无论是刚刚了解数据集还是准备发布相关分析结果,其中可视化都是必不可少的工具。Python 流行的数据分析库pandas提供了几种不同的选项来使用**.plot()** 即使正处于 Pandas 之旅的起步阶段也能很快就会创建基本图,从而对数据产生有价值的见解。
数据准备
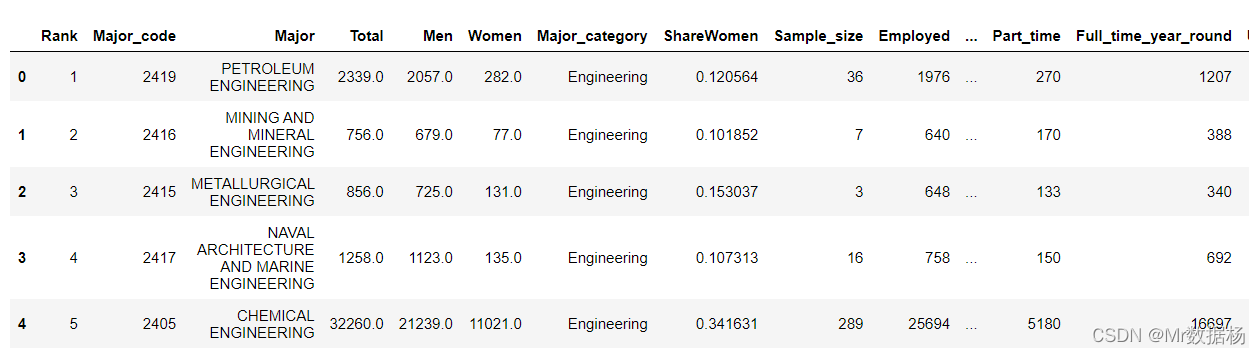
使用 American Community Survey 2010–2012 Public Use Microdata Sample的大学专业数据
import pandas as pd
df = pd.read_csv(
"数据科学必备 Pandas 数据可视化初学者指南/recent-grads.csv",
)
df.head()
创建 Pandas 绘图
数据集包含一些与每个专业毕业生收入相关的列:
- "Median"是全职、全年工作人员的收入中位数。
- "P25th"是收入的第 25 个百分位。
- "P75th"是收入的第 75 个百分点。
- "Rank"是按收入中位数排列的专业排名。
.plot() 返回一个折线图,其中包含 DataFrame 中每一行的数据。 x 轴值代表每个机构的排名,『P25th』、『Median』和『P75th』值绘制在 y 轴上。
import matplotlib.pyplot as plt
df.plot(x="Rank", y=["P25th", "Median", "P75th"])
plt.show()
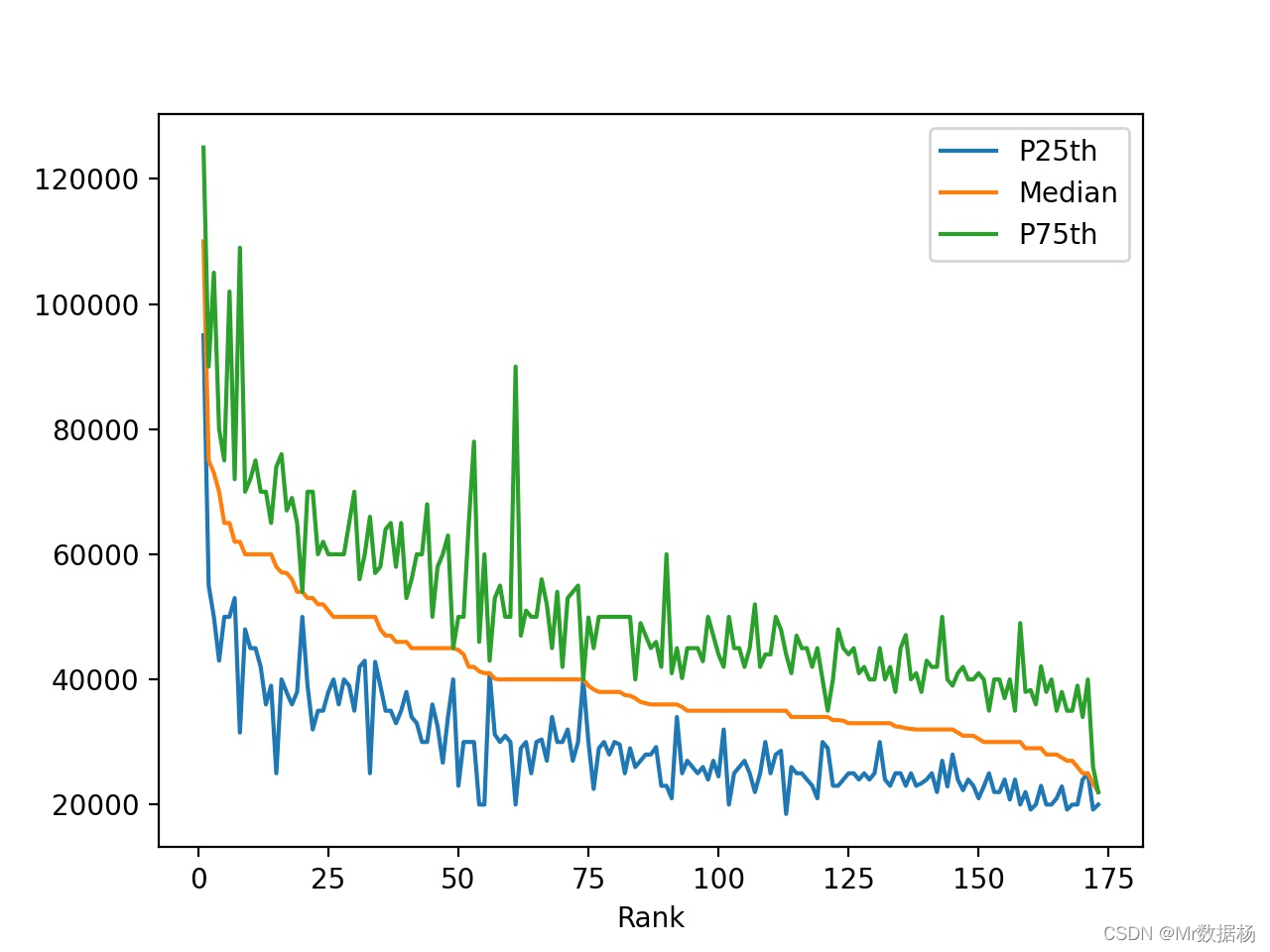
可以直观的获得相关信息。
- 收入中位数随着排名下降而下降。这是意料之中的,因为排名是由收入中位数决定的。
- 一些专业在 25% 和 75% 之间有很大的差距。拥有这些学位的人的收入可能明显低于或明显高于收入中位数。
- 其他专业在 25% 和 75% 之间的差距非常小。拥有这些学位的人的薪水非常接近中等收入。
.plot() 有几个可选参数。kind参数接受 11 个不同的字符串值并确定您将创建哪种绘图:
- "area"用于面积图。
- "bar"用于垂直条形图。
- "barh"用于水平条形图。
- "box"用于箱形图。
- "hexbin"用于六边形图。
- "hist"用于直方图。
- "kde"用于核密度估计图。
- "density"是"kde"的别名。
- "line"用于折线图。
- "pie"用于饼图。
- "scatter"用于散点图。
深入了解 Matplotlib
当调用一个 DataFrame 的 **.plot()**对象时,Matplotlib 会在后台创建绘图。
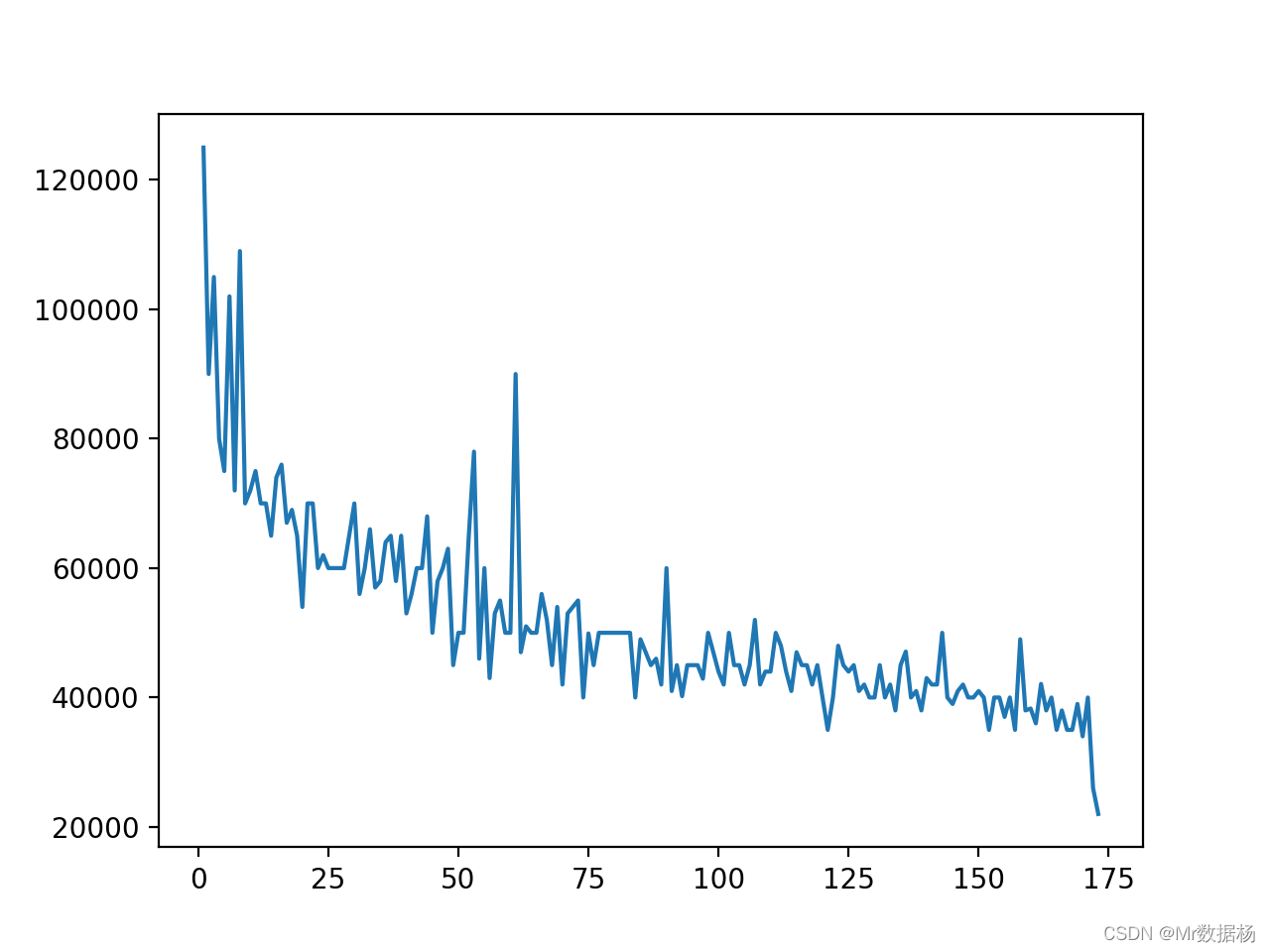
首先导入 matplotlib.pyplot 模块并将其重命名为 plt.。 然后调用 .plot() 并传递DataFrame 对象的『Rank』列作为第一个参数,将该『P75th』列作为第二个参数。
import matplotlib.pyplot as plt
plt.plot(df["Rank"], df["P75th"])
[<matplotlib.lines.Line2D at 0x7f859928fbb0>]
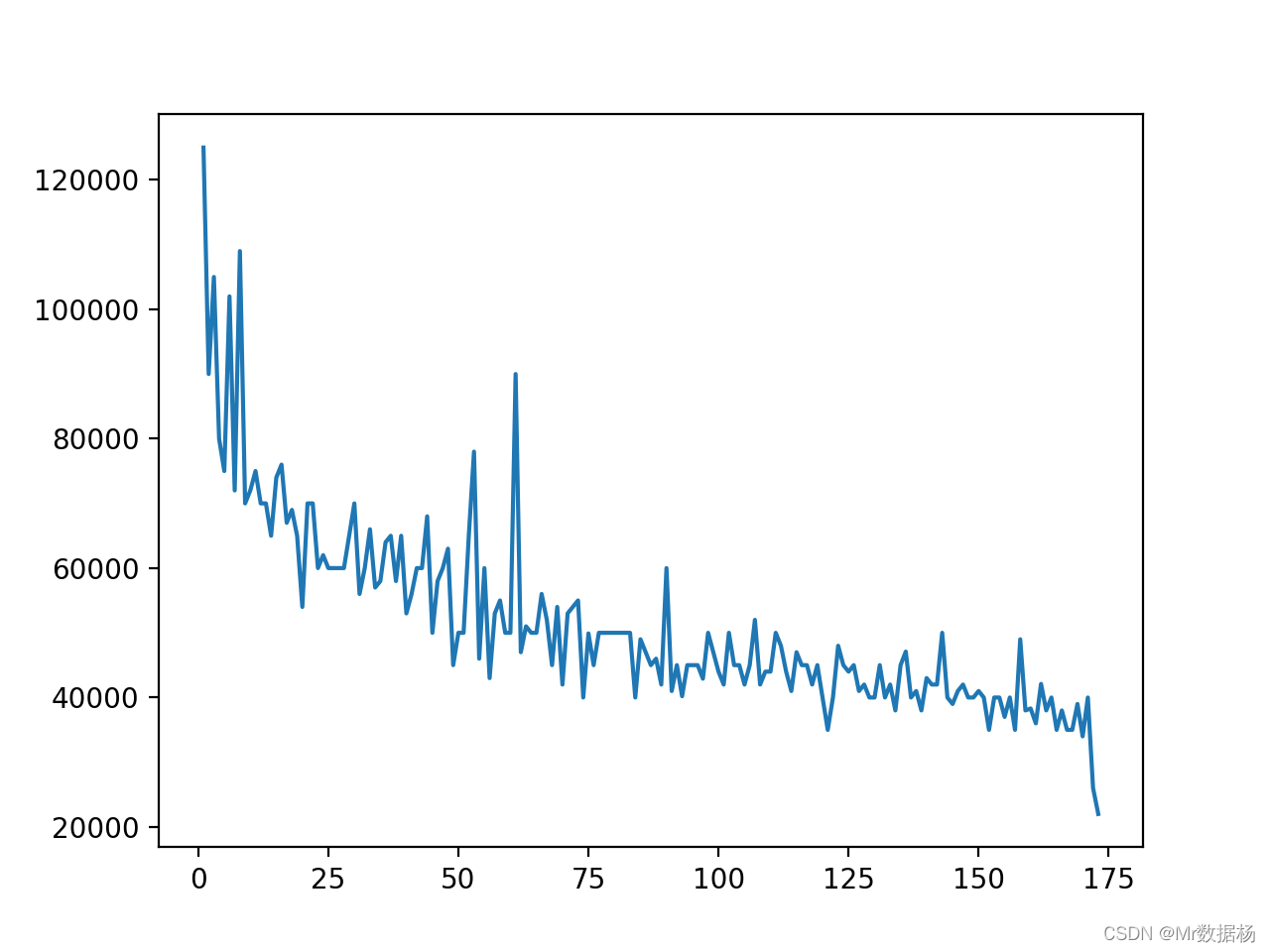
绘制一个折线图,df[“Rank”] 和 df[“P75th”] 的二维坐标关系折线。
DataFrame 可以使用 .plot() 对象的方法创建完全相同的图形。
df.plot(x="Rank", y="P75th")
<AxesSubplot:xlabel='Rank'>
数据的描述和检查
分布和直方图
DataFrame 不是 pandas 中唯一具有 .plot() 方法的类,Series 对象提供了类似的功能。可以将 DataFrame 的每一列作为 Series 对象。
使用从大学专业数据创建的 DataFrame 的『Median』列创建直方图的示例。
median_column = df["Median"]
type(median_column)
pandas.core.series.Series
median_column.plot(kind="hist")
<AxesSubplot:ylabel='Frequency'>
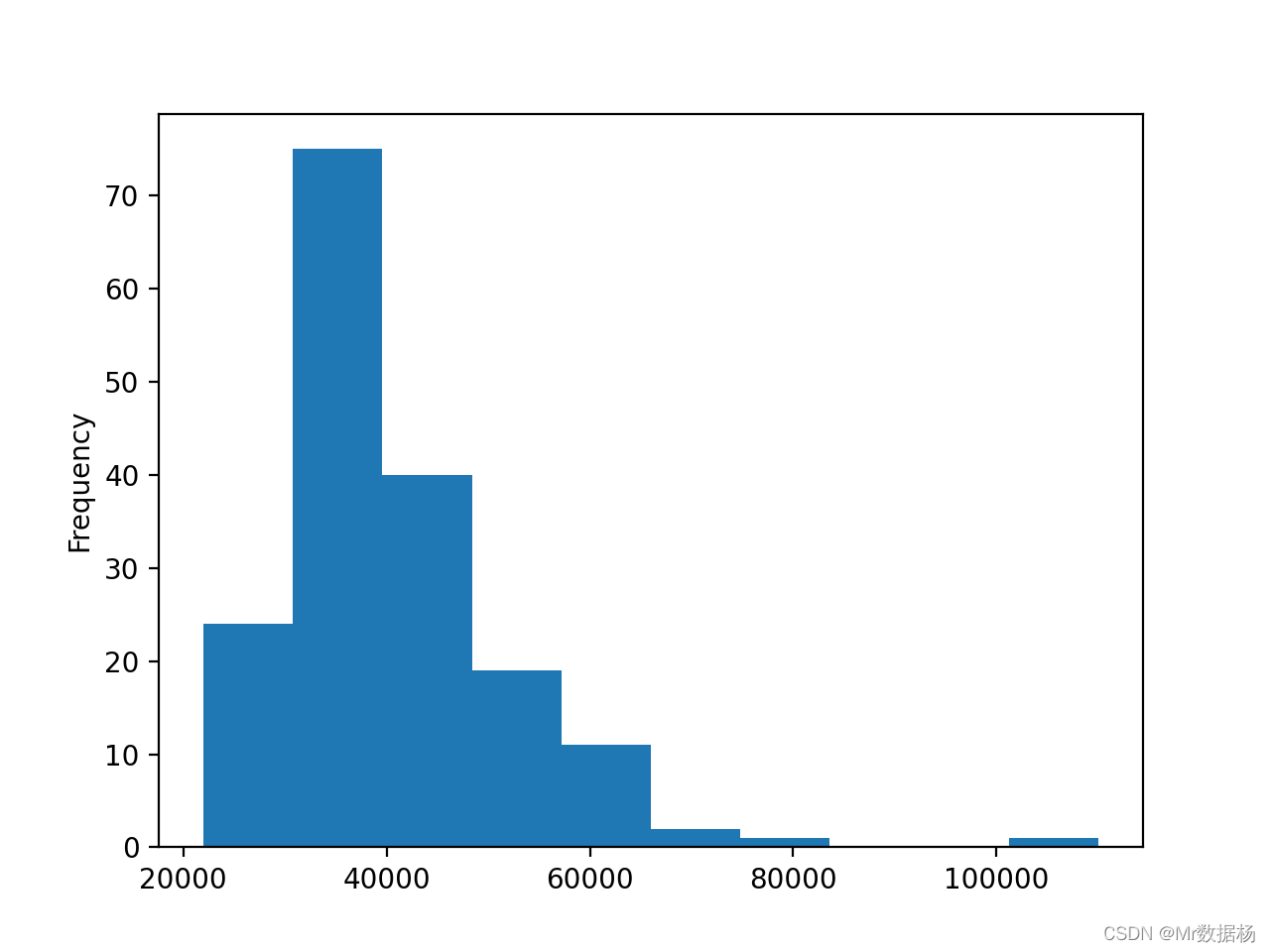
直方图显示数据分为 10 个区间,从 20,000 美元到 120,000 美元不等,每个区间的宽度为 10,000 美元。直方图的形状与正态分布不同,正态分布呈对称的钟形,中间有一个峰值。
异常值检测
异常值,指的是样本中的一些数值明显偏离其余数值的样本点,所以也称为离群点。异常值分析就是要将这些离群点找出来,然后进行分析。
问题:虽然专业的排名不是很高,但是也能获得相应较高的薪酬,这些数据应该如何检测。
可以使用直方图可以检测这样的异常值。
创建一个名为 top_5 的新 DataFrame。
top_5 = df.sort_values(by="Median", ascending=False).head(5)
创建条形图限制这5个专业的薪资。
top_5.plot(x="Major", y="Median", kind="bar", rot=5, fontsize=4)
<AxesSubplot:xlabel='Major'>
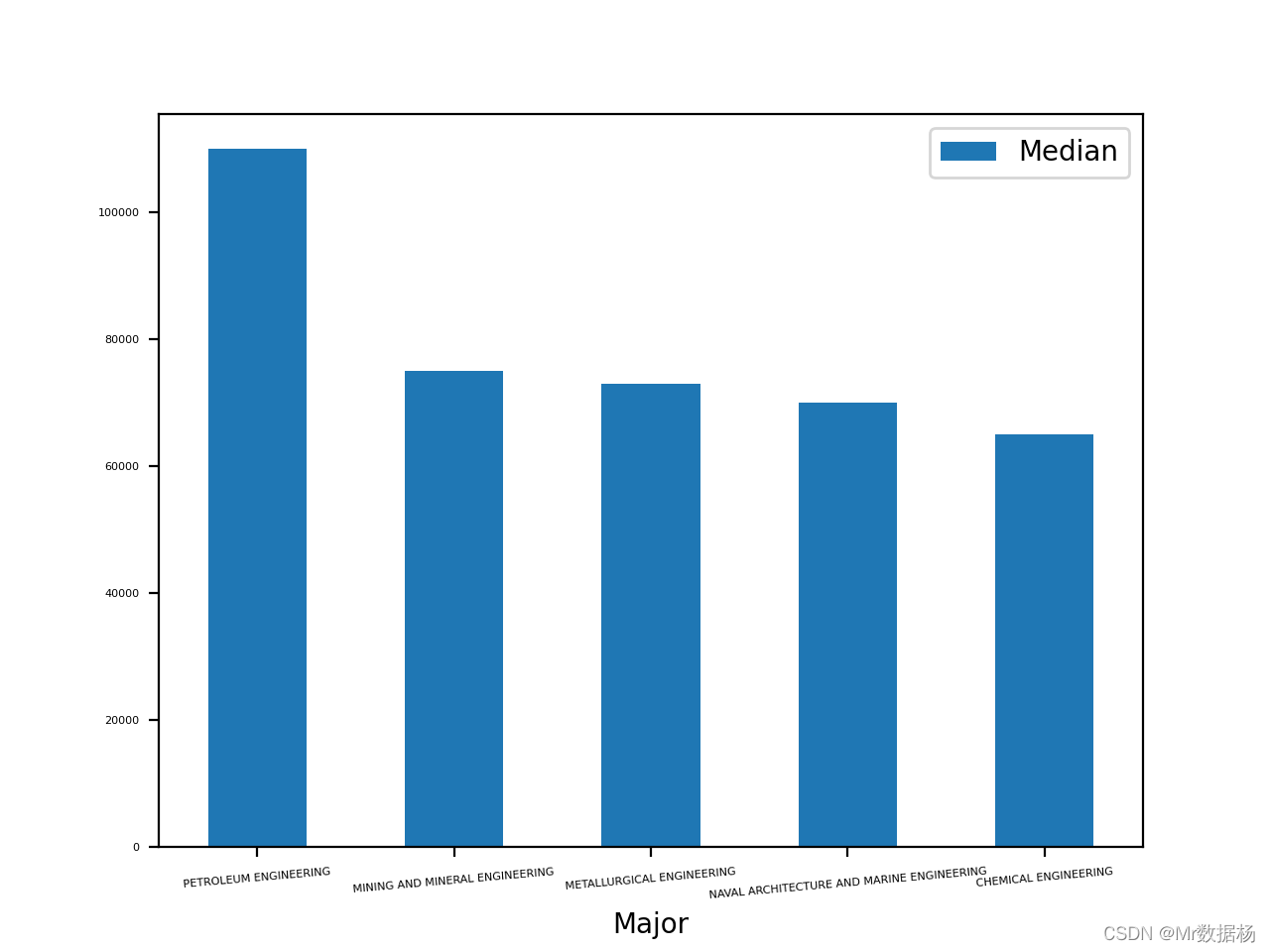
发现石油工程专业的工资中位数比其他专业高出 20,000 多美元。第二至第四名的专业的收入相对接近。
如果有一个数据点的值比其他数据点高或低得多,那么可能需要进一步调查。例如可以查看包含相关数据的列。
调查一下工资中位数在 60000 美元以上的所有专业,显示三个收入列。
top_medians = df[df["Median"] > 60000].sort_values("Median")
In [18]: top_medians.plot(x="Major", y=["P25th", "Median", "P75th"], kind="bar")
Out[18]: <AxesSubplot:xlabel='Major'>
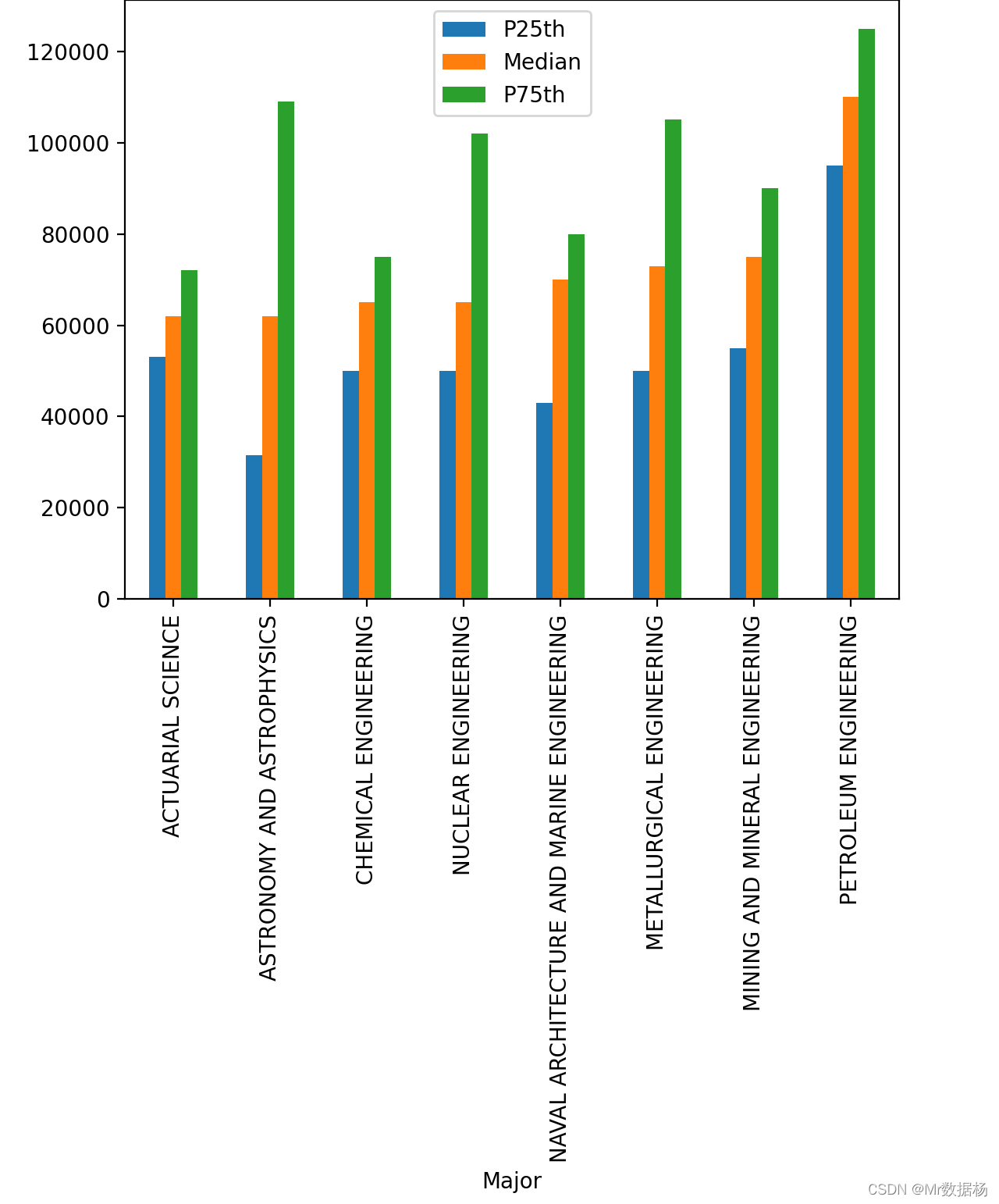
第 25 个和第 75 个百分位数证实了上面看到的情况:石油工程专业是迄今为止收入最高的应届毕业生。
检查相关性
通常想查看数据集的两列是否关联。如果选择收入中位数较高的专业,那么否也有较低的失业机会?
用『Median』和 『Unemployment_rate』创建散点图。
df.plot(x="Median", y="Unemployment_rate", kind="scatter")
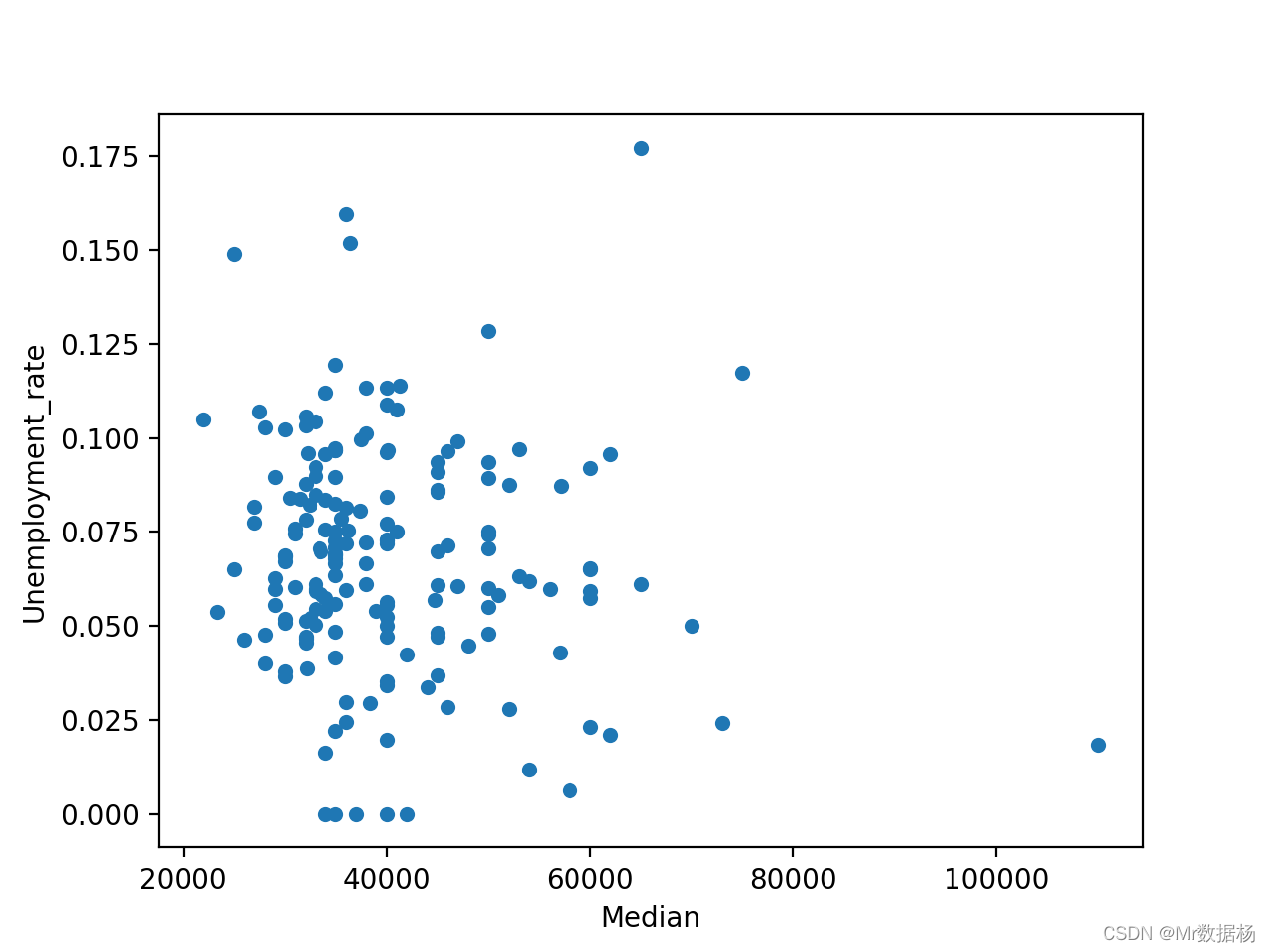
貌似看不出来啥规律,收入和失业率之间没有显着的相关性。
虽然散点图是获得有关可能相关性的第一印象的极好工具,但它肯定不是联系的明确证据。要了解不同列之间的相关性,可以使用.corr(). 如果怀疑两个值之间存在相关性,那么您可以使用多种工具来验证您的预感并衡量相关性有多强。
具体可以参考 数据科学必备的数据相关性分析的三种操作方式和可视化详解
但请记住,即使两个值之间存在相关性,也不意味着其中一个值的变化会导致另一个值的变化。换句话说,相关并不意味着因果关系。
分析分类数据
为了处理更大的信息块,人类的大脑有意识地和无意识地对数据进行分类。这种技术通常很有用,但远非完美无缺。有时我们将事物归入一个类别,经过进一步检查并不是那么相似。因此需要了解一些用于检查类别和验证给定分类是否有意义的工具。
分组
类别的基本用法是分组和聚合。可以使用 .groupby() 来确定大学专业数据集中每个类别的受欢迎程度。
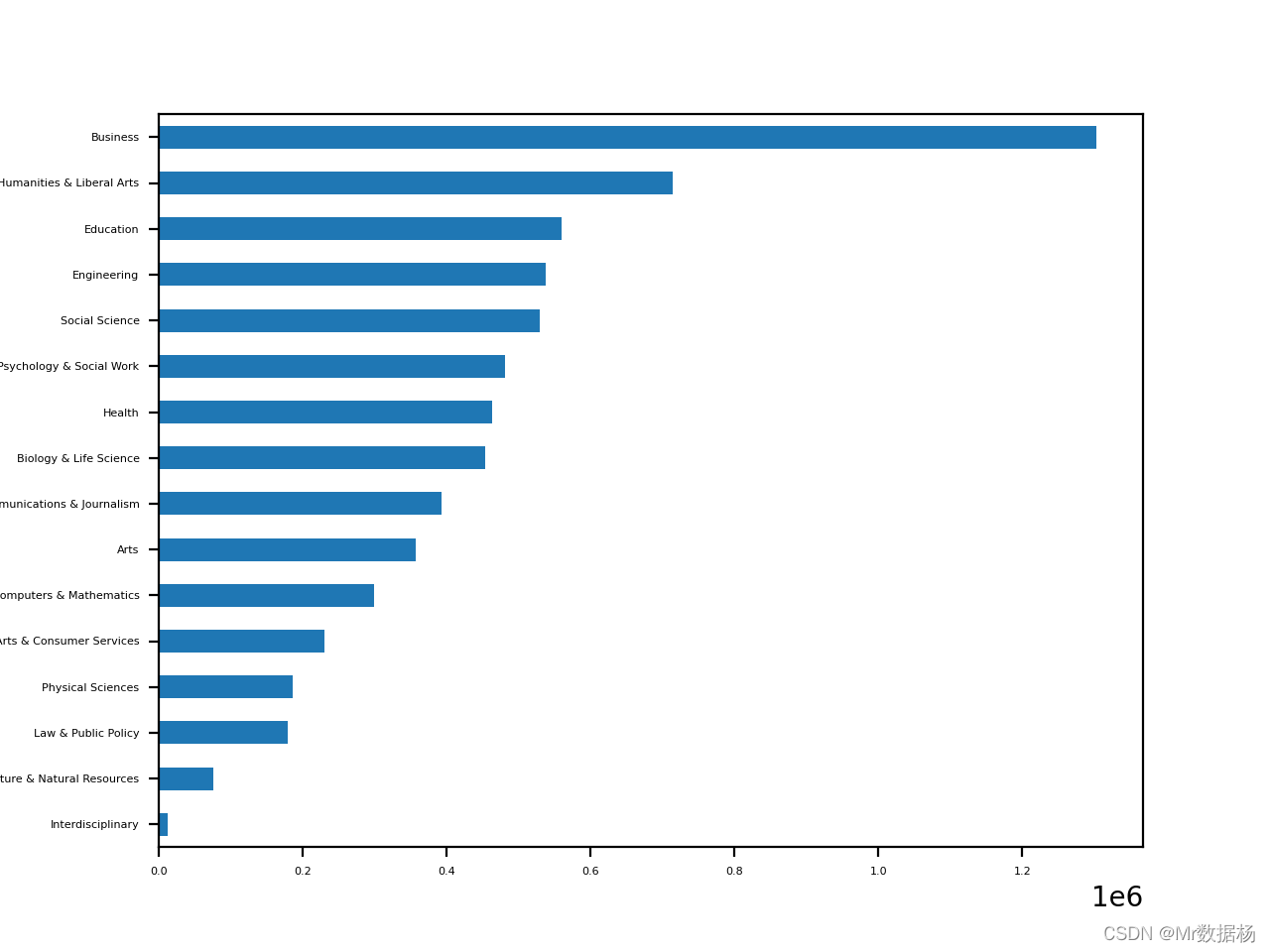
cat_totals = df.groupby("Major_category")["Total"].sum().sort_values()
cat_totals
Major_category
Interdisciplinary 12296.0
Agriculture & Natural Resources 75620.0
Law & Public Policy 179107.0
Physical Sciences 185479.0
Industrial Arts & Consumer Services 229792.0
Computers & Mathematics 299008.0
Arts 357130.0
Communications & Journalism 392601.0
Biology & Life Science 453862.0
Health 463230.0
Psychology & Social Work 481007.0
Social Science 529966.0
Engineering 537583.0
Education 559129.0
Humanities & Liberal Arts 713468.0
Business 1302376.0
Name: Total, dtype: float64
绘制一个水平条形图,显示 cat_totals 中的所有类别总数。
cat_totals.plot(kind="barh", fontsize=4)
<AxesSubplot:ylabel='Major_category'>
比率
想查看类别之间的差异,垂直和水平条形图通常是一个不错的选择。如果对比率感兴趣,那么饼图是一个很好的工具。
将总数低于 100000 的所有类别合并到一个名为 『Other』 的类别中,然后创建一个饼图。
small_cat_totals = cat_totals[cat_totals < 100_000]
big_cat_totals = cat_totals[cat_totals > 100_000]
small_sums = pd.Series([small_cat_totals.sum()], index=["Other"])
big_cat_totals = big_cat_totals.append(small_sums)
big_cat_totals.plot(kind="pie", label="")
<AxesSubplot:>
