学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
如果想学习 Python 数据分析,其中必掌握的一个数据处理技巧就是排序。可以极大的加速处理数据的效率。Pandas 使用的数据排序的方法有 .sort_values() 和 .sort_index() 。

文章目录
Pandas 排序方法入门
DataFrame 是一种带有标记的行和列的数据结构,能按行或列值以及行或列索引对数据进行排序。 DataFrame 中行和列索引是用数字表示,可以使用索引位置从特定行或列中检索数据。
默认情况下索引号从零开始,也可以手动分配自己的索引。
数据准备
import pandas as pd
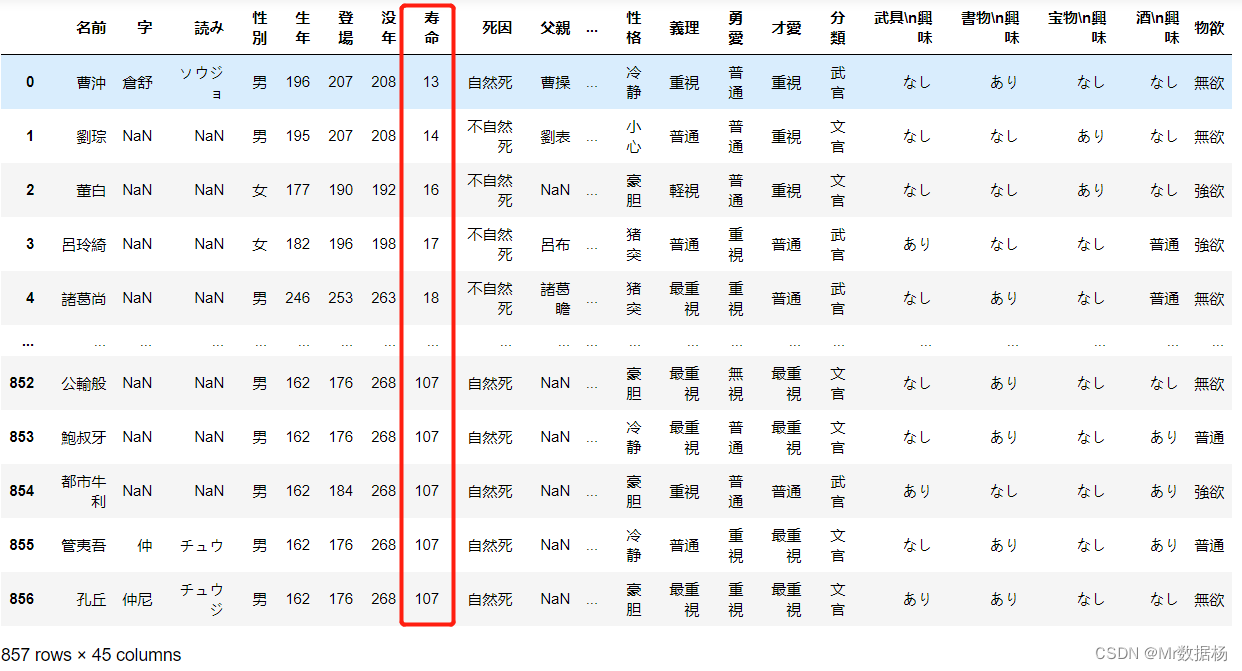
df = pd.read_excel("Romance of the Three Kingdoms 13/人物详情数据.xlsx")
df.head()
.sort_values()
类似 Excel 中的值排序,在 DataFrame 中使用 .sort_values() 沿任一轴(列或行)对值进行排序。
.sort_index()
使用 .sort_index() 通过行索引或列标签对 DataFrame 进行排序。
DataFrame 单列数据排序
.sort_values() 默认情况返回一个按升序排序的新 DataFrame ,并且不会修改原始 DataFrame。
按升序按列排序
使用 .sort_values() 排序要将单个参数传递给包含要排序的列的名称的方法。
df.sort_values("生年")
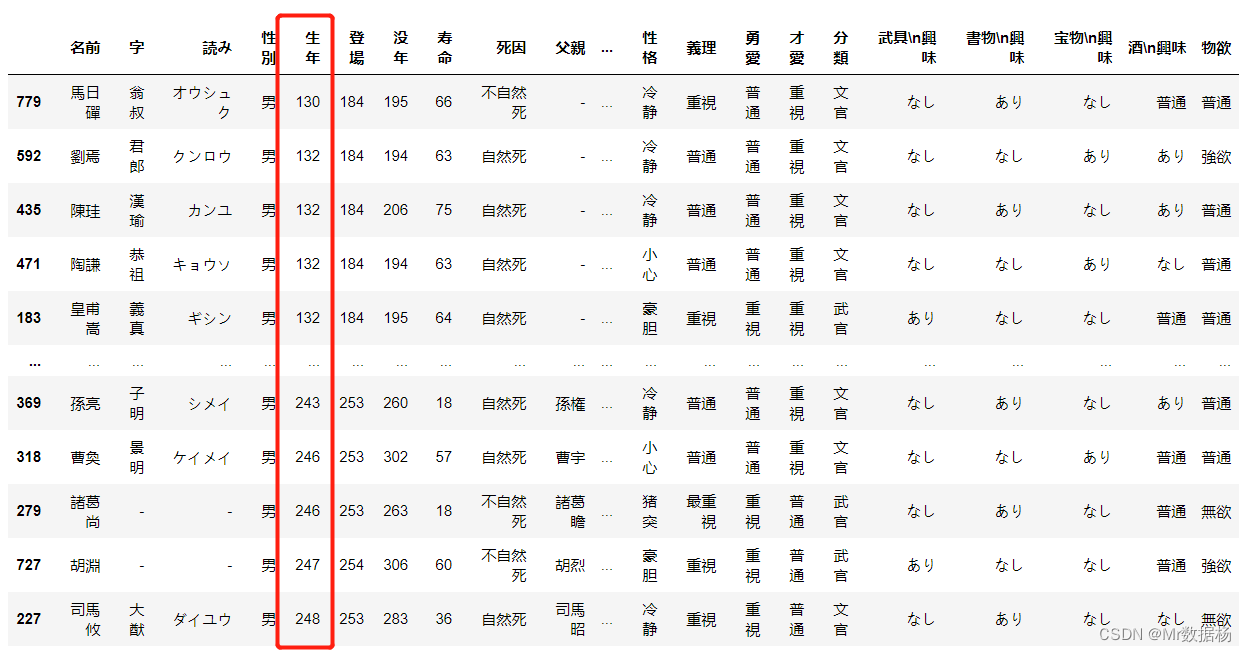
排序顺序调整
默认情况下 .sort_values() ascending 设置为 True(升序排列)。如果按降序排序则设置为 False 。
df.sort_values("生年",ascending=False)
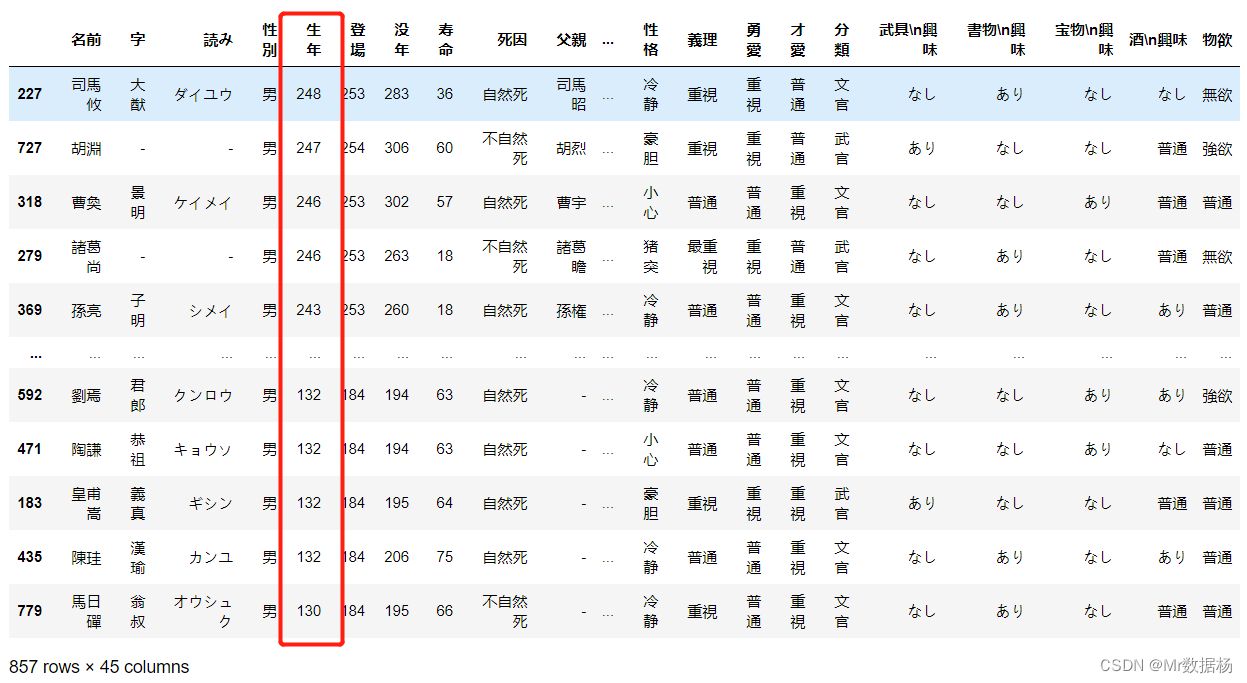
选择排序算法
可用的算法有 快速排序(quicksort) 、归并排序(mergesort) 、堆排序(heapsort)。
df.sort_values(by="city08",ascending=False,kind="mergesort")
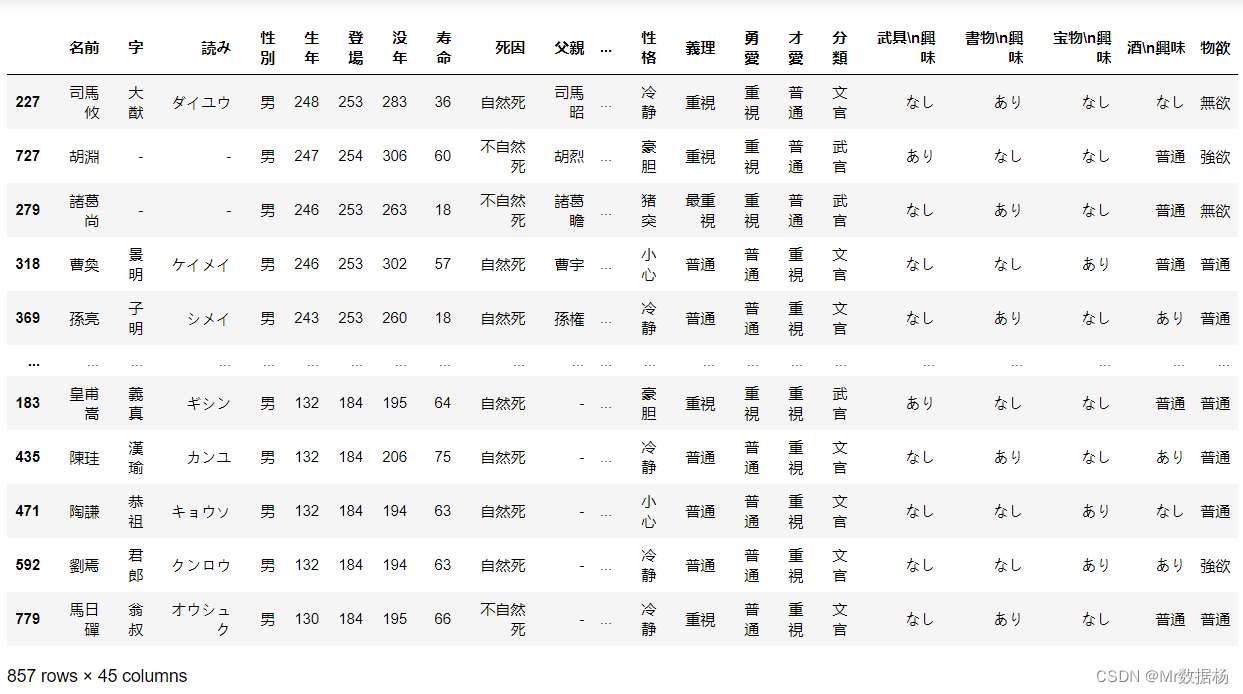
DataFrame 多列数据排序
按两个键排序,可以将列名列表by传递。
升序按列排序
要在多列上对 DataFrame 进行排序,必须提供列名列表。
df.sort_values(by=["生年", "寿命"])[["生年", "寿命"]]
生年 寿命
779 130 66
471 132 63
592 132 63
183 132 64
435 132 75
... ... ...
369 243 18
279 246 18
318 246 57
727 247 60
227 248 36
857 rows × 2 columns
更改列排序顺序
调整排序 by 列表的的顺序。
df.sort_values(by=["寿命","生年"])[["寿命","生年"]]
寿命 生年
335 13 196
605 14 195
794 16 177
679 17 182
369 18 243
... ... ...
822 107 162
843 107 162
844 107 162
845 107 162
851 107 162
857 rows × 2 columns
降序按多列排序
df.sort_values(by=["寿命","生年"],ascending=False)[["寿命","生年"]]
寿命 生年
811 107 162
822 107 162
843 107 162
844 107 162
845 107 162
... ... ...
369 18 243
679 17 182
794 16 177
605 14 195
335 13 196
857 rows × 2 columns
不同排序顺序的多列排序
使用多个列进行排序并让这些列使用不同的 ascending 参数。pandas 可以通过单个方法调用来完成此操作。如果要按升序对某些列进行排序,而按降序对某些列进行排序,则可以将布尔值列表传递给 ascending 即可。
df.sort_values(
by=["寿命","生年","登場"],
ascending=[True, True, False]
)[["寿命","生年","登場"]]
寿命 生年 登場
335 13 196 207
605 14 195 207
794 16 177 190
679 17 182 196
369 18 243 253
... ... ... ...
811 107 162 176
822 107 162 176
843 107 162 176
844 107 162 176
845 107 162 176
857 rows × 3 columns
DataFrame 索引排序
DataFrame 有一个.index 属性,默认表示行位置的数字。索引可以视为行号,有助于快速查找和识别行(功能同 MySQL)。
索引升序排序
使用 .sort_index() 根据行索引对 DataFrame 进行排序。
使用 .sort_values() 创建一个新的排序 DataFrame 进行后续的操作。
sorted_df = df.sort_values(by=["make", "model"])
sorted_df
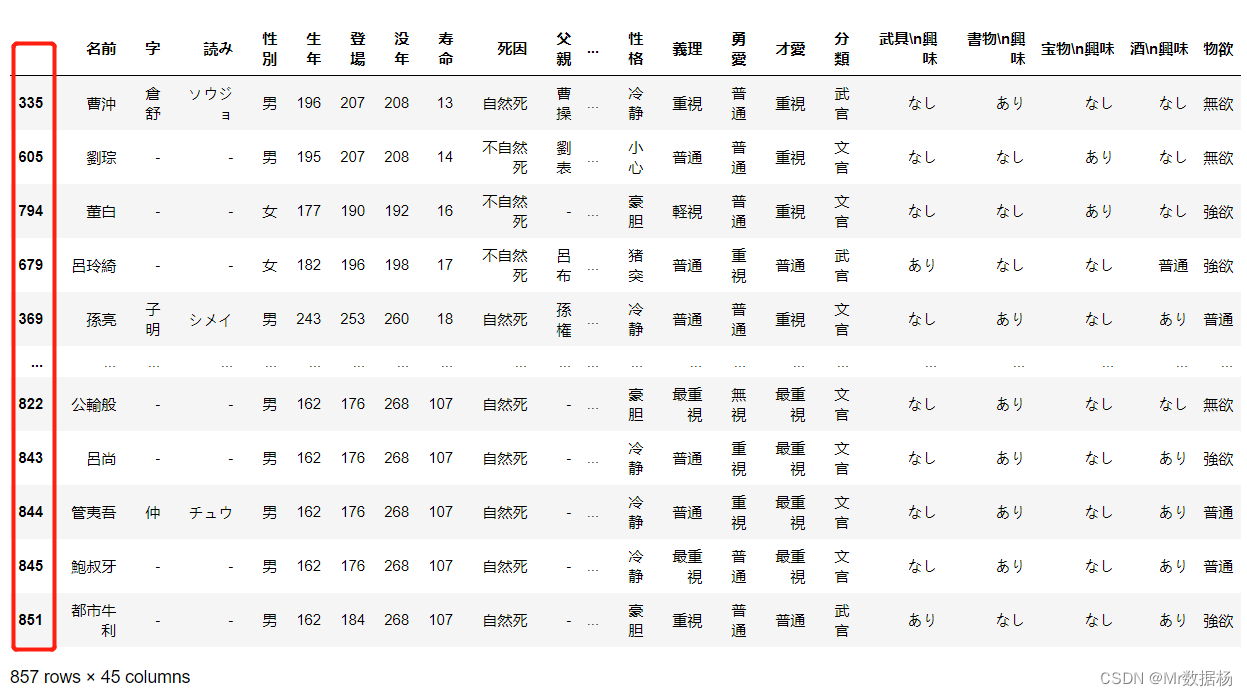
使用 .sort_index() 恢复 DataFrame 原始顺序。
sorted_df.sort_index()
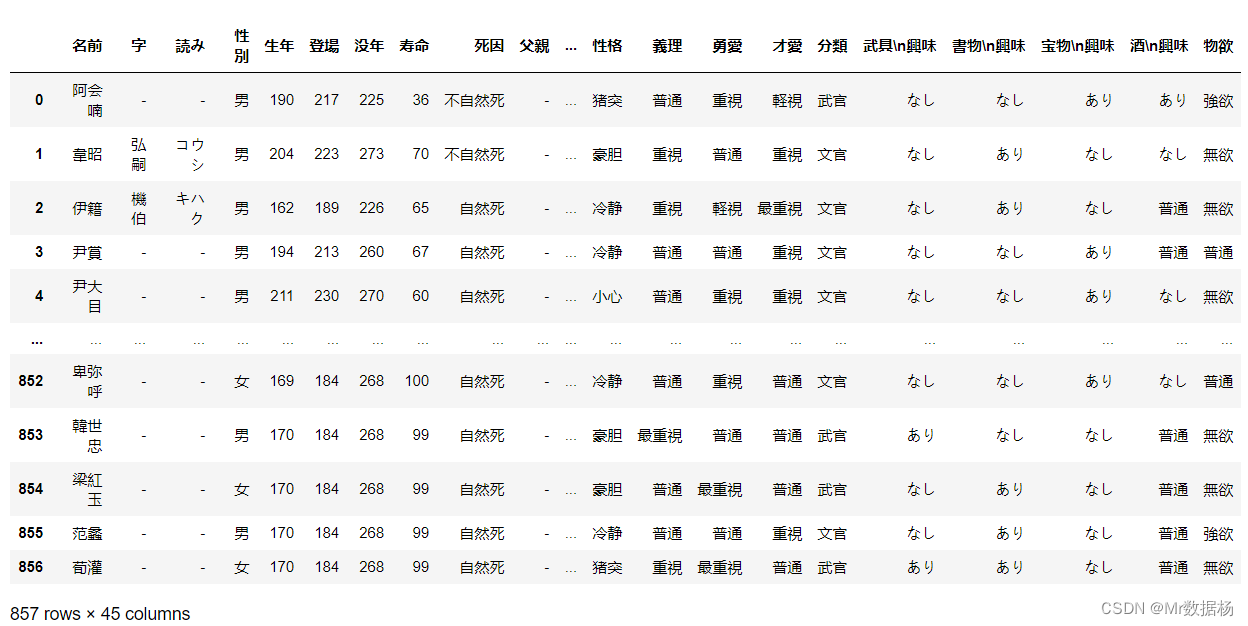
使用 bool 进行判断。
sorted_df.sort_index() == df
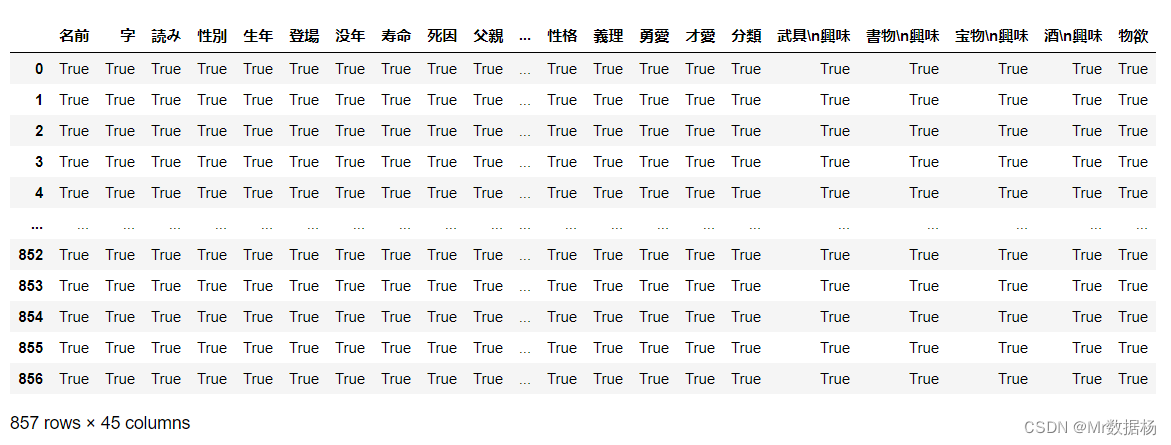
可以自定义索引分配了 .set_index() 设置列表进行参数传递。
assigned_index_df = df.set_index(["寿命","生年"])
assigned_index_df
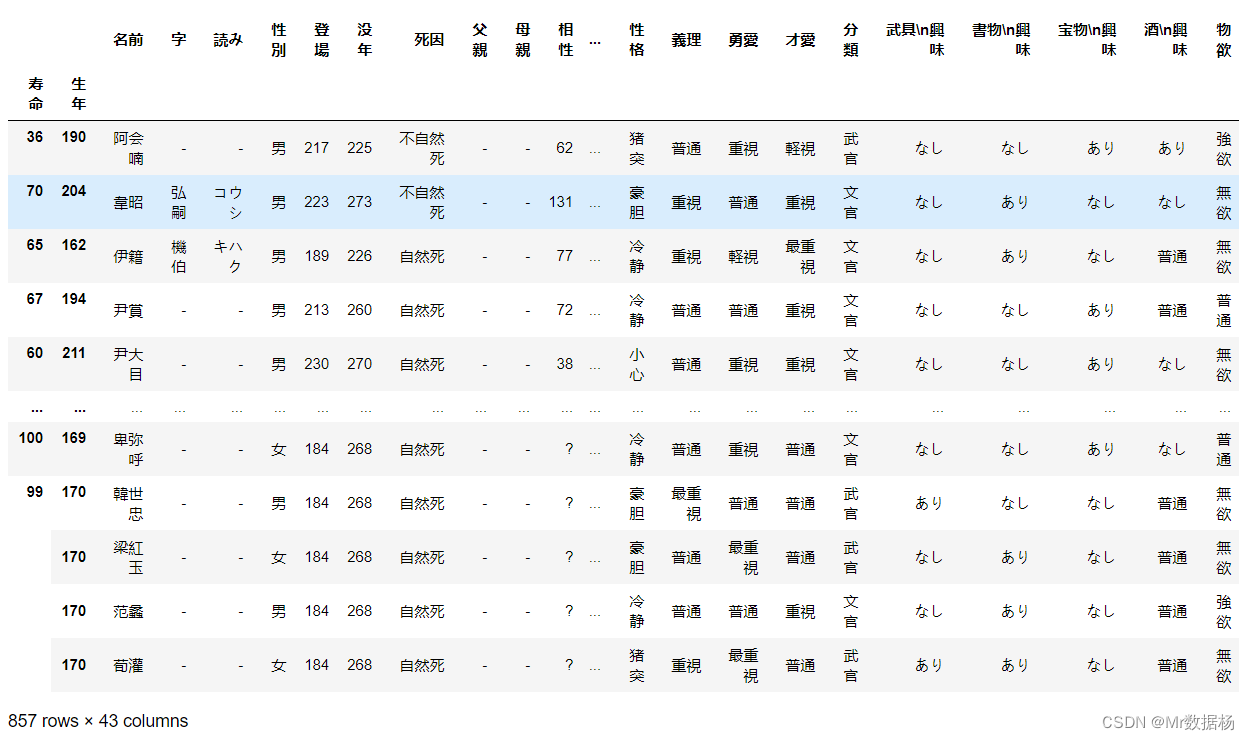
使用 .sort_index() 进行排序。
assigned_index_df.sort_index()
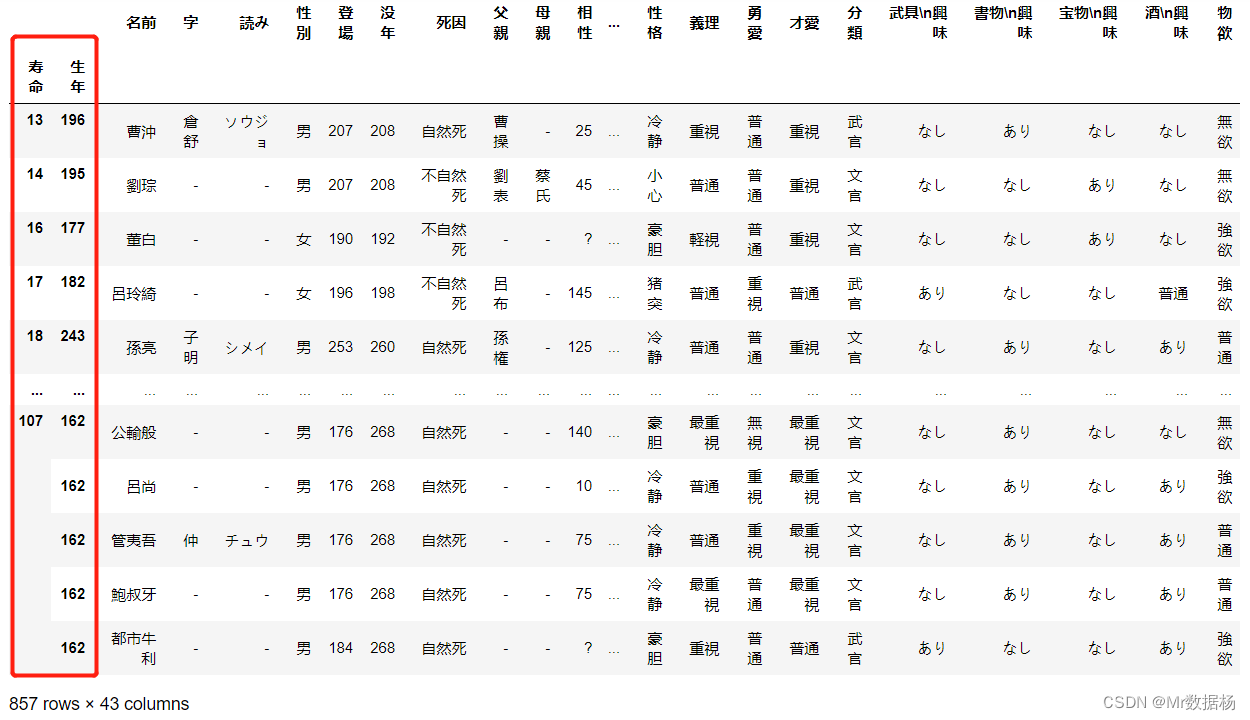
索引降序排序
assigned_index_df.sort_index(ascending=False)
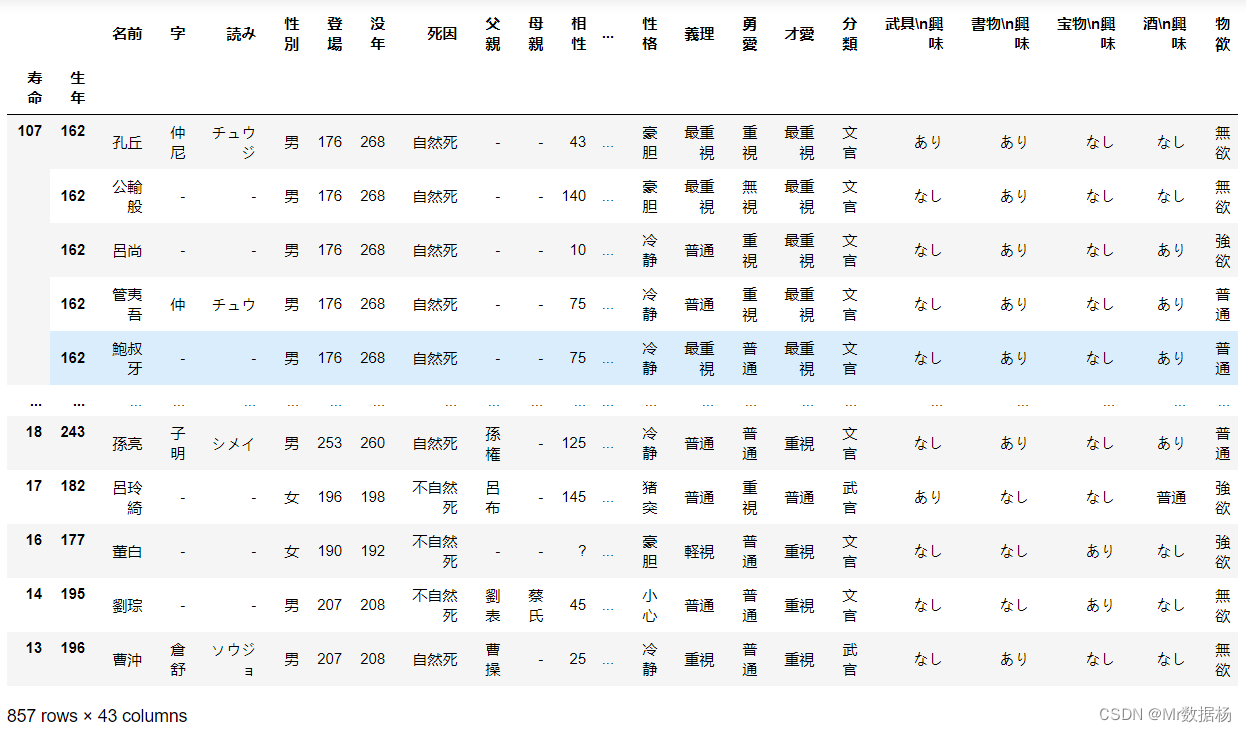
DataFrame 列排序
使用 DataFrame 的列标签对行值进行排序。 使用 .sort_index() 并将可选参数轴设置为 1 将按列标签对 DataFrame 进行排序。
DataFrame 的轴是指索引(axis=0)或列(axis=1)。 可以使用这两个轴来索引和选择 DataFrame 中的数据以及对数据进行排序。
列标签排序
df.sort_index(axis=1)
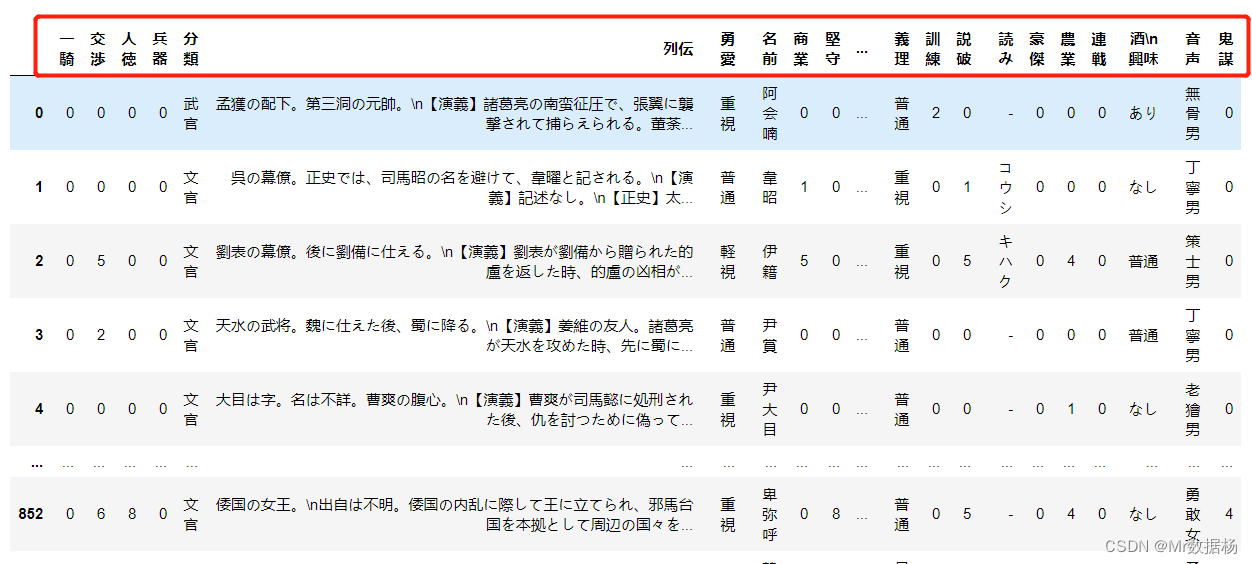
df.sort_index(axis=1, ascending=False)
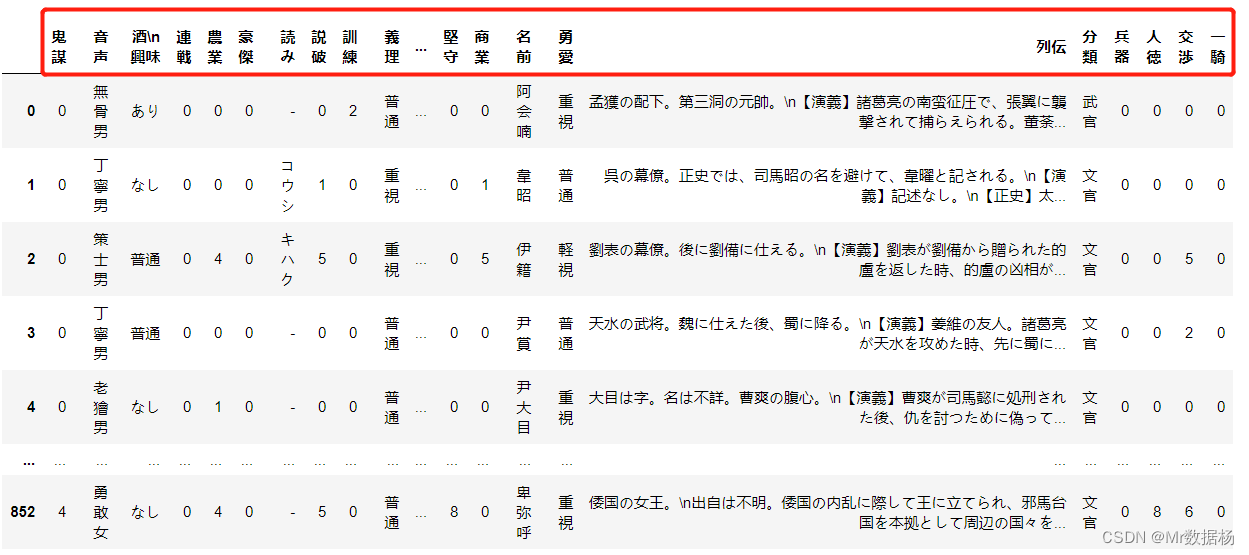
排序时处理丢失的数据
使用 na_position 参数执行此缺失数据列的排序操作。
df["mpgData_"] = df["mpgData"].map({
"Y": True})
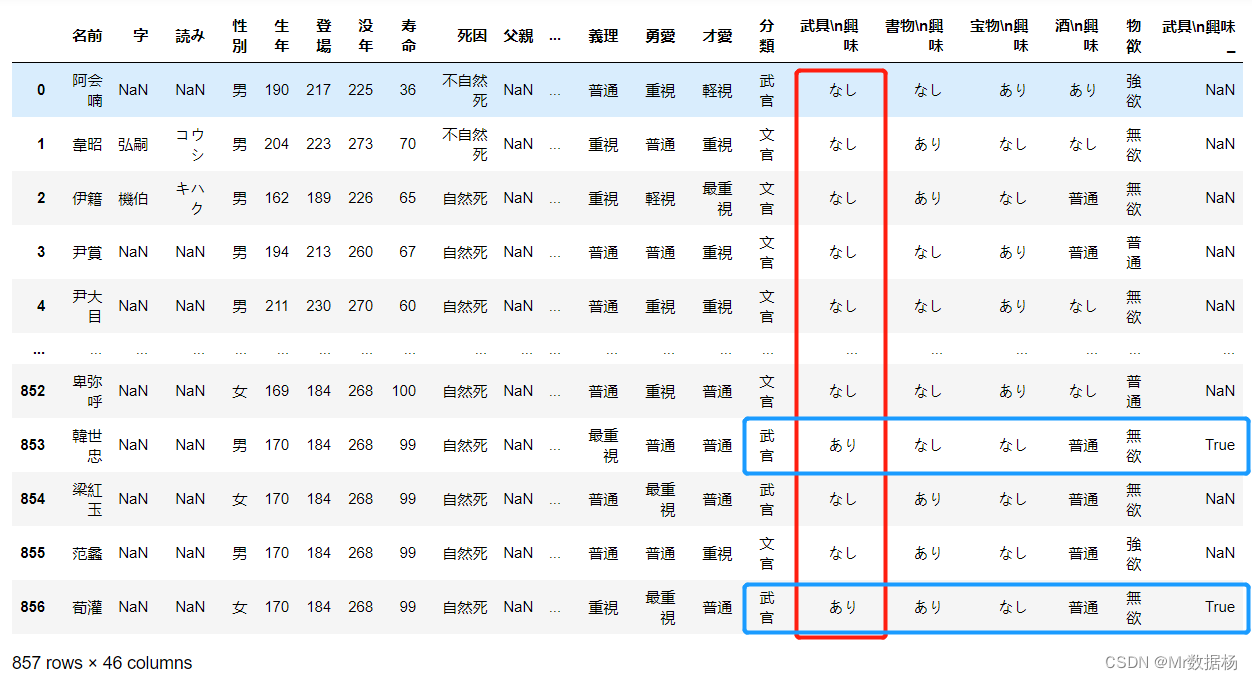
na_position 的 .sort_values()
.sort_values() 接受一个名为 na_position 的参数,该参数有助于处理要排序的列中的缺失数据。
df.sort_values(by="mpgData_",na_position="first")
用于排序的列中的任何缺失数据都将显示在 DataFrame 的前面。用于查看列的缺失值情况。
DataFrame 排序修改
在 .sort_values() 中增加重要的参数 inplace=True。作用在于直接对原始的 DataFrame 进行修改。
df.sort_values("寿命",inplace=True)
df.reset_index(drop=True,inplace=True)
df