学Python数据科学,玩游戏、学日语、搞编程一条龙。
这次就来学习一下《三国志》游戏中的数据是如何进行拼接的。
数据科学领域日常使用 Python 处理大规模数据集的时候经常需要使用到合并、链接的方式进行数据集的整合,其中应用的数据类型包括 Series 和 DataFrame,可以使用的方法也很多,比如本文中介绍的 .merge()、 .join() 和 .concat() 三种方法,进行拼接处理后的数据集可以发挥最大的用途。

merge 操作
.merge() 方法是用于组合通用列或索引上的数据,这个方法有点类似于 MySQL 中的 join 操作,可以实现左拼接、右拼接、全连接等操作。
通过关键字的索引进行拼接,实现多对一、一对多、多对多(笛卡尔乘积)连接。
merge 中参数解释:
- how:定义合并方式,选择参数有 『inner』,『outer』, 『left’』,『right』。
- on:定义2个 DataFrame 中都必须包含的列用于连接(索引键)。
- left_on 和 right_on:指定要合并的左侧或右侧对象中存在的列或索引。
- left_index 和 right_index:默认为 False,设置为以索引列作为合并基准。
- suffixes:字符串元组,用于附加到不是合并键的相同列名。
merge 拼接方式
一张图就能看明白不同关键字参数 merger 的方式。

merge 举例
数据读取
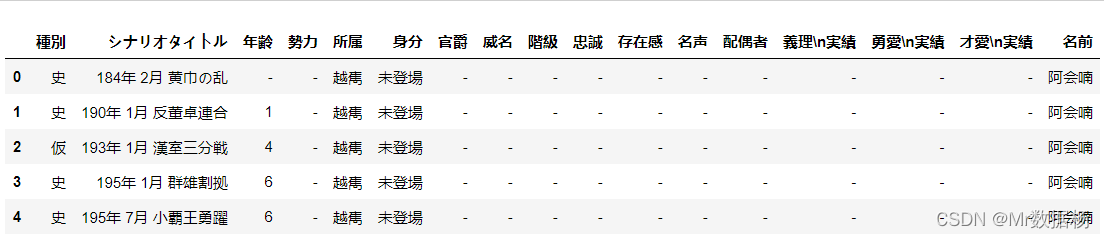
我们要进行势力所属和人物直接关系的拼接操作,读取的数据包括下面的2个列表,并将 人物历史登入数据 中没有势力的数据剔除。
import pandas as pd
country = pd.read_excel("Romance of the Three Kingdoms 13/势力列表.xlsx")
people = pd.read_excel("Romance of the Three Kingdoms 13/人物历史登入数据.xlsx")
# 剔除不包含的势力数据,即武将在野的状态
people = people[people["勢力"]!="-"]
country.head()

people.head()
内部联接
使用 merge 默认参数可以直接进行内部连接,匹配两个DataFrame交集的结果。
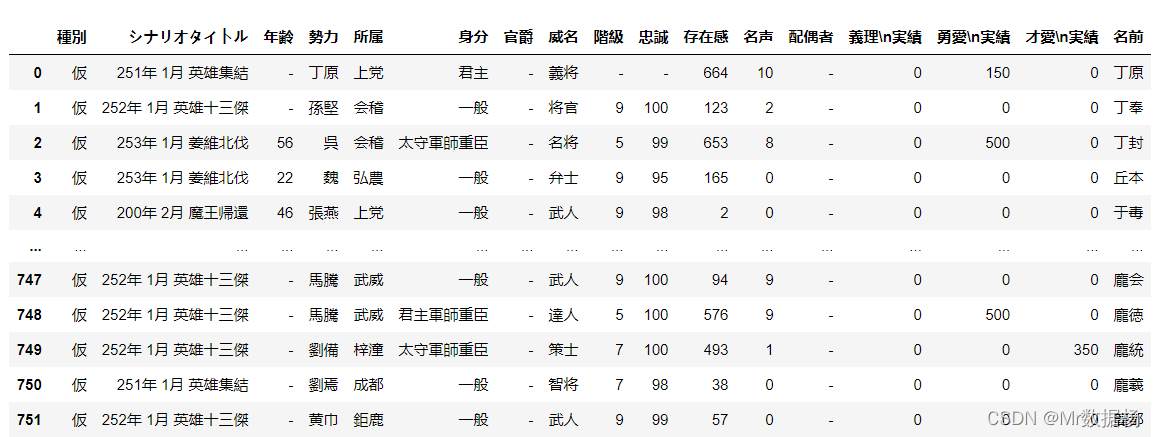
将人物和所属势力进行一个拼接,这里我们取的是这个人物最终归属的势力,即改人物数据聚合后的最后一条数据信息。
people_new = people.groupby('名前').nth(-1)
people_new["名前"] = people_new.index
people_new.reset_index(drop=True,inplace=True)
people_new
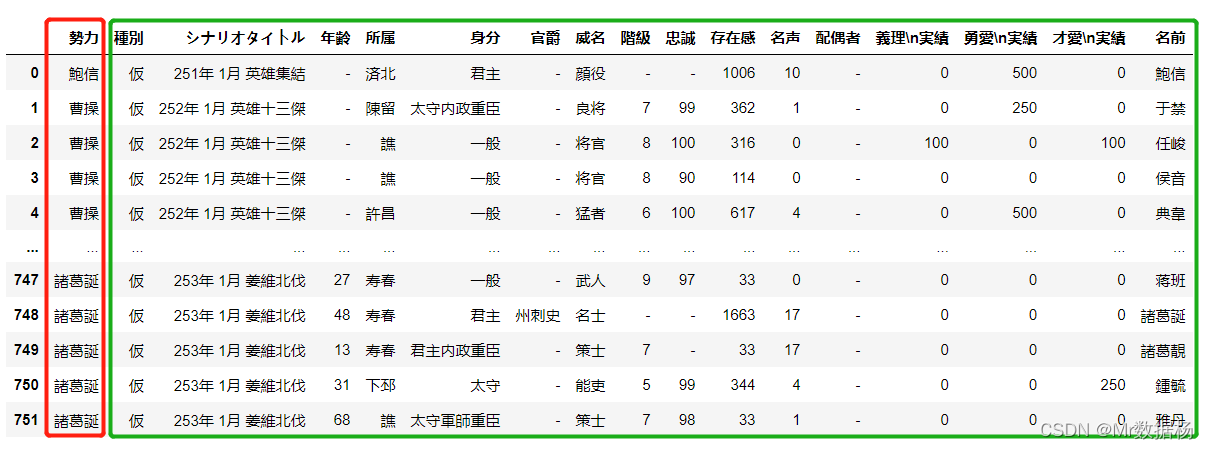
merge 中DataFrame的顺序决定了拼接结果的顺序。
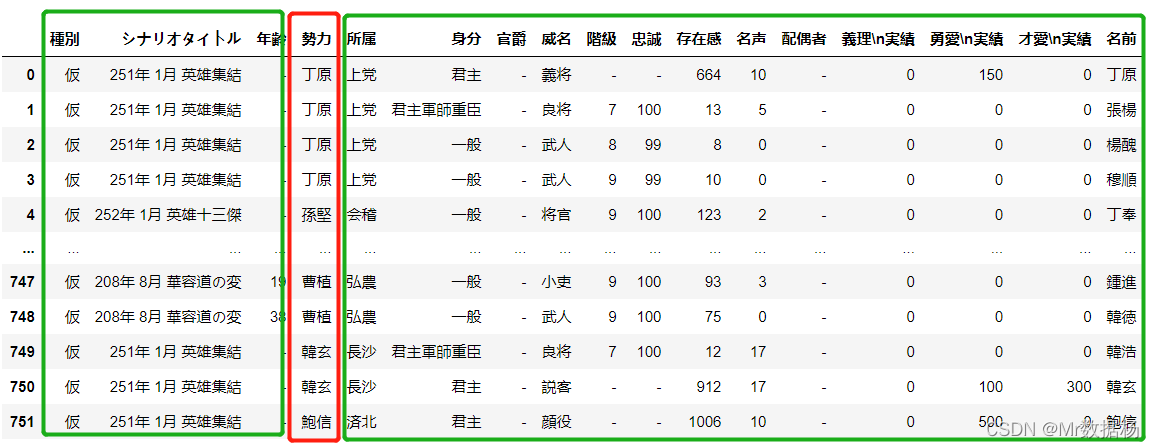
inner_merged_total = pd.merge(country,people_new,on=["勢力"])
inner_merged_total.head()
inner_merged_total = pd.merge(people_new,country,on=["勢力"])
inner_merged_total.head()
外连接
外连接(也称为完全外连接)中,来自两个 DataFrame 的所有行都将出现在新的 DataFrame 中。
本质上对于数据全的 df_A 和包含的 df_B 进行 outer 拼接,相当于 pd.merge(df_A ,df_B,on=[“key”])。
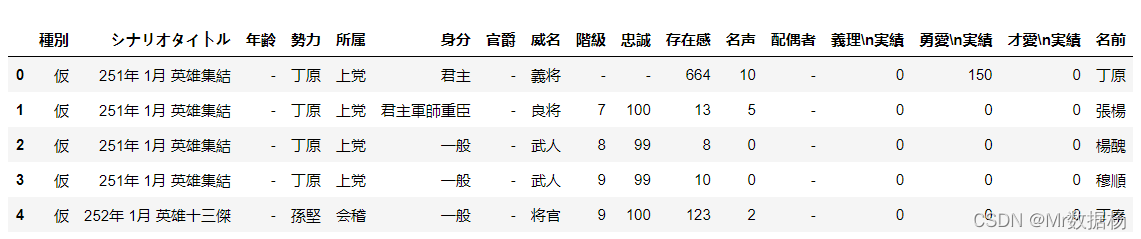
outer_merged = pd.merge(people_new,country,how="outer",on=["勢力"])
outer_merged.head()
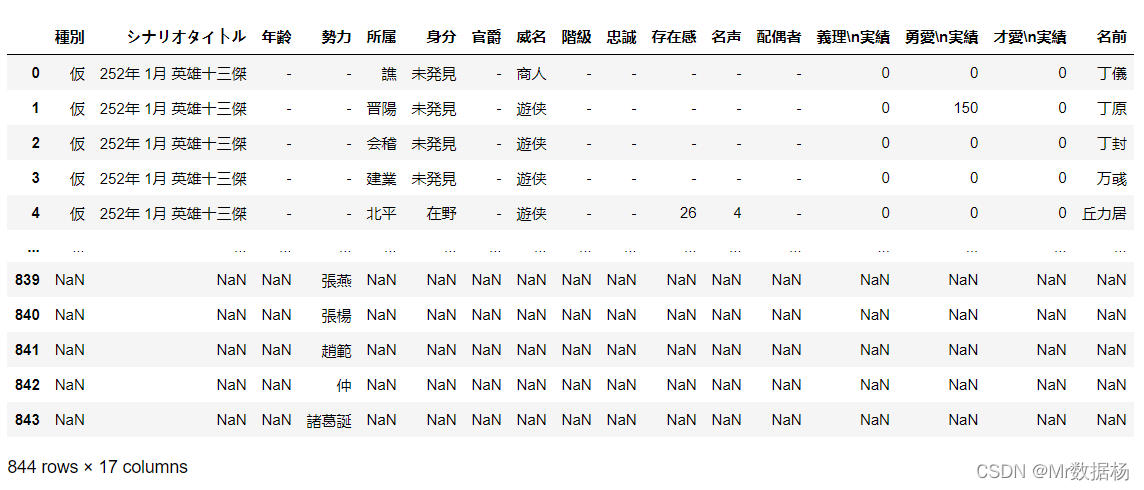
如果我们不剔除在野武将的数据的话会发现是整张表单进行拼接。
country = pd.read_excel("Romance of the Three Kingdoms 13/势力列表.xlsx")
people = pd.read_excel("Romance of the Three Kingdoms 13/人物历史登入数据.xlsx")
outer_merged = pd.merge(people_new,country,how="outer",on=["勢力"])
outer_merged
左连接
新合并的 DataFrame 与左侧 DataFrame 中的所有行一起保留(即merge中的第一个dataframe),同时丢弃右侧 DataFrame 中在左侧 DataFrame 的键列中没有匹配的行。
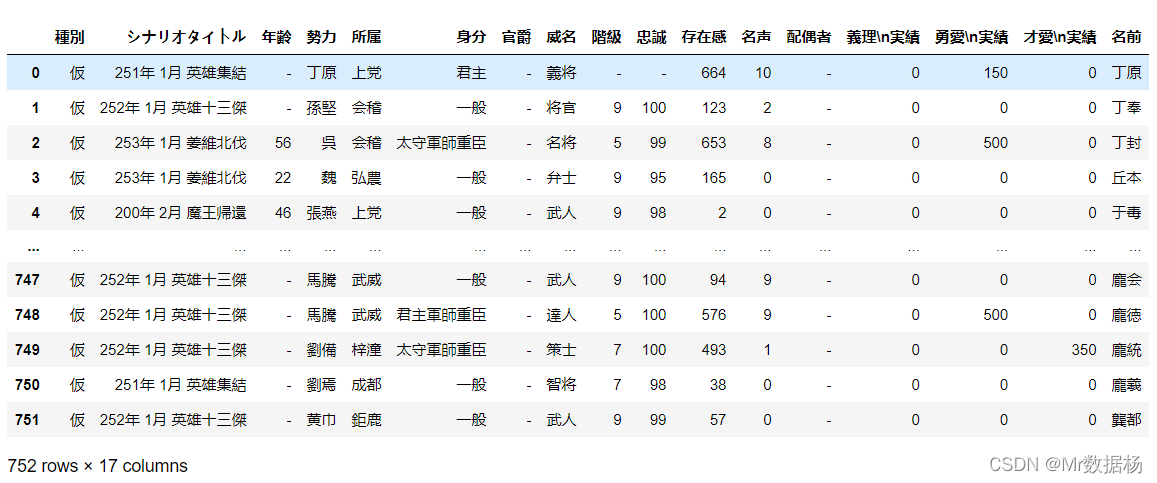
left_merged = pd.merge(people_new,country,how="left",on=["勢力"])
left_merged
右连接
新合并的 DataFrame 与右侧 DataFrame 中的所有行一起保留(即merge中的第二个dataframe),同时丢弃右侧 DataFrame 中在左侧 DataFrame 的键列中没有匹配的行。
right_merged = pd.merge(people_new,country,how="right",on=["勢力"])
right_merged
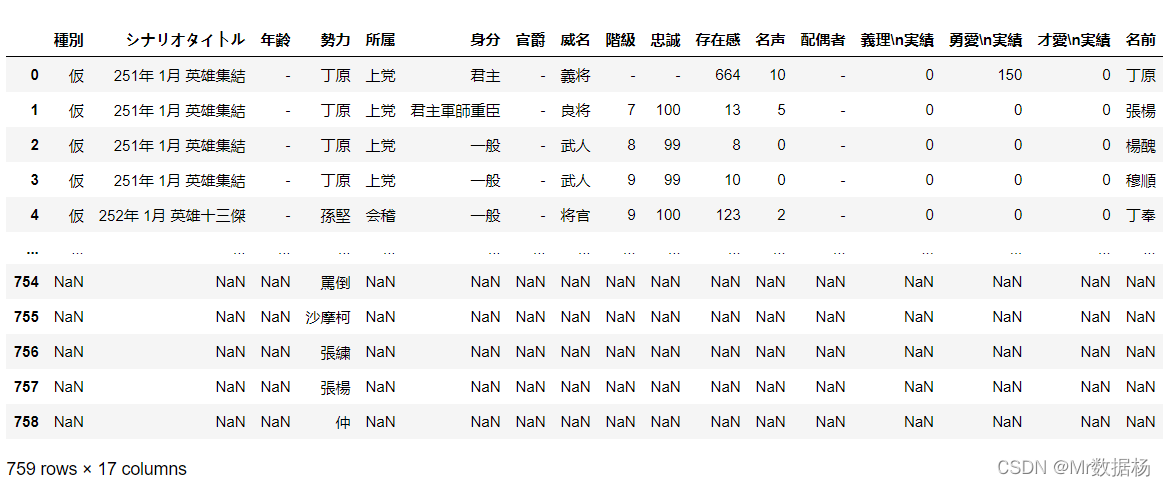
join 操作
join 操作和 merge 很相似,是在列或索引上组合数据,join 相当于指定了 merge 中的第一个 DataFreme 。并且命名冲突的列可以定义后缀进行重新命名。
这个结果和之前的左右 merger 很相似。
join 中参数解释:
- other:定义要拼接的 DataFrame。
- on:指定左侧 DataFrame 的可选列或索引名称。如果设置为 None,这是默认 index 连接。
- how:与 merge 中的 how 具有相同,如果不指定列则使用索引拼接。
- lsuffix 和 rsuffix:类似 merge() 中的后缀。
- sort:对生成后的 DataFrame 进行排序。
join 举例
people_new.join(country, lsuffix="left", rsuffix="right")
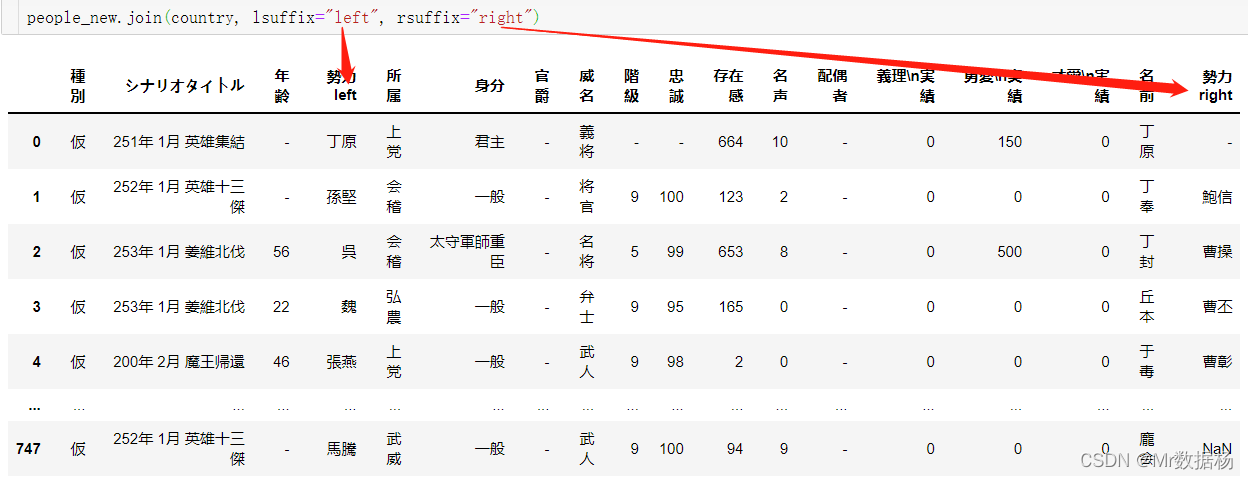
仅仅是index的横向拼接。
concat 操作
concat 操作起来就比较灵活,可以进行横向的拼接操作,也可以进行纵向的拼接操作。
纵向拼接操作
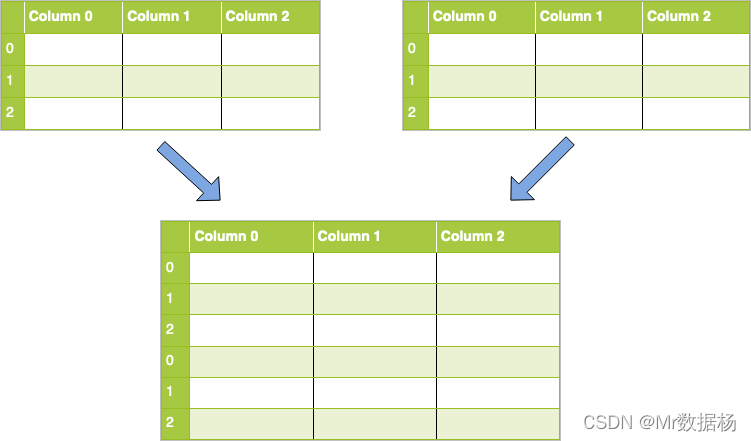
横拼接操作
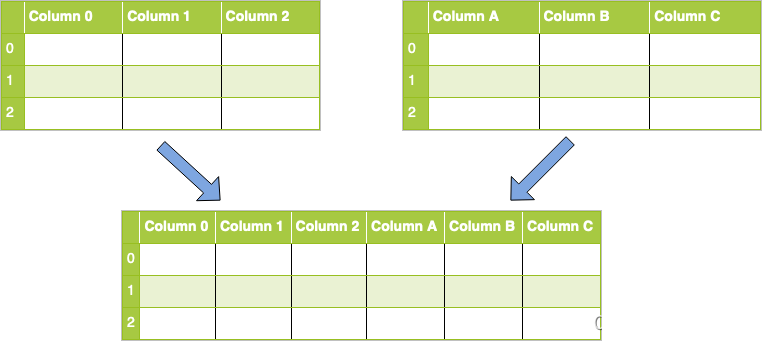
concat 中参数解释:
- objs:要连接的任何数据对象。可以是List,Serices,DataFrame,Dict 等等。
- axis:连接的轴。默认值为0(行轴),1(纵直)连接。
- join:类似于 merger 中的 how 参数,只接受值 inner 或 outer 。
- ignore_index:默认为False。True 为设置新的组合数据集将不会保留 axis 参数中指定的轴中的原始索引值。
- keys:构建分层索引,用于查询不同的行来自的原始数据集。
- copy:是否要复制源数据,默认值为True。
concat 举例
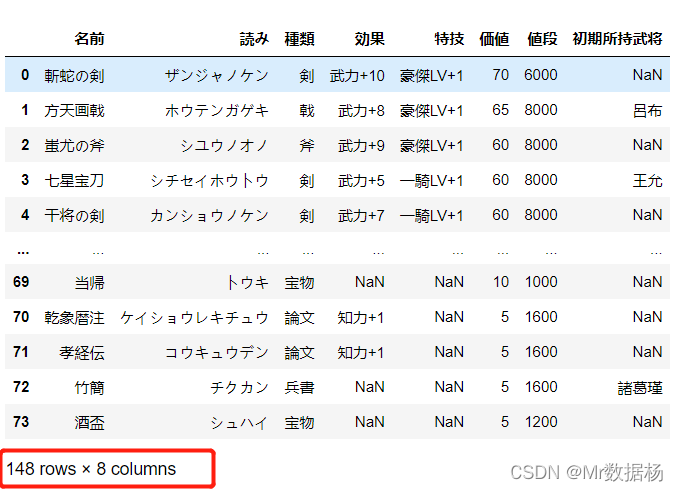
我们使用三国的宝物数据来观察,数据 74 行。
import pandas as pd
items = pd.read_excel("Romance of the Three Kingdoms 13/道具列表.xlsx")
items.head()

横向拼接后,保持数据最大行数 74。
pd.concat([items, items], axis=1)
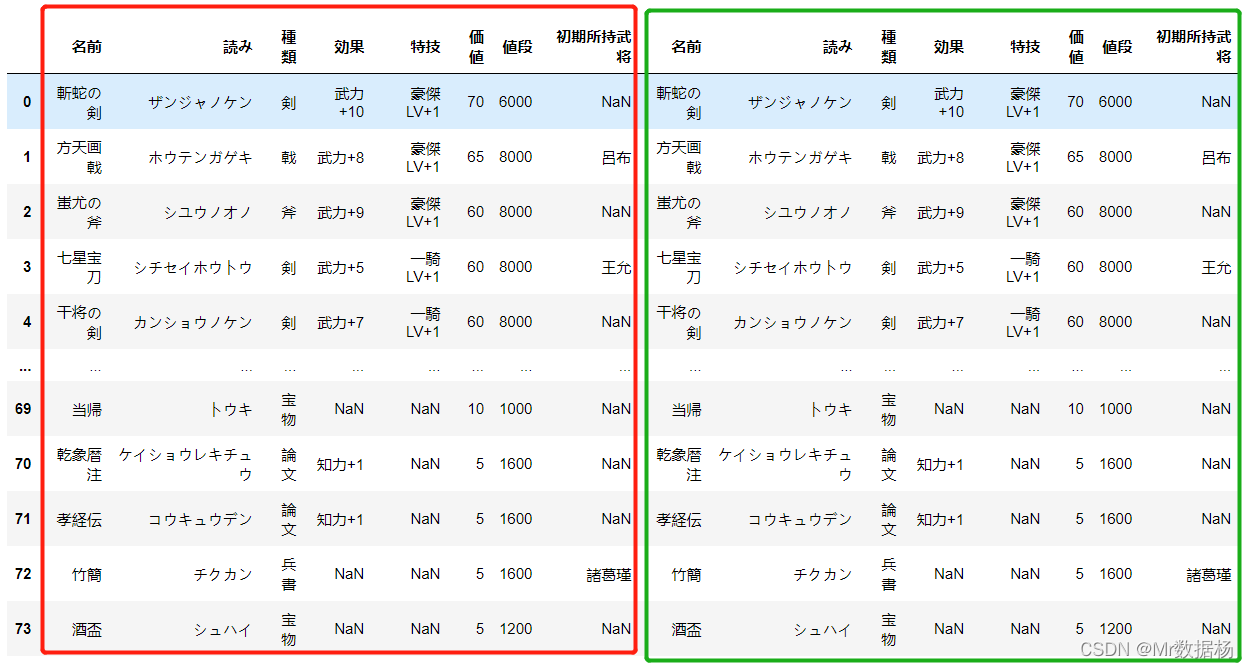
纵向拼接后,最大行数变成 74 的 2倍。
pd.concat([items, items], axis=0)
append 举例
append 也是 DataFrame 数据进行拼接的有效方式,方式同 concat 的纵向拼接,返回的结果需要对变量重新定义才能生效。
注意下面2个 append 行数的区别
items.append(items)
items

items = items.append(items)
items