原文链接: https://www.cnblogs.com/JunhaoWu/p/bayes_filter.html
粒子滤波确实是一个挺复杂的东西,从接触粒子滤波到现在半个多月,博主哦勒哇看了N多篇文章,查略了嗨多资料,很多内容都是看了又看,细细斟酌。今日,便在这里验证一下自己的修炼成果,请各位英雄好汉多多指教。
讲粒子滤波之前,还得先讲一个叫”贝叶斯滤波”的东西,因为粒子滤波是建立在贝叶斯滤波的基础上的哩。说太多抽象的东西也很难懂,以目标跟踪为例,直接来看这东西是怎么回事吧:
1. 首先咋们建立一个动态系统,用来描述跟踪目标在连续时间序列上的变换情况。简单一点,我们就使用目标的位置(i,j)作为这个动态系统的状态吧。
那怎么描述呢?
我们使用状态xt来描述系统在时刻t的状态,在这个例子中,xt=(it,jt);使用yt表示在时刻t目标的观测值。这里请注意,xt是我们建立的模型中,目标的位置,而目标的实际位置不一定与之相等。举个简单的例子就是:一部小车做匀加速直线运动,xt是我们用公式计算出来的小车的位置,yt是我们用GPS定位到的位置。
由于误差的存在,光靠理论公式计算得出来的结果肯定是有偏差的。但是,GPS又卡又慢,要靠它来完成我们的目标跟踪貌似也不是很靠谱。那我们做一下折衷吧,先用理论计算得到目标的位置,然后用观测值进行修正,使得我们的模型更加完美。
额!完美吗?不害臊!你理论得出来的不准确,然后还要靠又卡又慢的GPS来修正,还好意思跟我说完美!你怎么不上天,跟太阳肩并肩。再说了,你修正后的位置还不一定是准确了,要我说目标也可能就在计算到的位置,也可能在它东边、西边、南边、北边、东南边......
咔咔咔!行行行,我错了还不行么。你这人真是急躁,喝口茶消消气,再听我细细说来。前面那位大爷说的在理,咋们得听,嗯,我猜他应该是太阳的后裔,哈哈哈!跑题了。
是啊!目标的位置可能在好多个位置,有各种可能性,毕竟我们并没有得到一个准确的值。咦!那我们可以用概率来描述啊!这种不确定性不就是概率论里面说的那些东西吗?天呐,我好激动,修炼多年的概率论终于派上用场了。而且你看哦,用观测值yt对xt进行修正,这不就是说先得到先验概率p(xt),然后获取到更加丰富的信息yt后,对先验概率进行修正,得到后验概率p(xt|yt)吗?哇哇哇!贝叶斯,贝叶斯,这就是贝叶斯啊,条件概率啊!!!
2. 贝叶斯滤波
嗯嗯嗯,对对对,楼上正解。从贝叶斯理论的观点来看,状态估计问题(目标跟踪,信号滤波)就是根据之前一系列已有数据y1:t(后验只是)递推计算出当前状态xt的可信度。这个可信度就是概率公式p(xt|y1:t)。贝叶斯滤波通过预测和更新这两个步骤来递推计算xt的可信度。
预测过程是利用系统模型预测状态xt的先验概率密度,也就是通过已有的先验知识对未来系统的状态进行猜测,
更新过程是利用新的观测值yt对先验概率密度进行修正,得到后验概率密度。
3. 公式及推导
贝叶斯滤波的公式是酱紫的:
预测:
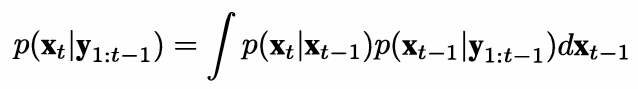
更新:
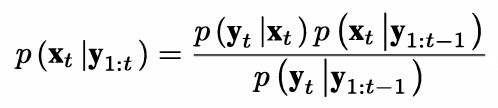
在推导之前,一些预备知识还是要的。贝叶斯公式(就是条件概率公式啦),全概率公式,样本空间的概念和完备事件组的概念。这些知识对推导过程的理解尤为重要,建议各位先了解一下这些概念。
还要提一下,动态系统中的状态转移问题,一般都先假设其服从一阶马尔科夫(Markov)模型,即
①当前时刻的状态xt只与上一时刻的状态xt-1有关;
②t时刻的观测值yt只与当前的状态xt有关。
下面进行贝叶斯滤波公式的推导:
预测:

哈哈!博主比较懒,直接上图了,字比较丑,见谅见谅。第一行是一个全概率公式的应用,然后第二第三第四行都是条件概率啦!最后一行是根据假设①来着。
这里你可能有一个问题,既然都说前时刻的状态xt只与上一时刻的状态xt-1有关,跟yt没半毛钱关系,即p(xt|xt-1)。那你弄一个p(xt|y1:t-1)是几个意思?
莫说你要问了,我当初可是也纠结了好久。说到底,这两个概率公式含义不一样。p(xt|xt-1)是纯粹根据模型进行预测(计算),啪,xt-1进去,公式一算,xt出来了,简单明了。p(xt|y1:t-1)这一个呢,是说既然我们已经拿到了一组数据,这些数据跟系统状态也是有关系的,那我们就可以根据这些数据来猜呀,只是猜测而已呐。(楼主yy:那... 你猜我猜不猜?)
更新:
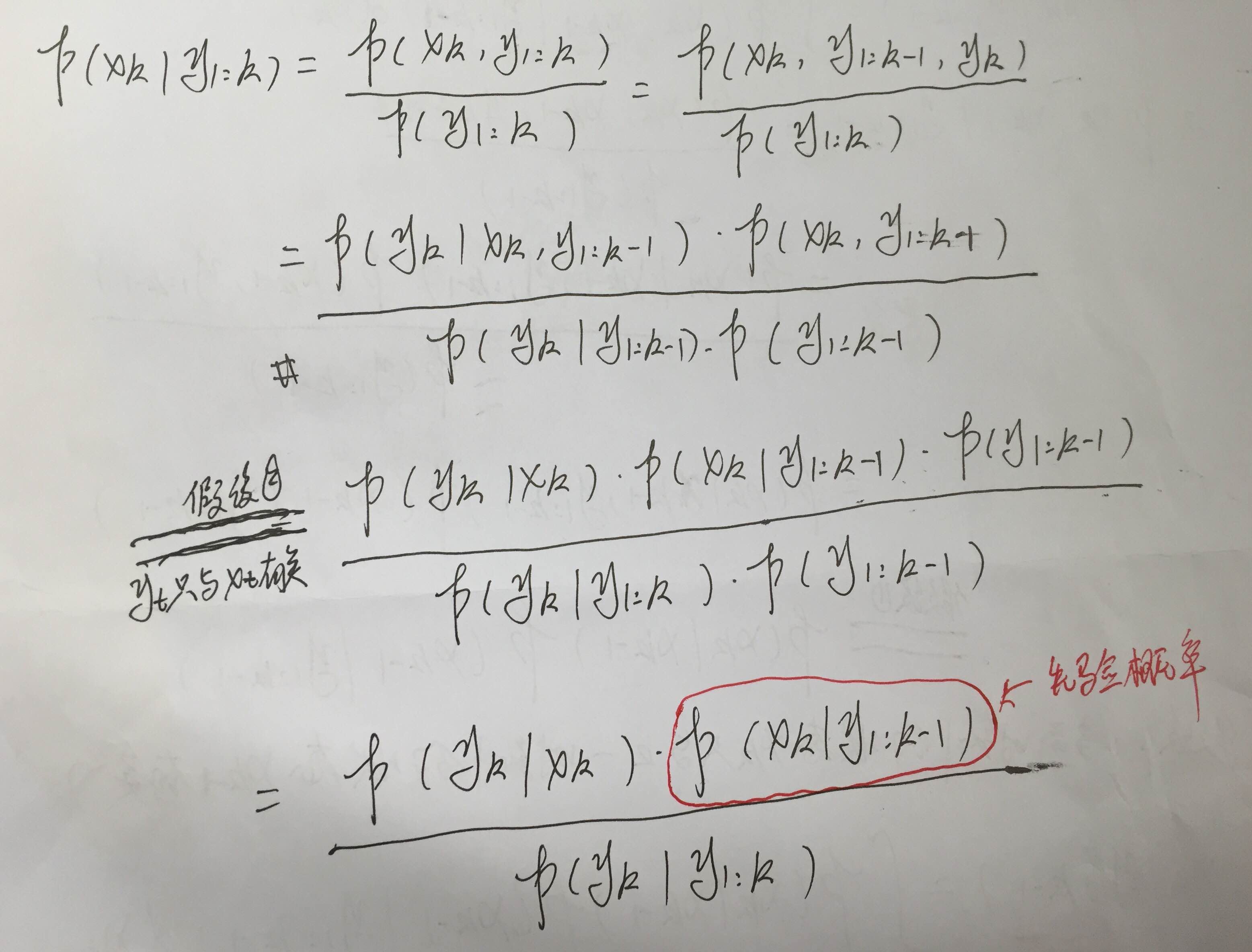
第三行是根据假设②,其他的全都是条件概率公式的应用。 上图中倒数第二行的分母有错误,应该是P(y_k| y_(1:k-1))
这里你应该跟我一样,也还有一个问题,就是既然yt只与xt有关,那分母的p(yt|y1:t)为什么不直接写成p(yt)啊!!!
关于这个问题,其实,我也不知道。要不你们也研究一下咯,然后拜托告诉我一声。
However,当贝叶斯滤波碰到了粒子滤波,这些推导完全不重要。哈哈哈!就是说我们推了半天没用,好想哭。。。
粒子滤波使用N个加权的样本(即粒子)来近似表示后验概率密度p(xt|y1:t)。因为有些问题系统状态变换很难建模嘛,公式都没有,xt没法产生啊!所以就撒样本呗,用样本的分布来近似状态xt的真实分布。
预知后事如何,请听下回分解。