学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
Pandas DataFrame 是一个包含二维数据及其对应索引的结构。DataFrame 广泛用于数据科学、机器学习、科学计算和许多其他数据密集型领域。
DataFrame 类似于SQL 表或在 Excel 中使用的电子表格。不过从处理数据的效率上来说比 SQL 和 Excel 更快,而且功能更全。

文章目录
Pandas DataFrame
Pandas DataFrame 是包含以二维、行和列组织的数据、对应于行和列的索引的数据结构。
使用字典的方式创建DataFrame。
import pandas as pd
df = pd.read_excel("Romance of the Three Kingdoms 13/人物详情数据.xlsx")
df.head()
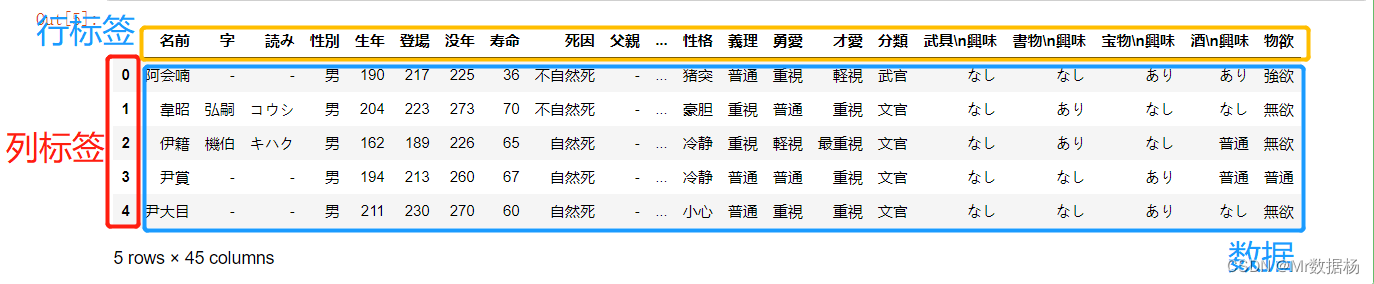
设定条件查询数据的前 N 行或者后 N 行内容。
df.head(2)

df.tail(2)

查看某列数据的话直接使用字典取值的方式获取即可。
name = df['名前']
name
0 阿会喃
1 韋昭
2 伊籍
3 尹賞
4 尹大目
...
852 卑弥呼
853 韓世忠
854 梁紅玉
855 范蠡
856 荀灌
Name: 名前, Length: 857, dtype: object
也可以像获取类实例的属性一样访问该列数据。
df.名前
0 阿会喃
1 韋昭
2 伊籍
3 尹賞
4 尹大目
...
852 卑弥呼
853 韓世忠
854 梁紅玉
855 范蠡
856 荀灌
Name: 名前, Length: 857, dtype: object
Pandas DataFrame 的每一列都是一个 pandas.Series 实例,保存一维数据及其索引的结构。可以像使用字典一样获取对象的单个项目,Series 方法是使用其索引作为键。
name [10]
'袁胤'
可以使用 .loc[] 访问器访问整行数据。
df.loc[10]

label 对应的行10,其中包含对应行数据之外,还提取了相应列的索引,返回的行也是一个 pandas.Series 实例。
创建 DataFrame
分别使用不同的方式创建DataFrame,创建之前先要导入对应的三方库。
import numpy as np
import pandas as pd
使用 Dict 创建
data = {
'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
pd.DataFrame(data)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
可以用 columns参数控制列的顺序,用index控制行索引的顺序。
pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x'])
z y x
100 100 2 1
200 100 4 2
300 100 8 3
使用 List 创建
字典键是列索引,字典值是 DataFrame 中的数据值。
l = [{
'x': 1, 'y': 2, 'z': 100},
{
'x': 2, 'y': 4, 'z': 100},
{
'x': 3, 'y': 8, 'z': 100}]
pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
还可以使用嵌套列表或列表列表作为数据值,并且创建时需要指明行、列索引。元组和列表创建的方式相同。
l = [[1, 2, 100],
[2, 4, 100],
[3, 8, 100]]
pd.DataFrame(l, columns=['x', 'y', 'z'])
x y z
0 1 2 100
1 2 4 100
2 3 8 100
使用 NumPy 数组创建
arr = np.array([[1, 2, 100],
[2, 4, 100],
[3, 8, 100]])
df_ = pd.DataFrame(arr, columns=['x', 'y', 'z'])
df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100
文件读取创建
可以在多种文件类型(包括 CSV、Excel、SQL、JSON 等)中保存和加载Pandas DataFrame 中的数据和索引。
先将生成的数据保存到不同的文件中。
import pandas as pd
data = {
'名前': ['阿会喃', '韋昭', '伊籍', '尹賞', '尹大目'],
'字': ['-', '弘嗣', '機伯', '-', '-'],
'読み': ['-', 'コウシ', 'キハク', '-', '-'],
'性別': ['男', '男', '男', '男', '男'],
'生年': [190, 204, 162, 194, 211],
'登場': [217, 223, 189, 213, 230],
'没年': [225, 273, 226, 260, 270],
'寿命': [36, 70, 65, 67, 60],
'死因': ['不自然死', '不自然死', '自然死', '自然死', '自然死'],
'父親': ['-', '-', '-', '-', '-'],
'母親': ['-', '-', '-', '-', '-'],
'相性': ['62', '131', '77', '72', '38'],
'列伝': ['孟獲の配下。第三洞の元帥。\n【演義】諸葛亮の南蛮征圧で、張翼に襲撃されて捕らえられる。董荼那ともども、諸葛亮に解放されて心服するが、同じく解放されながらも服従しない孟獲の命で沙口の守備に派遣される。次の戦いで馬岱との対戦を避けた董荼那が孟獲に処罰されると、董荼那と結託して孟獲を捕らえ蜀軍に引き渡した。その後、再び釈放された孟獲が諸葛亮に心服したものと誤解し、孟獲に誘い出されて董荼那と共に殺された。\n【正史】記述なし。',
'呉の幕僚。正史では、司馬昭の名を避けて、韋曜と記される。\n【演義】記述なし。\n【正史】太子・孫和の命で「博奕論」を著し、博奕(すごろく)が益体のない遊びだと論じた。孫亮が即位すると諸葛恪に推薦され、薛瑩、華覈らと共に「呉書」の編集に当たる。しかし、孫晧が即位すると「呉書」の編集方針を巡って孫晧と対立。下戸だったがむりやり酒を飲まされ、態度が反抗的だとして処刑された。華覈とは親交が篤く、華覈は最後まで韋昭の助命嘆願に奔走した。',
'劉表の幕僚。後に劉備に仕える。\n【演義】劉表が劉備から贈られた的盧を返した時、的盧の凶相が乗り手に祟るという逸話を劉備に伝える。蔡瑁が劉備暗殺を測った時は劉備に危機を伝え逃亡させた。劉表が死に、後を継いだ劉琮が早々に降伏すると、劉備に仕え関羽と共に荊州を守る。荊州が呂蒙の攻撃を受けると馬良と共に救援要請のため成都に向かい、関羽が死ぬと成都に残った。その後、劉備に皇帝になるよう勧めた。\n【正史】使者としての機知、応対を孫権に感心された。諸葛亮、法正、劉巴、李厳らと蜀科(蜀の法律)を作った。',
'天水の武将。魏に仕えた後、蜀に降る。\n【演義】姜維の友人。諸葛亮が天水を攻めた時、先に蜀に降伏していた姜維と連絡を取り合う。蜀軍が攻め寄せると同僚の梁緒と謀って城門を開き、蜀軍を招き入れた。\n【正史】諸葛亮が天水を攻めた時、天水太守の馬遵から異心ありと疑われる。馬遵が逃走したため、姜維、梁虔、梁緒と共に降伏。蜀の滅亡前に死んだ。',
'大目は字。名は不詳。曹爽の腹心。\n【演義】曹爽が司馬懿に処刑された後、仇を討つために偽って司馬師の部下となる。友人の文欽が毌丘倹と共に反乱を起こした時、文欽に司馬師の死が近いことを知らせようとするが、その意図が伝わらず追い返された。\n【正史】少年の頃、曹氏の召使いとなり、そのまま皇帝の側に仕えた。'],
'商業': [0, 1, 5, 0, 0],
'農業': [0, 0, 4, 0, 1],
'文化': [0, 0, 5, 0, 0],
'訓練': [2, 0, 0, 0, 0],
'巡察': [1, 0, 0, 0, 0],
'説破': [0, 1, 5, 0, 0],
'交渉': [0, 0, 5, 2, 0],
'弁舌': [0, 0, 4, 1, 0],
'人徳': [0, 0, 0, 0, 0],
'威風': [0, 0, 0, 0, 0],
'神速': [0, 0, 0, 0, 0],
'奮戦': [1, 0, 0, 0, 0],
'連戦': [0, 0, 0, 0, 0],
'攻城': [0, 0, 0, 0, 0],
'兵器': [0, 0, 0, 0, 0],
'堅守': [0, 0, 0, 0, 0],
'水連': [0, 0, 0, 0, 0],
'一騎': [0, 0, 0, 0, 0],
'豪傑': [0, 0, 0, 0, 0],
'鬼謀': [0, 0, 0, 0, 0],
'音声': ['無骨男', '丁寧男', '策士男', '丁寧男', '老獪男'],
'武器': ['刀', '弓', '弓', '弓', '弓'],
'性格': ['猪突', '豪胆', '冷静', '冷静', '小心'],
'義理': ['普通', '重視', '重視', '普通', '普通'],
'勇愛': ['重視', '普通', '軽視', '普通', '重視'],
'才愛': ['軽視', '重視', '最重視', '重視', '重視'],
'分類': ['武官', '文官', '文官', '文官', '文官'],
'武具\n興味': ['なし', 'なし', 'なし', 'なし', 'なし'],
'書物\n興味': ['なし', 'あり', 'あり', 'なし', 'なし'],
'宝物\n興味': ['あり', 'なし', 'なし', 'あり', 'あり'],
'酒\n興味': ['あり', 'なし', '普通', '普通', 'なし'],
'物欲': ['強欲', '無欲', '無欲', '普通', '無欲']}
columns_name = ['名前', '字', '読み', '性別', '生年', '登場', '没年', '寿命', '死因', '父親', '母親', '相性',
'列伝', '商業', '農業', '文化', '訓練', '巡察', '説破', '交渉', '弁舌', '人徳', '威風', '神速',
'奮戦', '連戦', '攻城', '兵器', '堅守', '水連', '一騎', '豪傑', '鬼謀', '音声', '武器', '性格',
'義理', '勇愛', '才愛', '分類', '武具\n興味', '書物\n興味', '宝物\n興味', '酒\n興味', '物欲'
]
df = pd.DataFrame(data=data,columns=columns_name)
df.to_csv('data.csv')
df.to_excel('data.xlsx')
检索索引和数据
创建 DataFrame 后可以进行一些检索、修改操作。
索引作为序列
df.index
RangeIndex(start=0, stop=5, step=1)
df.columns
Index(['名前', '字', '読み', '性別', '生年', '登場', '没年', '寿命', '死因', '父親', '母親', '相性',
'列伝', '商業', '農業', '文化', '訓練', '巡察', '説破', '交渉', '弁舌', '人徳', '威風', '神速',
'奮戦', '連戦', '攻城', '兵器', '堅守', '水連', '一騎', '豪傑', '鬼謀', '音声', '武器', '性格',
'義理', '勇愛', '才愛', '分類', '武具\n興味', '書物\n興味', '宝物\n興味', '酒\n興味', '物欲'],
dtype='object')
df.columns[0]
'名前'
用序列修改索引。
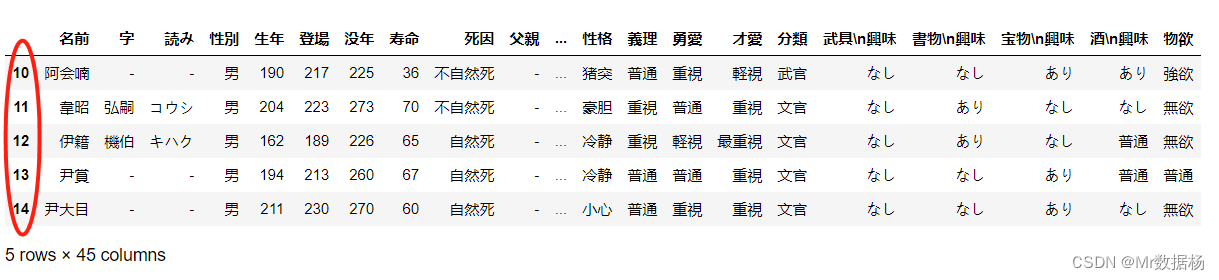
df.index = np.arange(10, 15)
df.index
Int64Index([10, 11, 12, 13, 14], dtype='int64')
df
数据转为 NumPy 数组
转化之后取值方式同List操作。
df.to_numpy()
array([['阿会喃', '-', '-', '男', 190, 217, 225, 36, '不自然死', '-', '-', '62',
'孟獲の配下。第三洞の元帥。\n【演義】諸葛亮の南蛮征圧で、張翼に襲撃されて捕らえられる。董荼那ともども、諸葛亮に解放されて心服するが、同じく解放されながらも服従しない孟獲の命で沙口の守備に派遣される。次の戦いで馬岱との対戦を避けた董荼那が孟獲に処罰されると、董荼那と結託して孟獲を捕らえ蜀軍に引き渡した。その後、再び釈放された孟獲が諸葛亮に心服したものと誤解し、孟獲に誘い出されて董荼那と共に殺された。\n【正史】記述なし。',
0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
'無骨男', '刀', '猪突', '普通', '重視', '軽視', '武官', 'なし', 'なし', 'あり', 'あり',
'強欲'],
......
['尹大目', '-', '-', '男', 211, 230, 270, 60, '自然死', '-', '-', '38',
'大目は字。名は不詳。曹爽の腹心。\n【演義】曹爽が司馬懿に処刑された後、仇を討つために偽って司馬師の部下となる。友人の文欽が毌丘倹と共に反乱を起こした時、文欽に司馬師の死が近いことを知らせようとするが、その意図が伝わらず追い返された。\n【正史】少年の頃、曹氏の召使いとなり、そのまま皇帝の側に仕えた。',
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
'老獪男', '弓', '小心', '普通', '重視', '重視', '文官', 'なし', 'なし', 'あり', 'なし',
'無欲']], dtype=object)
数据类型
数据值的类型,也称为数据类型或 dtypes,决定了 DataFrame 使用的内存量,以及计算速度和精度水平。
查看数据类型。
df.dtypes
名前 object
字 object
読み object
性別 object
生年 int64
登場 int64
没年 int64
......
dtype: object
使用.astype() 更改数据类型。
df_ = df.astype(dtype={
'生年': np.int32, '没年': np.int32})
df_.dtypes
名前 object
字 object
読み object
性別 object
生年 int32
登場 int64
没年 int32
......
dtype: object
DataFrame 大小
.ndim、.size和.shape分别返回维度数、每个维度上的数据值数和数据值总数。
df_.ndim
2
df_.shape
(5, 45)
df_.size
225
访问和修改数据
使用访问器获取数据
除了.loc[] 可以使用通过索引获取行或列的访问器之外,Pandas 还提供了访问器.iloc[],它通过整数索引检索行或列。
df.loc[10]
名前 阿会喃
字 -
読み -
性別 男
生年 190
登場 217
没年 225
......
酒\n興味 あり
物欲 強欲
Name: 10, dtype: object
df.iloc[0]
名前 阿会喃
字 -
読み -
性別 男
生年 190
登場 217
没年 225
......
酒\n興味 あり
物欲 強欲
Name: 10, dtype: object
.loc[] 和 .iloc[] 支持切片和 NumPy 的索引操作。
df.loc[:, '名前']
10 阿会喃
11 韋昭
12 伊籍
13 尹賞
14 尹大目
Name: 名前, dtype: object
df.iloc[:, 1]
10 阿会喃
11 韋昭
12 伊籍
13 尹賞
14 尹大目
Name: 名前, dtype: object
提供切片以及列表或数组而不是索引来获取多行或多列。
df.loc[11:15, ['名前', '字']]
名前 字
11 韋昭 弘嗣
12 伊籍 機伯
13 尹賞 -
14 尹大目 -
df.iloc[1:6, [0, 1]]
名前 字
11 韋昭 弘嗣
12 伊籍 機伯
13 尹賞 -
14 尹大目 -
.iloc[] 使用与切片元组、列表和 NumPy 数组相同的方式跳过行和列。
df.iloc[1:6:2, 0]
11 韋昭
13 尹賞
Name: 名前, dtype: object
使用 Python 内置的 **slice()**类,numpy.s_[] 或者 pd.IndexSlice[]。
df.iloc[slice(1, 6, 2), 0]
11 韋昭
13 尹賞
Name: 名前, dtype: object
df.iloc[np.s_[1:6:2], 0]
11 韋昭
13 尹賞
Name: 名前, dtype: object
df.iloc[pd.IndexSlice[1:6:2], 0]
11 韋昭
13 尹賞
Name: 名前, dtype: object
使用 .loc[] 和 .iloc[] 获取特定的数据值。但只需要一个值时建议使用专门的访问器 .at[] 和 .iat[]。
df.at[12, '名前']
'伊籍'
df.iat[2, 0]
'伊籍'
使用访问器设置数据
可以使用访问器通过传递 Python 序列、NumPy 数组或单个值来修改数据。
df.loc[:, '生年']
10 190
11 204
12 162
13 194
14 211
Name: 生年, dtype: int64
df.loc[:13, '生年'] = [40, 50, 60, 70]
df.loc[14:, '生年'] = 0
df['生年']
10 40
11 50
12 60
13 70
14 0
Name: 生年, dtype: int64
使用负索引 .iloc[] 来访问或修改数据。
df.iloc[:, -10] = np.array([88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0])w
df['生年']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
Name: 生年, dtype: float64
插入和删除数据
Pandas 提供了几种方便的方法来插入和删除行或列。
插入和删除行
创建一个插入的新数据。
new = pd.Series(data=['Mr数据杨', 'xxx', "-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-","-",],index=df.columns)
名前 Mr数据杨
字 xxx
読み -
性別 -
生年 -
登場 -
没年 -
寿命 -
......
物欲 -
dtype: object
使用 df.append() 加入新的数据。
df = df.append(pd.DataFrame(new).T)
df
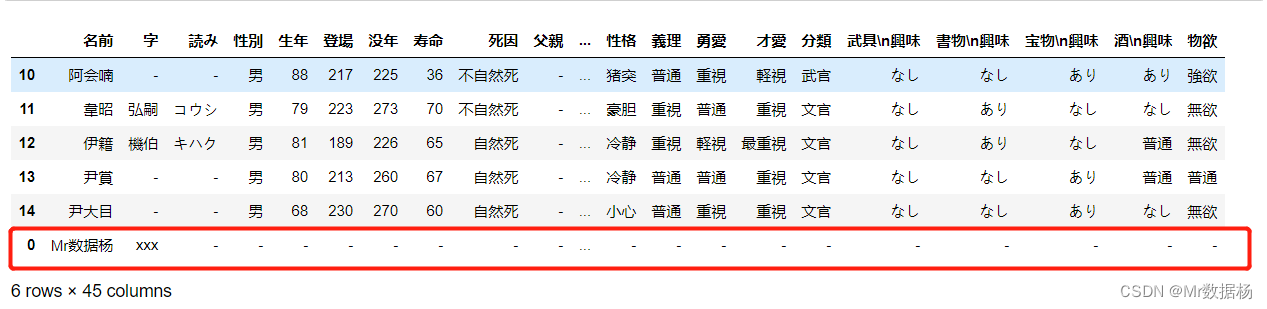
使用 df.drop() 删除新的数据。
df = df.drop(labels=[17])
df
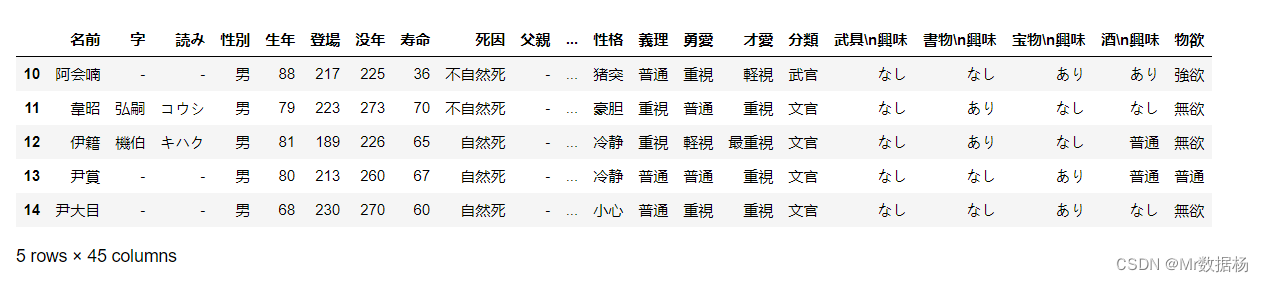
插入和删除列
直接赋值定义列名和定义数据。
df['temp_data'] = np.array([71.0, 95.0, 88.0, 79.0, 91.0])
df
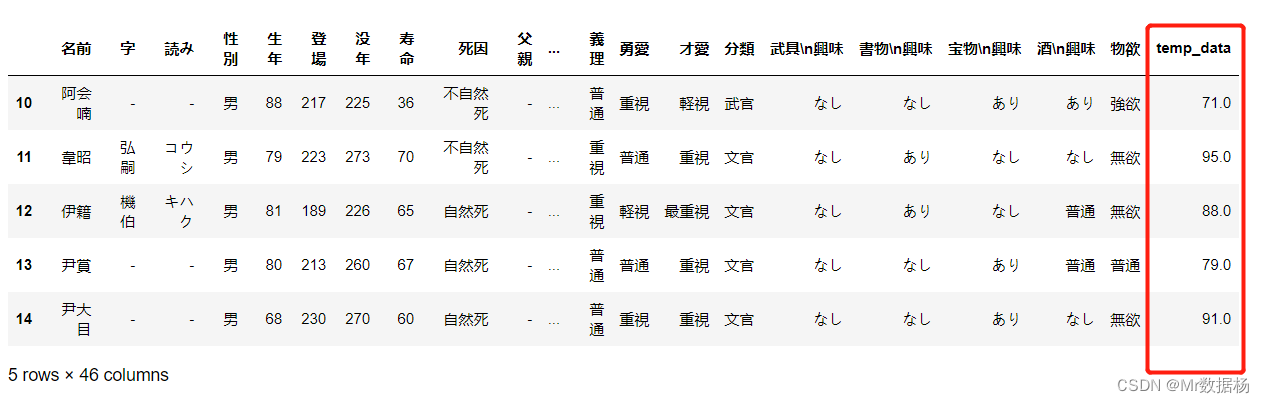
df['temp_data'] = 0.0
df
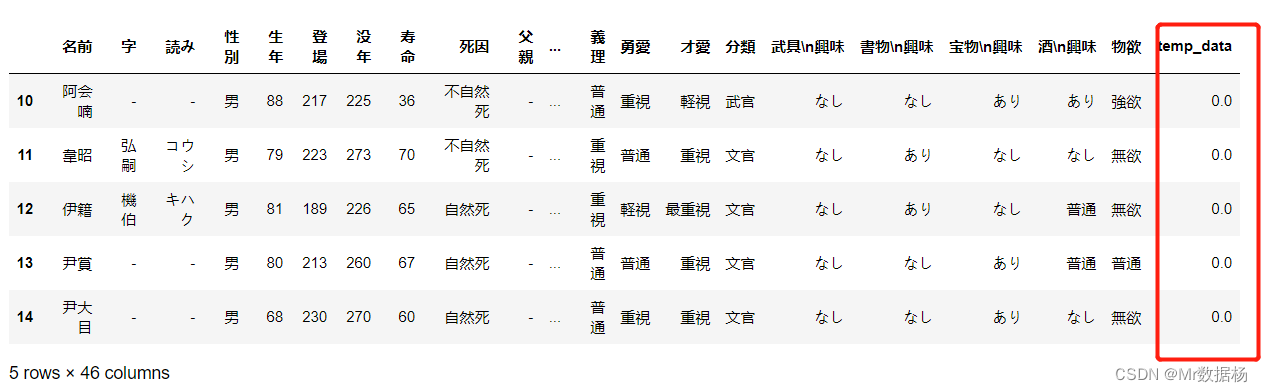
.insert() 在列的指定位置插入列数据。
df.insert(loc=4, column='new_temp_data',value=np.array([86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0]))
df

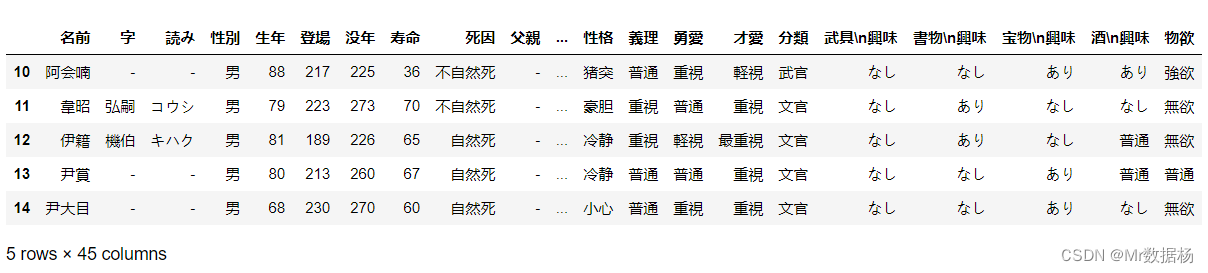
del 删除一列或者多列。
del df['new_temp_data]
df

使用 df.drop() 删除列。
df = df.drop(labels='age', axis=1)
df
应用算术运算
应用基本的算术运算。
df['没年'] - df['生年']
10 137
11 194
12 145
13 180
14 202
dtype: object
df['寿命'] / 100
10 0.36
11 0.7
12 0.65
13 0.67
14 0.6
Name: 寿命, dtype: object
线性组合公式计算汇总数据。
df['total'] =0.4 * df['商業'] + 0.3 * df['農業'] + 0.3 * df['文化']
df
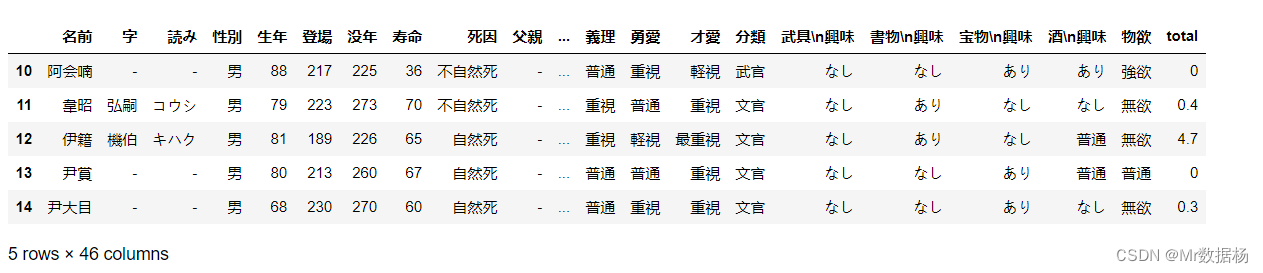
应用 NumPy 和 SciPy 函数
大多数 NumPy 和 SciPy 都可以作为参数而不是 NumPy 数组应用于 Pandas Series 或 DataFrame 对象。 可以使用 NumPy 的 numpy.average() 计算考生的总考试成绩。
import numpy as np
data = df.iloc[:, 13:16]
data
商業 農業 文化
10 0 0 0
11 1 0 0
12 5 4 5
13 0 0 0
14 0 1 0
np.average(data.astype(np.float),axis=1,weights=[0.4, 0.3, 0.3])
array([0. , 0.4, 4.7, 0. , 0.3])
del df['total']
df['total'] = np.average(df.iloc[:, 13:16].astype(np.float), axis=1,weights=[0.4, 0.3, 0.3])
df
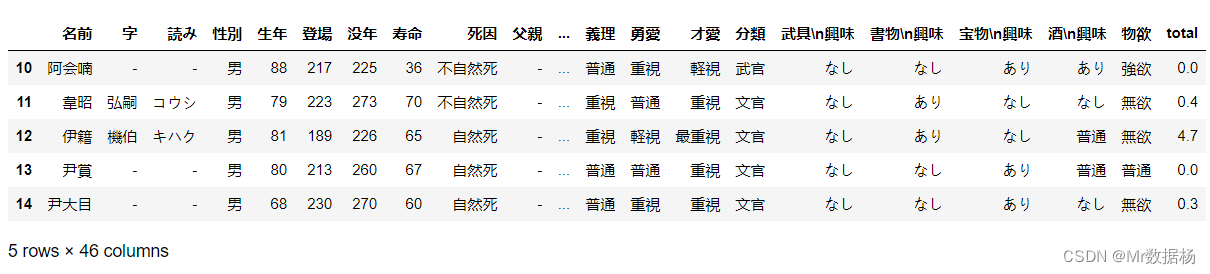
DataFrame 进行排序
.sort_values() 进行数据排序,需要指定排序的列。
df.sort_values(by='寿命', ascending=False)
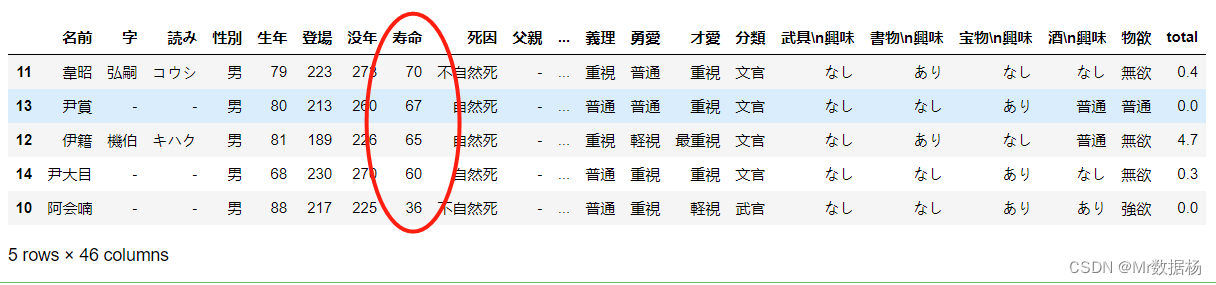
也可以指定多个列和多个列的排序方式。
df.sort_values(by=['生年', '寿命'], ascending=[False, False])
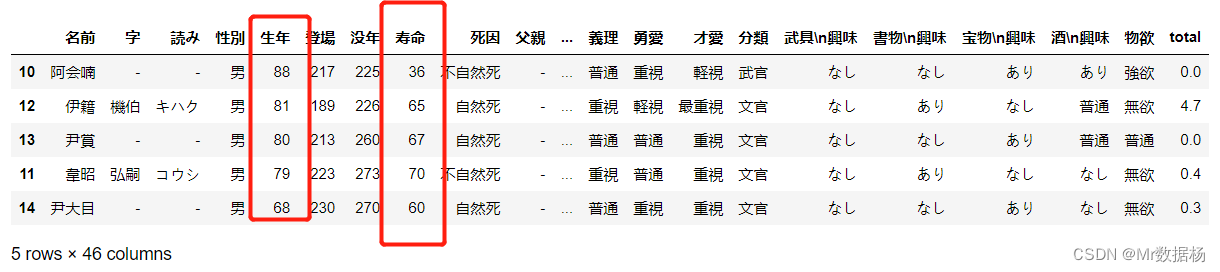
DataFrame 过滤数据
Pandas 的过滤功能工作方式类似于在 NumPy 中使用布尔数组进行索引。
filter_ = df['寿命'] >= 50
filter_
10 False
11 True
12 True
13 True
14 True
Name: 寿命, dtype: bool
使用表达式 df[filter_] 返回一个 DataFrame 中 True 的行数据。
df[filter_]

可是使用逻辑运算进行多条件的筛选。
df[(df['生年'] >= 80) & (df['寿命'] >= 65)]

使用.where() 可以替换不满足所提供条件的位置的值。
df['登場'].where(cond=df['登場'] >= 220, other=0.0)
10 0
11 223
12 0
13 0
14 230
Name: 登場, dtype: object
DataFrame 数据统计
基本统计信息使用 .describe()。
df.describe()
total
count 5.000000
mean 1.080000
std 2.031502
min 0.000000
25% 0.000000
50% 0.300000
75% 0.400000
max 4.700000
特定统计信息可以直接进行索引方法调用。
df.mean()
total 1.08
dtype: float64
df['total'].mean()
1.08
df.std()
total 2.031502
dtype: float64
df['total'].std()
2.031502
DataFrame 处理缺失数据
缺失数据在数据科学和机器学习中非常常见。Pandas 具有非常强大的处理缺失数据的功能。
Pandas 通常用 NaN(不是数字)值表示缺失数据。 在 Python 中可以使用 float(‘nan’)、math.nan 或 numpy.nan 获取 NaN。 从 Pandas 1.0 开始BooleanDtype、Int8Dtype、Int16Dtype、Int32Dtype 和 Int64Dtype 等新类型使用 pandas.NA 作为缺失值。
df_ = pd.DataFrame({
'x': [1, 2, np.nan, 4]})
df_
x
0 1.0
1 2.0
2 NaN
3 4.0
缺失数据进行计算
许多 Pandas 方法在执行计算时会忽略 nan 值,除非明确指示。
df = pd.read_excel("Romance of the Three Kingdoms 13/人物详情数据.xlsx",sheet_name="包含null")
df.head()
df_.mean()
生年 180.283547
登場 201.185531
没年 233.568261
寿命 54.284714
商業 0.770128
農業 0.631272
文化 0.719953
訓練 1.323221
巡察 1.079347
説破 0.821470
交渉 0.929988
弁舌 0.879813
人徳 0.142357
威風 0.285881
神速 0.871645
奮戦 0.536756
連戦 0.592765
攻城 0.658110
兵器 0.064177
堅守 0.640607
水連 0.625438
一騎 0.614936
豪傑 0.259043
鬼謀 0.253209
dtype: float64
df.mean(skipna=False)
生年 180.283547
登場 201.185531
没年 233.568261
寿命 54.284714
商業 0.770128
農業 0.631272
文化 0.719953
訓練 1.323221
巡察 1.079347
説破 0.821470
交渉 0.929988
弁舌 0.879813
人徳 0.142357
威風 0.285881
神速 0.871645
奮戦 0.536756
連戦 0.592765
攻城 0.658110
兵器 0.064177
堅守 0.640607
水連 0.625438
一騎 0.614936
豪傑 0.259043
鬼謀 0.253209
dtype: float64
填充缺失数据
.fillna() 进行缺失数据填充。
# 指定填充数据
df.fillna(value="-")
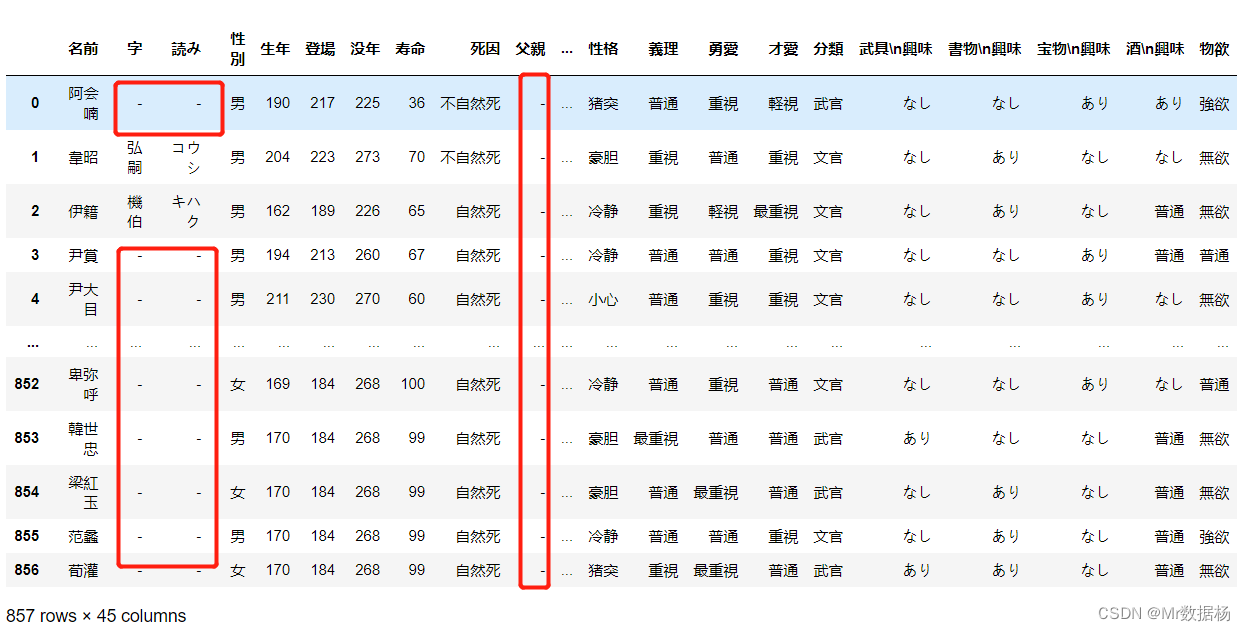
# 向前填充
df.fillna(method='ffill')
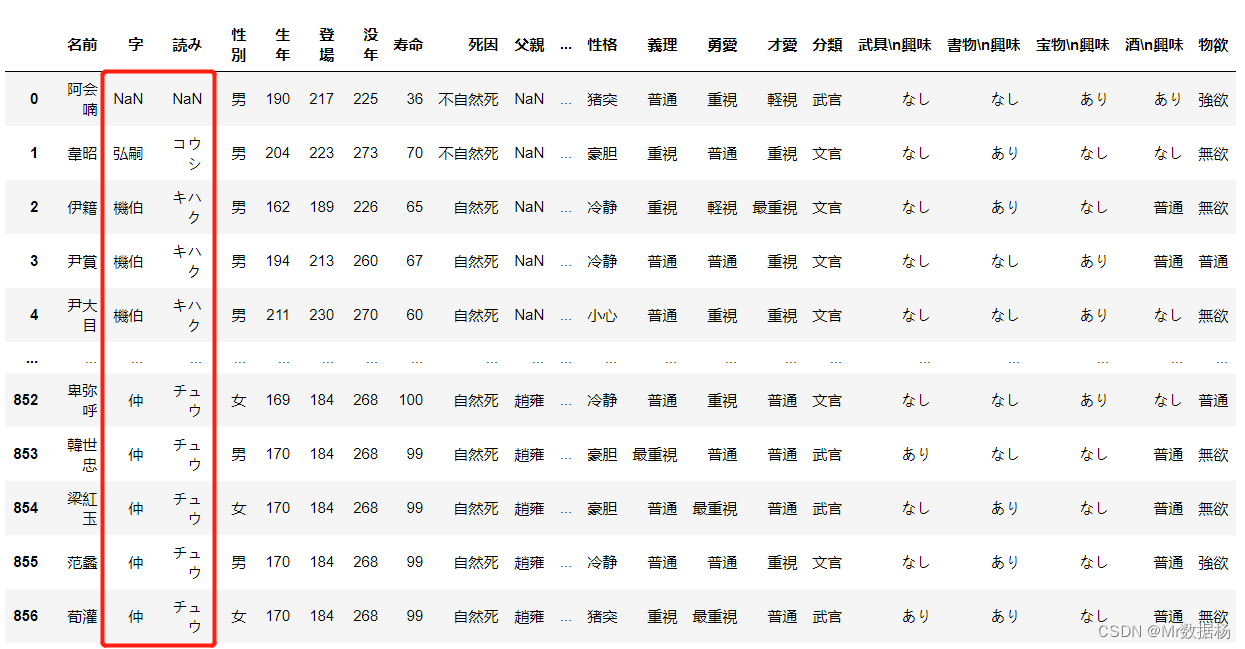
# 向后填充
df.fillna(method='bfill')
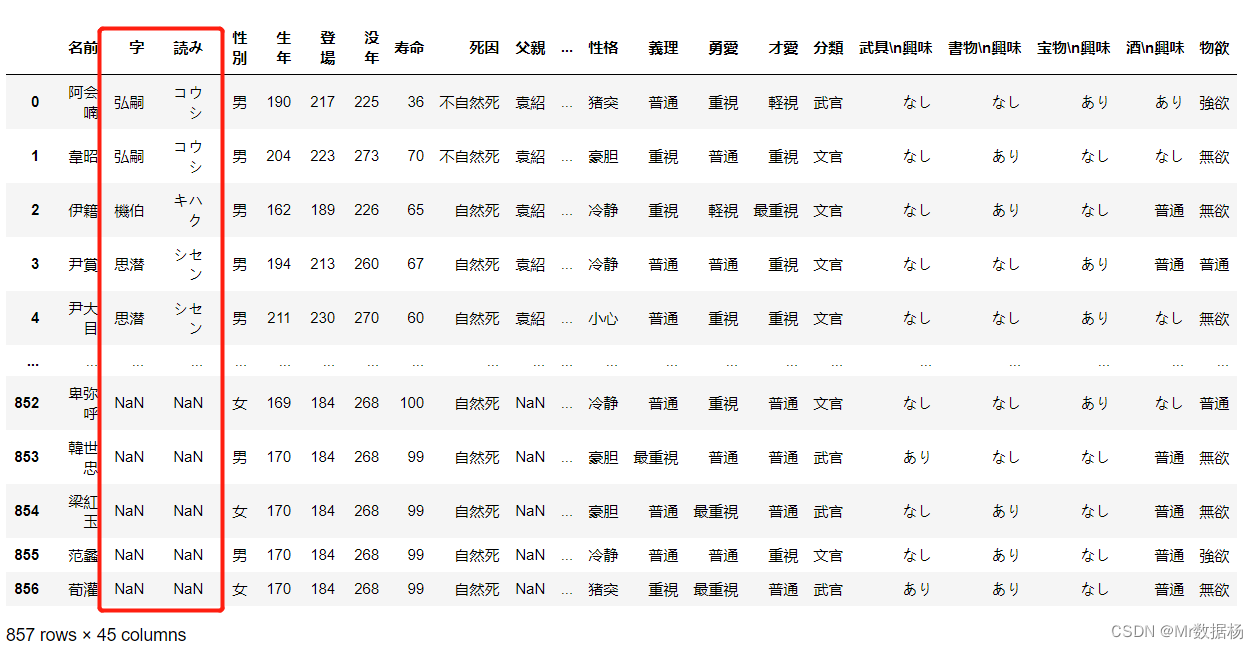
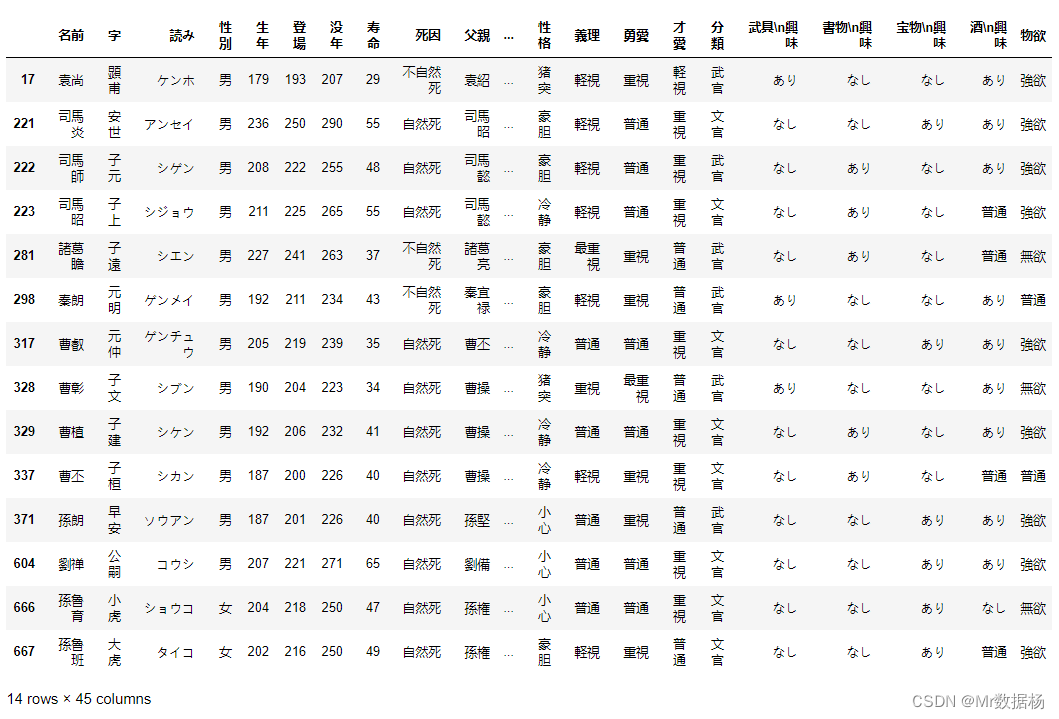
删除缺少数据的行和列
使用 .dropna() 直接进行处理。
df.dropna()
遍历 DataFrame
使用.items()and .iteritems() 遍历 Pandas DataFrame 的列。每次迭代都会产生一个以列名和列数据作为Series对象的元组。
for col_label, col in df.iteritems():
print(col_label, col, sep='\n', end='\n\n')
名前
0 阿会喃
1 韋昭
2 伊籍
3 尹賞
4 尹大目
...
852 卑弥呼
853 韓世忠
854 梁紅玉
855 范蠡
856 荀灌
Name: 名前, Length: 857, dtype: object
字
0 NaN
1 弘嗣
2 機伯
3 NaN
4 NaN
...
852 NaN
853 NaN
854 NaN
855 NaN
856 NaN
Name: 字, Length: 857, dtype: object
読み
0 NaN
1 コウシ
2 キハク
3 NaN
4 NaN
...
852 NaN
853 NaN
854 NaN
855 NaN
856 NaN
Name: 読み, Length: 857, dtype: object
性別
0 男
1 男
2 男
3 男
4 男
..
852 女
853 男
854 女
855 男
856 女
Name: 性別, Length: 857, dtype: object
生年
0 190
1 204
2 162
3 194
4 211
...
852 169
853 170
854 170
855 170
856 170
Name: 生年, Length: 857, dtype: int64
登場
0 217
1 223
2 189
3 213
4 230
...
852 184
853 184
854 184
855 184
856 184
Name: 登場, Length: 857, dtype: int64
没年
0 225
1 273
2 226
3 260
4 270
...
852 268
853 268
854 268
855 268
856 268
Name: 没年, Length: 857, dtype: int64
寿命
0 36
1 70
2 65
3 67
4 60
...
852 100
853 99
854 99
855 99
856 99
Name: 寿命, Length: 857, dtype: int64
......
使用 .iterrows() 遍历 DataFrame 的行。
for row_label, row in df.iterrows():
print(row_label, row, sep='\n', end='\n\n')
0
名前 阿会喃
字 NaN
読み NaN
性別 男
生年 190
登場 217
没年 225
寿命 36
死因 不自然死
父親 NaN
母親 NaN
相性 62
列伝 孟獲の配下。第三洞の元帥。\n【演義】諸葛亮の南蛮征圧で、張翼に襲撃されて捕らえられる。董荼...
商業 0
農業 0
文化 0
訓練 2
巡察 1
説破 0
交渉 0
弁舌 0
人徳 0
威風 0
神速 0
奮戦 1
連戦 0
攻城 0
兵器 0
堅守 0
水連 0
一騎 0
豪傑 0
鬼謀 0
音声 無骨男
武器 刀
性格 猪突
義理 普通
勇愛 重視
才愛 軽視
分類 武官
武具\n興味 なし
書物\n興味 なし
宝物\n興味 あり
酒\n興味 あり
物欲 強欲
Name: 0, dtype: object
......
DataFrame 时间序列
使用时间序列创建index
创建一个一天中的每小时温度数据 DataFrame。
temp_c = [ 8.0, 7.1, 6.8, 6.4, 6.0, 5.4, 4.8, 5.0,
9.1, 12.8, 15.3, 19.1, 21.2, 22.1, 22.4, 23.1,
21.0, 17.9, 15.5, 14.4, 11.9, 11.0, 10.2, 9.1]
使用 date_range() 构建时间索引。
dt = pd.date_range(start='2022-04-16 00:00:00.0', periods=24,freq='H')
df
DatetimeIndex(['2022-04-16 00:00:00', '2022-04-16 01:00:00',
'2022-04-16 02:00:00', '2022-04-16 03:00:00',
'2022-04-16 04:00:00', '2022-04-16 05:00:00',
'2022-04-16 06:00:00', '2022-04-16 07:00:00',
'2022-04-16 08:00:00', '2022-04-16 09:00:00',
'2022-04-16 10:00:00', '2022-04-16 11:00:00',
'2022-04-16 12:00:00', '2022-04-16 13:00:00',
'2022-04-16 14:00:00', '2022-04-16 15:00:00',
'2022-04-16 16:00:00', '2022-04-16 17:00:00',
'2022-04-16 18:00:00', '2022-04-16 19:00:00',
'2022-04-16 20:00:00', '2022-04-16 21:00:00',
'2022-04-16 22:00:00', '2022-04-16 23:00:00'],
dtype='datetime64[ns]', freq='H')
使用日期时间值作为行索引很方便。
temp_c
2022-04-16 00:00:00 8.0
2022-04-16 01:00:00 7.1
2022-04-16 02:00:00 6.8
2022-04-16 03:00:00 6.4
2022-04-16 04:00:00 6.0
2022-04-16 05:00:00 5.4
2022-04-16 06:00:00 4.8
2022-04-16 07:00:00 5.0
2022-04-16 08:00:00 9.1
2022-04-16 09:00:00 12.8
2022-04-16 10:00:00 15.3
2022-04-16 11:00:00 19.1
2022-04-16 12:00:00 21.2
2022-04-16 13:00:00 22.1
2022-04-16 14:00:00 22.4
2022-04-16 15:00:00 23.1
2022-04-16 16:00:00 21.0
2022-04-16 17:00:00 17.9
2022-04-16 18:00:00 15.5
2022-04-16 19:00:00 14.4
2022-04-16 20:00:00 11.9
2022-04-16 21:00:00 11.0
2022-04-16 22:00:00 10.2
2022-04-16 23:00:00 9.1
索引和切片
用切片来获取部分信息。
temp["2022-04-16 02:00:00":"2022-04-16 08:00:00"]
temp_c
2022-04-16 02:00:00 6.8
2022-04-16 03:00:00 6.4
2022-04-16 04:00:00 6.0
2022-04-16 05:00:00 5.4
2022-04-16 06:00:00 4.8
2022-04-16 07:00:00 5.0
2022-04-16 08:00:00 9.1
重采样
使用 .resample() 进行重采样选取数据。
temp.resample(rule='6h').mean()
temp_c
2022-04-16 00:00:00 6.616667
2022-04-16 06:00:00 11.016667
2022-04-16 12:00:00 21.283333
2022-04-16 18:00:00 12.016667
窗口滚动
使用 .rolling() 进行固定长度滚动窗口分析,指定数量的相邻行计算统计数据。
temp.rolling(window=3).mean()
temp_c
2022-04-16 00:00:00 NaN
2022-04-16 01:00:00 NaN
2022-04-16 02:00:00 7.300000
2022-04-16 03:00:00 6.766667
2022-04-16 04:00:00 6.400000
2022-04-16 05:00:00 5.933333
2022-04-16 06:00:00 5.400000
2022-04-16 07:00:00 5.066667
2022-04-16 08:00:00 6.300000
2022-04-16 09:00:00 8.966667
2022-04-16 10:00:00 12.400000
2022-04-16 11:00:00 15.733333
2022-04-16 12:00:00 18.533333
2022-04-16 13:00:00 20.800000
2022-04-16 14:00:00 21.900000
2022-04-16 15:00:00 22.533333
2022-04-16 16:00:00 22.166667
2022-04-16 17:00:00 20.666667
2022-04-16 18:00:00 18.133333
2022-04-16 19:00:00 15.933333
2022-04-16 20:00:00 13.933333
2022-04-16 21:00:00 12.433333
2022-04-16 22:00:00 11.033333
2022-04-16 23:00:00 10.100000
DataFrame 绘图
Pandas 允许基于 DataFrames 可视化数据或创建绘图。它在后台使用Matplotlib ,因此利用 Pandas 的绘图功能与使用 Matplotlib 非常相似。
import matplotlib.pyplot as plt
temp.plot()
plt.show()
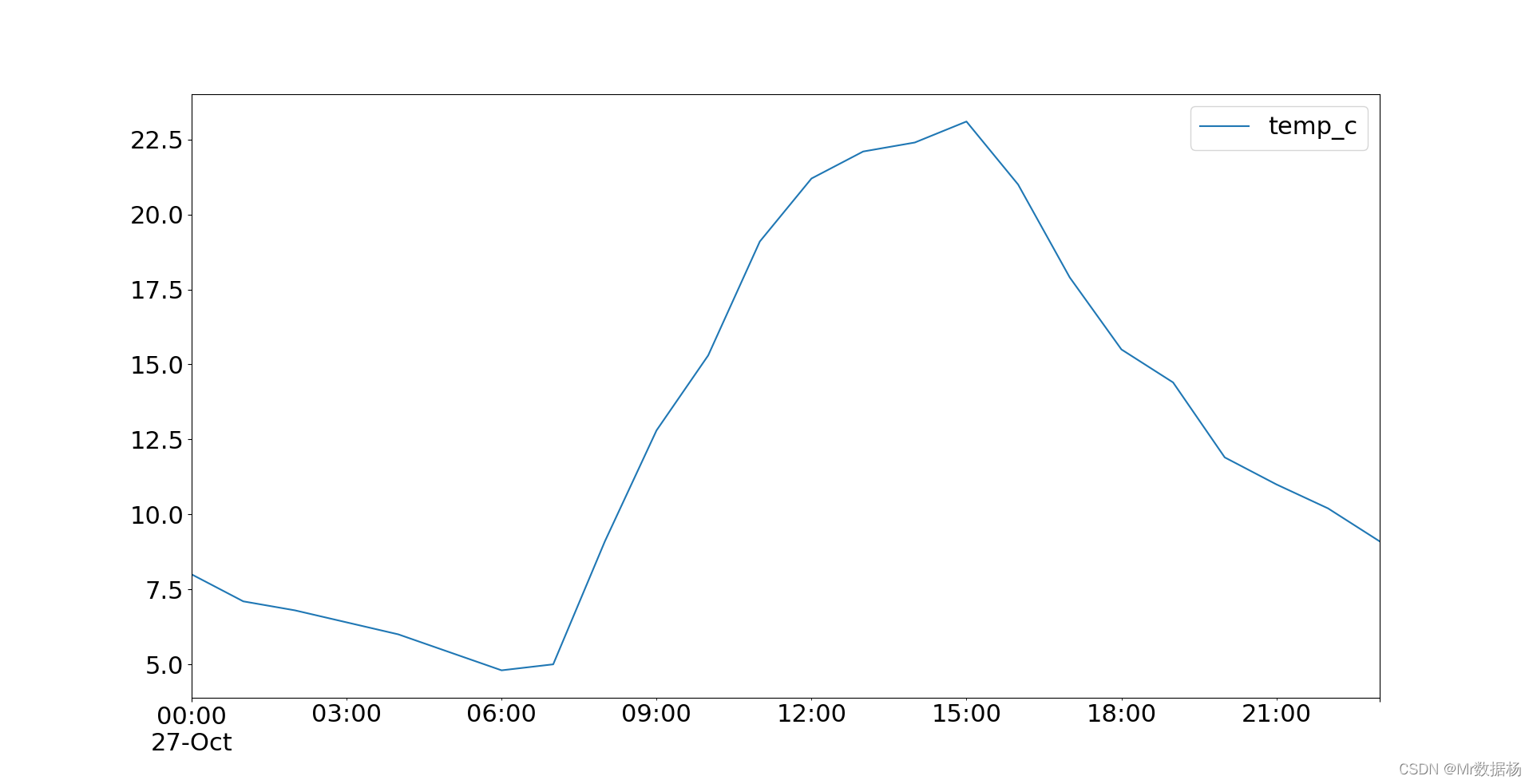
图像的保存。
temp.plot().get_figure().savefig('tmp.png')
其他图表,比如直方图。
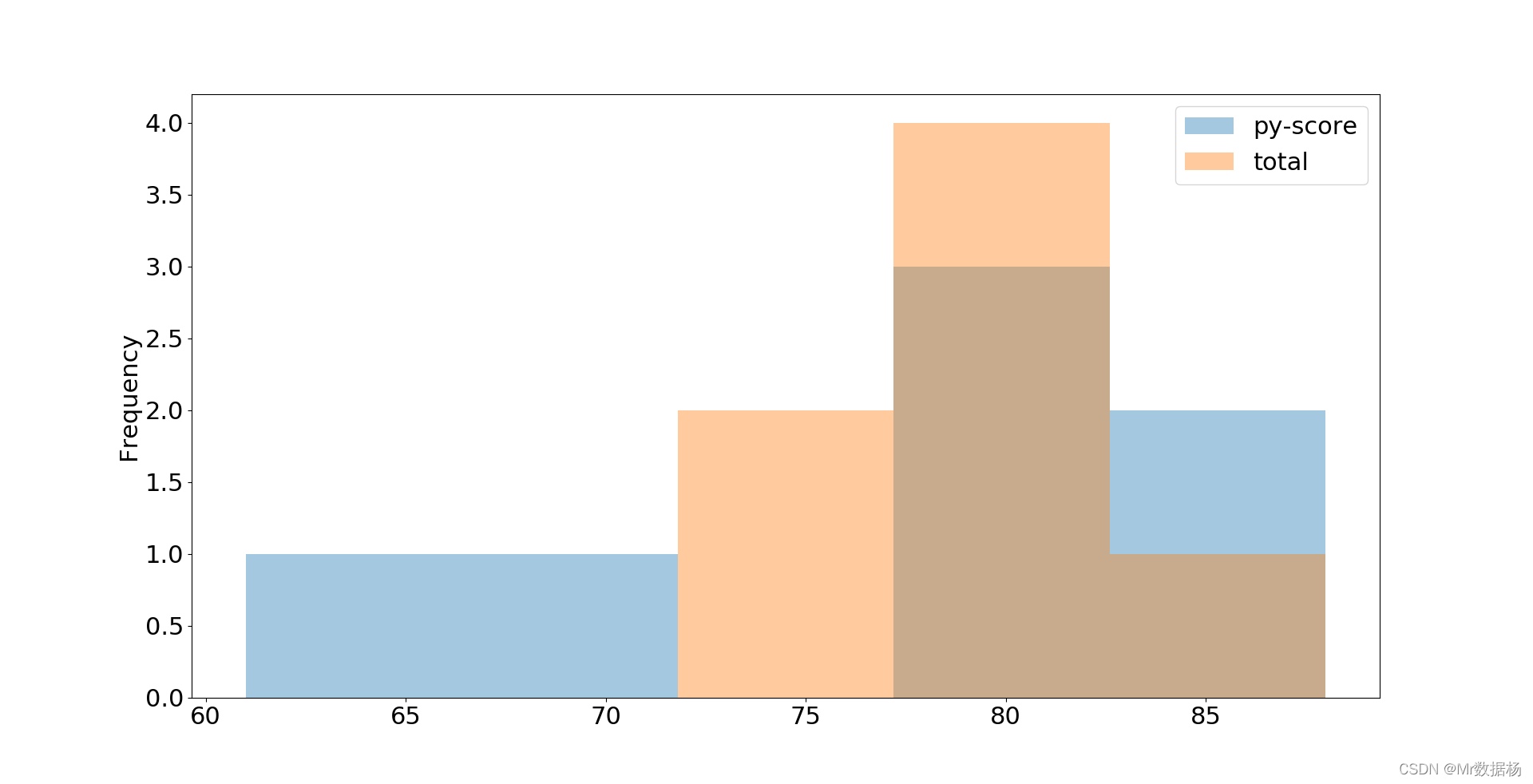
df.loc[:, ['py-score', 'total']].plot.hist(bins=5, alpha=0.4)
plt.show()