时间序列预测是我们实际项目场景中经常碰到的一类主题。在这篇文章里简单介绍一下我们观远在时序问题上的一些探索和心得体会。
时序问题的定义和分类
顾名思义,时间序列指的是按照时间顺序先后发生的数据序列,在此基础上,我们会对这个序列做各种任务,如分类,聚类,异常检测,预测等。本文主要的关注点会放在时间序列的预测类任务上。
时序预测的用途非常的广泛,如气象降雨,交通流量,金融,商业公司的销售经营,医学上的药物反应,各类系统的运作负荷,等等方面都可以见到相关的应用场景。麦肯锡的一个关于 AI 场景价值的研究中也把时序类问题的价值排在了各类数据形式中的第二位:
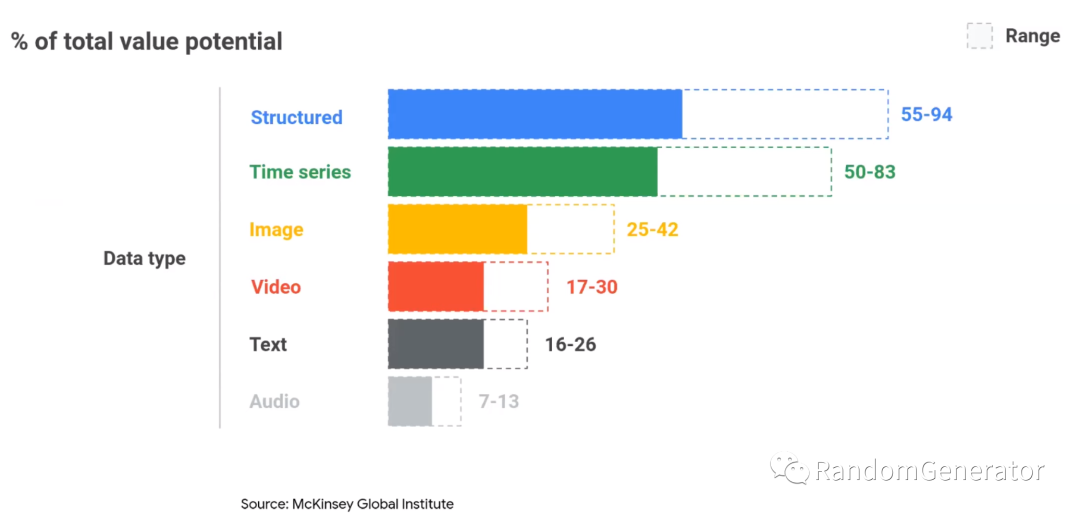
下图是 Google 内部的各种时序预测的场景,看起来是不是应用范围一点也不亚于搜广推呢 :)

在很多研究中,会把时间序列进一步区分成单变量时间序列和多变量时间序列。例如单支股票的价格走势是一个单变量时序问题,但某支股票的价格波动除了自身因素,也会受到其它股票价格波动的影响,甚至是股票市场外的一些其它信息影响,所以我们需要通盘考虑来做预测,就形成了所谓的多变量时间序列问题。
简单来设想,我们只要把输入和输出的维度从一维变到高维就能处理多变量的时序问题了。但实际问题中,情况往往更为复杂。例如股票市场中可能会有新股上市,也可能会有退市,这个多维本身可能也会有数量的波动。如果考虑所有曾经出现过的股票信息,那么维度可能就会很高,但序列本身长度却相对受到局限,不像 NLP 场景中有海量的序列数据可以做各种数据增强,自监督学习,迁移学习的玩法,一般很难达到比较好的预测效果。
因此,业界在实际做时序问题时,通常采用的手段还是对每一个序列来做训练学习(但不一定是单独模型),把相关的动态,静态信息通过特征的方式输入到模型中。比如股票代码就不再是维度上的区别,而是做成一个类别变量,输入到模型中进行训练。这也是目前较为主流的问题形式和对应的实践方式,后面我们会再展开详述。
时序预测的效果检验
在介绍具体预测方法之前,我们先来看下如何检验时序预测的效果。
Metric
在指标方面,作为一个回归问题,我们可以使用 MAE,MSE 等方式来计算。但这类 metric 受到具体预测数值区间范围不同,展现出来的具体误差值区间也会波动很大。比如预测销量可能是几万到百万,而预测车流量可能是几十到几百的范围,那么这两者预测问题的 MAE 可能就差距很大,我们很难做多个任务间的横向比较。
所以实际问题中,我们经常会使用对数值量纲不敏感的一些 metric,尤其是 SMAPE 和 WMAPE 这两种:
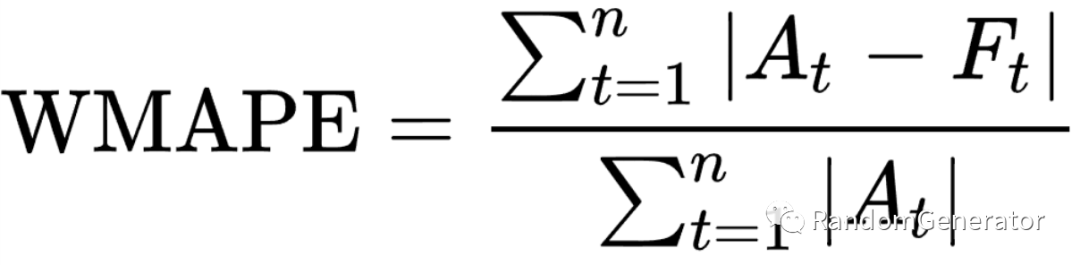
这类误差计算方法在各类不同的问题上都会落在 0~1 的区间范围内,方便我们来进行跨序列的横向比较,十分方便。
在实际项目中我们还会经常发现,很多真实世界的时序预测目标,如销量,客流等,都会形成一个类似 tweedie 或 poisson 分布的情况。如果我们用 WMAPE 作为指标,模型优化目标基本可以等价为 MAE(优化目标为中位数),则整体的预测就会比平均值小(偏保守)。在很多业务问题中,预测偏少跟预测偏多造成的影响是不同的,所以实际在做优化时,我们可能还会考察整体的预测偏差(总量偏大或偏小),进而使用一些非对称 loss 来进行具体的优化。
交叉验证
我们在一开始接触机器学习的交叉验证概念时,教科书上一般都是对数据做随机的 split。不过在时序问题上,需要特别注意不能做随机 split,而需要在时间维度上做前后的 split,以保证与实际预测应用时的情况一致。比如用 1-6 月的数据做训练,在 7 月数据上做验证,用 2-7 月的数据做训练,在 8 月数据上做验证,以此类推。
后面在介绍机器学习方法时,我们也会再次提到类似的思想,即使用一段时间窗口的历史数据作为模型输入,对未来的一个时间窗口做预测输出和效果验证。这是时序问题中极为重要的一点。
稳定性
时序问题整体来说是个难度很大的问题,纵观 Kaggle 相关比赛,能够稳定在时序问题上拿金的大佬几乎没有,但其它像 CV,分类等问题上排名靠前的 GM,熟悉的名字比例明显就会高很多。这其中很大一部分原因来自于真实世界中的时序问题基本都是不符合 i.i.d 假设的,世界变幻莫测,如果我们能准确预知未来,那还做什么算法工程师 :)
正因如此,除了验证准确率的 metric,我们还需要考察模型的稳定性。例如在不同的序列之间的精度波动,不同预测 step 之间的精度波动,以及不同时间点的精度波动等。综合表现稳定的模型往往才是业务上的更优选择。
传统时序方法
从这一节开始,我们介绍具体的预测方法。
时间序列问题有着悠久的研究历史,如果去看这方面的相关资料,会找到很多经典的时间序列检测,预处理,和预测方法。例如很多时序模型都要求序列本身是平稳的,如果没有达到检测要求的话就需要通过差分操作来转换为平稳序列。这方面的资料比较多,理论也略显复杂,我们在这里不做太多展开,只列举几种比较常用的方法。
移动平均
在业界做过几个时序预测场景的同学,经常会发出这样的感慨:“MA 好强啊”。移动平均虽然是一个很简单的方法,但往往在很多实际问题中有着非常良好的表现,是一个不容易打败的 baseline。
最简单的移动平均,就是使用过去 n 个时间点的观测值的平均,作为下一个点的预测。
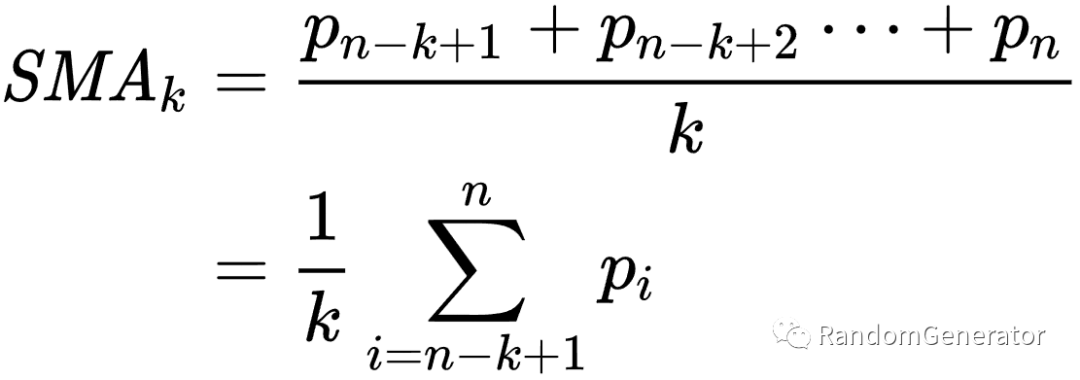
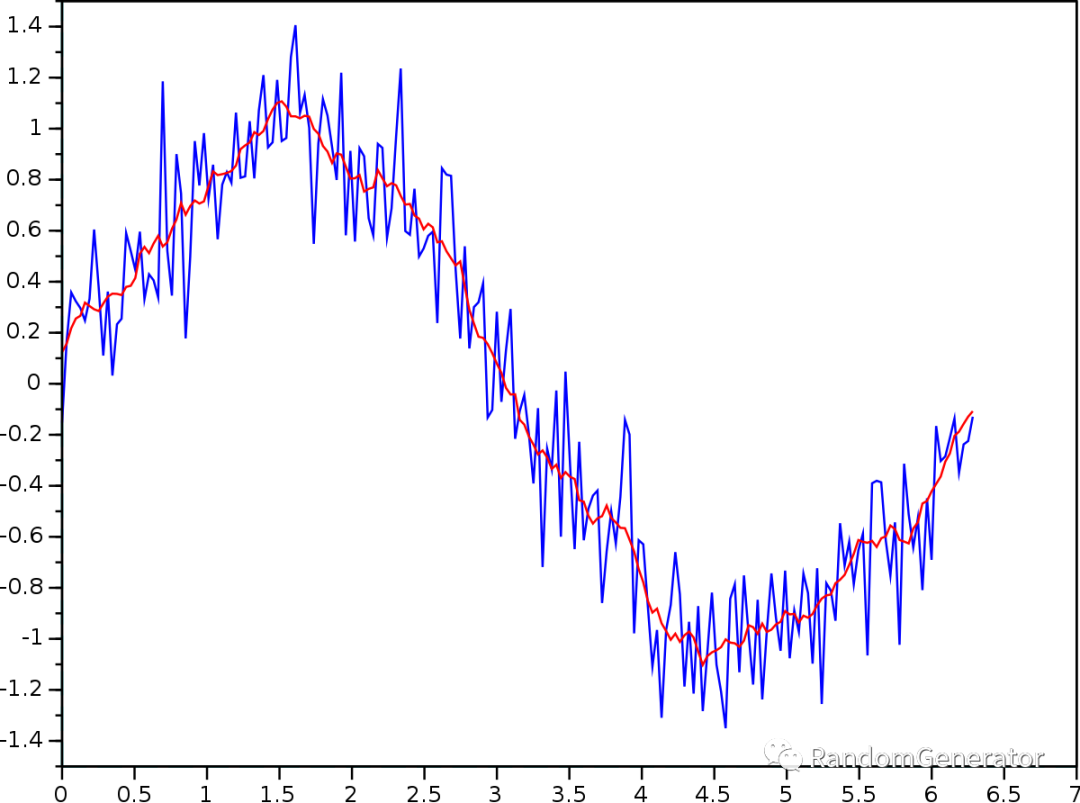
可以看到移动平均给出的预测非常的“靠谱”,如果把 MA 的参考范围缩小,比如只考虑前一个时间点,我们很容易就能得出一个看起来非常准确,但只是“滞后”了一点的预测效果。但是这个滞后并不是那么好修复的,这也是很多初学者经常有的一个疑问。
在最基础的移动平均基础上,我们还可以有加权移动平均,指数移动平均等方法。当年 M4 比赛的冠军方法是由 Uber 提出的 ES-RNN,其中 ES 就是指数平滑的缩写 :)
移动平均在具体实现时也比较方便,例如在 pandas 里就有 rolling[1], ewm[2] 等方法,可以直接进行计算。在 sql 中也可以用 window function[3] 的方法来快速实现。相对其它方法来说,移动平均的计算速度很快,在海量序列场景下也能够适用。
不过如果要做多步预测,移动平均方法就会显得有些困难了。
ARIMA
时序预测领域最知名的算法,应该没有之一。其中 AR 部分可以类比为高级的加权移动平均,而 MA 虽然是移动平均的缩写,但其实是对 AR 部分的残差的移动平均。
ARIMA 相关的理论基础非常多,这里就略过了(我也不懂)。实际在使用时还需要做平稳性检验,确定 p, d, q 参数的值,使用起来有点麻烦。好在我们有 Auto ARIMA[4](原版为 R 中的 forecast 包,Python 中也有类似的库如 pmdarima[5]),可以通过 AutoML 的手段来自动搜寻最佳的参数组合。
与 ARIMA 类似的还有很多,例如改进版的 SARIMA,ARIMAX,还有虽然听过,但从来没用过的 ARCH,GARCH 模型等……这类模型相比简单的移动平均,拟合能力明显会更强一些,但缺点是运行时间也明显变长了。通常来说,这类传统模型我们都需要对每一条时间序列都单独拟合和预测。如果我们要对淘宝所有的商品做销量预测,可以预见到序列的数量会非常之大,这类方法在执行时就需要花费很长的时间,而且需要用户自己来开发相应的并发执行机制。
Prophet
由 Facebook 开源的 Prophet[6] 是另一个非常知名的时序预测模型。因为 API 设计比较友好,还附带一系列可视化和模型解释,在广大人民群众之中迅速的流行了起来。
Prophet 背后使用的是加性模型模式,将时间序列分解为趋势,季节,节假日等外部变量这三类模型之和,且利用了概率建模方式,在预测时可以输出预测值的概率分布情况。具体可以参考我们组鼎彦同学的这篇优秀的 介绍 Prophet 原理的文章[7]。
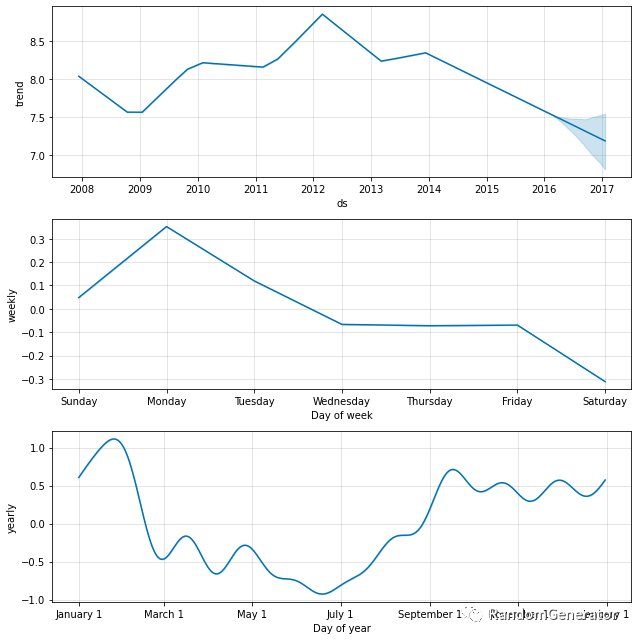
Prophet 相比原版 ARIMA,在非线性趋势,季节性,外部变量方面都具有优势,做多步预测也会更加自然一些。但同样,Prophet 的训练预测也需要在每一条序列维度来进行,大规模序列的性能会是一个挑战。
最近 Uber 也推出了一个有些类似的时序预测库 Orbit[8],据称效果比 Prophet 更好。另外我们还尝试过基于 PyTorch 的 NeuralProphet[9],API 跟 Prophet 非常接近,不过实测下来预测的稳定性没有 Prophet 好,可能神经网络比较容易跑飞……
问题
这里我们来总结一下传统时序预测方法的一些问题:
对于时序本身有一些性质上的要求,需要结合预处理来做拟合,不是端到端的优化;
需要对每条序列做拟合预测,性能开销大,数据利用率和泛化能力堪忧,无法做模型复用;
较难引入外部变量,例如影响销量的除了历史销量,还可能有价格,促销,业绩目标,天气等等;
通常来说多步预测能力比较差。
正因为这些问题,实际项目中一般只会用传统方法来做一些 baseline,主流的应用还是属于下面要介绍的机器学习方法。
机器学习方法
如果我们去翻阅一下 Kaggle 或其它数据科学竞赛平台上的相关时序预测比赛,会发现绝大多数的获胜方案使用的是传统机器学习的方式,更具体地来说,一般就是 xgboost 和 lightgbm 这类梯度提升树模型。其中有个有意思的例外是当年的 Web Traffic Forecasting[10],我当时看了这个比赛也很激动,尝试了 N 多深度学习的方法来做时序问题,可惜大都没有很好的结果。砍手豪大佬的这篇文章[11] 也对相关原因做了一些分析。下面我们对这类方法做个简单介绍。
建模方式
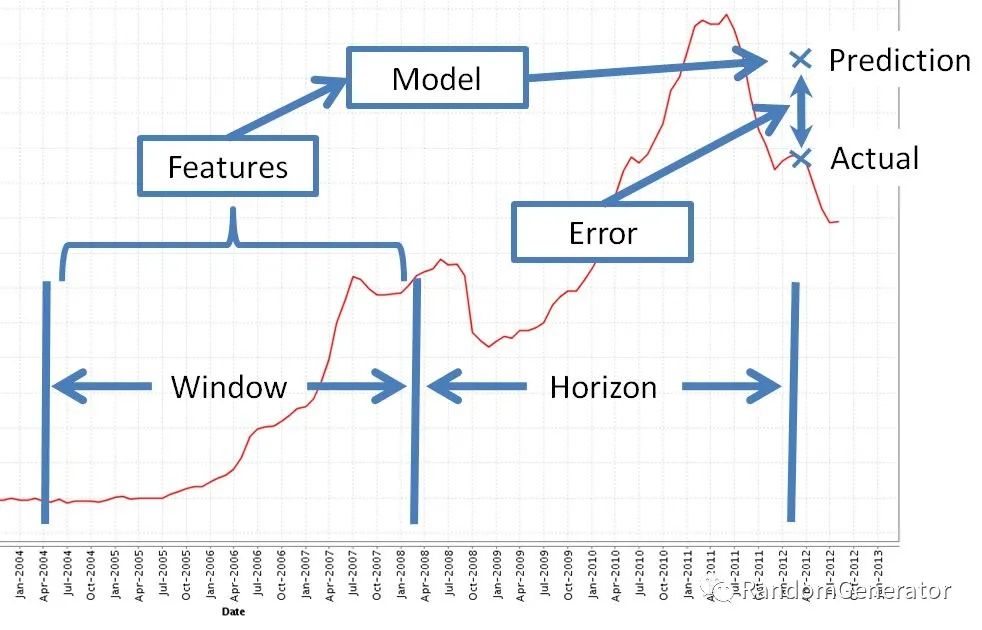
机器学习方法处理时序问题的基本思路跟前面提到的时序验证划分一致,就是把时序切分成一段历史训练窗口和未来的预测窗口,对于预测窗口中的每一条样本,基于训练窗口的信息来构建特征,转化为一个表格类预测问题来求解。

如上图中,浅蓝色的部分即为我们构建特征的窗口,我们利用这部分的信息输入构建特征后,再去预测深蓝色预测窗口中的值,计算误差,再不断迭代改进。这个窗口可以不断往前滑动,就形成了多个预测窗口的样本,一定程度上可以提高我们的数据利用率。
实际场景中,一般我们需要确定几个参数:
历史窗口的大小,即我们预测未来时,要参考过去多少时间的信息作为输入。太少可能信息量不充分,太多则会引入早期不相关的信息(比如疫情前的信息可能目前就不太适用了)。
预测点 gap 的大小,即预测未来时,我们是从 T+1 开始预测,还是 T+2,T+3?这与现实的业务场景有关,例如像补货场景,预测 T+1 的销量,可能已经来不及下单补货了,所以我们需要扩大这个提前量,做 T+3 甚至更多提前时间的预测。
预测窗口的大小,即我们需要连续预测多长的未来值。比如从 T+1 开始一直到 T+14 都需要预测输出。这一点也跟实际的业务应用场景有关。
另外值得一提的是,上图中画的是一条时间序列,实际上如果我们有成百上千个序列,是可以把这些数据放在一起做训练的。这也是机器学习方法对于传统时序方法的一个较为明显的优势。
在看一些文章的时候,我们也会看到一些额外加入时序预处理步骤的方法,比如先做 STL 分解再做建模预测。我们尝试下来这类方法总体来说效果并不明显,但对于整个 pipeline 的复杂度有较大的增加,对于 AutoML,模型解释等工作都造成了一定的困扰,所以实际项目中应用的也比较少。
特征工程
这张图更明确的指出了我们构建特征和建模的方式。为了便于理解,我们可以假设预测的 horizon 长度仅为 1 天,而历史的特征 window 长度为 7 天,那么我们可以构建的最基础的特征即为过去 7 天的每天的历史值,来预测第 8 天的值。这个历史 7 天的值,跟之前提到的移动平均,AR(自回归)模型里所使用的值是一样的,在机器学习类方法中,一般被称为 lag 特征。
对于时间本身,我们也可以做各类日期衍生特征,例如我们以天为粒度做预测,我们可以添加这天是星期几,是一个月的第几天,是哪个月份,是否是工作日等等特征输入。
另外一类最常见的基础特征,就是区分不同序列的类别特征,例如不同的门店,商品,或者不同的股票代码等。通过加入这个类别特征,我们就可以把不同的时间序列数据放在一张大表中统一训练了。模型理论上来说可以自动学习到这些类别之间的相似性,提升泛化能力。
类别属性实际上可以归类为静态特征,即随着时间的变化,不会发生变化的信息。除了最细粒度的唯一键,还可以加入其它形式的静态特征。例如商品属于的大类,中类,小类,门店的地理位置特性,股票所属的行业等等。除了类别型,静态特征也可能是数值型,例如商品的重量,规格,一般是保持不变的。
Lag 特征,日期特征这类,则属于动态特征,随着时间变化会发生改变。这其中又可以分成两类,一类是在预测时无法提前获取到的信息,例如预测值本身,跟预测值相关的不可知信息,如未来的客流量,点击量等。对于这类信息,我们只能严格在历史窗口范围内做各种特征构建的处理,一般以 lag 为主。另一类则是可以提前获取到的信息,例如我们有明确的定价计划,可以预知在 T+1 时计划售卖的商品价格是多少。对于这类特征,我们则可以直接像静态特征那样直接加入对应时间点的信息进去。
以上提到的基本属于直接输入的信息,基于这些信息,我们还可以进一步做各种复杂的衍生特征。例如在 lag 的基础上,我们可以做各种窗口内的统计特征,比如过去 n 个时间点的平均值,最大值,最小值,标准差等。进一步,我们还可以跟之前的各种维度信息结合起来来计算,比如某类商品的历史均值,某类门店的历史均值等。也可以根据自己的理解,做更复杂计算的衍生,例如过去 7 天中,销量连续上涨的天数,过去 7 天中最大销量与最低销量之差等等。很多数据科学比赛的获胜方案中都会有大量篇幅来讲解这方面的衍生特征如何来构建。
最后值得一提的是还有很多将各类特征工程手段自动化的工具,在时间序列领域最有名的莫过于 tsfresh[12] 了。除了前面提到的一些基础操作,tsfresh 还能够支持 wavelet 等高深操作,但缺点就是运行时间相对有点长,且需要结合特征选择来达到更好的效果。
模型选择
模型这块,基本上没有什么花样,大家的主流选择基本都是 GBDT 和 NN。个人最常使用的选择是 LightGBM[13] 和 fastai[14],然后选择好时序验证方式,做自动参数优化就可以了(比如使用 Optuna 或 FLAML)。Lgb 的训练速度快,而且在某些业务特征比较重要的情况下,往往能达到比神经网络更好更稳定的效果。而 NN 的主要优势在类别变量的表达学习上,理论上可以达到更好的 embedding 表示。此外 NN 的 loss 设计上也会比较灵活,相对来说 lgb 的 loss 或者多目标学习限制条件就比较多了。更多的讨论也可以参考我的这篇 表格数据模型对比[15] 的文章。总体来说,目前最常见的选择仍然是树模型一族。
有一个值得注意的考量点在于 local 模型与 global 模型的取舍。前面提到的经典时序方法中都属于 local 模型,即每一个序列都要构建一个单独的模型来训练预测;而我们提到的把所有数据都放在一起训练则是 global 模型的方式。实际场景中,可能需要预测的时序天然就会有很不一样的规律表现,比如科技类股票,跟石油能源类股票的走势,波动都非常不一样,直接放在一起训练反而可能导致整体效果下降。所以很多时候我们要综合权衡这两种方式,在适当的层级做模型的拆分训练。深度学习领域有一些工作如 DeepFactor[16] 和 FastPoint[17] 也在自动适配方面做了些尝试。
深度学习方法
前面有提到过在 Kaggle 2018 年的 Web Traffic Forecasting 比赛中,冠军选手采用了深度学习的方案,当时年幼的我看到这个分享大受震撼,感觉深度学习统治时间序列领域的时代就要到来了!后面也花了不少时间调研和尝试各类针对时序问题设计的 NN 模型(有不少是从 NLP 领域借鉴过来的)。不过几年尝试下来,发现绝大多数论文中实验数字看起来很漂亮的模型,在真实世界场景中应用的效果都不太理想,包括后来的很多比赛也仍然是树模型占据获胜方案的主流地位。这里有一个原因可能跟前面介绍传统时序方法中的问题类似,很多学术研究的数据集(参考 papers with code)都是比较单一的时间序列(比如气象信息,医学记录),没有包含什么其它输入信息和业务目标。而现实应用中的时序场景很多时候都是海量序列,包含了很多层级维度,促销,气候,外部事件等异常丰富的业务输入信息,其预测场景也更加丰富多样。
总体来说,深度学习的思路是尽量只使用原始的序列和其它相关输入信息,基本不做特征工程,希望通过各类模型结构自动学习到时序的隐含表达,进而做端到端的预测输出。所以我把特征工程 + NN 的方案归类到了上面机器学习方法中。这一节里简要介绍一下这几年我们做过的深度学习相关尝试,可以供同学们参考。
RNN 系列
直接借鉴 NLP 领域中经典的 RNN, GRU, LSTM 模型来做时间序列的预测应该是最直观的一种思路了。使用这个方法,甚至可以直接做任意步的预测窗口输出。但实际场景中,一般时序问题的输入输出窗口大小带有比较重要的业务含义,也需要针对性进行训练,评估,优化,所以往往不会直接使用这类原始 RNN 的方式来做训练预测。
Seq2Seq
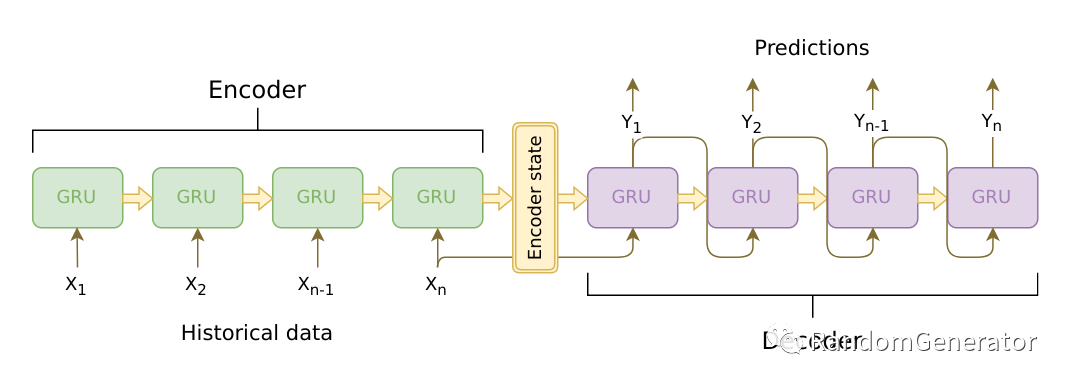
这就是前面提到的 Web Traffic Forecasting 比赛冠军方案中主要采用的模型。基本是借鉴了 NLP 里的经典架构,使用 RNN/GRU/LSTM 作为基本单元,encoder 中做训练窗口中的信息提取,然后在 decoder 中做预测 horizon 的多步输出。作者在方案里还尝试了在 decoder 时同时引入注意力机制,但发现效果并不稳定,最后直接改成了 lag 特征来捕捉固定周期的历史信息。
在训练预测方面,作者也花了不少功夫,例如使用 SMAC3 进行自动调参,使用 COCOB 作为优化器,通过一系列 SGD averaging,多模型,多 checkpoint 输出的均值来提升模型的稳定性等,具体可以参考作者的这篇 总结文档[18]。
我们当时也把这套架构迁移到了很多我们内部的项目中,但整体用下来发现调参的计算开销要比跑树模型大的多得多,训练稳定性却远不如树模型,很难调整到一个稳定预测输出的状态。再加上整体的误差分析和模型解释也比较难做,所以后来也并没有推广使用。砍手豪大佬之后也分析过这次比赛之所以是神经网络模型获胜,跟使用的 SMAPE 指标也有很大关系。
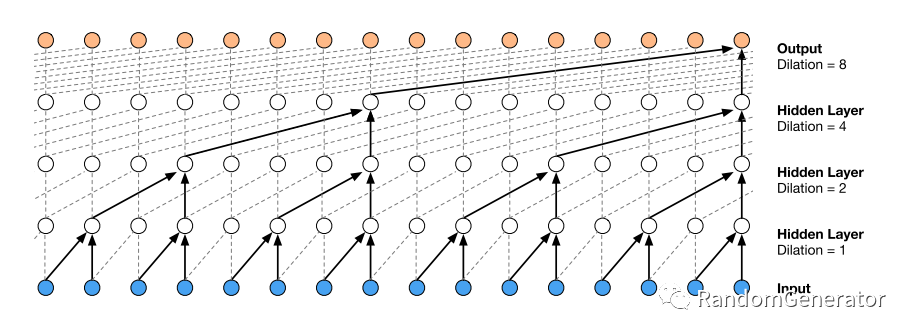
WaveNet
这也是当年非常火的一个模型,主要是 RNN 系列模型不好并行,所以突然发现谷歌提出的这个空洞因果卷积感觉很高级,性能理论上也比 RNN 之类的好很多,它的结构大致长这样:
除了使用一维 CNN 来做序列预测外,WaveNet 里还加入了 residual connection 和 skip connection,以及一系列复杂的“门机制”:
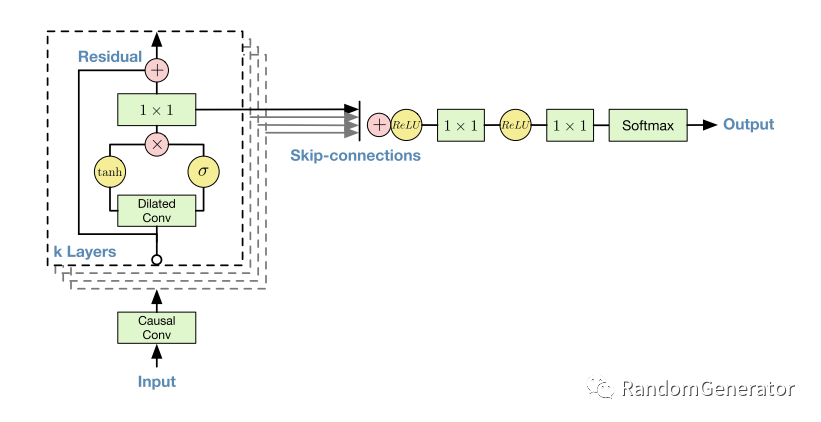
不过我们实际使用下来,感觉 CNN 整体对于序列问题的预测效果还是不如 RNN 系列。事后来看可能跟缺乏位置编码这类信息有关。
顺带一提 WaveNet 这类 CNN 结构也可以用在 Seq2Seq 框架中的 encoder 部分。
LSTNet
当年应该是在 Papers With Code 上看到 LSTNET 占据了几个 benchmark 的榜首位置,也去简单尝试了一下,模型结构也是愈发花里胡哨:
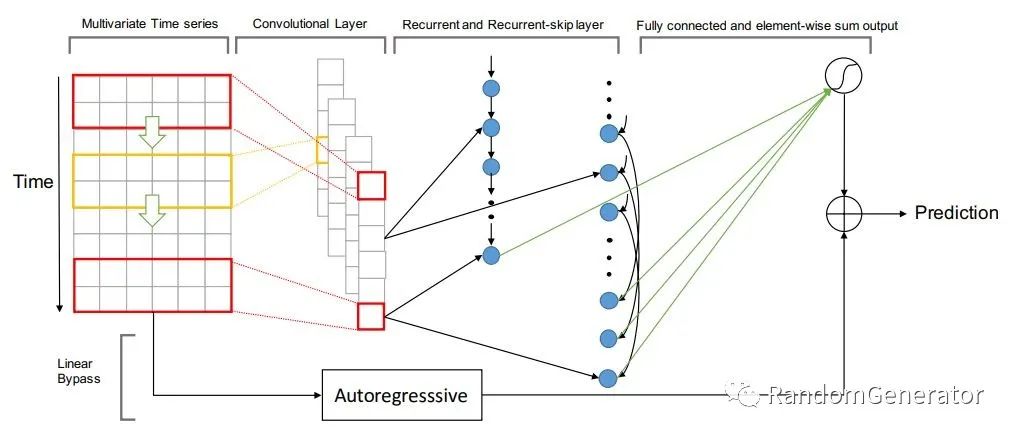
不过效果嘛,还是不理想,不如特征工程加 fastai 效果来的好。
DeepAR
亚马逊提出的一个网络架构,也是基于 Seq2Seq,不过 DeepAR 的输出跟 Prophet 一样,是一个概率分布,这也是它与传统 RNN 系列最大的一个区别。
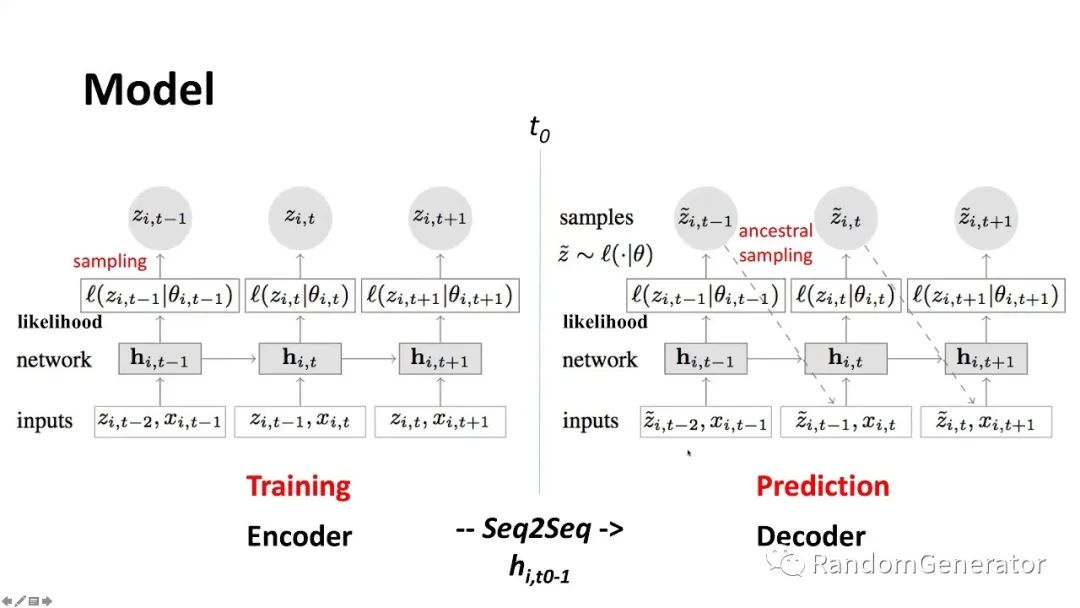
虽然来头很大,但尝试下来仍然是很难稳定收敛,多次训练的精度波动也很大,最终效果也无法与 GBDT 匹敌。不过在尝试 DeepAR 的过程中发现亚马逊开源的一个挺不错的时序预测库 gluon-ts[19],里面包含了非常多的深度学习时序模型实现,也很方便自己实现相关模型,大大加速了我们的实验尝试,非常值得推荐!
概率分布输出本身是个挺有用的特性,例如用于下游的 Service Level 的满足率计算等。理论上我们也可以用 quantile regression 方法,或者 ngboost[20] , LightGBMLSS[21] 等库在 GBDT 模型上实现概率预测输出。
N-Beats
这也是一个来头很大的模型,出自 Element AI[22],Bengio 是其中的 Co-Founder。第一次见到它是来自 M5 比赛亚军的分享,不过他也只是在 top-level 的预测中使用了一下 N-Beats 模型。
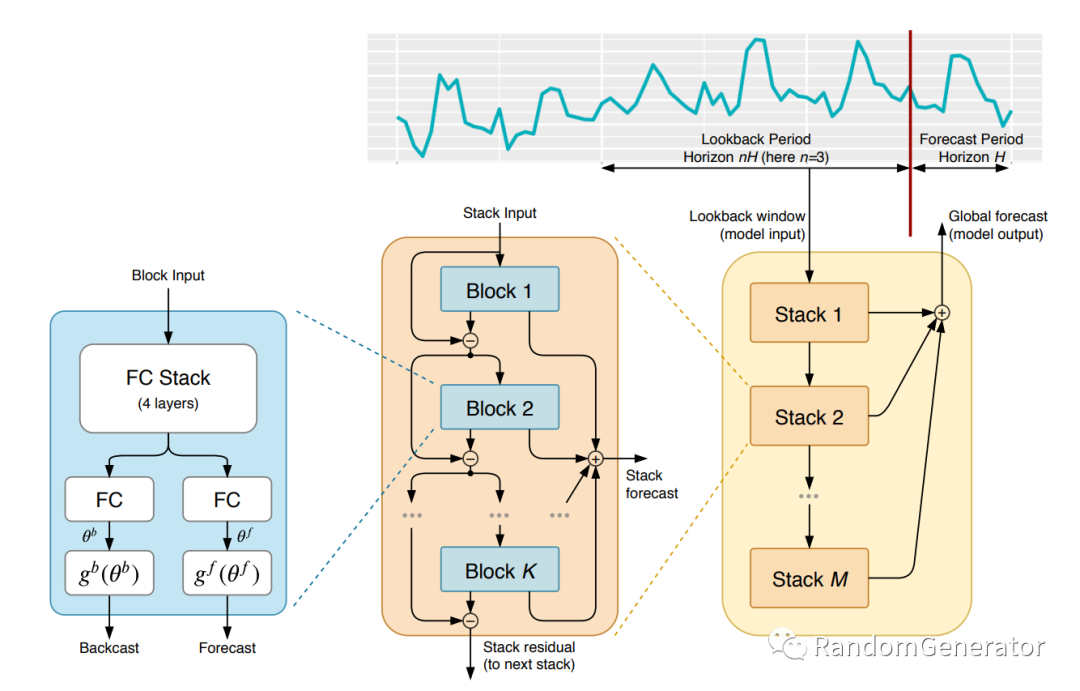
从介绍来看,N-Beats 专注于做单变量的时序预测,且可以具有一定的 seasonality,trend 的可解释性,跟 Prophet 很相似。从论文的实验来看,作者使用了非常重的 ensemble,每个序列搞了 180 个模型的 bagging。这感觉有点过于“杀鸡用牛刀”了……我们实测下来也没有取得很好的效果,而且看起来还不好加额外的特征变量,使用场景很受限。
TFT
终于来到了一个尝试下来表现可以与树模型匹敌的深度学习模型了!这就是 Google AI 提出的 Temporal Fusion Transformers。也是本文提到的第一个带 transformer 结构的模型 :)
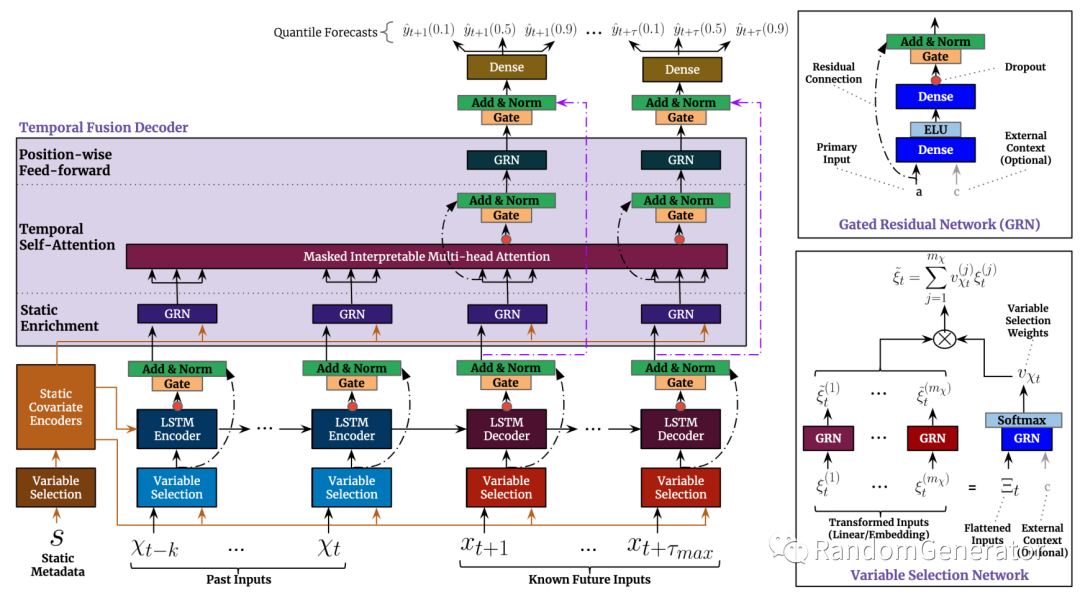
个人感觉 TFT 的设计里最有意思的是对于特征变量选择网络的考虑,从实现效果上来说跟树模型做特征选择很相似。顺带一提我们在表格类问题上测试下来表现比较好的模型,例如 TabNet,NODE 等,也都有这种模拟决策树行为的设计。具体实验下来在一些场景中 TFT 甚至可以超越特征+GBDT 的建模方案,非常惊人!不过训练计算开销仍然是比较大,这点还是跟树模型有差距。
TFT 还有一点比较有意思的是对于特征输入的设计挺系统化,分成了静态类别/连续变量,动态已知类别/连续变量,和动态未知类别/连续变量。以我们使用的 pytorch-forecasting[23] 库为例,其 dataset 接口大致长这样:
training = TimeSeriesDataSet(
data[lambda x: x.date <= training_cutoff],
time_idx= ..., # column name of time of observation
target= ..., # column name of target to predict
group_ids=[ ... ], # column name(s) for timeseries IDs
max_encoder_length=max_encoder_length, # how much history to use
max_prediction_length=max_prediction_length, # how far to predict into future
# covariates static for a timeseries ID
static_categoricals=[ ... ],
static_reals=[ ... ],
# covariates known and unknown in the future to inform prediction
time_varying_known_categoricals=[ ... ],
time_varying_known_reals=[ ... ],
time_varying_unknown_categoricals=[ ... ],
time_varying_unknown_reals=[ ... ],
)这种归类方式非常具有通用性,值得推广。
深度学习总结
总体看来,目前(22 年初)能够大规模推广应用的深度时序模型感觉还基本没有(最新的 Informer, Autoformer 还没尝试)。前阵子有一篇很有意思的论文也讨论了这点,标题就叫 Do We Really Need Deep Learning Models for Time Series Forecasting?[24],从结果来看基本还是 GBDT 完胜。
这块也有很多综述文章可以参考,例如:
Learnings from Kaggle’s Forecasting Competitions[25]
Neural forecasting: Introduction and literature overview[26]
除了模型预测本身,深度学习中的各种强项,例如预训练和迁移学习,表达学习,生成式模型等方面,目前也还很难应用于时序领域。未来想要有所突破,如何能更好的做 数据增强[27],做 时序问题的预训练[28],也是很值得深入研究的方向。
最后在整体架构方面,跟机器学习模型 pipeline 来对比看,前者一般模型部分处理会相对简单,但涉及到的预处理,特征工程及后处理方面会比较复杂;而深度学习手段正好相反,在整体 pipeline 层面会相对简单,更提倡 end-to-end 的训练,但模型部分则相对复杂和难以优化。
AutoML
最后我们来看下时序领域的 AutoML,近几年 Github 上也出现了一些针对时序问题的 AutoML 库,例如:
Auto_TS[29]
AutoTS[30]
不过总体来说他们面向的还是模型的自动选择和调优,针对时序问题做了一些特定的配置项,如时间粒度,前面有提到过的预测的长度,自动的 validation 等。但从前文的对比来看,目前效果比较好的主流方法还是特征工程+GBDT 模型,尤其是特征工程这块的自动化显得尤为关键,而目前 tsfresh 也并没有在衍生特征的自动化上做多少工作。个人在前面 TFT 的结构化时序数据集接口设计基础上,设计相应的自动化特征工程与模型优化,会是一个能够达到比较好效果的路径。
此外,前文中比较少有提到时序数据的各种检测判断,预处理等环节。在之前的 AutoML 比赛中,就有 life-long learning 的设定,即模型的学习预测会随着时间的推移不断有新数据的输入,这也与真实项目的情况非常符合。因此完善的 AutoML 方案中,也需要包含例如 prior shift, covariate shift, concept drift 等方面的检测与处理,以适应复杂的真实预测场景。
可以预见未来会有更多的面向时序问题的 AutoML 框架和产品出现,不断降低使用门槛,扩展相关的应用场景。对这些方向感兴趣的同学也可以多跟我们讨论交流,一起打造行业领先的 AI 产品。
参考资料
[1]
rolling: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rolling.html
[2]ewm: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.ewm.html
[3]window function: https://learnsql.com/blog/moving-average-in-sql/
[4]Auto ARIMA: https://www.rdocumentation.org/packages/forecast/versions/8.16/topics/auto.arima
[5]pmdarima: http://alkaline-ml.com/pmdarima/index.html
[6]Prophet: https://facebook.github.io/prophet/
[7]介绍 Prophet 原理的文章: https://zhuanlan.zhihu.com/p/463183142
[8]Orbit: https://github.com/uber/orbit
[9]NeuralProphet: https://github.com/ourownstory/neural_prophet
[10]Web Traffic Forecasting: https://www.kaggle.com/c/web-traffic-time-series-forecasting/
[11]砍手豪大佬的这篇文章: https://zhuanlan.zhihu.com/p/352461742
[12]tsfresh: https://github.com/blue-yonder/tsfresh
[13]LightGBM: https://github.com/microsoft/LightGBM
[14]fastai: https://github.com/fastai/fastai
[15]表格数据模型对比: https://zhuanlan.zhihu.com/p/381323980
[16]DeepFactor: https://arxiv.org/abs/1905.12417
[17]FastPoint: https://dl.acm.org/doi/abs/10.1007/978-3-030-46147-8_28
[18]总结文档: https://github.com/Arturus/kaggle-web-traffic/blob/master/how_it_works.md
[19]gluon-ts: https://github.com/awslabs/gluon-ts
[20]ngboost: https://github.com/stanfordmlgroup/ngboost
[21]LightGBMLSS: https://github.com/StatMixedML/LightGBMLSS
[22]Element AI: https://www.elementai.com/
[23]pytorch-forecasting: https://github.com/jdb78/pytorch-forecasting
[24]Do We Really Need Deep Learning Models for Time Series Forecasting?: https://arxiv.org/pdf/2101.02118.pdf
[25]Learnings from Kaggle’s Forecasting Competitions: https://arxiv.org/abs/2009.07701
[26]Neural forecasting: Introduction and literature overview: https://arxiv.org/abs/2004.10240
[27]数据增强: https://arxiv.org/abs/2002.12478
[28]时序问题的预训练: https://arxiv.org/abs/2005.06978
[29]Auto_TS: https://github.com/AutoViML/Auto_TS
[30]AutoTS: https://github.com/winedarksea/AutoTS
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书