学习 pandas 排序方法是开始或练习使用 Python 进行基本数据分析的好方法。 最常见的是,数据分析是使用 Excel、SQL 或 pandas 完成的。 使用 pandas 的一大优点是可以处理大量数据并提供高性能的数据操作能力。
本文介绍如何使用 .sort_values() 和 .sort_index(),能够在 DataFrame 中有效地对数据进行排序。

文章目录
Pandas 排序方法入门
DataFrame 是一种带有标记的行和列的数据结构。可以按行或列值以及行或列索引对 DataFrame 进行排序。
行和列都有索引,它们是数据在 DataFrame 中位置的数字表示。可以使用 DataFrame 的索引位置从特定行或列中检索数据。默认情况下,索引号从零开始。您也可以手动分配自己的索引。
数据准备
美国环境保护署 (EPA) 针对 1984 年至 2021 年间制造的车辆编制的燃油经济性数据。
EPA燃油经济性数据集
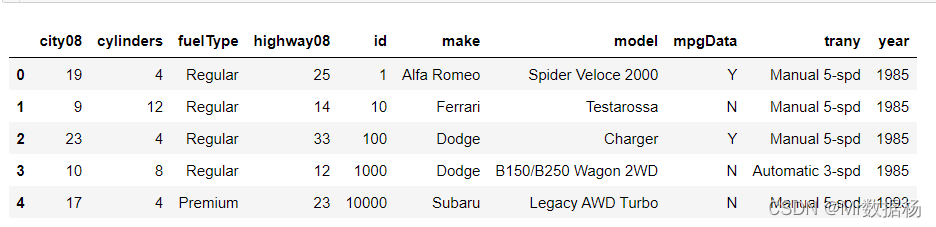
出于分析目的,将按品牌、型号、年份和其他车辆属性查看车辆的 MPG(英里/加仑)数据要读入 DataFrame 的列。
import pandas as pd
column_subset = [
"id",
"make",
"model",
"year",
"cylinders",
"fuelType",
"trany",
"mpgData",
"city08",
"highway08"
]
df = pd.read_csv(
"数据科学必备Pandas DataFrame:数据排序详解/vehicles.csv",
usecols=column_subset,
nrows=100
)
df.head()
.sort_values()
可以使用 .sort_values() 沿任一轴(列或行)对 DataFrame 中的值进行排序,类似 Excel 中的值排序。
.sort_index()
可以使用 .sort_index() 通过行索引或列标签对 DataFrame 进行排序,是根据行索引或列名对 DataFrame 进行排序
DataFrame 单列数据排序
使用 .sort_values(). 默认情况返回一个按升序排序的新 DataFrame,不会修改原始 DataFrame。
按升序按列排序
使用 .sort_values() 排序要将单个参数传递给包含要排序的列的名称的方法。
df.sort_values("city08")
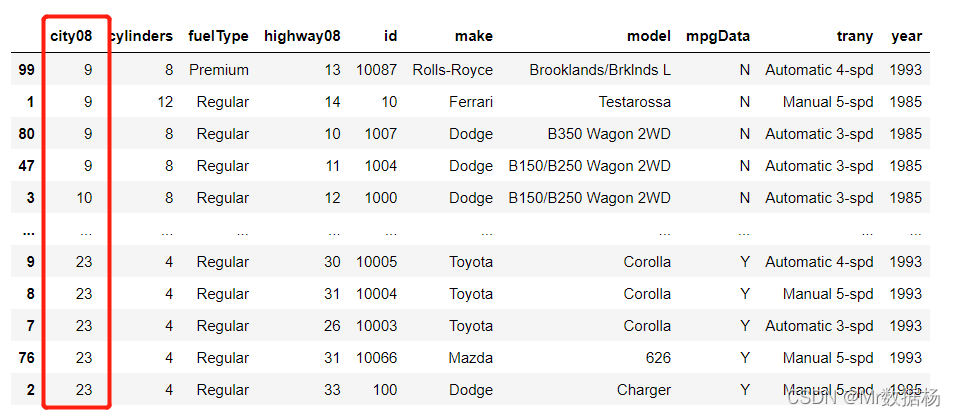
排序顺序调整
默认情况下 .sort_values() ascending设置为 True(升序排列). 如果按降序排序,则设置为 False 。
df.sort_values(by="city08",ascending=False)
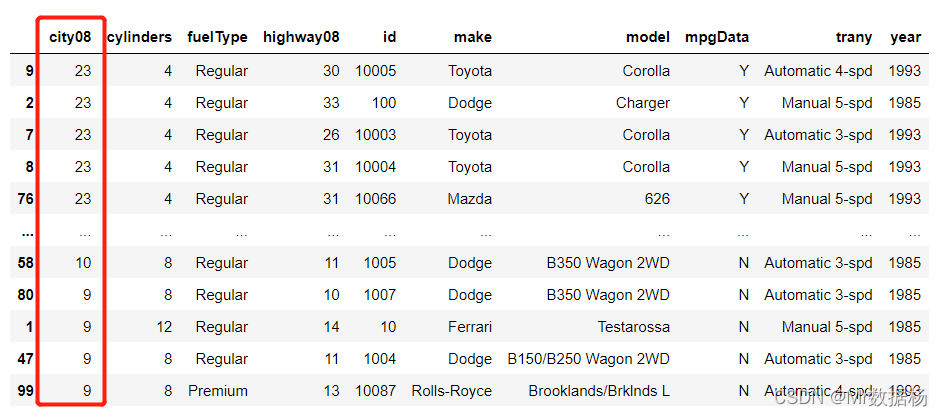
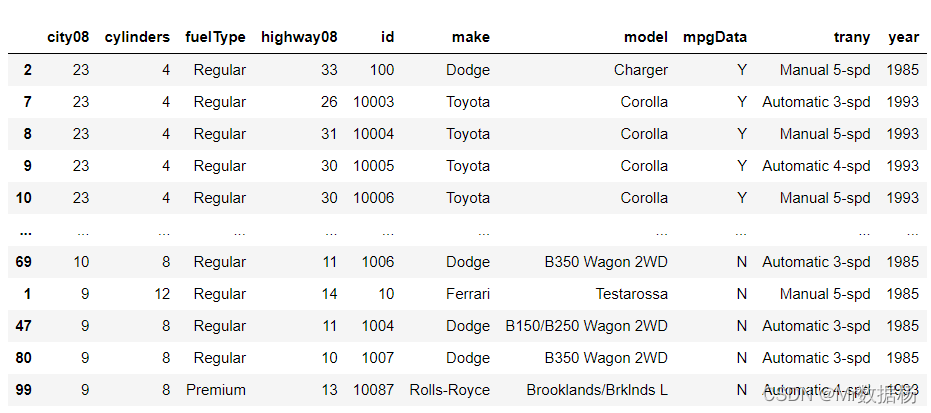
选择排序算法
可用的算法有快速排序(quicksort) 、归并排序(mergesort) 、堆排序(heapsort)。
df.sort_values(by="city08",ascending=False,kind="mergesort")
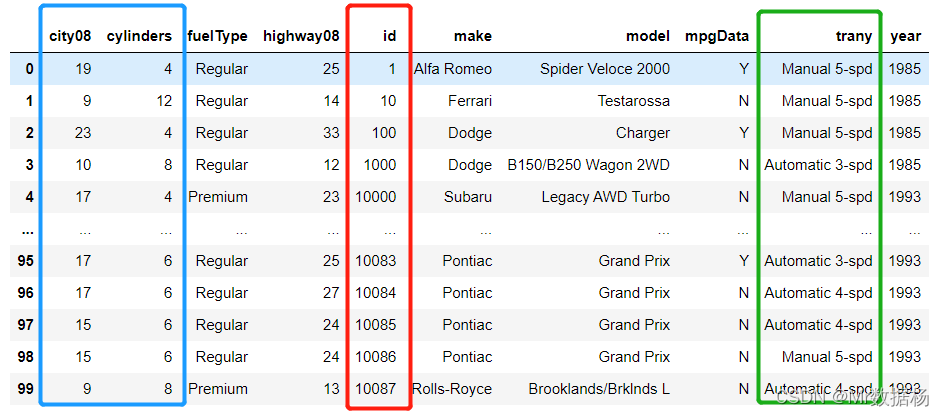
DataFrame 多列数据排序
按两个键排序,可以将列名列表by传递。
升序按列排序
要在多列上对 DataFrame 进行排序,必须提供列名列表。
df.sort_values(by=["make", "model"])[["make", "model"]]
make model
0 Alfa Romeo Spider Veloce 2000
18 Audi 100
19 Audi 100
20 BMW 740i
21 BMW 740il
.. ... ...
12 Volkswagen Golf III / GTI
13 Volkswagen Jetta III
15 Volkswagen Jetta III
16 Volvo 240
17 Volvo 240
[100 rows x 2 columns]
更改列排序顺序
调整排序 by 列表的的顺序。
df.sort_values(by=["model", "make"])[["make", "model"]]
make model
18 Audi 100
19 Audi 100
16 Volvo 240
17 Volvo 240
75 Mazda 626
.. ... ...
62 Ford Thunderbird
63 Ford Thunderbird
88 Oldsmobile Toronado
42 CX Automotive XM v6
43 CX Automotive XM v6a
[100 rows x 2 columns]
降序按多列排序
df.sort_values(by=["make", "model"],ascending=False)[["make", "model"]]
make model
16 Volvo 240
17 Volvo 240
13 Volkswagen Jetta III
15 Volkswagen Jetta III
11 Volkswagen Golf III / GTI
.. ... ...
21 BMW 740il
20 BMW 740i
18 Audi 100
19 Audi 100
0 Alfa Romeo Spider Veloce 2000
[100 rows x 2 columns]
不同排序顺序的多列排序
使用多个列进行排序并让这些列使用不同的 ascending 参数。使用 pandas 可以通过单个方法调用来完成此操作。如果要按升序对某些列进行排序,而按降序对某些列进行排序,则可以将布尔值列表传递给 ascending。
df.sort_values(
by=["make", "model", "city08"],
ascending=[True, True, False]
)[["make", "model", "city08"]]
make model city08
0 Alfa Romeo Spider Veloce 2000 19
18 Audi 100 17
19 Audi 100 17
20 BMW 740i 14
21 BMW 740il 14
.. ... ... ...
11 Volkswagen Golf III / GTI 18
15 Volkswagen Jetta III 20
13 Volkswagen Jetta III 18
17 Volvo 240 19
16 Volvo 240 18
[100 rows x 3 columns]
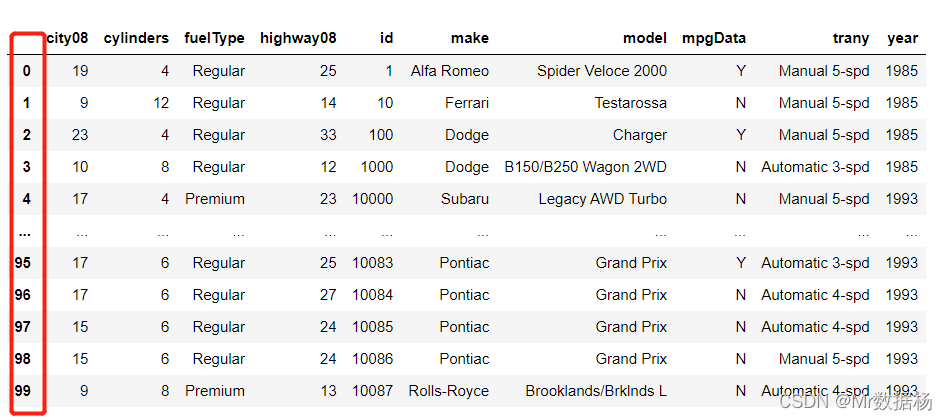
DataFrame 索引排序
DataFrame 有一个.index属性,默认情况下是其行位置的数字表示。可以将索引视为行号,有助于快速查找和识别行。
索引升序排序
可以使用 .sort_index() 根据行索引对 DataFrame 进行排序。 像在前面的示例中那样按列值排序会重新排序 DataFrame 中的行,因此索引变得杂乱无章。 当过滤 DataFrame 或删除或添加行时,也会发生这种情况。
使用 .sort_values() 创建一个新的排序 DataFrame 进行后续的操作。
sorted_df = df.sort_values(by=["make", "model"])
sorted_df
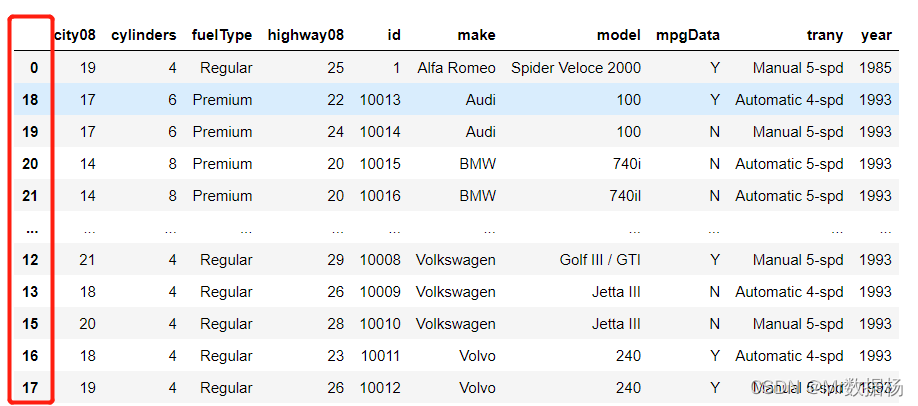
使用 .sort_index() 恢复 DataFrame 原始顺序。
sorted_df.sort_index()
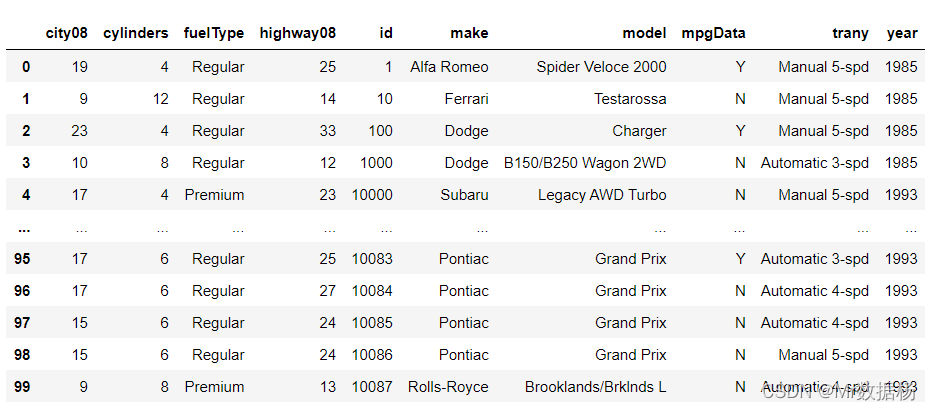
使用 bool 进行判断。
sorted_df.sort_index() == df
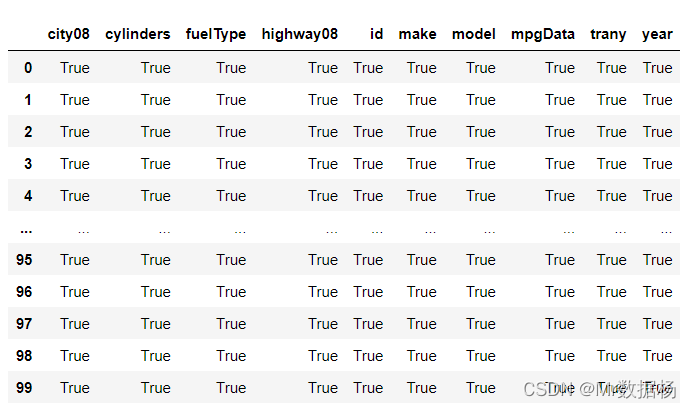
可以自定义索引分配了 .set_index() 设置列表进行参数传递。
assigned_index_df = df.set_index(["make", "model"])
assigned_index_df
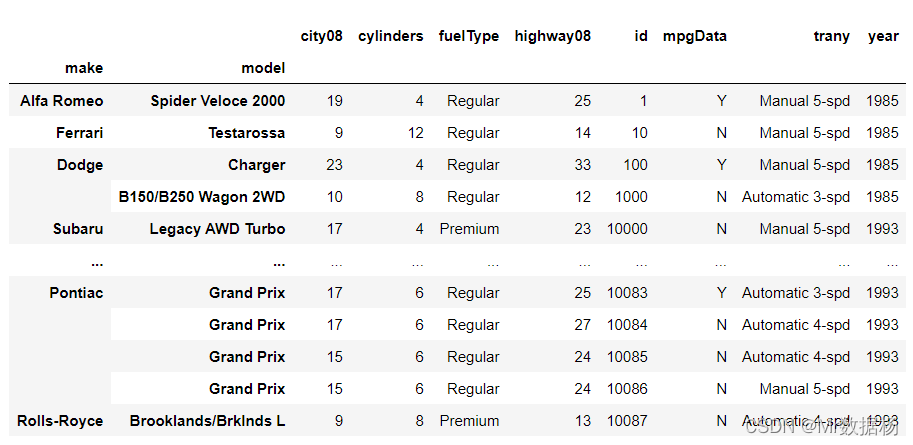
使用 .sort_index() 进行排序。
assigned_index_df.sort_index()
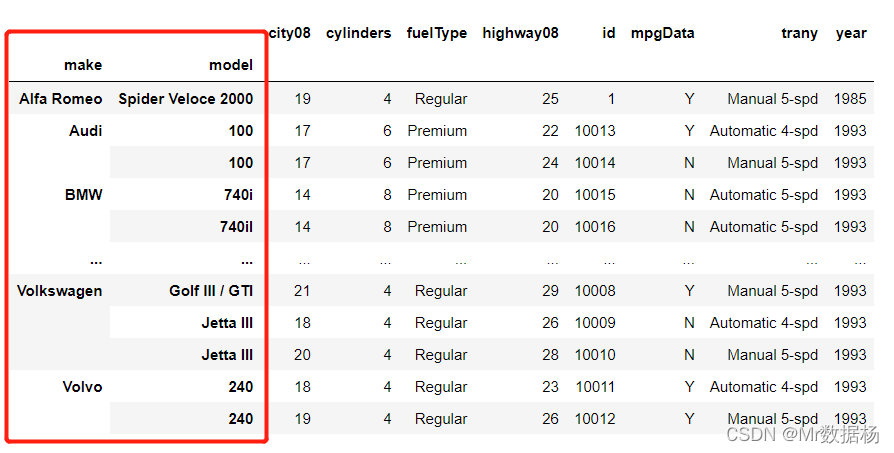
索引降序排序
assigned_index_df.sort_index(ascending=False)
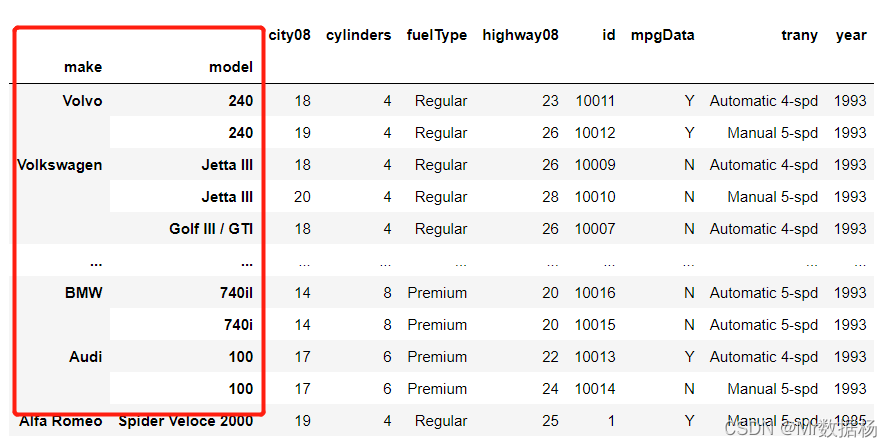
DataFrame 列排序
使用 DataFrame 的列标签对行值进行排序。 使用 .sort_index() 并将可选参数轴设置为 1 将按列标签对 DataFrame 进行排序。 排序算法应用于轴标签而不是实际数据。 这有助于对 DataFrame 进行视觉检查。
当您使用 .sort_index() 而不传递任何显式参数时,使用 axis=0 作为默认参数。 DataFrame 的轴是指索引(axis=0)或列(axis=1)。 可以使用这两个轴来索引和选择 DataFrame 中的数据以及对数据进行排序。
列标签排序
df.sort_index(axis=1)
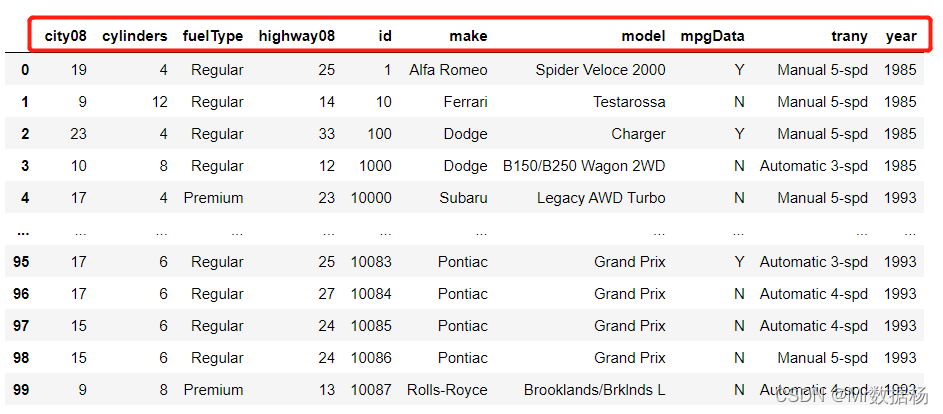
df.sort_index(axis=1, ascending=False)
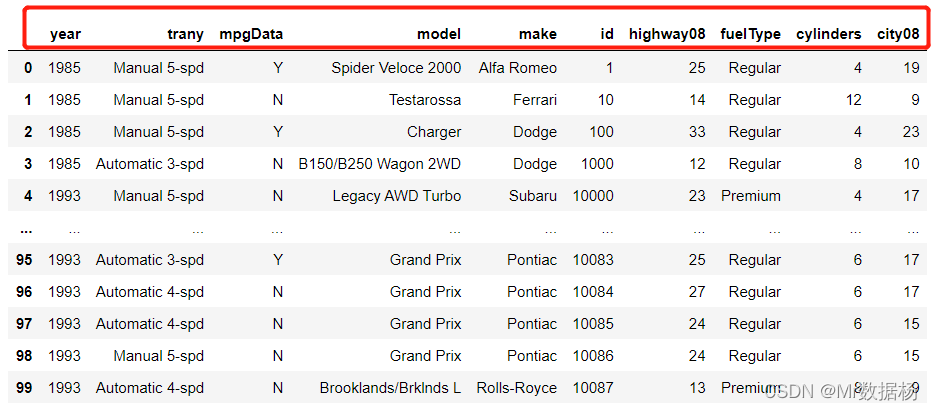
排序时处理丢失的数据
现实的数据通常有很多不完善之处。虽然 pandas 有多种方法可用于在排序之前清理数据,但有时在排序时查看哪些数据丢失是件好事。可以使用 na_position 参数执行此操作。
df["mpgData_"] = df["mpgData"].map({
"Y": True})
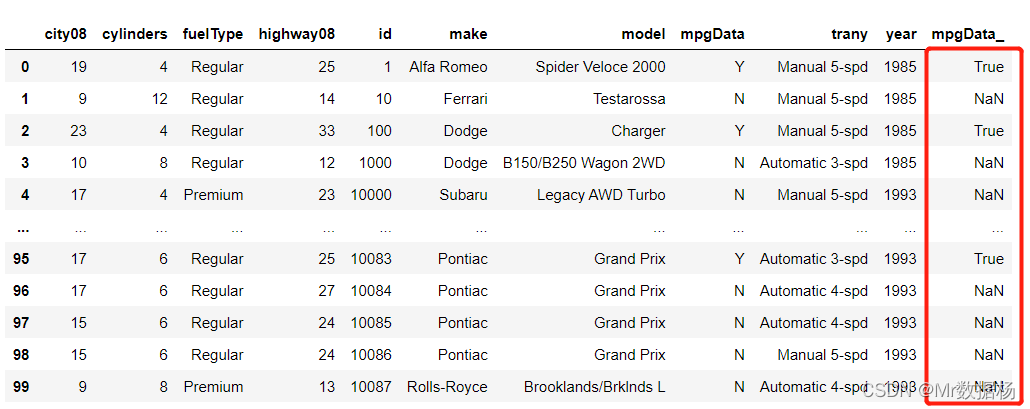
na_position 的 .sort_values()
.sort_values() 接受一个名为 na_position 的参数,该参数有助于处理要排序的列中的缺失数据。
df.sort_values(by="mpgData_",na_position="first")
city08 cylinders fuelType ... trany year mpgData_
1 9 12 Regular ... Manual 5-spd 1985 NaN
3 10 8 Regular ... Automatic 3-spd 1985 NaN
4 17 4 Premium ... Manual 5-spd 1993 NaN
5 21 4 Regular ... Automatic 3-spd 1993 NaN
11 18 4 Regular ... Automatic 4-spd 1993 NaN
.. ... ... ... ... ... ... ...
32 15 8 Premium ... Automatic 4-spd 1993 True
33 15 8 Premium ... Automatic 4-spd 1993 True
37 17 6 Regular ... Automatic 3-spd 1993 True
85 17 6 Regular ... Automatic 4-spd 1993 True
95 17 6 Regular ... Automatic 3-spd 1993 True
[100 rows x 11 columns]
用于排序的列中的任何缺失数据都将显示在 DataFrame 的前面。用于查看列的缺失值情况。
DataFrame 排序修改
在 .sort_values() 中增加重要的参数 inplace=True。作用在于直接对原始的 DataFrame 进行修改。
df.sort_values("city08", inplace=True)
df.sort_index(inplace=True)
账面的代码每次执行结果结果的 df 都会替代原始的 df 。