一种改进的原子搜索算法
文章目录
摘要:原子搜索算法(Atom Search Algorithm,ASO)是模仿自然界中原子运动而提出的一种新型优化算法,针对ASO在求解复杂函数时存在易早熟及收敛速度慢的问题,提出了一种改进ASO算法(Improved Atomic Search Algorithm,IASO)。IASO加入了原子个体历史最优解产生的约束力来修正ASO的加速度,增强全局搜索能力。自适应更新两个乘数系数来协调算法的全局搜索和局部开发能力。适时采用高斯变异策略来重新更新原子位置,提高跳出早熟的能力。
1.原子搜索算法
基础原子搜索算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/112909360
2. 改进原子搜索算法
2.1 引入新的共价键约束力
ASO 每次迭代中种群最佳原子对周围 原子存在一个共价键约束力 G i d G_{i}^{d} Gid, 由式 (10) 可知它是种群最佳原子位置与当前原子位 置的差值, 这种机制提高了全局最优信息对 当前原子的引导作用, 加强了原子个体之间 的协同合作。为了更好的更新原子加速度方 向, 本文引入原子对自身的认知, 加入原子 个体历史最优解-单个原子在历次迭代中的 最佳位置叫原子个体历史最优解。在每一 次迭代中的个体原子位置都与原子个体历 史最优位置进行比较, 如果当前个体原子位 置优于它的个体历史最优位置, 则把当前个 体原子位置更新为个体历史最优位置, 相反, 则不更新。假设每个原子个体在迭代中产生 的个体历史最优解对周围原子也存在一个 共价键约束力, 因此原子的加速度受种群最 佳原子产生的共价键约束力和个体历史最 优原子产生的共价键约束力共同影响。原子可以利用种群信息和自身经验, 通过信息融 合更新加速度, 提高了算法的全局探索能力。 原子个体历史最优解产生的共价键约束力 定义为 P i d P_{i}^{d} Pid, 其表达式如下(14)所示:
P i d = λ e − 20 t T ( x p d ( t ) − x i d ( t ) ) (14) P_{i}^{d}=\lambda e^{\frac{-20 t}{T}}\left(x_{p}^{d}(t)-x_{i}^{d}(t)\right) \tag{14} Pid=λeT−20t(xpd(t)−xid(t))(14)
其中 λ \lambda λ 是系数因子, x p d x_{p}{ }^{d} xpd 代表第 t t t 次迭代 中原子 i i i 的历史最优位置。
2.2 自适应调整系数因子
引入原子个体历史最优解产生的共价 键约束力 P i d P_{i}^{d} Pid 之后, 原子加速度 a i d a_{i}^{d} aid 的公式更 新为如下(15)所示:
a i = F i d + G i d + P i d m i a_{i}=\frac{F_{i}{ }^{d}+G_{i}{ }^{d}+P_{i}^{d}}{m_{i}} ai=miFid+Gid+Pid
= − α ( 1 − t − 1 T ) 3 e − 20 t T ∑ j ∈ K ben rand j [ 2 ( h i j ( t ) ) 13 − ( h i j ( t ) ) 7 ] m i =-\alpha\left(1-\frac{\mathrm{t}-1}{\mathrm{~T}}\right)^{3} e^{-\frac{20 t}{T}} \sum_{j \in K_{\text {ben }}} \frac{\operatorname{rand}_{j}\left[2\left(h_{i j}(t)\right)^{13}-\left(h_{i j}(t)\right)^{7}\right]}{m_{i}} =−α(1− Tt−1)3e−T20t∑j∈Kben mirandj[2(hij(t))13−(hij(t))7]
+ β e − 20 t T ( x best d ( t ) − x i d ( t ) ) m i + λ e − 20 t T ( x p d ( t ) − x i d ( t ) ) m i +\beta e^{\frac{-20 t}{T}} \frac{\left(x_{\text {best }}^{d}(t)-x_{i}^{d}(t)\right)}{m_{i}}+\lambda e^{\frac{-20 t}{T}} \frac{\left(x_{p}^{d}(t)-x_{i}^{d}(t)\right)}{m_{i}} +βeT−20tmi(xbest d(t)−xid(t))+λeT−20tmi(xpd(t)−xid(t))
其中 β \beta β 和 λ \lambda λ 都是超参数, 对算法的寻优 速度和优化结果有着重要的影响, 可以看出 β \beta β 代表了原子向全局历史最优解运动能力的 权重, λ \lambda λ 代表了原子对自己的认可程度。这 两个参数反映了对种群信息和个体信息的 接受程度, 不同阶段需要设置不同大小。在 算法搜索初期, 为了增强原子的全局搜索能 力, 让 λ \lambda λ 取较大的值, β \beta β 取较小的值, 这样 可以使原子在整个可行空间进行搜索。在搜 索后期, λ \lambda λ 取较小的值, β \beta β 取较大的值, 可 以使原子快速收敛于最优值。所以随着迭代 次数的增加, λ \lambda λ 逐渐变大, β \beta β 逐渐变小, 基 于此本文对两个参数采取自适应更新策略, 平衡全局信息与局部信息, 提高信息利用率。 β \beta β 和 λ \lambda λ 的自适应更新公式如下(16)所示:
β = β max + ( β min − β max ) × T − t T − 1 \beta=\beta_{\text {max }}+\left(\beta_{\text {min }}-\beta_{\text {max }}\right) \times \frac{T-t}{T-1} β=βmax +(βmin −βmax )×T−1T−t
λ = λ min + ( λ max − λ min ) × T − t T − 1 \lambda=\lambda_{\text {min }}+\left(\lambda_{\text {max }}-\lambda_{\text {min }}\right) \times \frac{T-t}{T-1} λ=λmin +(λmax −λmin )×T−1T−t
其中 β min , λ min \beta_{\text {min }}, \lambda_{\text {min }} βmin ,λmin 分别为参数的最小值; β max \beta_{\text {max }} βmax , λ max \lambda_{\max } λmax 为最大值。可知 β \beta β 和 λ \lambda λ 都在 [ 0.1 ] [0.1] [0.1] 之间变 化。
2.3高斯变异策略
A S O \mathrm{ASO} ASO 优化算法在更新原子全局最优位 置的过程中, 原子通常会表现出早熟的现象, 整个原子种群进入搜索停滞, 陷入局部极值。 为了加快原子的收玫速度, 提高原子跳出早 熟的能力, 将高斯变异策略 [ 18 ] { }^{[18]} [18] 引入 IASO 算 法的原子位置更新中, 加入高斯变异因子对 原子位置进行扰动, 使之产生新的位置继续 进行更新。在对原子位置进行高斯变异之前, 首先进行变异系数判断, 变异系数是衡量一 组数据离散程度的一个归一化量度, 变异系 数的定义为如下(17)所示:
c v = δ μ c_{v}=\frac{\delta}{\mu} cv=μδ
其中 c v c_{v} cv 是变异系数; δ \delta δ 是标准差; μ \mu μ 是 平均值。
IASO 算法提前设置一个变异系数阈值 c s t d c_{s t d} cstd, 为了保持算法的效率, 变异系数不宜过 大, 本文设置 c s t d = 0.1 c_{s t d}=0.1 cstd=0.1, 算法前期迭代收敛 性一般较好, 迭代中后期易陷入局部最优解, 在算法进行 T / 5 T / 5 T/5 次迭代之后, 再根据变异系 数适时采用高斯变异。对相邻三次的迭代结 果求取高斯变异系数 s t d Y ( t ) s t d Y(t) stdY(t), 其求解公式如 下(18)所示:
std Y ( t ) = ∑ i = 1 − 2 ′ ( y best i − mean Y ( t ) ) 2 mean Y ( t ) \operatorname{std} Y(t)=\frac{\sqrt{\sum_{i=1-2}^{\prime}\left(y_{\text {best }}^{i}-\text { mean } Y(t)\right)^{2}}}{\operatorname{mean} Y(t)} stdY(t)=meanY(t)∑i=1−2′(ybest i− mean Y(t))2
其中 t t t 是当前迭代次数, y b e s t i y_{b e s t}^{i} ybesti 是第 i i i 次 迭代的最优解, mean Y ( t ) Y(t) Y(t) 是三次迭代结果 y best y_{\text {best }} ybest 的平均值, 其定义如下(19)所示:
mean Y ( t ) = ∑ i = t − 1 i y b e s i 3 \operatorname{mean} Y(t)=\frac{\sum_{i=t-1}^{i} y_{b e s}^{i}}{3} meanY(t)=3∑i=t−1iybesi
如果 std Y ( t ) > c s t d \operatorname{std} Y(t)>c s t d stdY(t)>cstd, 说明每次迭代的最优 解 y best y_{\text {best }} ybest 变化较大, 算法的收玫性仍然较好, 此时对原子位置更新不采用高斯扰动, 如果 s t d Y ( t ) < c s t d s t d Y(t)<c s t d stdY(t)<cstd, 则说明迭代结果 y best y_{\text {best }} ybest 变化不大, 算法陷入了局部停滞, 此时对原子的位置进 行高斯变异扰动更新, 提高原子的多样性, 跳出局部极值。加入高斯变异后的原子位置 更新公式如下(20)所示:
x i d ( t ) ‾ = r i ⊗ x i d ( t ) + Gaussian ⊗ ( x b e s t d ( t ) − x i d ( t ) ) \overline{x_{i}^{d}(t)}=r_{i} \otimes x_{i}^{d}(t)+\text { Gaussian } \otimes\left(\quad x_{best}^{d}(t)-x_{i}^{d}(t))\right. xid(t)=ri⊗xid(t)+ Gaussian ⊗(xbestd(t)−xid(t))
( 20 ) (20) (20)
其中 r i r_{i} ri 为服从 0-1 之间均匀分布的随机 数; Gaussian N ( 0 , 1 ) , x i d ( t ) N(0,1), x_{i}^{d}(t) N(0,1),xid(t) 是第 t t t 次迭代原 子位置, x i d ( t ) ‾ \overline{x_{i}^{d}(t)} xid(t) 是加高斯扰动后的原子位置。 IASO 算法流程图
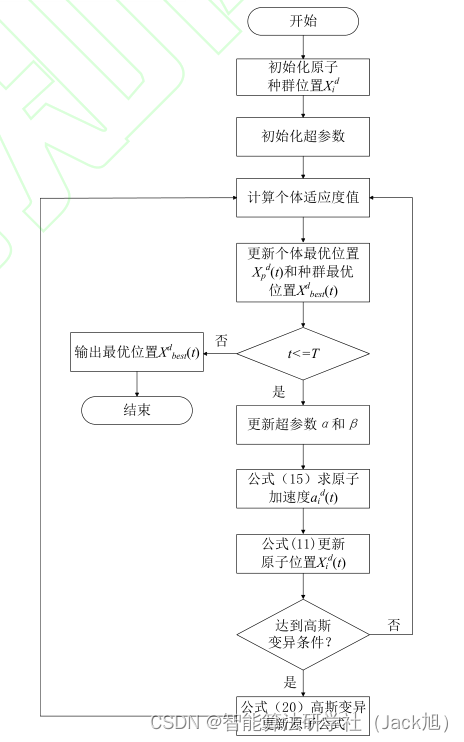
3.实验结果

4.参考文献
[1]李建锋,卢迪,李贺香.一种改进的原子搜索算法[J/OL].系统仿真学报:1-13[2021-05-06].http://kns.cnki.net/kcms/detail/11.3092.V.20210409.1508.008.html.