一、数据预处理
1.1 异常值清理
由于设备故障或计算错误,时序数据中会有一些异常值,这些异常值会对时间序列的预测造成不好的影响,所以先进行平滑处理,去除异常值。平滑处理的方式可以采用取前后均值的方法,代码如下:
def diff_smooth(ts):
dif = ts.diff().dropna() # 差分序列
td = dif.describe() # 描述性统计得到:min,25%,50%,75%,max值
high = td['75%'] + 6 * (td['75%'] - td['25%']) # 定义高点阈值,1.5倍四分位距之外
low = td['25%'] - 6 * (td['75%'] - td['25%']) # 定义低点阈值,同上
# 变化幅度超过阈值的点的索引
forbid_index = dif[(dif > high) | (dif < low)].index
i = 0
while i < len(forbid_index) - 1:
target = forbid_index[i] # 异常点的索引
# 用前后值的中间值均匀填充
mean_value = (ts[target-1] + ts[target+1])/2
ts[target] = mean_value
i += 1
return ts1.2 白噪声检验
如果时序数据是白噪声,没有规律可学,就没有预测的必要性,没有研究的意义。
白噪声是指不相关的随机变量,定义为:(对一系列的e1,e2,e3…..et)满足三个条件
1.E(et)=0
2.Var(et)=a2
3.Cov(et,es)=0 (其中t不等于s)
常用的检验方法有两种:ACF自相关图法和Ljung-Box q统计量
ACF自相关图法

如自相关图,当t=0时,acf=1,其他时候afc都为在虚线以下时,时序数据才为白噪声,代码如下
from statsmodels.graphics.tsaplots import plot_acf
plt.figure(figsize=[20,5])
plt.subplot(211)
plot_acf(stationary, ax=plt.gca())Ljung-Box q统计量法
纯随机性检验,如果p值小于5%,序列为非白噪声
from statsmodels.stats.diagnostic import acorr_ljungbox
def test_stochastic(ts):
p_value = acorr_ljungbox(ts, lags=1)[1] # lags可自定义
return p_value二. 模型的选择
业内常用的时间序列预测算法有:ARIMA和LSTM
2.1 ARIMA模型
ARIMA模型分可以看成AR模型和MA模型的组合。
AR:当前值只是过去值的加权求和。
MA:过去的白噪音的移动平均。
ARMA:AR和MA的综合。
ARIMA:和ARMA的区别,就是公式左边的x变成差分算子,保证数据的稳定性。
arima(p,d,q) 有三个参数,p是偏自相关系数,d是d次差分后时序数据变平稳,q是自相关系数。
from statsmodels.tsa.arima_model import ARMA
model = ARMA(history, order=(1, 1))
model_fit = model.fit(disp=0)
yhat = model_fit.forecast()[0]
predictions.append(yhat)2.2 LSTM
基于TFTS(TensorFlow Time Series)的时间序列模型,使用方法:
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(reader, batch_size=10, window_size=20)
estimator = ts_estimators.TimeSeriesRegressor(model=_LSTMModel(num_features=1, num_units=128), optimizer=tf.train.AdamOptimizer(0.001))
estimator.train(input_fn=train_input_fn, steps=5000)可调参数:batch_size, window_size, num_units, learning_rate, steps
效果如图:
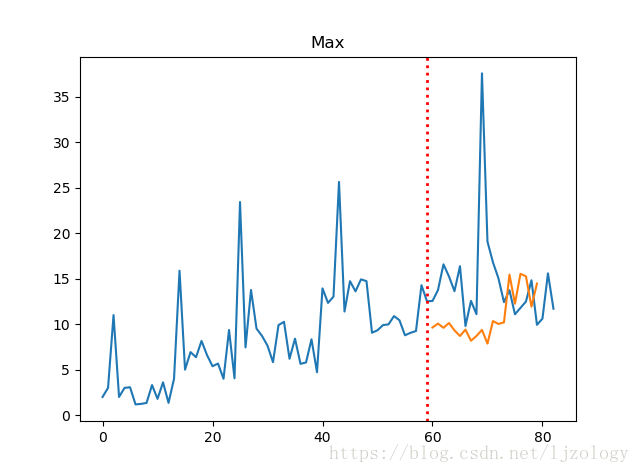
三. 评估方法
3.1 相对误差
原理

程序
def get_average_relative_error(y_t, y_p):
y_relative_error = [math.fabs(y_p[i] - y_t[i]) / y_t[i] for i in range(len(y_p))]
y_average_relative_error = sum(y_relative_error) / len(y_relative_error)
return y_average_relative_error3.2 均方误差
原理
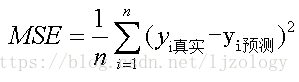
程序
def get_average_absolute_error(y_t, y_p):
y_absolute_error = [math.fabs(y_p[i] - y_t[i]) for i in range(len(y_p))]
y_average_absolute_error = sum(y_absolute_error) / len(y_absolute_error)
return y_average_absolute_error