学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
可视化是数据科学中必不可少的部分。Python 流行的数据分析库pandas提供了 .plot() 方法进行数据可视化。即使新手阶段也能很快就会创建基本图,从而对数据产生有价值的见解。

数据准备
import pandas as pd
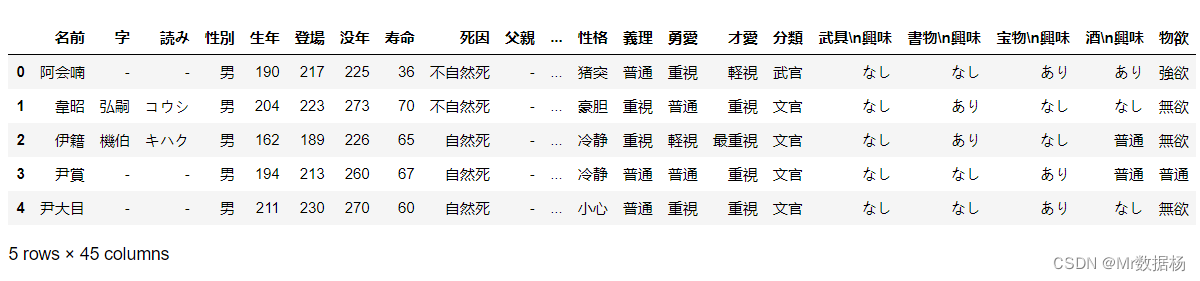
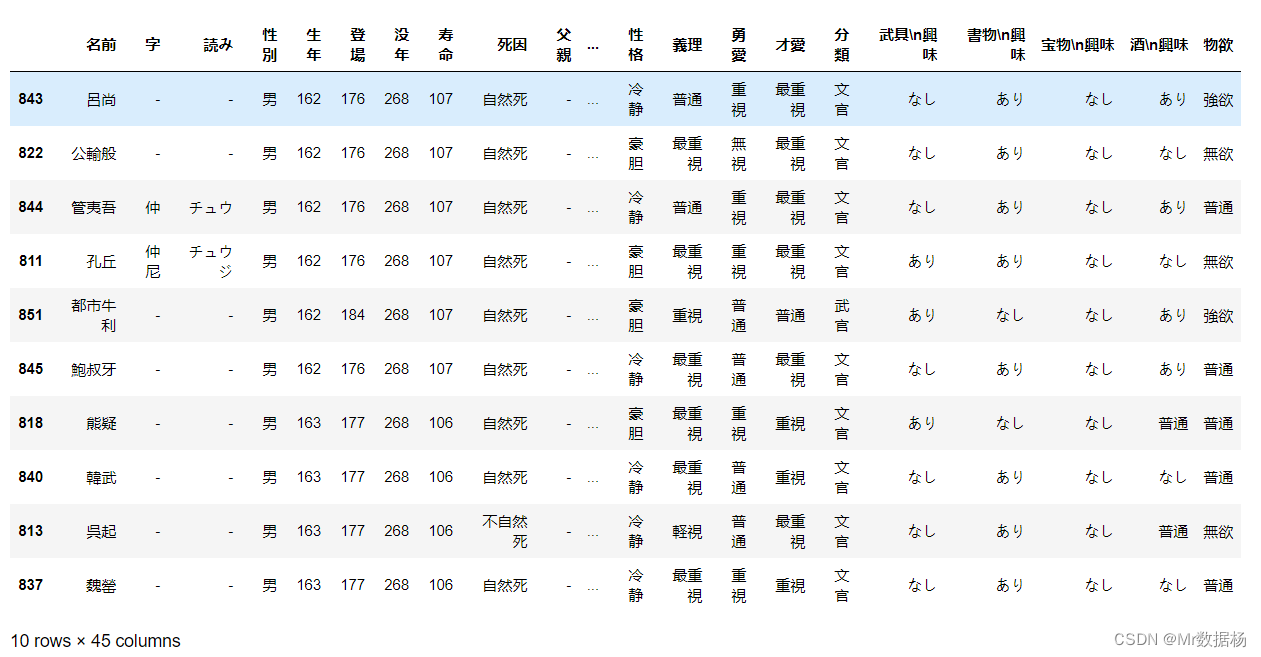
df = pd.read_excel("Romance of the Three Kingdoms 13/人物详情数据.xlsx")
df.head()
创建 Pandas 绘图
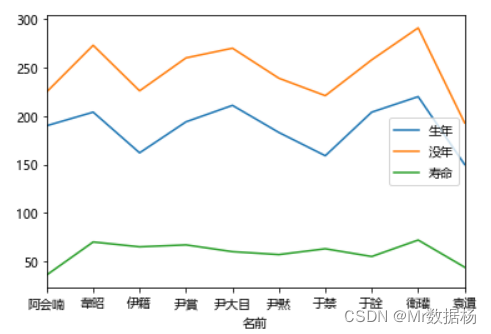
.plot() 返回一个折线图,其中包含 DataFrame 中每一行的数据。 x 轴值代表可视化的数据列。
import matplotlib.pyplot as plt
df.head(10).plot(x="名前", y=["生年","没年","寿命"])
plt.show()
.plot() 有几个可选参数。kind参数接受 11 个不同的字符串值并确定将创建哪种绘图:
- "area"用于面积图。
- "bar"用于垂直条形图。
- "barh"用于水平条形图。
- "box"用于箱形图。
- "hexbin"用于六边形图。
- "hist"用于直方图。
- "kde"用于核密度估计图。
- "density"是"kde"的别名。
- "line"用于折线图。
- "pie"用于饼图。
- "scatter"用于散点图。
深入了解 Matplotlib
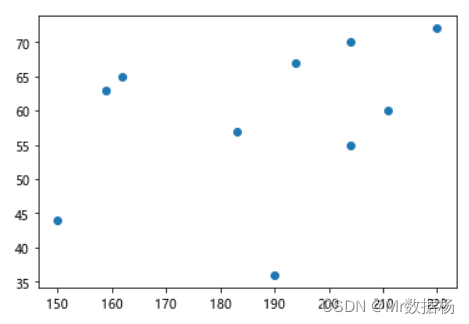
当调用一个 DataFrame 的 **.plot()**对象时,Matplotlib 会在后台创建绘图。
import matplotlib.pyplot as plt
plt.scatter(df.head(10)["生年"], df.head(10)["寿命"])
<matplotlib.collections.PathCollection at 0x2caac179438>
绘制生年和寿命的关系散点图。
数据的描述和检查
分布和直方图
DataFrame 不是 pandas 中唯一具有 .plot() 方法的类,Series 对象提供了类似的功能。可以将 DataFrame 的每一列作为 Series 对象。
绘制一个武将性格的直方图。
type(df["寿命"])
pandas.core.series.Series
df["寿命"].plot(kind="hist")
<matplotlib.axes._subplots.AxesSubplot at 0x2caac398240>
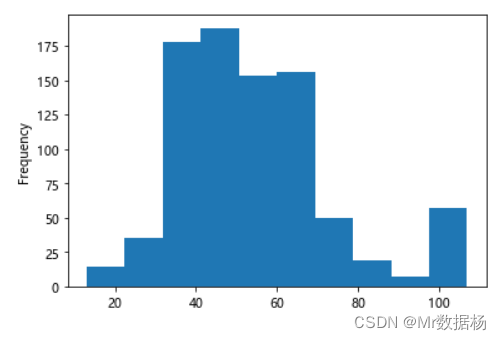
直方图显示数据分为 5 个区间,从 0 美元到 100 岁不等,每个区间的宽度为 20 岁。直方图的形状与正态分布不同,正态分布呈对称的钟形,中间有一个峰值。
异常值检测
异常值,指的是样本中的一些数值明显偏离其余数值的样本点,所以也称为离群点。异常值分析就是要将这些离群点找出来,然后进行分析。
可以使用直方图可以检测这样的异常值。
检测年龄异常的人。
top_5 = df.sort_values(by="Median", ascending=False).head(10)
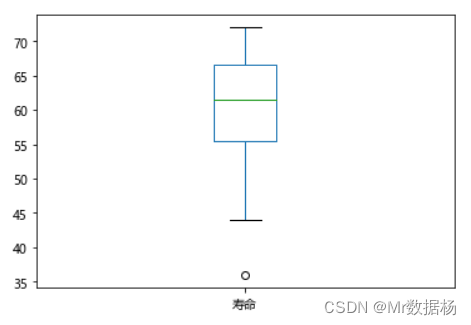
看到游戏设定中一些年龄异常的人,也可以使用箱线图直接查看。
df["寿命"].head(10).plot(kind="box")
检查相关性
通常想查看数据集的两列是否关联。
用『生年』和 『寿命』创建散点图。
df.plot(x="生年", y="寿命", kind="scatter")
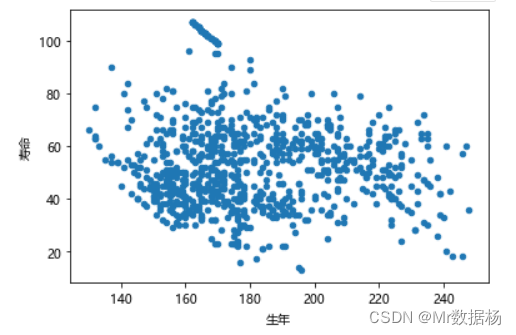
貌似看不出来啥规律。
虽然散点图是获得有关可能相关性的第一印象的极好工具,但它肯定不是联系的明确证据。要了解不同列之间的相关性,可以使用.corr(). 如果怀疑两个值之间存在相关性,那么您可以使用多种工具来验证您的预感并衡量相关性有多强。
具体可以参考 数据科学必备的数据相关性分析的三种操作方式和可视化详解
但请记住,即使两个值之间存在相关性,也不意味着其中一个值的变化会导致另一个值的变化。换句话说,相关并不意味着因果关系。
分析分类数据
为了处理更大的信息块,人类的大脑有意识地和无意识地对数据进行分类。这种技术通常很有用,但远非完美无缺。有时我们将事物归入一个类别,经过进一步检查并不是那么相似。因此需要了解一些用于检查类别和验证给定分类是否有意义的工具。
分组
类别的基本用法是分组和聚合,可以使用 .groupby() 。
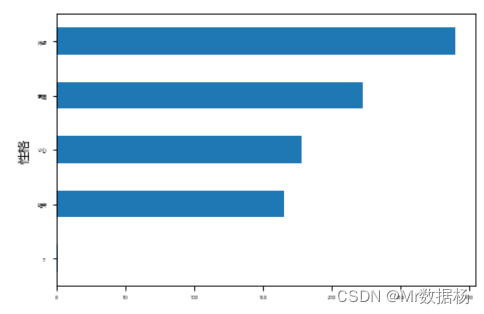
cat_totals = df.groupby("性格")["性格"].count().sort_values()
cat_totals
性格
? 1
猪突 165
小心 178
豪胆 223
冷静 290
Name: 性格, dtype: int64
绘制一个水平条形图,显示 cat_totals 中的所有类别总数。
cat_totals.plot(kind="barh", fontsize=4)
<AxesSubplot:ylabel='Major_category'>
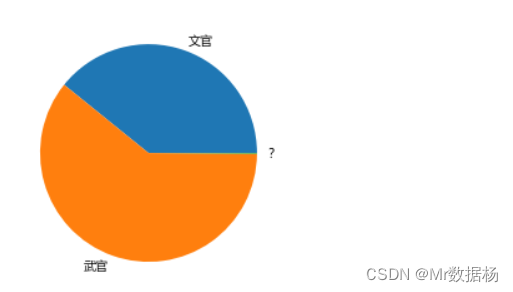
比率
想查看类别之间的差异,垂直和水平条形图通常是一个不错的选择。如果对比率感兴趣,那么饼图是一个很好的工具。
『分類』 的类别然后创建一个饼图。
df.groupby("分類")["分類"].count()
分類
文官 336
武官 520
? 1
Name: 分類, dtype: int64
df.groupby("分類")["分類"].count().plot(kind="pie", label="")