1、python导入相应的库
这里我们导入python数据分析相关的库,并配置画图模块
%matplotlib inline
import pandas as pd
import numpy as np
import datetime
import matplotlib.pylab as plt
import seaborn as sns
import itertools
import statsmodels.api as sm
from matplotlib.pylab import style
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
style.use('ggplot')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
2、读取数据
我们先读取附件一给出的煤炭价格数据,并选择我们需要的数据,由于原始数据的时间索引间隔是没有规律的,所以我们需要对数据进行重采样,根据第二题的要求,我们分别以天、周、月为单位对数据重采样,并取平均价格那一列作为预测数据。
#读取数据
price = pd.read_excel("data.xlsx", index_col=0, parse_dates=[0], header=1)
price = price.rename(columns={
'价格低值(元/吨)':'low', '价格高值(元/吨)':'high', '价格平均值(元/吨)':'mean'})
price_week = price.resample('W-WED').mean().resample('W-WED').interpolate('linear')
price_week = price_week['mean']
price_day = price_week.resample('D').interpolate('linear')
price_month = price_day.resample('MS').mean()
以下为原始数据前10行

把以天为单位的数据为例画出图像
price_day.plot(figsize=(12,8))
plt.legend(bbox_to_anchor=(1.25, 0.5))
plt.title("money")
sns.despine()

通过分析以上图可以看到数据的平稳性较差,需要对数据做差分
3、差分法
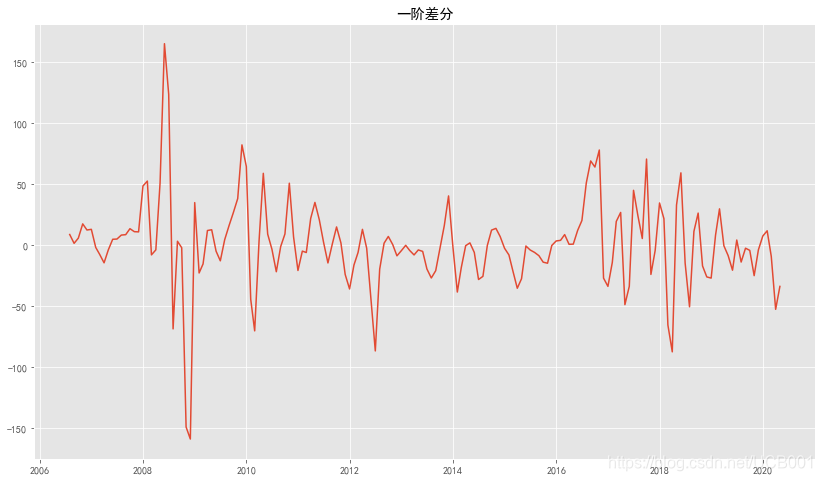
先对数据做一阶差分
#做一阶差分
def differ(price):
price_diff = price.diff()
price_diff = price_diff.dropna()
plt.figure(figsize=(14, 8))
plt.plot(price_diff)
plt.title('一阶差分')
plt.show()
return price_diff
#以月为单位的数据为例
day_diff = differ(price_month)
画出一阶差分后的图,我们可以看到平稳性很高,所以只需做一阶差分就可以了
4、时间序列定阶
定阶问题,主要是确定p,d,q三个参数,差分的阶数d一般通过观察图示,1阶或2阶即可。我们主要确定p和q的值,通过以下两个函数确定。
1)、自相关函数ACF(autocorrelation function)
自相关函数ACF描述的是时间序列观测值与其过去的观测值之间的线性相关性。计算公式如下:
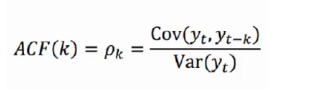
其中k代表滞后期数,如果k=2,则代表yt和yt-2
2)、偏自相关函数PACF(partial autocorrelation function)
偏自相关函数PACF描述的是在给定中间观测值的条件下,时间序列观测值预期过去的观测值之间的线性相关性。
综上,p和q的阶数确定规则如下:

接下来我们来画一下PACF和ACF的图
#画acf和pacf图像
def show_acf(price_diff):
acf = plot_acf(price_diff, lags=20)
plt.title("ACF")
acf.show()
pacf = plot_pacf(price_diff, lags=20)
plt.title("PACF")
pacf.show()
show_acf(month_diff)
结果如图:


5、信息准则定阶
通过拖尾和截尾对模型进行定阶的方法,往往具有很强的主观性。因此我们可以通过信息准则定阶,常用的信息准则函数有下面2种:
AIC准则
AIC准则全称为全称是最小化信息量准则(Akaike Information Criterion),计算公式如下:
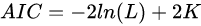
其中 L 表示模型的极大似然函数,K 表示模型参数个数。
BIC准则
AIC准则存在一定的不足之处。当样本容量很大时,在AIC准则中拟合误差提供的信息就要受到样本容量的放大,而参数个数的惩罚因子却和样本容量没关系,因此当样本容量很大时,使用AIC准则选择的模型不收敛与真实模型,它通常比真实模型所含的未知参数个数要多。BIC(Bayesian InformationCriterion)贝叶斯信息准则弥补了AIC的不足,计算公式如下:

其中 n 表示样本容量。
#信息准则定阶:AIC、BIC、HQIC
def get_pq(data):
#AIC
AIC = sm.tsa.arma_order_select_ic(data, max_ar=6, max_ma=4, ic='aic')['aic_min_order']
#BIC
BIC = sm.tsa.arma_order_select_ic(data, max_ar=6, max_ma=4, ic='bic')['bic_min_order']
print('the AIC is{},\nthe BIC is{}\n'.format(AIC,BIC))
get_pq(price_month)
得出结果如下:
the AIC is(4, 0),
the BIC is(1, 1)
我们取BIC的结果,因此可以确定p、q的值分别为1、1
6、训练模型,预测数据
预测数据并将结果保存在本地的CSV文件中
#预测数据
def predict(price, order, start, end, freq=None):
model = ARIMA(price, order=order, freq=freq)
result = model.fit()
pred = result.predict(start, end, dynamic=True, typ='levels')
plt.figure(figsize=(14, 8))
plt.xticks(rotation=45)
plt.plot(pred)
plt.plot(price)
return pred
#36月数据
pred_month = predict(price_month, (1, 1, 1), '2020-04', '2023-04', 'MS')
pred_month.to_csv("36月数据.csv")
#35周数据
pred_week = predict(price_week, (5, 1, 0), '2020-04-15', '2020-12-30' 'W-WED')
pred_week.to_csv("35周数据.csv")
#31天数据
pred_day = predict(price_day, (1, 1, 5), '2020-4-15', '2020-6-10')
pred_day.to_csv("31天数据.csv")
以周为单位的数据为例
