在理解粒子滤波的概念之前,先来了解一些基本概念。
蒙特卡罗方法和拉斯维加斯方法
知乎里面有个很好的解释:链接:https://www.zhihu.com/question/20254139/answer/14499889
蒙特卡罗是一类随机方法的统称。这类方法的特点是,可以在随机采样上计算得到近似结果,随着采样的增多,得到的结果是正确结果的概率逐渐加大,但在(放弃随机采样,而采用类似全采样这样的确定性方法)获得真正的结果之前,无法知道目前得到的结果是不是真正的结果。
举例说明,一个有10000个整数的集合,要求其中位数,可以从中抽取m<10000个数,把它们的中位数近似地看作这个集合的中位数。随着m增大,近似结果是最终结果的概率也在增大,但除非把整个集合全部遍历一边,无法知道近似结果是不是真实结果。
另外一个例子,给定数N,要求它是不是素数,可以任选m个小于N的数,看其中有没有能整除N的数,如果没有则判断为素数。这和通常见到的蒙特卡罗例子不同,近似结果往往错得更离谱,但随着m增大,近似结果是最终结果的概率也在增大。
把蒙特卡罗方法和另外一类方法——拉斯维加斯方法[1]——对比一下,更容易了解哪些方法属于蒙特卡罗,哪些不属于。拉斯维加斯方法是另一类随机方法的统称。这类方法的特点是,随着采样次数的增多,得到的正确结果的概率逐渐加大,如果随机采样过程中已经找到了正确结果,该方法可以判别并报告,但在但在放弃随机采样,而采用类似全采样这样的确定性方法之前,不保证能找到任何结果(包括近似结果)。
举例说明,有一个有死胡同但无环路的迷宫,要求从入口走到出口的一条路径。可以从入口出发,在每个叉路口随机选择一个方向前行,到死胡同则报告失败并回到入口重新试探,到出口则报告成功。随着试探次数增多,找到一条入口到出口的路径的概率增大,但除非全枚举,即使试10000年,也无法保证找到任何要求的路径。
先验概率, 后验概率和似然函数
网上的一个例子:
- 先验——根据若干年的统计(经验)或者气候(常识),某地方下雨的概率;
- 似然——下雨(果)的时候有乌云(因/证据/观察的数据)的概率,即已经有了果,对证据发生的可能性描述;
- 后验——根据天上有乌云(原因或者证据/观察数据),下雨(结果)的概率; 后验 ~ 先验*似然 :
存在下雨的可能(先验),下雨之前会有乌云(似然)~ 通过现在有乌云推断下雨概率(后验););
瓜熟蒂落的例子
- 先验概率,就是常识、经验所透露出的“因”的概率,即瓜熟的概率。应该很清楚。
- 后验概率,就是在知道“果”之后,去推测“因”的概率,也就是说,如果已经知道瓜蒂脱落,那么瓜熟的概率是多少。后验和先验的关系可以通过贝叶斯公式来求。也就是:
- 似然函数,是根据已知结果去推测固有性质的可能性(likelihood),是对固有性质的拟合程度,所以不能称为概率。在这里就是说,不要管什么瓜熟的概率,只care瓜熟与蒂落的关系。如果蒂落了,那么对瓜熟这一属性的拟合程度有多大。似然函数,一般写成L(瓜熟 | 已知蒂落),和后验概率非常像,区别在于似然函数把瓜熟看成一个肯定存在的属性,而后验概率把瓜熟看成一个随机变量。
先验分布:根据一般的经验认为随机变量应该满足的分布
后验分布:通过当前训练数据修正的随机变量的分布,比先验分布更符合当前数据
似然估计:已知训练数据,给定了模型,通过让似然性极大化估计模型参数的一种方法
后验分布往往是基于先验分布和极大似然估计计算出来的。
粒子滤波
文章来源:https://www.zhihu.com/question/25371476/answer/31552082
百度百科定义:
粒子滤波(PF: Particle Filter)的思想基于蒙特卡洛方法(Monte Carlo methods),它是利用粒子集来表示概率,可以用在任何形式的状态空间模型上。其核心思想是通过从后验概率中抽取的随机状态粒子来表达其分布,是一种顺序重要性采样法(Sequential Importance Sampling)。简单来说,粒子滤波法是指通过寻找一组在状态空间传播的随机样本对概率密度函数进行近似,以样本均值代替积分运算,从而获得状态最小方差分布的过程。这里的样本即指粒子,当样本数量N→∝时可以逼近任何形式的概率密度分布。
知乎上面有个基于Rob Hess的放狗的讲解,很形象。Rob Hess之前有实现了一种Sampling Importance Resampling (SIR),根据重要性重采样。主要有下面几个步骤:
1)初始化阶段-提取跟踪目标特征
该阶段要人工指定跟踪目标,程序计算跟踪目标的特征,比如可以采用目标的颜色特征。具体到Rob Hess的代码,开始时需要人工用鼠标拖动出一个跟踪区域,然后程序自动计算该区域色调(Hue)空间的直方图,即为目标的特征。直方图可以用一个向量来表示,所以目标特征就是一个N*1的向量V 列表内容
2)索阶段-放狗
我们已经掌握了目标的特征,下面放出很多条狗,去搜索目标对象,这里的狗就是粒子particle。狗有很多种放法。比如,a)均匀的放:即在整个图像平面均匀的撒粒子(uniform distribution);b)在上一帧得到的目标附近按照高斯分布来放,可以理解成,靠近目标的地方多放,远离目标的地方少放。Rob Hess的代码用的是后一种方法。狗放出去后,每条狗怎么搜索目标呢?就是按照初始化阶段得到的目标特征(色调直方图,向量V)。每条狗计算它所处的位置处图像的颜色特征,得到一个色调直方图,向量Vi,计算该直方图与目标直方图的相似性。相似性有多种度量,最简单的一种是计算sum(abs(Vi-V)).每条狗算出相似度后再做一次归一化,使得所有的狗得到的相似度加起来等于1.
3)决策阶段
我们放出去的一条条聪明的狗向我们发回报告,“一号狗处图像与目标的相似度是0.3”,“二号狗处图像与目标的相似度是0.02”,“三号狗处图像与目标的相似度是0.0003”,“N号狗处图像与目标的相似度是0.013”…那么目标究竟最可能在哪里呢?我们做次加权平均吧。设N号狗的图像像素坐标是(Xn,Yn),它报告的相似度是Wn,于是目标最可能的像素坐标X = sum(Xn*Wn),Y = sum(Yn*Wn).
4)重采样阶段Resampling
既然我们是在做目标跟踪,一般说来,目标是跑来跑去乱动的。在新的一帧图像里,目标可能在哪里呢?还是让我们放狗搜索吧。但现在应该怎样放狗呢?让我们重温下狗狗们的报告吧。“一号狗处图像与目标的相似度是0.3”,“二号狗处图像与目标的相似度是0.02”,“三号狗处图像与目标的相似度是0.0003”,“N号狗处图像与目标的相似度是0.013”…综合所有狗的报告,一号狗处的相似度最高,三号狗处的相似度最低,于是我们要重新分布警力,正所谓好钢用在刀刃上,我们在相似度最高的狗那里放更多条狗,在相似度最低的狗那里少放狗,甚至把原来那条狗也撤回来。这就是Sampling Importance Resampling,根据重要性重采样(更具重要性重新放狗)。
(2)->(3)->(4)->(2)如是反复循环,即完成了目标的动态跟踪。
Particle Filter C++的实现
在知乎https://zhuanlan.zhihu.com/p/37502749里面有个粒子滤波的实现
知乎的作者林明用的是Udacity的Simulator,Udacity的仿真器是用Unity做的。
仿真器提供Landmark(以下称为地标)的X, Y 坐标。 这些个地标的位置就是完全正确的位置,也就是Ground truth data。 仿真器里的车自身带有传感器,可以感知某个障碍物,并得到障碍物相对于我的位置信息。
那么从宏观上来看,本次项目的目的是让车辆知道自己在哪里。那么对于车辆来说,输入和输出就明确了。
输入: Map 数据。车辆传感器数据(包括速度,转向角,障碍物方位感知)
输出: 车辆在Map上的坐标
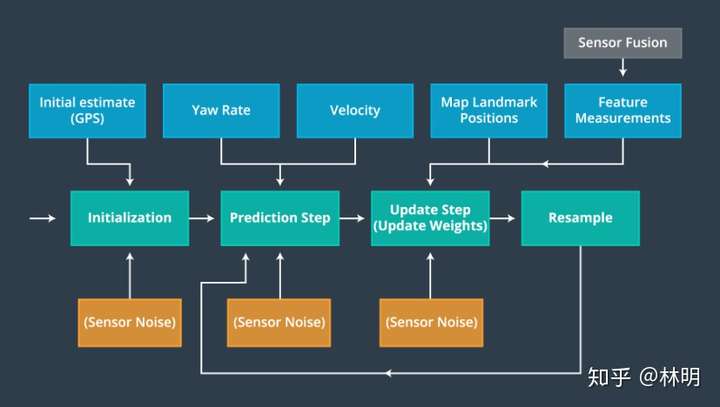
首先整个PF的构建都围绕着一下内容展开。从下图的箭头顺序可以看出,依次是初始化,预测,更新粒子状态及粒子的权重,重采样。
简单解释一下,初始化,就是定义传感器的噪声也就是sigma等参数和获取第一批GPS信号(Groud Truth x,y坐标)。预测过程就是根据车辆的yaw rate ,velocity 数据 + re-sample之后的各个粒子的值和其权重等,预测下一个sample time 之后的自身位置。在update step,根据自身预测的位置,传感器数据更新自身位置,最后通过重采样对各个粒子的权重进行重新采样。
林明github地址:https://github.com/Fred159/CarND-Kidnapped-Vehicle-Project,上面有完整代码。