著变化。
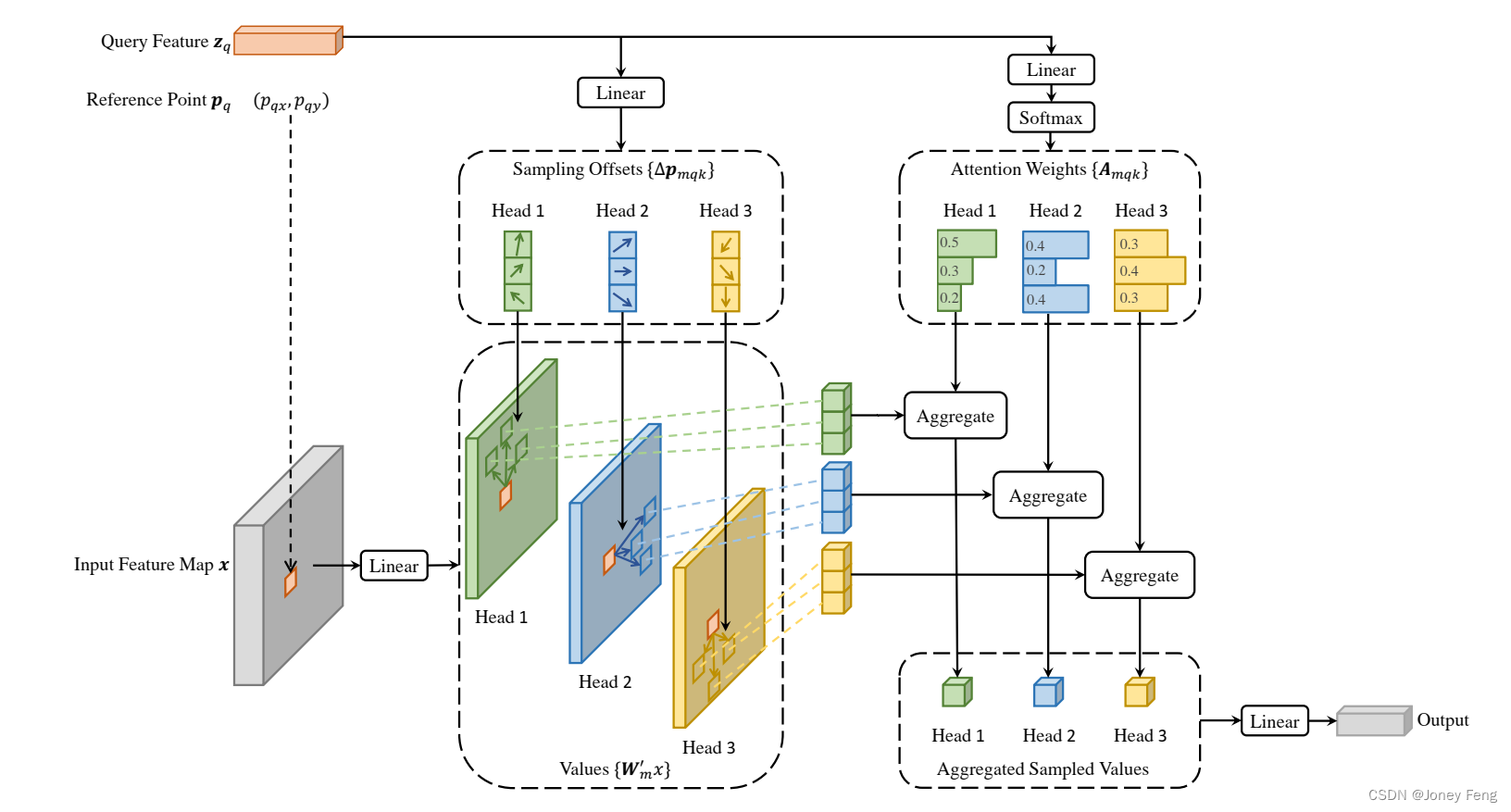 图2:提出的可变形注意力模块的示意图。
图2:提出的可变形注意力模块的示意图。
4.方法
4.1.用于端到端的可变性注意力机制
可变形注意力模块:将Transformer注意力应用于图像特征图的核心问题是它会遍历所有可能的空间位置。为了解决这个问题,我们提出了一个可变形注意力模块。受可变形卷积(Dai et al.,2017;Zhu et al.,2019b)的启发,可变形注意力模块仅关注参考点周围的一小组关键采样点,而不考虑特征图的空间大小,如图2所示。通过为每个查询分配一个固定数量的关键点,可以缓解收敛和特征空间分辨率方面的问题。给定一个输入特征图x ∈ ℝC×H×W,其中q索引一个具有内容特征zq和二维参考点pq的查询元素,可变形注意力特征通过以下方式计算: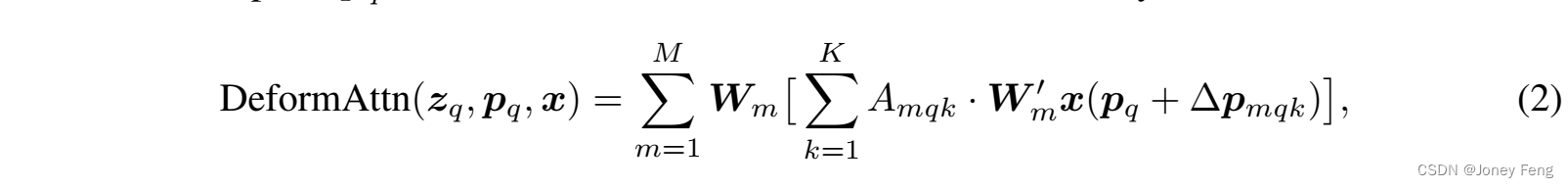 其中,m索引注意力头,k索引采样的关键点,K是总采样关键点数(K = HW)。∆pmqk和Amqk分别表示第m个注意力头中第k个采样点的采样偏移和注意力权重。标量注意力权重Amqk的取值范围为[0,1],通过PK k=1 Amqk = 1进行归一化。∆pmqk是2维实数,其取值范围没有约束。由于pq + ∆pmqk是分数值,计算x(pq + ∆pmqk)时采用双线性插值,与Dai et al.(2017)类似。∆pmqk和Amqk都是通过对查询特征zq进行线性投影获得的。在实现中,查询特征zq被输入到一个具有3MK通道的线性投影操作符中,其中前2MK通道编码了采样偏移∆pmqk,剩余的MK通道被输入到softmax操作符中以获得注意力权重Amqk。 可变形注意力模块旨在处理卷积特征图作为关键要素。设Nq为查询元素的数量。当MK相对较小时,可变形注意力模块的复杂度为O(2NqC2 + min(HWC2, NqKC2))(详见附录A.1)。当它应用于DETR编码器时,其中Nq = HW,复杂度变为O(HWC2),与空间尺寸成线性关系。当它作为DETR解码器中的交叉注意力模块时,其中Nq = N(N为目标查询的数量),复杂度变为O(NKC2),与空间尺寸HW无关。 多尺度可变形注意力模块。大多数现代目标检测框架受益于多尺度特征图(Liu et al.,2020)。我们提出的可变形注意力模块可以自然地扩展到多尺度特征图。设fxl为输入的多尺度特征图,其中xl∈ℝC×Hl×Wl。设p^q∈[0,1]2为每个查询元素q的归一化坐标的参考点,则多尺度可变形注意力模块应用如下:
其中,m索引注意力头,k索引采样的关键点,K是总采样关键点数(K = HW)。∆pmqk和Amqk分别表示第m个注意力头中第k个采样点的采样偏移和注意力权重。标量注意力权重Amqk的取值范围为[0,1],通过PK k=1 Amqk = 1进行归一化。∆pmqk是2维实数,其取值范围没有约束。由于pq + ∆pmqk是分数值,计算x(pq + ∆pmqk)时采用双线性插值,与Dai et al.(2017)类似。∆pmqk和Amqk都是通过对查询特征zq进行线性投影获得的。在实现中,查询特征zq被输入到一个具有3MK通道的线性投影操作符中,其中前2MK通道编码了采样偏移∆pmqk,剩余的MK通道被输入到softmax操作符中以获得注意力权重Amqk。 可变形注意力模块旨在处理卷积特征图作为关键要素。设Nq为查询元素的数量。当MK相对较小时,可变形注意力模块的复杂度为O(2NqC2 + min(HWC2, NqKC2))(详见附录A.1)。当它应用于DETR编码器时,其中Nq = HW,复杂度变为O(HWC2),与空间尺寸成线性关系。当它作为DETR解码器中的交叉注意力模块时,其中Nq = N(N为目标查询的数量),复杂度变为O(NKC2),与空间尺寸HW无关。 多尺度可变形注意力模块。大多数现代目标检测框架受益于多尺度特征图(Liu et al.,2020)。我们提出的可变形注意力模块可以自然地扩展到多尺度特征图。设fxl为输入的多尺度特征图,其中xl∈ℝC×Hl×Wl。设p^q∈[0,1]2为每个查询元素q的归一化坐标的参考点,则多尺度可变形注意力模块应用如下: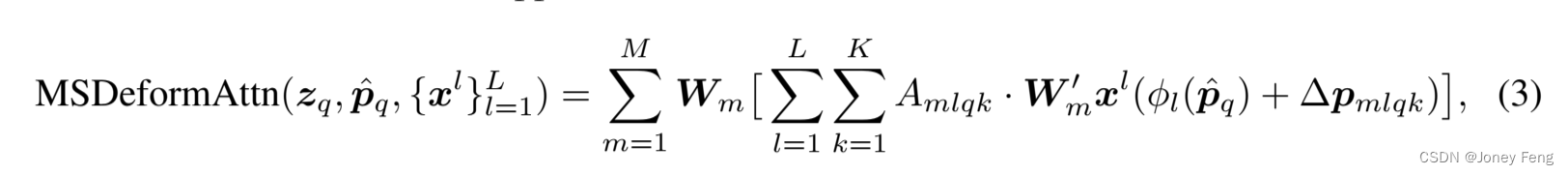 其中,m索引注意力头,l索引输入特征级别,k索引采样点。∆pmlqk和Amlqk分别表示第l个特征级别和第m个注意力头中第k个采样点的采样偏移和注意力权重。标量注意力权重Amlqk通过PL l=1 PK k=1 Amlqk = 1进行归一化。在这里,我们使用归一化坐标p^q∈[0,1]2来清楚地表示尺度公式,其中归一化坐标(0,0)和(1,1)分别表示图像的左上角和右下角。方程3中的函数φl(p^q)将归一化坐标p^q重新缩放到第l个级别的输入特征图上。 多尺度可变形注意力与之前的单尺度版本非常相似,唯一的区别是它从多尺度特征图中采样LK个点,而不是从单尺度特征图中采样K个点。当L = 1,K = 1,并且Wm0∈RCv×C被固定为单位矩阵时,所提出的注意力模块退化为可变形卷积(Dai et al.,2017)。可变形卷积设计用于单尺度输入,每个注意力头仅关注一个采样点。然而,我们的多尺度可变形注意力从多尺度输入中考虑多个采样点。所提出的(多尺度)可变形注意力模块也可以看作是Transformer注意力的一种高效变体,其中引入了可变形采样位置的预过滤机制。当采样点遍历所有可能的位置时,所提出的注意力模块等价于Transformer注意力。
其中,m索引注意力头,l索引输入特征级别,k索引采样点。∆pmlqk和Amlqk分别表示第l个特征级别和第m个注意力头中第k个采样点的采样偏移和注意力权重。标量注意力权重Amlqk通过PL l=1 PK k=1 Amlqk = 1进行归一化。在这里,我们使用归一化坐标p^q∈[0,1]2来清楚地表示尺度公式,其中归一化坐标(0,0)和(1,1)分别表示图像的左上角和右下角。方程3中的函数φl(p^q)将归一化坐标p^q重新缩放到第l个级别的输入特征图上。 多尺度可变形注意力与之前的单尺度版本非常相似,唯一的区别是它从多尺度特征图中采样LK个点,而不是从单尺度特征图中采样K个点。当L = 1,K = 1,并且Wm0∈RCv×C被固定为单位矩阵时,所提出的注意力模块退化为可变形卷积(Dai et al.,2017)。可变形卷积设计用于单尺度输入,每个注意力头仅关注一个采样点。然而,我们的多尺度可变形注意力从多尺度输入中考虑多个采样点。所提出的(多尺度)可变形注意力模块也可以看作是Transformer注意力的一种高效变体,其中引入了可变形采样位置的预过滤机制。当采样点遍历所有可能的位置时,所提出的注意力模块等价于Transformer注意力。
可变形Transformer编码器。我们用所提出的多尺度可变形注意力模块替换DETR中处理特征图的Transformer注意力模块。编码器的输入和输出都是具有相同分辨率的多尺度特征图。在编码器中,我们从ResNet(He et al.,2016)的C3到C5阶段的输出特征图中提取多尺度特征图fxlgL l=1 −1(L =4)(经过1×1卷积变换),其中Cl的分辨率比输入图像低2l。最低分辨率的特征图xL通过对最终的C5阶段进行3×3步长2的卷积获得,表示为C6。所有的多尺度特征图都有C =256个通道。请注意,不使用FPN(Lin et al.,2017a)中的自顶向下结构,因为我们所提出的多尺度可变形注意力本身可以在多尺度特征图之间交换信息。多尺度特征图的构建也在附录A.2中进行了说明。第5.2节的实验证明,添加FPN不会提高性能。在编码器中应用多尺度可变形注意力模块时,输出与输入具有相同的分辨率。键和查询元素都来自于多尺度特征图的像素。对于每个查询像素,参考点是它本身。为了确定每个查询像素所在的特征级别,我们在特征表示中添加了一个尺度级别嵌入,表示为el,除了位置嵌入之外。与具有固定编码的位置嵌入不同,尺度级别嵌入felgL l=1是随机初始化的,并与网络一起进行训练。
可变形Transformer解码器。解码器中有交叉注意力和自注意力模块。两种类型的注意力模块的查询元素都是对象查询。在交叉注意力模块中,对象查询从特征图中提取特征,其中键元素来自编码器的输出特征图。在自注意力模块中,对象查询之间相互交互,其中键元素来自对象查询。由于我们提出的可变形注意力模块是为了处理卷积特征图作为键元素而设计的,我们只将每个交叉注意力模块替换为多尺度可变形注意力模块,而不改变自注意力模块。对于每个对象查询,通过可学习的线性投影和sigmoid函数,从其对象查询嵌入中预测参考点的二维归一化坐标p^q。因为多尺度可变形注意力模块提取参考点周围的图像特征,我们让检测头相对于参考点预测边界框的相对偏移量,以进一步减少优化难度。参考点被用作框中心的初始猜测。检测头相对于参考点预测边界框的相对偏移量。具体细节请参阅附录A.3。通过在DETR中用可变形注意力模块替换Transformer注意力模块,我们建立了一个高效且快速收敛的检测系统,称为Deformable DETR(见图1)。
4.2.关于Deformable DETR模型的补充改进和变体
Deformable DETR通过其快速收敛性、计算和内存效率,为我们开拓了利用各种改进和变体的端到端目标检测器的可能性。由于篇幅有限,我们在这里只介绍这些改进和变体的核心思想。具体的实现细节请参阅附录A.4。 迭代边界框细化。这受到光流估计中的迭代细化方法(Teed&Deng,2020)的启发。我们建立了一个简单有效的迭代边界框细化机制来改善检测性能。在这里,每个解码器层基于前一层的预测对边界框进行细化。 两阶段可变形DETR。在原始DETR中,解码器中的对象查询与当前图像无关。受两阶段目标检测器的启发,我们探索了一种Deformable DETR的变体,用于生成区域建议作为第一阶段。生成的区域建议将作为对象查询输入到解码器中进行进一步细化,形成一个两阶段的Deformable DETR。在第一阶段,为了获得高召回率的建议,多尺度特征图中的每个像素都将作为对象查询。然而,直接将像素设置为对象查询会给解码器中的自注意力模块带来不可接受的计算和内存开销,其复杂度随查询数量的平方增长。为了避免这个问题,我们移除了解码器,形成了一个仅有编码器的Deformable DETR用于区域建议生成。在其中,每个像素被分配为一个对象查询,直接预测一个边界框。然后,选择得分最高的边界框作为区域建议。在将区域建议输入到第二阶段之前,不进行非极大值抑制。
5.实验
数据集。我们在COCO 2017数据集(Lin等人,2014)上进行实验。我们的模型在训练集上进行训练,并在验证集和测试开发集上进行评估。实现细节。ImageNet(Deng等人,2009)预训练的ResNet-50(He等人,2016)被用作骨干网络。在去除了FPN(Lin等人,2017a)的情况下提取多尺度特征图。默认情况下,可变形注意力的M = 8和K = 4。可变形Transformer编码器的参数在不同的特征层之间共享。其他超参数设置和训练策略主要遵循DETR(Carion等人,2020),只是用具有2倍损失权重的Focal Loss(Lin等人,2017b)用于边界框分类,并且将对象查询的数量从100增加到300。为了进行公平比较,我们还报告了经过这些修改的DETR-DC5的性能,表示为DETR-DC5+。默认情况下,模型训练50个epochs,学习率在第40个epoch时按0.1的因子衰减。与DETR(Carion等人,2020)一样,我们使用Adam优化器(Kingma&Ba,2015)进行模型训练,基础学习率为2×10^(-4),β1 = 0.9,β2 = 0.999,并且权重衰减为10^(-4)。用于预测对象查询参考点和采样偏移的线性投影的学习率乘以0.1的因子。运行时间在NVIDIA Tesla V100 GPU上评估。
5.1.与DETR的比较
如表1所示,与Faster R-CNN + FPN相比,DETR需要更多的训练轮次才能收敛,并且在检测小物体方面的性能较低。与DETR相比,Deformable DETR在较少的训练轮次下取得了更好的性能(尤其是对小物体)。详细的收敛曲线如图3所示。通过迭代边界框细化和两阶段范式的辅助,我们的方法可以进一步提高检测准确性。我们提出的Deformable DETR与Faster R-CNN + FPN和DETR-DC5具有相当的FLOPs。但是运行时间要快得多(1.6倍)比DETR-DC5,只比Faster R-CNN + FPN慢25%。DETR-DC5的速度问题主要是由于Transformer注意力中的大量内存访问。我们提出的可变形注意力可以缓解这个问题,但代价是无序的内存访问。因此,它仍然比传统的卷积稍慢一些。
表1:Deformable DETR与DETR在COCO 2017验证集上的比较。DETR-DC5+表示使用Focal Loss和300个对象查询的DETR-DC5。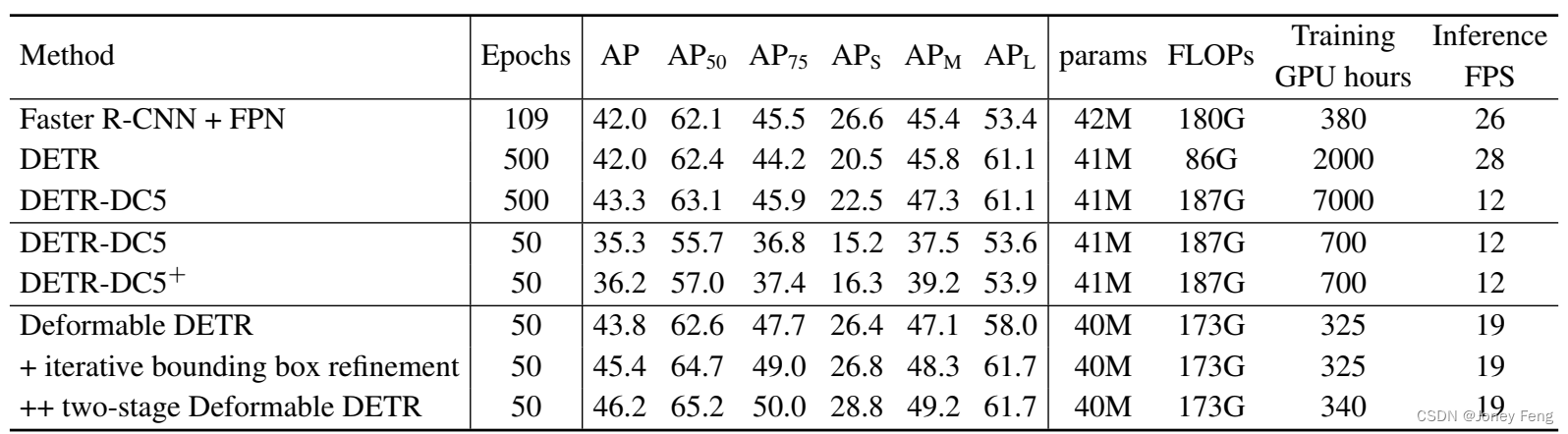

图3:Deformable DETR和DETR-DC5在COCO 2017验证集上的收敛曲线。对于Deformable DETR,我们通过改变学习率降低的轮次(在AP分数跃升的位置)来探索不同的训练计划。
5.2.关于可变形注意力的消融研究
表2展示了对所提出的可变形注意力模块的各种设计选择的消融实验结果。与单尺度输入相比,使用多尺度输入可以有效提高检测准确性,平均精度(AP)提高了1.7%,尤其在小物体上的平均精度(APS)提高了2.9%。增加采样点数K可以进一步提高0.9%的AP。使用多尺度可变形注意力,允许不同尺度级别之间的信息交换,可以额外提高1.5%的AP。因为已经采用了跨级特征交换,添加FPN不会提高性能。当不应用多尺度注意力且K=1时,我们的(多尺度)可变形注意力模块退化为可变形卷积,准确性明显降低。
5.3.与当前主流方法的比较
表3将所提出的方法与其他最先进的方法进行了比较。在表3中,我们的模型都使用了迭代边界框细化和两阶段机制。使用ResNet-101和ResNeXt-101(Xie等人,2017),我们的方法分别达到了48.7 AP和49.0 AP,没有任何额外的操作。通过使用带有DCN(Zhu等人,2019b)的ResNeXt-101,准确性提高到了50.1 AP。通过使用额外的测试时增强,所提出的方法达到了52.3 AP。
表2:可变形注意力在COCO 2017验证集上的消融实验结果。“MS inputs”表示使用多尺度输入。“MS attention”表示使用多尺度可变形注意力。K是每个特征层上每个注意力头的采样点数。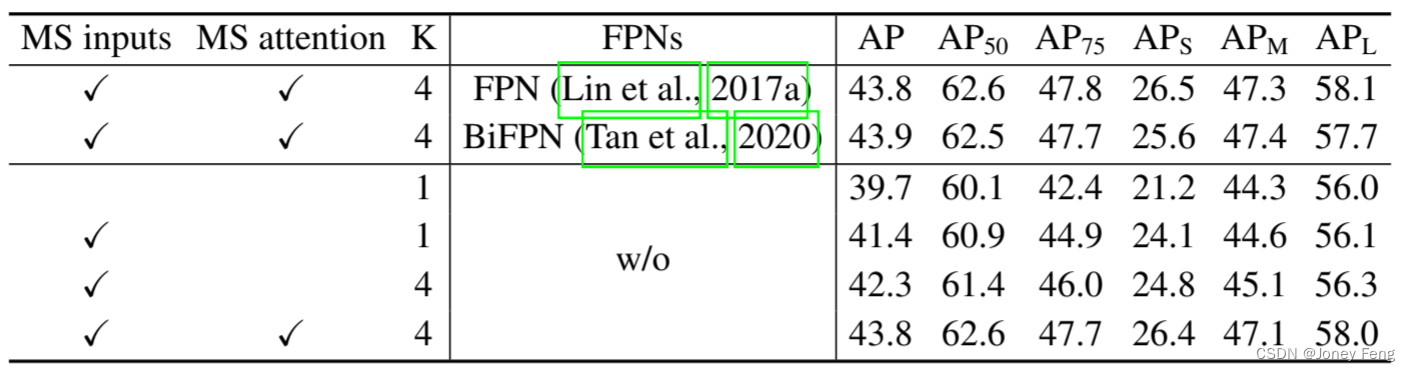
表3:Deformable DETR与COCO 2017 test-dev集上最先进方法的比较。“TTA”表示测试时增强,包括水平翻转和多尺度测试。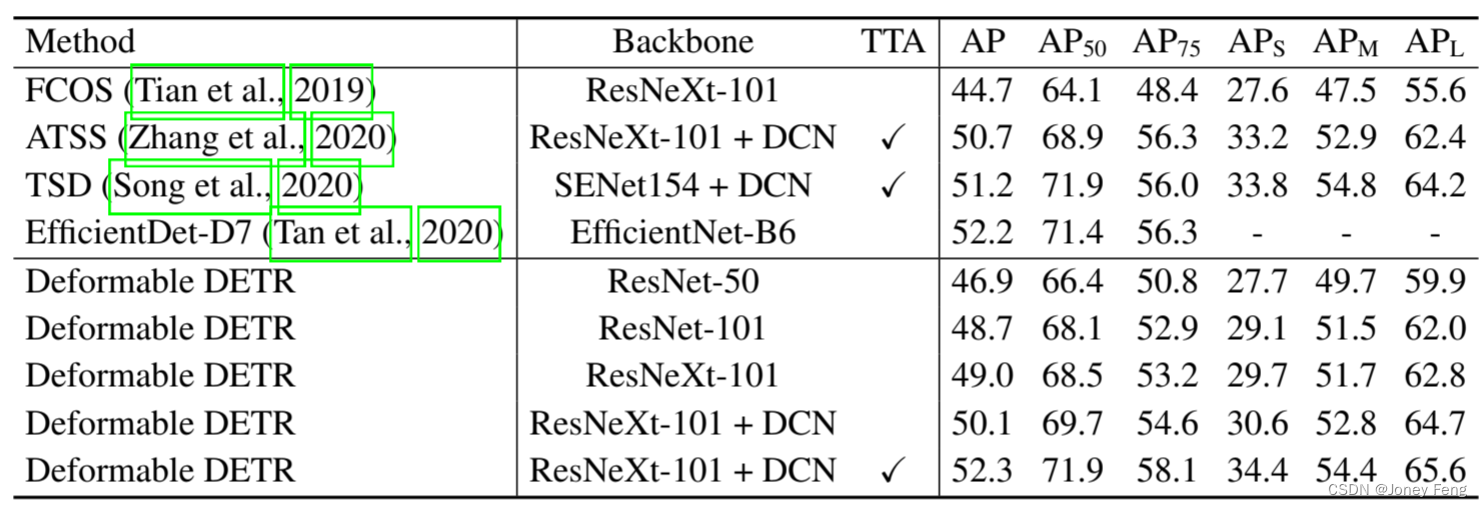
6.结论
Deformable DETR是一种高效且快速收敛的端到端目标检测器。它使我们能够探索更有趣和实用的端到端目标检测器的变体。Deformable DETR的核心是(多尺度)可变形注意力模块,它是一种在处理图像特征图时高效的注意力机制。我们希望我们的工作能够为探索端到端目标检测开辟新的可能性。 致谢:本工作得到了中国国家重点研发计划(2020AAA0105200)、北京人工智能研究院和中国国家自然科学基金(批准号U19B2044和批准号61836011)的支持。
7.参考文献
Joshua Ainslie,Santiago Ontanon,Chris Alberti,Philip Pham,Anirudh Ravula和Sumit Sanghai等人。在转换器中编码长而结构化的数据。arXiv预印本arXiv:2004.08483,2020年。
Iz Beltagy,Matthew E Peters和Arman Cohan。Longformer:长文档转换器。arXiv预印本arXiv:2004.05150,2020年。
Nicolas Carion,Francisco Massa,Gabriel Synnaeve,Nicolas Usunier,Alexander Kirillov和Sergey Zagoruyko。使用转换器的端到端目标检测。在ECCV,2020年。
Rewon Child,Scott Gray,Alec Radford和Ilya Sutskever。使用稀疏转换器生成长序列。arXiv预印本arXiv:1904.10509,2019年。
Krzysztof Choromanski,Valerii Likhosherstov,David Dohan,Xingyou Song,Jared Davis,Tamas Sarlos,David Belanger,Lucy Colwell和Adrian Weller。通过线性可扩展的长上下文转换器进行蛋白质掩码语言建模。arXiv预印本arXiv:2006.03555,2020年。
Jifeng Dai,Haozhi Qi,Yuwen Xiong,Yi Li,Guodong Zhang,Han Hu和Yichen Wei。可变形卷积网络。在ICCV,2017年。
Jia Deng,Wei Dong,Richard Socher,Li-Jia Li,Kai Li和Li Fei-Fei。ImageNet:一个大规模的层次结构图像数据库。在CVPR,2009年。
Golnaz Ghiasi,Tsung-Yi Lin和Quoc V Le。Nas-fpn:学习可扩展的特征金字塔架构用于目标检测。在CVPR,2019年。
Kaiming He,Xiangyu Zhang,Shaoqing Ren和Jian Sun。深度残差学习用于图像识别。在CVPR,2016年。
Jonathan Ho,Nal Kalchbrenner,Dirk Weissenborn和Tim Salimans。多维转换器中的轴向注意力。arXiv预印本arXiv:1912.12180,2019年。
Han Hu,Zheng Zhang,Zhenda Xie和Stephen Lin。用于图像识别的局部关系网络。在ICCV,2019年。
Zilong Huang,Xinggang Wang,Lichao Huang,Chang Huang,Yunchao Wei和Wenyu Liu。CCNet:交叉注意力用于语义分割。在ICCV,2019年。
Angelos Katharopoulos,Apoorv Vyas,Nikolaos Pappas和François Fleuret。转换器是RNN:具有线性注意力的快速自回归转换器。arXiv预印本arXiv:2006.16236,2020年。
Diederik P Kingma和Jimmy Ba。Adam:一种随机优化方法。在ICLR,2015年。
Nikita Kitaev,Łukasz Kaiser和Anselm Levskaya。Reformer:高效转换器。在ICLR,2020年。
Tao Kong,Fuchun Sun,Chuanqi Tan,Huaping Liu和Wenbing Huang。深度特征金字塔重构用于目标检测。在ECCV,2018年。
Tsung-Yi Lin,Michael Maire,Serge Belongie,James Hays,Pietro Perona,Deva Ramanan,Piotr Dollar和C Lawrence Zitnick。Microsoft COCO:上下文中的常见对象。在ECCV,2014年。
Tsung-Yi Lin,Piotr Dollar,Ross Girshick,Kaiming He,Bharath Hariharan和Serge Belongie。特征金字塔网络用于目标检测。在CVPR,2017年。
Tsung-Yi Lin,Priya Goyal,Ross Girshick,Kaiming He和Piotr Dollar。密集目标的焦点损失。
附录A.1 变形注意力的复杂度
假设查询元素的数量是Nq,在变形注意力模块中(参见方程2),计算采样坐标偏移∆pmqk和注意力权重Amqk的复杂度为O(3NqCMK)。给定采样坐标偏移和注意力权重,计算方程2的复杂度为O(NqC2 + NqKC2 + 5NqKC),其中5NqKC中的5是由于双线性插值和注意力中的加权和。另一方面,我们也可以在采样之前计算W0mW0mx,因为它与查询无关,计算方程2的复杂度将变为O(NqC2 + HWC2 + 5NqKC)。因此,变形注意力的总体复杂度为O(NqC2 + min(HWC2;NqKC2)+ 5NqKC + 3NqCMK)。在我们的实验中,M = 8,K ≤ 4和C = 256,默认情况下,因此5K + 3MK < C,并且复杂度为O(2NqC2 + min(HWC2;NqKC2))。 附录A.2 构建用于变形DETR的多尺度特征图 如第4.1节所讨论并在图4中所示,编码器fxlgL l=1−1(L=4)的输入多尺度特征图是从ResNet的C3到C5阶段的输出特征图中提取的(通过1×1卷积进行转换)。最低分辨率的特征图xL是通过在最终的C5阶段进行3×3步幅2卷积获得的。需要注意的是,我们不使用FPN(Lin et al.,2017a),因为我们提出的多尺度变形注意力本身可以在多尺度特征图之间交换信息。
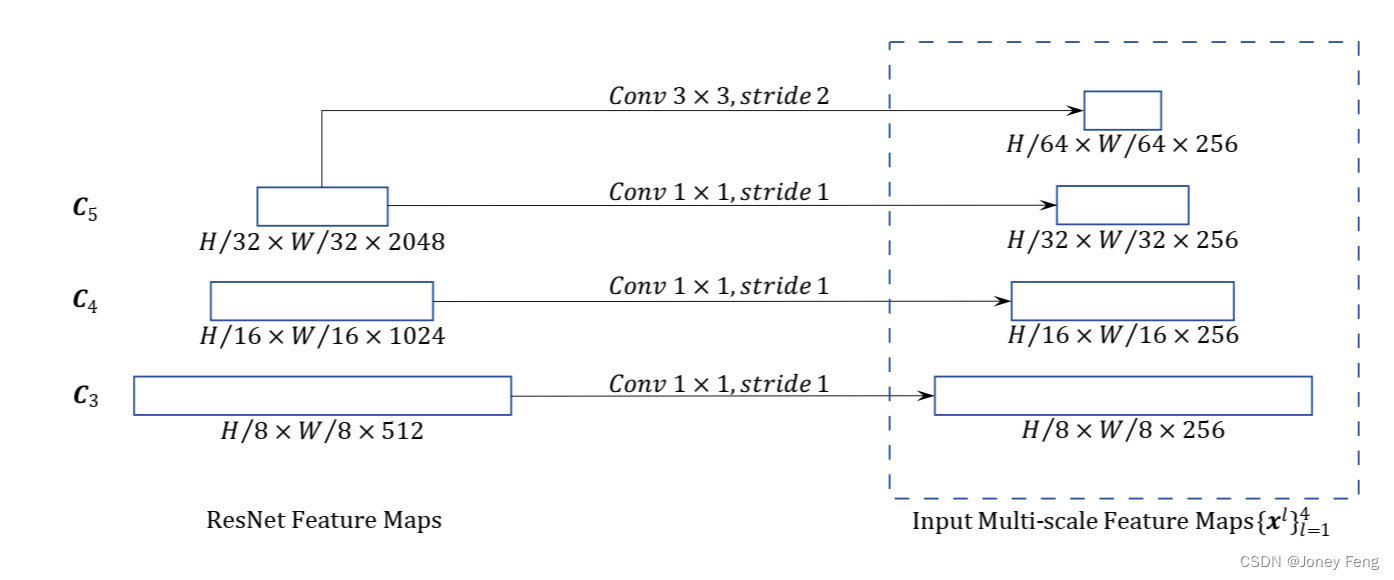
图4:构建用于变形DETR的多尺度特征图。
附录A.3 变形DETR中的边界框预测 由于多尺度变形注意力模块提取了参考点周围的图像特征,我们设计了检测头来预测边界框,以参考点为相对偏移量,以进一步降低优化难度。参考点被用作盒子中心的初始猜测。检测头预测相对于参考点的偏移量p^q = (^pqx; p^qy),即b^q = f(σ(bqx) + σ^(-1)(^pqx); σ(bqy) + σ^(-1)(^pqy); σ(bqw); σ(bqh)),其中bqfx;y;w;hg ∈ R由检测头预测。σ和σ^(-1)分别表示sigmoid函数和反sigmoid函数。σ和σ^(-1)的使用是为了确保b^是标准化的坐标,即^bq ∈ [0,1]^4。这样,学习到的解码器注意力将与预测的边界框具有强相关性,也加速了训练的收敛。
附录A.5 Deformable DETR关注的内容:为了研究Deformable DETR在给出最终检测结果时关注的内容,我们绘制了每个最终预测项(即物体中心的x/y坐标、物体边界框的宽度/高度、该物体的类别分数)相对于图像中每个像素的梯度范数,如图5所示。根据Taylor定理,梯度范数可以反映输出相对于像素扰动的变化程度,因此可以显示模型主要依赖于哪些像素来预测每个项。可视化结果表明,Deformable DETR关注物体的极端点来确定其边界框,这与DETR(Carion et al., 2020)中的观察结果类似。具体而言,Deformable DETR关注物体的左/右边界来预测x坐标和宽度,以及上/下边界来预测y坐标和高度。与DETR(Carion et al., 2020)不同的是,我们的Deformable DETR还关注物体内部的像素来预测其类别。
图5:最终检测结果中每个项(物体中心的坐标(x;y),物体边界框的宽度/高度w=h,该物体的类别得分c)相对于输入图像I中每个像素的梯度范数。
附录A.6 多尺度可变形注意力的可视化:为了更好地理解学习到的多尺度可变形注意力模块,我们在编码器和解码器的最后一层中可视化了采样点和注意力权重,如图6所示。为了易读性,我们将来自不同分辨率特征图的采样点和注意力权重合并到一张图片中。与DETR(Carion et al., 2020)类似,实例在可变形DETR的编码器中已经分离开来。而在解码器中,我们的模型关注整个前景实例,而不仅仅是极端点,这与DETR(Carion et al., 2020)中的观察结果不同。结合图5中k@I @c k的极端点可视化,我们可以猜测这是因为我们的可变形DETR不仅需要极端点,还需要内部点来确定物体类别。可视化还表明,所提出的多尺度可变形注意力模块可以根据前景物体的不同尺度和形状来调整其采样点和注意力权重。
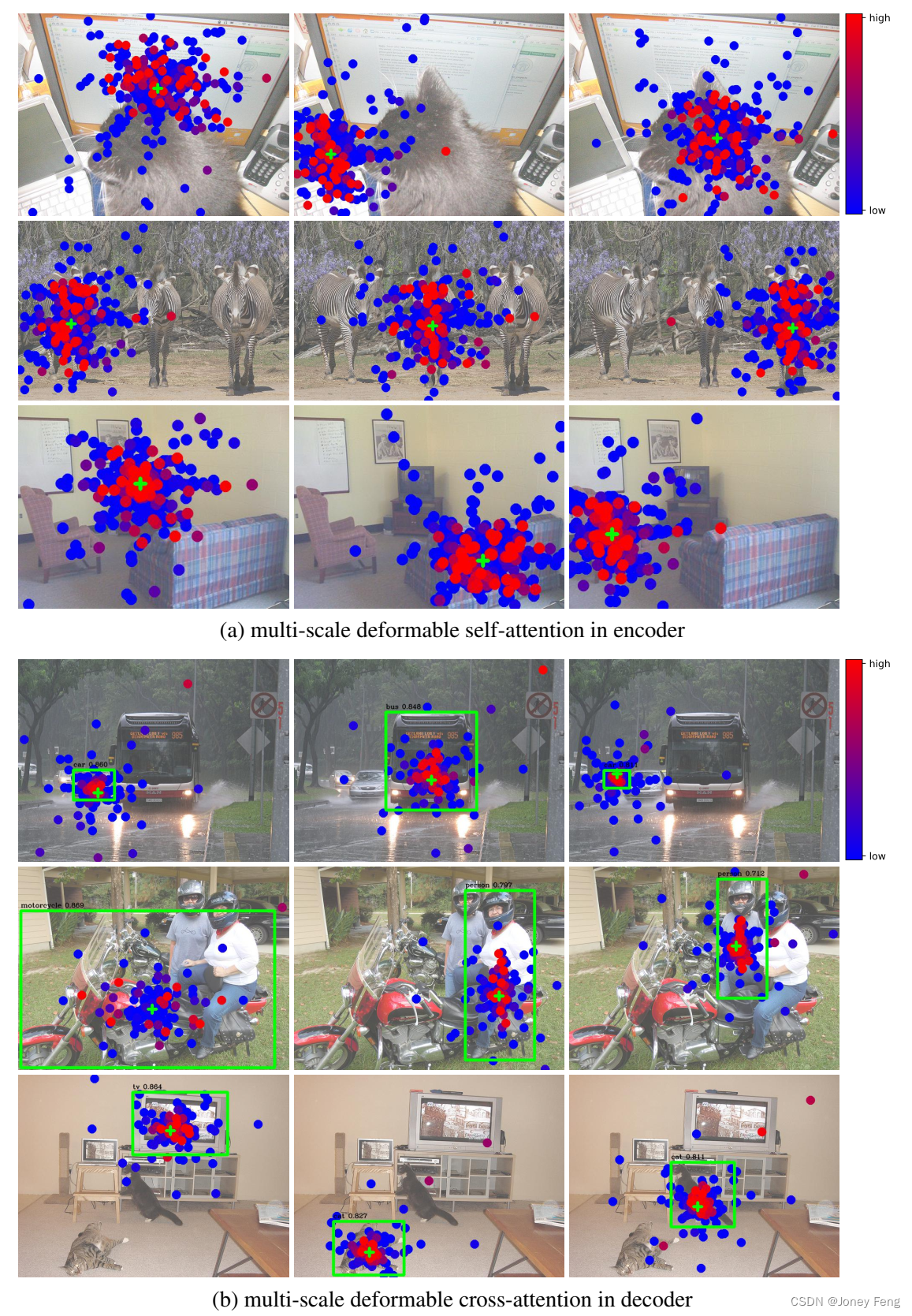
图6:多尺度可变形注意力的可视化。为了易读性,我们将来自不同分辨率特征图的采样点和注意力权重绘制在一张图片中。每个采样点都标记为一个填充的圆圈,其颜色表示其对应的注意力权重。参考点显示为绿色的十字标记,它也等同于编码器中的查询点。在解码器中,预测的边界框显示为绿色的矩形,类别和置信度得分则显示在其上方。
附录A.7 符号表:论文中的符号表。符号 描述 m 注意力头的索引 l 关键元素的特征级别索引 q 查询元素的索引 k 关键元素的索引 Nq 查询元素的数量 Nk 关键元素的数量 M 注意力头的数量 L 输入特征级别的数量 K 每个注意力头每个特征级别中抽样的关键元素数量 C 输入特征的维度 Cv 每个注意力头的特征维度 H 输入特征图的高度 W 输入特征图的宽度 Hl 第l个特征级别的输入特征图的高度 Wl 第l个特征级别的输入特征图的宽度 Amqk 第m个头中qth查询到kth关键元素的注意力权重 Amlqk 第m个头中第l个特征级别的qth查询到kth关键元素的注意力权重 zq 第q个查询元素的输入特征 pq 第q个查询元素的参考点的二维坐标 p^q 第q个查询元素的归一化二维参考点坐标 x 输入特征图(关键元素的输入特征)xk 第k个关键元素的输入特征 xl 第l个特征级别的输入特征图 ∆pmqk 第m个头中qth查询到kth关键元素的采样偏移量 ∆pmlqk 第m个头中第l个特征级别的qth查询到kth关键元素的采样偏移量 Wm 第m个头的输出投影矩阵 Um 第m个头的输入查询投影矩阵 Vm 第m个头的输入关键元素投影矩阵 W 0 m 第m个头的输入值投影矩阵 φl(p^) 第l个特征级别中p^的非归一化二维坐标 exp 指数函数 σsigmoid函数 σ−1 sigmoid函数的逆函数