在对已有数据集不知道从何下手处理的时候,或者领导要求从这份数据中统计一些相关的内容信息的话,那么 Python 中的 Pandas 可以帮助你处理这些复杂的数据信息,不管数据是大是小都可以拆分成可操作的部分,并进行处理获得想要的结果。
通过本文可以学习到:
- 使用 Series 和 DataFrame 对象。
- .loc、.iloc的使用和索引运算符对数据进行子集的操作。
- 通过查询、分组和聚合数据。
- 处理缺失、无效和不一致的数据。
- 在 Jupyter 笔记本中可视化您的数据集。
文章目录
环境的配置
首先是熟悉 Python 的内置数据结构,尤其是列表和字典。可以参考前面的内容。
Pandas 预览数据
下载 NBA 的数据进行后续的操作。
import requests
proxies = {
'http': 'http://localhost:19180',
'https': 'http://localhost:19180'
}
download_url = "https://raw.githubusercontent.com/fivethirtyeight/data/master/nba-elo/nbaallelo.csv"
response = requests.get(download_url, proxies=proxies, verify=False)
with open("nba_all_elo.csv", "wb") as f:
f.write(response.content)
print("Download ready.")
查看的数据基本信息。
import pandas as pd
# 读取数据
nba = pd.read_csv("nba_all_elo.csv")
# 数据类型
type(nba)
<class 'pandas.core.frame.DataFrame'>
# 行数
len(nba)
126314
# 行、列数
nba.shape
(126314, 23)
数据的预览。
# 查看前5行数据
nba.head()
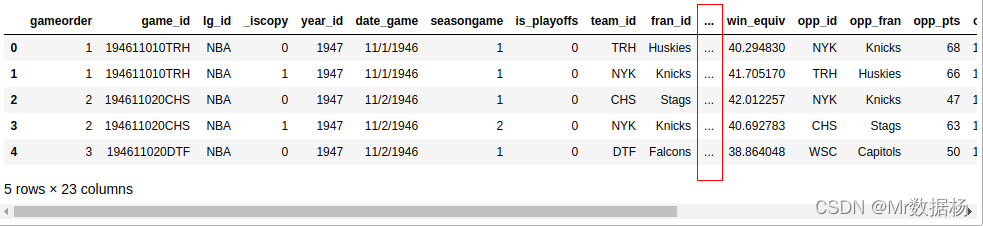
会看到一列省略号 (…) 表示缺失的数据。屏幕足够宽的话不会显示这个。可以进行设置为滚动条显示。
pd.set_option("display.max.columns", 2)
# 显示最后5行数据
nba.tail()

Pandas 检查数据
显示数据类型
了解数据的第一步是发现它包含的不同数据类型。虽然可以将任何内容放入列表中,但列包含特定数据类型的值。当用 Pandas 和 Python 比较数据结构时,会发现 Pandas 更快!
显示所有列及其数据类型。
nba.info()
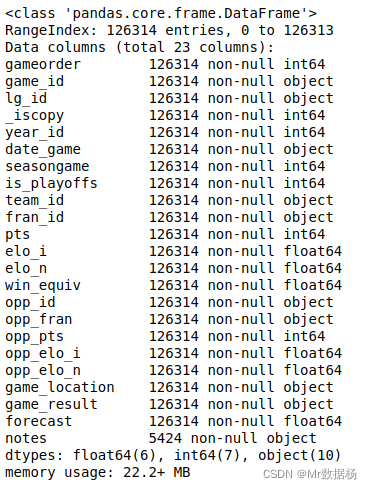
可以看到数据类型 int64、float64 和 object。Pandas 使用 NumPy 库来处理这些类型。
显示基础统计
显示所有数字列的一些基本描述性统计信息。
nba.describe()
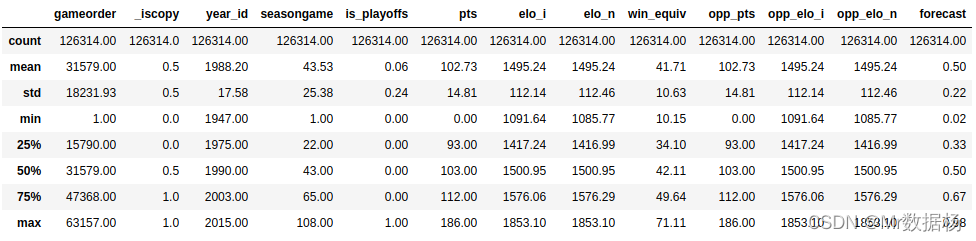
使用 include 参数,可以查看其他数据类型。不会计算object列的平均值或标准差,只显示一些描述性统计信息。
import numpy as np
nba.describe(include=object)

探索数据集
探索性数据分析可以回答有关数据集的问题。
例如可以检查特定值在列中出现的频率。
nba["team_id"].value_counts()
BOS 5997
NYK 5769
LAL 5078
...
SDS 11
nba["fran_id"].value_counts()
Name: team_id, Length: 104, dtype: int64
Lakers 6024
Celtics 5997
Knicks 5769
...
Huskies 60
Name: fran_id, dtype: int64
数据中发现 Lakers 总共有6024场比赛,但是LAL(洛杉矶湖人)对应的只有5078场比赛,那么数据是不是有什么问题?
nba.loc[nba["fran_id"] == "Lakers", "team_id"].value_counts()
LAL 5078
MNL 946
Name: team_id, dtype: int64
经过探索后发现居然还有一支队伍叫 MNL(明尼阿波利斯湖人队) 。经过百度发现这俩队是一个队伍,是前后继承的关系。
将 date_game 的值转换为数据 datetime 类型。然后可以使用 min 和 max 聚合函数,找到明尼阿波利斯湖人队的第一场和最后一场比赛信息数据。
nba["date_played"] = pd.to_datetime(nba["date_game"])
nba.loc[nba["team_id"] == "MNL", "date_played"].min()
Timestamp('1948-11-04 00:00:00')
nba.loc[nba['team_id'] == 'MNL', 'date_played'].max()
Timestamp('1960-03-26 00:00:00')
nba.loc[nba["team_id"] == "MNL", "date_played"].agg(("min", "max"))
min 1948-11-04
max 1960-03-26
Name: date_played, dtype: datetime64[ns]
这就解释了为什么可能不认识这支球队的原因,很多不是篮球迷都不知道。
Pandas 数据结构
Series 对象
Python 最基本的数据结构是list,Series根据列表创建一个新对象。
revenues = pd.Series([1, 2, 3])
revenues
0 1
1 2
2 3
dtype: int64
type(revenues.values)
<class 'numpy.ndarray'>
Series 操作同 List,区别在于可以设置显式索引值。
data = pd.Series(
[1, 2, 3],
index=["A", "B", "C"]
)
>>> data
A 1
B 2
C 3
dtype: int64
也可以通过字典的方式构建 Series 。
data = pd.Series({
"A": 1, "B": 2})
data
A 1
B 2
dtype: int64
Series 也支持 .keys() 和 in 关键字。
>>> data.keys()
Index(['A', 'B'], dtype='object')
>>> "A" in data
True
>>> "C" in data
False
DataFrame 对象
DataFrame 可以通过在构造函数中提供字典来将这些对象组合成一个。字典键将成为列名,值应包含Series对象。
A_ = pd.Series([1, 2, 3],index=["A", "B", "C"])
B_ = pd.Series({
"A": 11, "B": 22})
data = pd.DataFrame({
"A": A_,
"B": B_
})
data
A B
A 1 11.0
B 2 22.0
C 3 NaN
新 DataFrame 索引是两个Series索引的并集。
data.index
Index(['A', 'B', 'C'], dtype='object')
DataFrame也将其值存储在 NumPy 数组中。
data.values
array([[1, 11.0],
[2, 22.0],
[3, nan]])
DataFrame 轴操作。
data.axes
[Index(['A', 'B', 'C'], dtype='object'), Index(['A', 'B'], dtype='object')]
data.axes[0]
Index(['A', 'B', 'C'], dtype='object')
data.axes[1]
Index(['A', 'B'], dtype='object')
DataFrame也是一个类字典的数据结构,也支持 .keys() 和 in 关键字。
data.keys()
Index(['A', 'B'], dtype='object')
Series元素操作
使用索引运算符
支持关键字和索引数字操作。
A_
A 1
B 2
C 3
dtype: int64
A_['A']
1
A_[0]
1
支持 list 的切片操作。
A_[-1]
3
A_[1:]
B 2
C 3
dtype: int64
.loc和.iloc
处理标签索引是数字的情况。
colors = pd.Series(
["red", "purple", "blue", "green", "yellow"],
index=[1, 2, 3, 5, 8]
)
colors
1 red
2 purple
3 blue
5 green
8 yellow
dtype: object
- .loc 指标签索引。
- .iloc 指位置索引。
colors.loc[1]
'red'
colors.iloc[1]
'purple'
.loc 指向图像右侧的标签索引。同时.iloc指向图片左侧的位置索引。
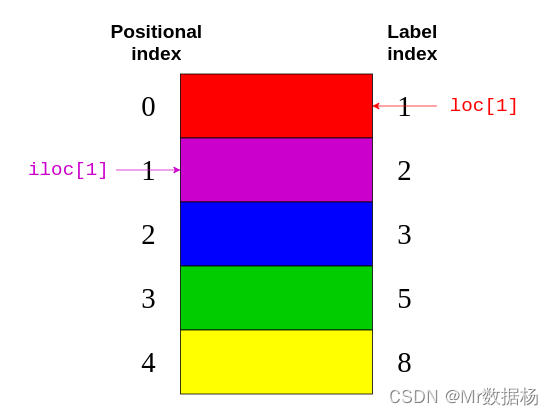
.iloc 返回具有隐式索引的元素。
colors.iloc[1:3]
2 purple
3 blue
dtype: object
.loc 返回显式索引在 3 到 8 之间的元素。
colors.loc[3:8]
3 blue
5 green
8 yellow
dtype: object
.iloc 支持负位置索引传递。
colors.iloc[-2]
'green'
DataFrame 元素访问
使用索引运算符
将 DataFrame 视为其 Series 值为的字典。
import pandas as pd
A_ = pd.Series([1, 2, 3],index=["A", "B", "C"])
B_ = pd.Series({
"A": 11, "B": 22})
data = pd.DataFrame({
"A": A_,
"B": B_
})
data["A"]
A 1
B 2
C 3
Name: A, dtype: int64
type(data["A"])
<class 'pandas.core.series.Series'>
也支持 . 符号访问。
data["A"]
A 1
B 2
C 3
Name: A, dtype: int64
有可能出现函数方法和列名重复的情况。
toys = pd.DataFrame([
{
"name": "ball", "shape": "sphere"},
{
"name": "Rubik's cube", "shape": "cube"}
])
toys["shape"]
0 sphere
1 cube
Name: shape, dtype: object
toys.shape
(2, 2)
.loc和.iloc
DataFrame 也提供 .loc 和 .iloc 数据访问方法。
data.loc["A"]
A 1.0
B 11.0
Name: A, dtype: float64
data.loc["A": "B"]
A B
A 1 11.0
B 2 22.0
data.iloc[1]
A 2.0
B 22.0
Name: B, dtype: float64
查询数据集
可以根据索引访问庞大数据集的子集,意味着可以根据索引来查询数据。
筛选2010年以后的数据信息。
current_decade = nba[nba["year_id"] > 2010]
current_decade.shape
可以选择特定字段不为空的行。
games_with_notes = nba[nba["notes"].notnull()]
games_with_notes.shape
(5424, 24)
针对字符传数据可以使用字符串内置函数进行处理。
ers = nba[nba["fran_id"].str.endswith("ers")]
ers.shape
(27797, 24)
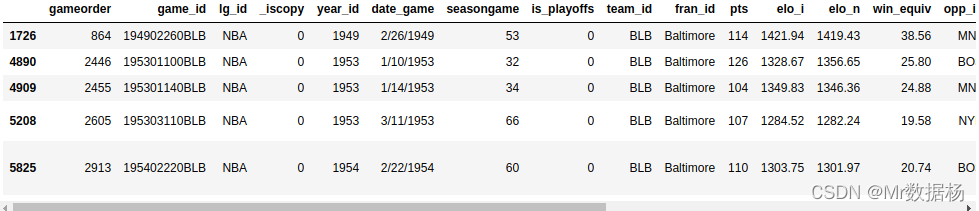
多条件搜索使用 & 符号。
nba[
(nba["_iscopy"] == 0) &
(nba["pts"] > 100) &
(nba["opp_pts"] > 100) &
(nba["team_id"] == "BLB")
]
分组和聚合数据
Pandas 库提供了分组和聚合函数进行各种数据的统计操作。
Series 有 20 多种不同的方法来计算描述性统计量。
A_.sum()
6
A_.min()
1
DataFrame 可以有多个列可以进行聚合分组操作。
根据 fran_id 聚合,求和 pts 列数据。
nba.groupby("fran_id", sort=False)["pts"].sum()
fran_id
Huskies 3995
Knicks 582497
Stags 20398
Falcons 3797
Capitols 22387
...
列操作
创建原 df 的副本DataFrame 使用。
df = nba.copy()
df.shape
(126314, 24)
根据现有列定义新列,并且可以进行相同的列操作。
df["difference"] = df.pts - df.opp_pts
df.shape
(126314, 25)
df["difference"].max()
68
列名可以重新自定义。
renamed_df = df.rename(
columns={
"game_result": "result", "game_location": "location"}
)
也可以删除不需要的行或者列。
df.shape
(126314, 25)
elo_columns = ["elo_i", "elo_n", "opp_elo_i", "opp_elo_n"]
# 这里需要指定 axis = 1 为列,axis = 0 为行
df.drop(elo_columns, inplace=True, axis=1)
df.shape
(126314, 21)
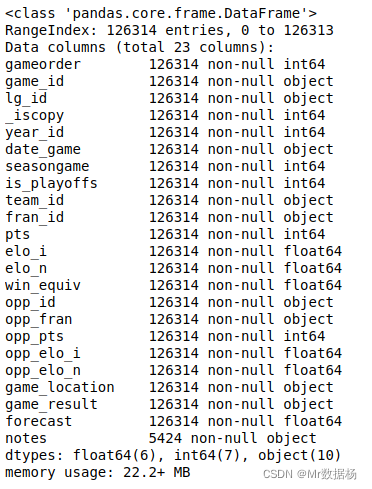
数据类型重新定义
这里重新定义的数据类型是根据列全部重新定义。
df.info()
重新定义时间列函数,转化成日期格式。
df["date_game"] = pd.to_datetime(df["date_game"])
重新定义object数据类型。
df["game_location"] = pd.Categorical(df["game_location"])
df["game_location"].dtype
CategoricalDtype(categories=['A', 'H', 'N'], ordered=False)
也可以直接赋值操作。
df["game_id"] = df["game_id"].astype('object')
清理数据
缺失值
观察notes列包含 5424 个缺失值。
nba.info()
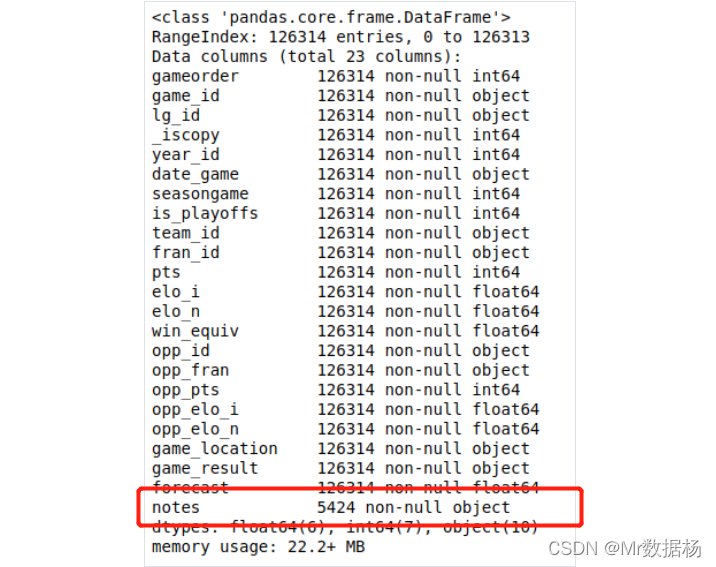
处理包含缺失值的记录的最简单方法是忽略或者删除。
rows_without_missing_data = nba.dropna()
rows_without_missing_data.shape
(5424, 24)
缺失值也可以进行填充。
data_with_default_notes = nba.copy()
data_with_default_notes["notes"].fillna(
value="no notes at all",
inplace=True
)
无效值
无效值可能比缺失值更难处理,也会为后续的数据分析操作造成各种不可未知的麻烦。
这个需要根据自己对业务的理解剔除相关不合理的或者异常的数据。
不一致的值
可以定义一些互斥的查询条件,并验证这些条件不会同时出现。
判断比赛得分和比赛结果的例子。
nba[(nba["pts"] > nba["opp_pts"]) & (nba["game_result"] != 'W')].empty
True
nba[(nba["pts"] < nba["opp_pts"]) & (nba["game_result"] != 'L')].empty
True
幸运的是这两个查询都返回一个空的DataFrame证明不存在不一致的数据。
数据集的拼接
使用 .concat() 拼接2个DataFrame。
further_city_data = pd.DataFrame(
{
"revenue": [7000, 3400], "employee_count":[2, 2]},
index=["New York", "Barcelona"]
)
city_data = pd.DataFrame({
"revenue": pd.Series([4200, 8000, 6500],index=["Amsterdam", "Toronto", "Tokyo"]),
"employee_count": pd.Series({
"Amsterdam": 5, "Tokyo": 8})
})
all_city_data = pd.concat([city_data, further_city_data], sort=False)
all_city_data
revenue employee_count
Amsterdam 4200 5.0
Tokyo 6500 8.0
Toronto 8000 NaN
New York 7000 2.0
Barcelona 3400 2.0
还可以通过提供参数 axis=1 追加列。
city_countries = pd.DataFrame({
"country": ["Holland", "Japan", "Holland", "Canada", "Spain"],
"capital": [1, 1, 0, 0, 0]},
index=["Amsterdam", "Tokyo", "Rotterdam", "Toronto", "Barcelona"]
)
cities = pd.concat([all_city_data, city_countries], axis=1, sort=False)
cities
revenue employee_count country capital
Amsterdam 4200.0 5.0 Holland 1.0
Tokyo 6500.0 8.0 Japan 1.0
Toronto 8000.0 NaN Canada 0.0
New York 7000.0 2.0 NaN NaN
Barcelona 3400.0 2.0 Spain 0.0
Rotterdam NaN NaN Holland 0.0
使用 join 参数设置进行拼接。
pd.concat([all_city_data, city_countries], axis=1, join="inner")
revenue employee_count country capital
Amsterdam 4200 5.0 Holland 1
Tokyo 6500 8.0 Japan 1
Toronto 8000 NaN Canada 0
Barcelona 3400 2.0 Spain 0
使用 merge() 参数设置进行拼接。
countries = pd.DataFrame({
"population_millions": [17, 127, 37],
"continent": ["Europe", "Asia", "North America"]
}, index= ["Holland", "Japan", "Canada"])
pd.merge(cities, countries, left_on="country", right_index=True)
revenue employee_count country capital population_millions continent
Amsterdam 4200.0 5.0 Holland 1.0 17 Europe
Rotterdam NaN NaN Holland 0.0 17 Europe
Tokyo 6500.0 8.0 Japan 1.0 127 Asia
Toronto 8000.0 NaN Canada 0.0 37 North America
DataFrame 可视化
Series 和 DataFrame对象都有一个 .plot() 方法绘制可视化图。
绘制某只队伍全部赛季的比赛得分的趋势图。
nba[nba["fran_id"] == "Knicks"].groupby("year_id")["pts"].sum().plot()
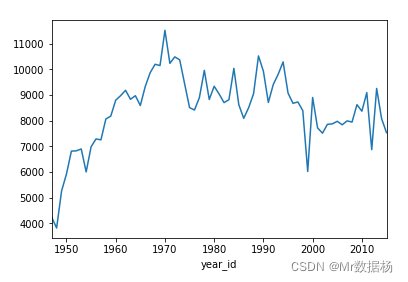
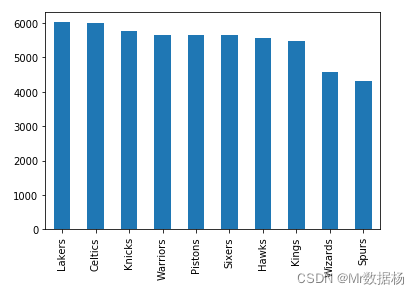
绘制比赛次数最多的队伍的柱状图,取前 N 个队伍。
nba["fran_id"].value_counts().head(10).plot(kind="bar")